Bouchons applicatifs (Partie 2)
Recherche des goulots d’étranglements

La première partie de cet article s’est concentré sur la mise en place d’une politique de centralisation des journaux générés par une partie du SI d’Atomenergy. Pour rappel, l'entreprise a développé un tableau de bord énergie utilisé pour piloter le fonctionnement de ses centrales. Malheureusement, cette application est devenue très lente à charger. Nous avons été missionnés pour mettre en place une politique de détection des goulots d’étranglement.
A la recherche des goulots
Un des moyens les plus simples pour repérer les goulots est de générer un événement à chaque fonction d’entrée/sortie du système. Pour permettre de corréler ces événements entre eux, on utilise un identifiant de requête qui circule dans l’application. Ce dernier est généré à l’appel du service, il identifie chaque entrée de journal à la suite de cet appel.

Grâce à ces journaux, nous avons accès à deux métriques importantes :
- le temps de réponse, c’est-à-dire le temps total qu’a mis l’application pour répondre ou la latence de l’application ;
- le temps jusqu’au dernier octet (Time To Last Byte, TTLB), où le temps entre un appel et le moment ou la réponse est entièrement reçue. Cette variable correspond au temps de réponse additionné à la latence du réseau.
Construction de l’outil de recherche des goulots
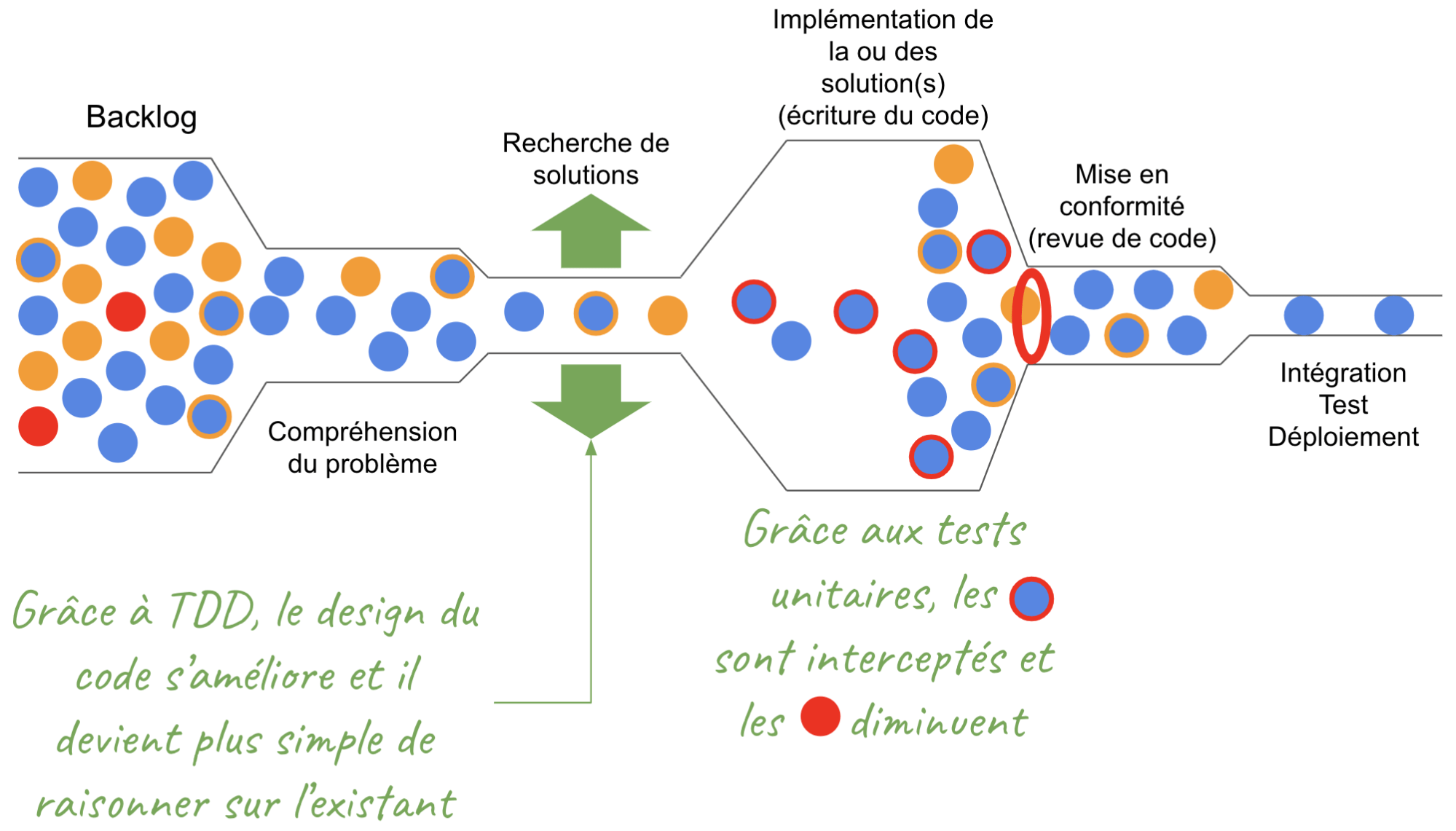
Notre objectif est de construire un tableau de bord constitué d’une série d’éléments (tableaux graphiques, mesures) permettant de répondre à différentes questions sur le fonctionnement de notre système. Chacun de ces éléments de monitoring permet de répondre à une question. Les réponses vont nous permettre de naviguer sur le parcours. (Figure 2)
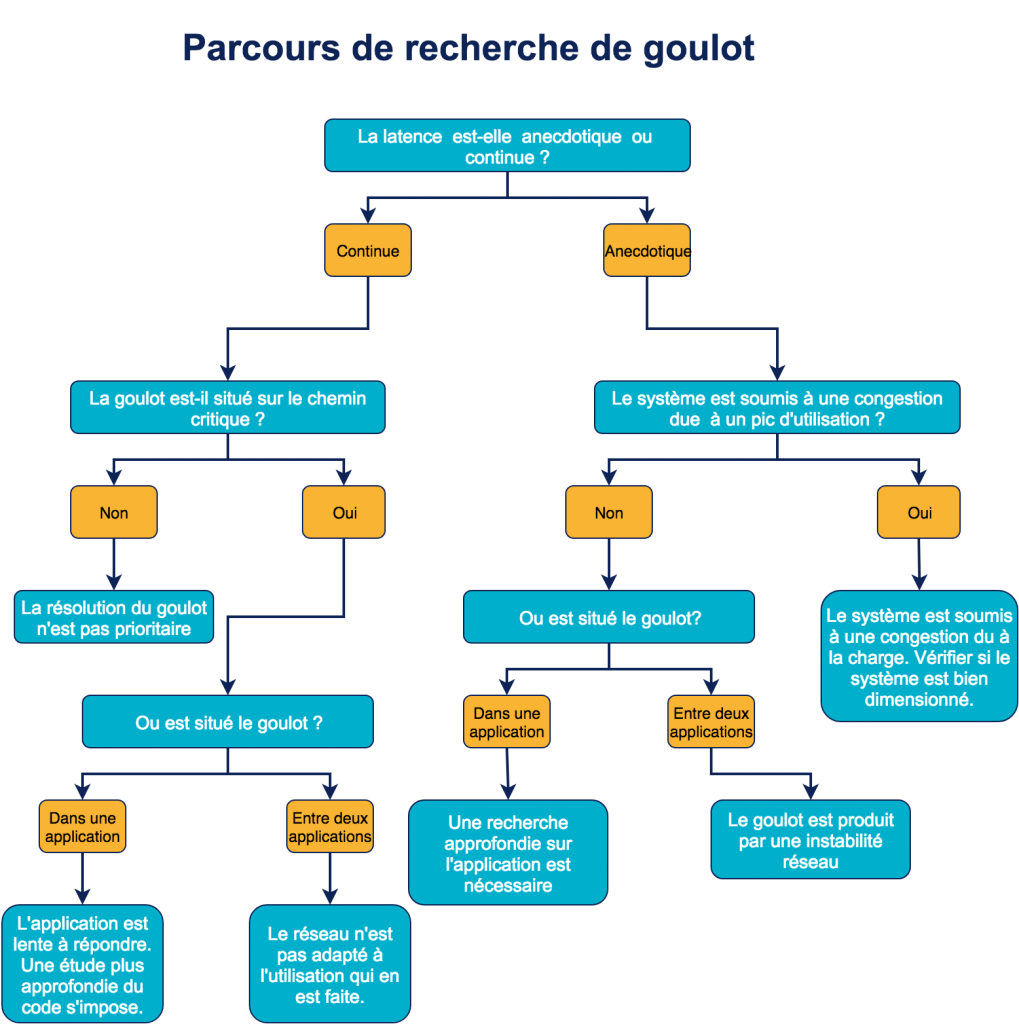
La latence est-elle anecdotique ou continue ?
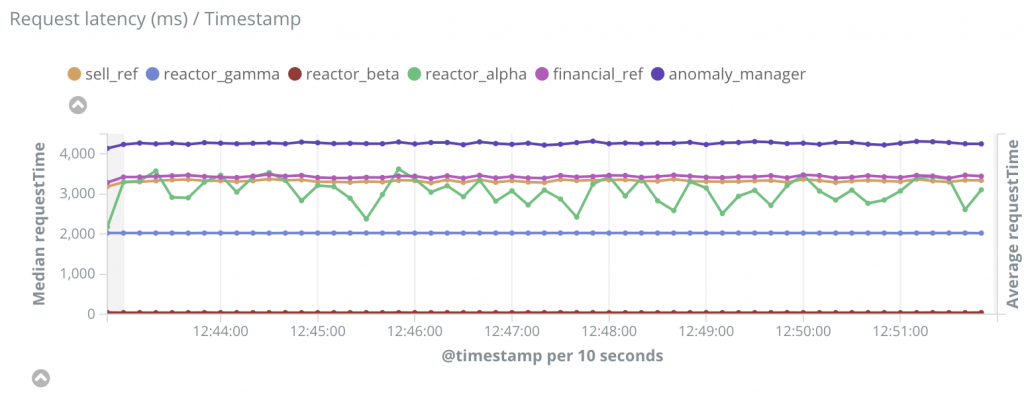
Deux graphiques permettent de repérer aisément les pics de latences. Le premier compare le temps de réponse des différents services. Le second permet de suivre l’évolution du TTLB.

Comment évolue la latence, est-elle dû au trafic ?
Les deux graphiques de la question précédente ainsi le suivant (Figure 5) permettent de suivre l’évolution du trafic et son impact sur la latence. Ce dernier compte le nombre de requêtes sur chaque service. Ces graphiques permettent de répondre aux questions d’impact du trafic sur la latence des différentes applications. Si la latence reste constante malgré un pic de connexion, on peut dire que sur la période analysée, le trafic n’a pas été responsable de la latence. Dans le cas contraire, nous aurions trouvé une des causes de la latence. On peut ainsi déduire la localisation de la latence en fonction des pics remontés par les différents services.

Quel est le profil d’un appel, quel est son chemin critique ?
Une étude des journaux générés par un appel à l’application cible (dans notre cas le tableau de bord énergie) permet de déterminer l’ordre d’appel des applications ainsi que le chemin critique. Il est composé des requêtes bloquantes, c’est-à-dire des requêtes bloquant l’exécution tant qu’elles ne sont pas résolues.
Les éléments suivants ont été générés en filtrant les requêtes par identifiant de corrélation, un header qui est transmis aux acteurs d’un même appel. Cet article décrit leur fonctionnement : https://blog.octo.com/present-et-avenir-du-monitoring-de-flux/.
Attention, les timestamp générés par une même machine (type) sont nécessairement ordonnés. Par contre, les horloges entre différentes machines sont synchronisées par NTP, ce niveau de synchronisation ne garantit pas l'ordonnancement des entrées de journaux entre les hôtes. L’analyse du tableau suivant doit prendre en compte cette limitation.
De plus, ce tableau ne présente qu’un seul appel au tableau de bord, il ne peut être généralisable que si les valeurs sont proches des valeurs médianes.
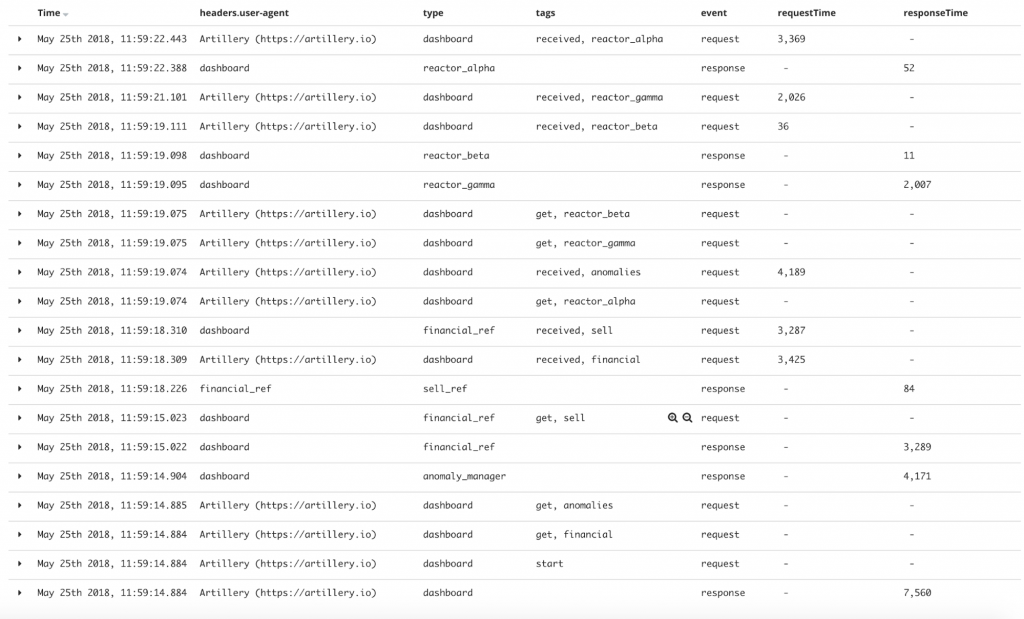
Les tags get et received sont ajoutés à une entrée de journal lorsqu’un service en appelle un autre puis lorsqu’il reçoit le dernier octet d’une requête.
Où sont situés les goulots ?
Avec les temps de réponse et les TTLB sur chacun des services, il est maintenant possible de connaître la localisation exacte des goulots. À l’aide des deux graphiques, nous pouvons corréler ces métriques en les classant par latence décroissante. Seules les plus grandes latences nécessitent d’être affichées sur ce tableau de bord.


Une fois classé, on peut situer les goulots en raisonnant étape par étape. On prend le service qui a le temps de réponse le plus important, situé sur le chemin critique, puis on prend le temps pris par chacune de ses requêtes. Pour chaque requête, on calcule l’écart entre le temps de la requête et le temps de réponse du service. On en déduit la présence ou non d’un goulot. Si le goulot est sur le chemin critique, le corriger aura un impact direct sur la latence globale. On recommence pour le service suivant.
Il peut y avoir deux types principaux de goulots :
- Des latences réseau entre les services : TTLB - temps de réponse
- Des latences dues à un temps passé à l’intérieur des services : temps de réponse - somme du TTLB des requêtes critiques. Les requêtes critiques étant les requêtes qui font attendre l’application.
Mise en application sur Atomenergy
Les courbes ne montrent aucun pic de latences ni aucun pic d’utilisation, il s’agit d’une latence continue. On peut donc immédiatement passer à la recherche du chemin critique.
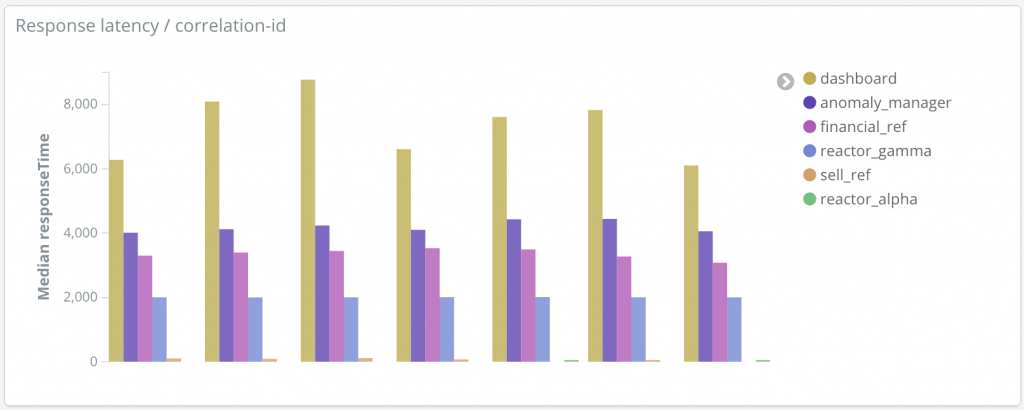
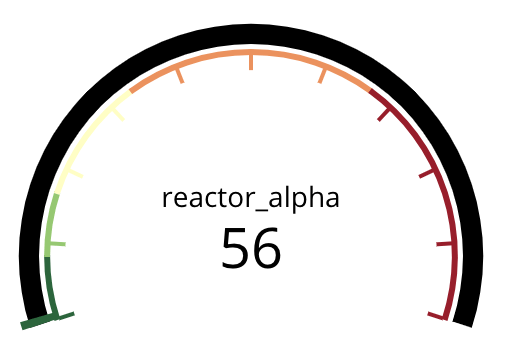
Dans notre cas, le tableau de bord a pris 7, 369 s pour répondre. On remarque deux événements avec le tag « received » (voir figure 13) qui montre le chemin critique pour la construction du tableau de bord. Le premier est immédiatement suivi de trois « get » est le « received anomalies ». On en déduit que le service attend la réponse de « l’anomalie manager » pour appeler les trois réacteurs. De le réacteur le plus long à répondre est le réacteur alpha (Figure 6). En additionnant les deux « request time » critiques, on obtient à peu près le temps de réponse du tableau de bord (7, 3s ≈ 4,2 s + 3 s = 7, 2 s)
 |  |  |
| Temps de réponse du tableau de bord | TTLB du référentiel d’anomalie | TTLB du gestionnaire du réacteur alpha |
Dans notre cas, le tableau de bord a pris 7, 369 s pour répondre. On remarque deux événements avec le tag « received » (voir figure 13) qui montre le chemin critique pour la construction du tableau de bord. Le premier est immédiatement suivi de trois « get » est le « received anomalies ». On en déduit que le service attend la réponse de « l’anomalie manager » pour appeler les trois réacteurs. De le réacteur le plus long à répondre est le réacteur alpha (Figure 6). En additionnant les deux « request time » critiques, on obtient à peu près le temps de réponse du tableau de bord (7, 3s ≈ 4,2 s + 3 s = 7, 2 s)
 |  |
| Temps de réponse du référentiel d’anomalie | Temps de réponse du gestionnaire du réacteur alpha |
Le chemin critique d’intégration du tableau de bord comprend donc le gestionnaire d’anomalie et le réacteur alpha. Il ne reste plus qu’à trouver les goulots sur ces deux services pour réduire la latence.
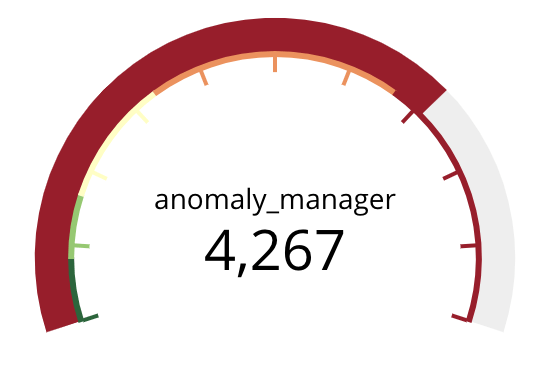
Les journaux du tableau de bord indiquent que le gestionnaire d’anomalie met 4,27 secondes à lui répondre (TTLB). Les journaux du gestionnaire d’anomalie indique qu’il met 4,25 secondes de calcul. On peut en déduire qu’il n’y a pas ou peu de latence réseau entre le tableau de bord et le gestionnaire d’anomalie : moins de 30 ms. Par contre, le gestionnaire d’anomalie met un long temps pour répondre, nous avons détecté un premier goulot applicatif.
En répétant le processus, on obtient les goulots suivant :
- Un goulot applicatif au niveau du gestionnaire d’anomalie ;
- Un goulot applicatif au niveau du référentiel de vente ;
- Un goulot généré par le réseau entre le tableau de bord et le gestionnaire du réacteur alpha ;
- Un goulot applicatif au niveau du gestionnaire du réacteur gamma.
Les deux goulots prioritaires, rappelons-le, sont ceux situés dans l’application du gestionnaire d’anomalie ainsi que celui situé dans le réseau entre le tableau de bord et le gestionnaire du réacteur alpha, car ils sont situés sur le chemin critique.
L’article se concentre sur la détection des goulots et non la façon de les corriger pour cette raison, nous imaginerons l’histoire suivante.
Une étude approfondie du code du gestionnaire d’anomalie a permis de découvrir une fonction particulièrement lente à exécuter. Du côté du réseau vers le réacteur alpha, une erreur de configuration a été résolue.

La correction de ces goulots a largement réduit le temps de chargement du tableau de bord. Néanmoins, un nouveau chemin critique est apparu et il reste deux goulots dans notre application. Atomenergy a réussi à mettre en place un outil efficace permettant le repérage des goulots dans son système d’information.
Recap
Lors de la mise en œuvre de l’observabilité chez Atomenergy les éléments suivant ont été mis en place :
- Entrées de journaux au format JSON ;
- Ajout d'événements à toutes les entrées/sorties des applications ;
- Ajout de user-agent et d’identifiants de corrélation dans les en-tête des requêtes ;
- Agrégation des journaux via l’identifiant de corrélation afin de calculer les latences ;
- Déploiement d’une stack ELK ;
- Construction d’un tableau de bord adapté à la découverte des goulots.
Le mot de la fin
Les outils mis en place pour l’observabilité de notre SI permettent de faciliter la résolution des goulots en apportant des informations sur leur localisation et leur cause. À travers cet article, j’ai défendu l’idée que l’observabilité n’est pas forcément coûteuse à mettre en place si l’on connaît le besoin auquel on cherche à répondre, mais qu’elle permet de répondre précisément et factuellement à un problème.
Pour rappel, différentes méthodologies existent pour l’analyse de performance et la correction des erreurs. Elles prennent la forme des trois méthodes déclinables suivantes :
- La méthode USE pour (Utilization—Saturation—Errors) ;
- La méthode RED (Rate—Errors—Duration)
- Les Golden Signals (Latency— Traffic— Errors— Saturations)
Aujourd’hui, il existe des solutions industrialisables pour suivre la trace d’un appel au sein d’un SI. Ces solutions de trace distribuées comme openTracing.io ou Jaeger.io permettent de marquer puis d’analyser une requête sans toucher au code en effectuant des injections de dépendances. Ces pratiques de tracing font partie des techniques d’APM (Application Performance Management) qui permettent l’analyse de la performance et de la disponibilité d’application distribuée. Même si ces solutions peuvent être très performantes, restons attentifs à ces deux éléments :
- Ces solutions sont invasives, car elles modifient le code pendant la période d’exécution ce qui peut être un risque pour la sécurité et la stabilité de nos applications.
- Ces solutions ne sont pas magiques, elles ne doivent pas être la solution miracle pour soulager des douleurs de communication au sein de nos organisations. N’utilisons pas des solutions techniques pour résoudre nos problèmes d’organisation.
Cet article en deux parties était le second de la série dédiée au thème de l’observabilité dans les systèmes d’information. Le premier, « Décommissionner sans paniquer » traite d’une banque qui cherche à décommissionner son monolithe applicatif. Dans ce contexte, l’observabilité a permis d’effectuer un suivi précis de la migration tout en facilitant la découverte d’éventuelles difficultés. L’article est disponible à l’adresse suivante :
https://blog.octo.com/decommissionner-sans-paniquer/.

Avec la participation de la tribu ARCHI