Bouchons applicatifs (Partie 1)
Centralisation des journaux d’événements

Il arrive régulièrement, dans nos quotidiens, de perdre du temps dans les transports que ce soit dans notre voiture ou dans les transports en commun, cela à cause de « bouchons ». Ces derniers sont causés par un ensemble de facteurs comme des travaux, un accident, une grève ou tout simplement une incapacité à gérer la densité du trafic. Quand on observe attentivement ces causes, on remarque qu’elles génèrent des ralentissements, car elles forment des goulots comme des rétrécissements ou des fermetures de voies.
Un système d’information est de même composé d’un ensemble de voies qui permettent le transport de nos informations. En fonction du trafic et de divers incidents, la circulation sur ces voies peut être altérée pouvant provoquer des ralentissements. On appelle cela de la latence. Les systèmes d’information sont complexes et le manque de sondes dans ces derniers rendent la découverte des causes de ces bouchons difficile.
Un tableau de bord métier dans les bouchons
Atomenergy est une entreprise fictive gestionnaire de centrales nucléaires. Afin de contrôler sa rentabilité, elle possède une application de pilotage qui permet de suivre en temps réel l’évolution des résultats autant techniques que financiers. Après deux années de développement, une douleur importante apparaît, l’application prend de longues secondes avant de se lancer.
Cette douleur provoque un abandon de l’application par une partie du personnel des centrales. Un questionnaire montre que ⅘ des employés ont abandonnés l’utilisation du tableau de bord. Cet abandon provoque une diminution de coordination entre les équipes et donc une baisse des revenus à cause du manque d’efficience.
Nous avons été missionnés pour trouver ces goulots et mettre en place des pratiques afin de repérer à l’avenir des goulots qui pourraient se former. Nous verrons à travers cette suite d’articles comment quelques actions permettent d’obtenir un niveau d’observabilité suffisant pour déterminer la localisation et la cause de ces goulots.

La démarche sera séparée en trois étapes :
Etat des lieux
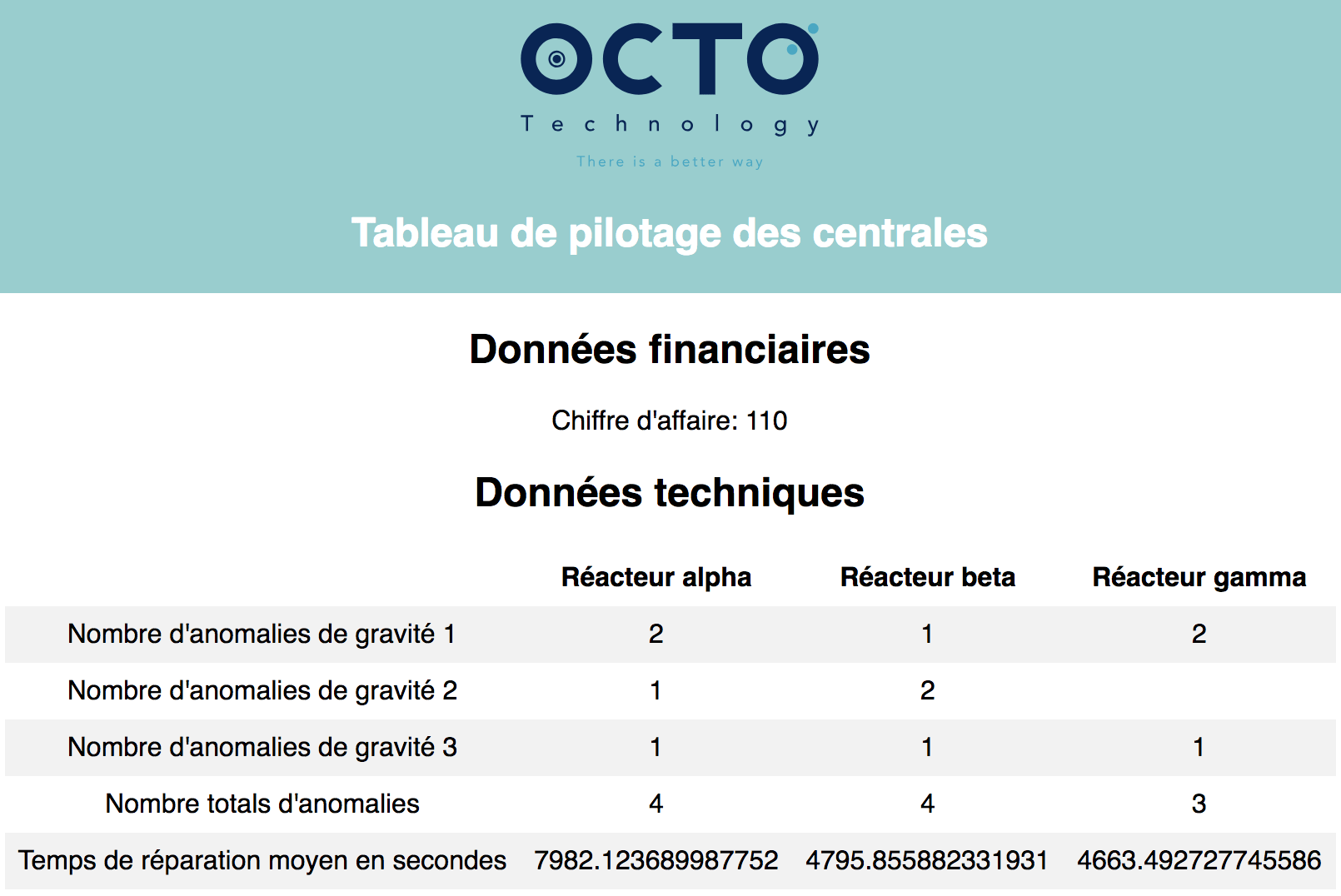
Le tableau de bord énergie permet le pilotage d’une centrale en rassemblant des données métier issu des services de ventes et des données techniques issues des composants de la centrale. Les données à intégrer proviennent donc de différents services.
Lors du lancement du tableau de bord, on observe une attente de 8 à 10 secondes avant son chargement.

Une fois chargé, le tableau de bord affiche des données :
- Le chiffre d’affaires généré au cours de la période sélectionnée, calculé à partir du prix de l’énergie et de la quantité vendue ;
- Le nombre d’anomalies détectées ainsi que le temps de réparation pour les plus critiques d’entre elles.
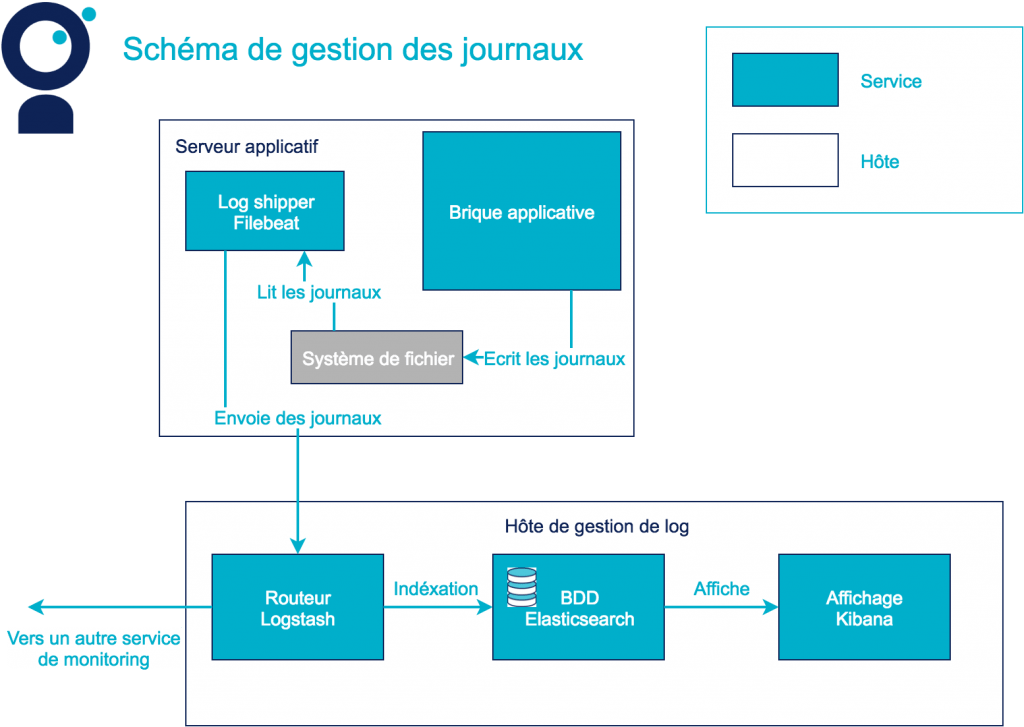
Aucune mécanique de centralisation des journaux n’a été mise en place lors du développement de l’application. Il y a seulement des journaux d’accès générés par les proxys et les briques applicatives de l’application de pilotage. Ces journaux sont stockés sur chacune des machines hébergeant les différents services. Les exploitants vont les remonter à la main par connexion SSH lorsque quelqu’un les demande. Cette demande peut prendre plusieurs jours. Malgré le manque d’outillage pour le monitoring, un schéma d’architecture est disponible dans la documentation du système.

Le tableau de bord énergie fédère des données de plusieurs applications. Le système est composé de 7 briques applicatives :
- Un tableau de bord qui intègre toutes les informations ;
- Un référentiel finances qui récupère les ventes et calcule les données financières ;
- Un référentiel de ventes qui archive l’ensemble des ventes ;
- Un référentiel d’anomalies qui archive les journaux d’anomalies envoyés par les réacteurs ;
- Trois gestionnaires de réacteurs qui génèrent les journaux anomalies et conservent l’historique des versions des logiciels et les correctifs réalisés.
Centralisation des journaux

Une des solutions pour rendre le système observable, dans le cas de recherche de latence, est d’agréger les journaux. Pour cela, nous devons les centraliser. Une fois indexés, ces derniers permettront d’intégrer les différents événements analysés des briques applicatives.

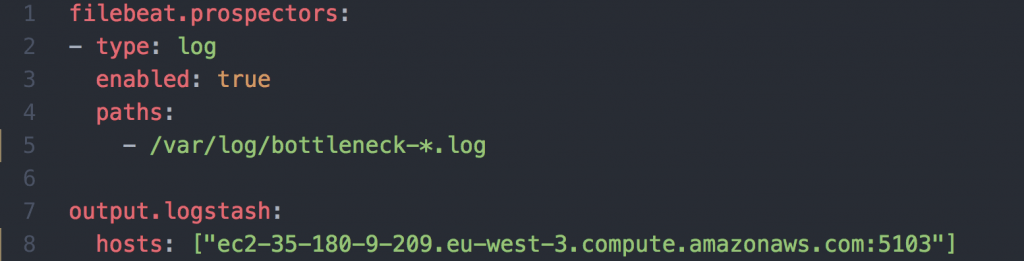
J’ai choisi d’utiliser la stack ELK (Elasticsearch LogStash Kibana) pour la centralisation des journaux. Un agent présent sur chaque brique récupère ces derniers, générés au format JSON (Figure 4) par l’application puis les envoie à Logstash. Dans la configuration suivante, l’agent Filebeat s’abonne aux fichiers de log de type bottleneck-*.log contenu dans /var/log. Il envoie ensuite l’ensemble des fichiers à Logstash au fur à mesure qu’ils sont écrits par l’application.
Logstash distribue ensuite les journaux en fonction des besoins. Dans notre cas, nous conserverons tous les journaux permettant de calculer des latences. Ces derniers sont filtrés à l’aide d’un tag spécifique. Ils sont ensuite envoyés à Elasticsearch pour être indexés. Kibana permet enfin de visualiser sous différentes formes les métriques calculées à partir des événements indexés.
Avant de commencer la recherche des goulots, la validation de l’architecture est nécessaire. En effet, définir les causes des ralentissements peut être difficile si la carte initiale est fausse. Après avoir identifié chaque brique en ajoutant un identifiant dans l’en-tête de requête (Figure 6: user-agent), une première analyse permet de confirmer l’architecture proposée par la documentation. Les journaux d’accès suivants ont été générés après une requête sur le tableau de bord depuis un navigateur.
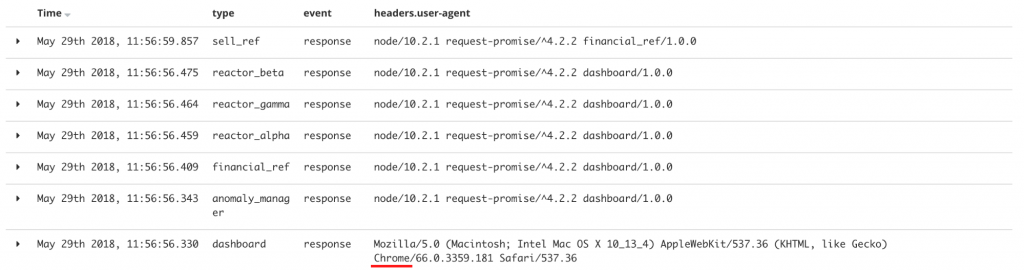
Le tableau de bord est ouvert grâce au navigateur Chrome. On observe que les appels sont tels que décrits sur le schéma d’architecture (Figure 3).
Dans le prochain article, nous partirons à la recherche des goulots à l’aide des journaux que nous avons réussi à centraliser.
La suite est disponible au lien suivant:
https://blog.octo.com/bouchons-applicatifs-partie-2/

Avec la participation de la tribu ARCHI