Bonne nouvelle : L’Infra As Code c’est du code !
La notion d'Infra As Code consiste à voir l’infrastructure comme un asset logiciel classique. Bonne nouvelle, on va pouvoir reprendre des pratiques liées au code de la Programmation Orientée Objet.
Dans cet article nous allons nous intéresser à une de ces pratiques : l'abstraction. Il s’agit de séparer la mise en oeuvre technique bas niveau de son utilisation faite à plus haut niveau.
Votre objectif en construisant des abstractions doit être le même : masquer la complexité pour être le plus largement et le plus facilement utilisé ! Tout l’art réside dans le bon dosage : un composant sans complexité ne nécessite pas d’abstraction.
Adopter cet état d’esprit aide plus que n’importe quelle formation théorique pour construire des abstractions efficaces.
Pourquoi investir dans des abstractions ?
Assurer le développement des parties complexes par les experts
Personne n’est expert en tout, mais il existe toujours au moins un référent par technologie dans chaque entreprise.
Ces référents ne se multiplient pas et ne peuvent participer à tous les projets (Brent dans The Phoenix Project) : nous sommes convaincus que ces personnes peuvent faciliter l’accès à leur expertise en développant des couches d’abstraction adaptées au contexte de l’entreprise.
Réutiliser les implémentations pour différents projets
L’accès et l'adhésion à ces abstractions sont les clés de la réutilisabilité. Une belle abstraction qui n’a jamais été utilisée car incomprise ou inadaptée a une valeur métier proche du néant. Et ce, bien que l’abstraction en elle-même soit élégante d’un point de vue expertise technique et de code. Ce que l’on décrit ici peut se transposer à l’utilisation de librairies dans le monde Open Source.
Pourquoi rest-client ou httparty dans le monde Ruby sont plus souvent utilisés pour appeler des services Rest que Net::HTTP pourtant natif ? Au-delà d’être de bonnes abstractions, celles-ci sont populaires et bien documentées : nous avons accès au code source pour debugger d'éventuels comportements étranges, et il est possible de les enrichir ou de corriger des bugs à travers des Pull Requests.
Les différents niveaux d’abstraction
Dans l’environnement des outils de gestion de configuration, on retrouve . 2 niveaux d’abstractions de base : Ressource et Module, ce dernier peut être affiné en deux sous parties : le module expert, le module métier.
La ressource : l’unité de base
La ressource est le niveau d’abstraction le plus bas, c’est celle qui est le plus proche de l’action réellement effectuée sur le serveur cible. On peut la comparer aux fonctions de base d’un langage.
Le pattern Ressource nous permet de passer d’une logique d’action à une logique d’état désiré. C’est l’application de ce pattern qui nous permet d’assurer l’idempotence de notre code assez facilement.
Par exemple, nous souhaitons rajouter une entrée dans le fichier /etc/hosts de notre serveur.
En Shell, pour ajouter une entrée nous pouvons faire :
echo "127.0.0.1 localhost" >> /etc/hosts
Si nous voulons rendre cette action idempotente, on peut essayer :
if (!grep -q 127.0.0.1 /etc/hosts); then echo "127.0.0.1 localhost" >> /etc/hosts; fi
Et en puppet :
host { 'localhost': ip => '127.0.0.1', }
Quel type de code souhaitez vous maintenir?
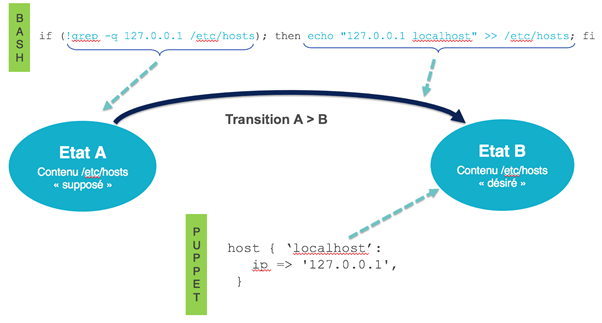
Lorsque l’on fait du Shell il est nécessaire de regarder le delta par rapport à la cible et en fonction de cela, nous effectuons la transition. La commande Shell présentée, semble gérer le delta correctement, mais on peut trouver des cas où l’état préalable n’est pas géré (127.0.0.1 est présent mais n'est pas associé à localhost). Les gérer vaut-il la peine de complexifier le code ?
Dans le cas de Puppet, le pattern Ressource nous permet de spécifier directement l’état cible et c’est l’outil qui nous masque la transition.
L’usage du pattern Ressource présente l'intérêt qu’il s’intéresse à l’état désiré en masquant la constellation d’états de départ potentiellement infini.
Module expert : masquer la complexité d’une brique technique
L’écriture de ce module nécessite une connaissance intime de la brique manipulée. Mais elle nécessite également une bonne connaissance de l’outil de gestion de configuration afin de l’utiliser au mieux et de ne pas enchaîner des commandes Shell bas niveau.
Celui-ci connaît et gère par exemple : la syntaxe et l’emplacement des fichiers de configuration, le processus de déploiement, la validité des versions, les différents comportements entre versions et OS, le chemin vers les binaires...
De plus, il expose une interface d’entrée simplifiée : on peut notamment y retrouver des flags de feature flipping.
Module métier : intégrer nos besoins spécifiques
Il assure la corrélation entre le besoins besoins spécifiques au projet/contexte métier et l’appel aux modules experts. Nous allons donc retrouver des appels à de multiples modules experts, mais aussi la définition de variables métiers ou connexes à l’organisation.
Il faut faire attention à ce que l’on mets derrière le mot "métier" : on ne parle pas ici de transposer des règles métier liée à l’entreprise dans le code d’infrastructure. On parle de toutes les pratiques internes liées à l’usage de l’infrastructure : un module métier peut être un module qui exploite un module expert tomcat et un module expert logstash pour en faire un tomcat configuré dans le contexte de production avec la tuyauterie de collecte de log. Par nature, ce type de module est spécifique au contexte de l'entreprise.
Ces modules métier ne connaissent ni l’emplacement des fichiers de configuration, ni aucun composant technique précis. Cela lui est abstrait par le module expert.
Si nous voulons installer un MySQL avec Puppet, nous utiliserons un module expert (ici, issu de la communauté) puis dans le module métier nous le référencerons :
class { '::mysql::server': root_password => 'strongpassword', remove_default_accounts => true, }
Nous indiquons au module expert un nouveau mot de passe root et la suppression des comptes par défaut. À lui de savoir installer MySQL.
Il est écrit par un développeur connaissant les spécificités métiers (organisation, utilisation du produit, manière d’exploiter...). Il n’a pas besoin d’être expert sur le produit installé mais doit comprendre l’interface offerte par le module expert.
Correspondance des concepts
Ces trois niveaux peuvent se transposer dans les différents outils de management de configuration mais aussi avec la Programmation Orientée Objet.
| Programmation Objet | Shell | Puppet | Ansible | |
| Ressource | Fonction de base d’un langage | Fonction complexe | Ressource | Module |
| Module expert | Interface | Fonction qui appelle des fonctions “Ressource” | Module (principalement issu de la communauté) | Role (principalement issu de la communauté) |
| Module métier | Consommation de l’interface | Script | Profile (privé) | Role/Playbook (privé) |
Wrap up
L’approche ne doit pas être confondue avec la simple automatisation de l’existant. La construction de ces abstractions sera plus complexe avec certains outils graphiques, langages propriétaires simplistes et autres outils orientés “automatisation de l’existant”.
Ces outils limités ne permettent pas de construire des abstractions, de réaliser des diffs, de faire du dry-run, ou de travailler de manière collaborative. Ils ne sont pas dans la mouvance Infra As Code mais dans une logique d’automatisation de processus ad-hoc.
Les outils dans cette mouvance d’Infra As Code nécessitent de refaire tout ce qui à été développé dans le passé et de revoir les processus d’automatisation souvent obsolètes et pauvres. Cela prend du temps et demande un investissement initial mais c’est nécessaire !
Avec cette approche nous serons en mesure de reprendre bien d’autres patterns éprouvés issus du monde logiciel : refactoring, clean code, usines de développements, tests automatisés, pratiques organisationnelles liées à l’agile et au software craftsmanship … Ils permettent de garantir la maintenabilité et la qualité du code. L’infra As Code va bien au-delà d’un “yum install” dans un script !