Big data : some myths
At my hairdresser’s, on the coffee table, I came across one of those hype men's magazines with a model on the cover and the promise to learn how to avoid 10 common mistakes when wearing a tie. I accidentally open the page 34: "The Big Data revolution."

The subject continues to spread widely, particularly among the neophyte public, which annoys many people. Each success has its criticism ... One can legitimately ask how the public comes to understand big data. Among simplistic journalists, embittered experts irritated by the abuse of the term and sellers who promise miracles, it is not easy to navigate. I will try in this article to dismantle some myths and redefine the term.
Big Data = Big Brother
This shot is a real public enemy. No, I do not work for the NSA and no, I won't fraudulently make use of your personal data! What is Big Data?
- A cultural and technological phenomenon at the origin of an exponential accumulation of data within our Information systems. We share, communicate and produce data, more and more, all the time and everywhere.
- Infrastructures, technologies and statistical methods to massively analyze data
- The observation regarding the amount of data produced, global human brain mass will not be able to analyze everything. Hence, the importance of Datascience, machine learning and artificial intelligence to transform, in an automated way, this ocean of data into information, or better, into knowledge.
Phenomenons have no moral inclination. No more than tools or technologies. Data analysis has always existed. As well as the creation of personal information files. Big Data application’s primary concerns are health services improvement, energy consumption optimization and reduction (smart metering, smart city), user experience improvement, human knowledge sharing, fights against bank fraud, open data and the idea of transparency…
Big Data = Hadoop

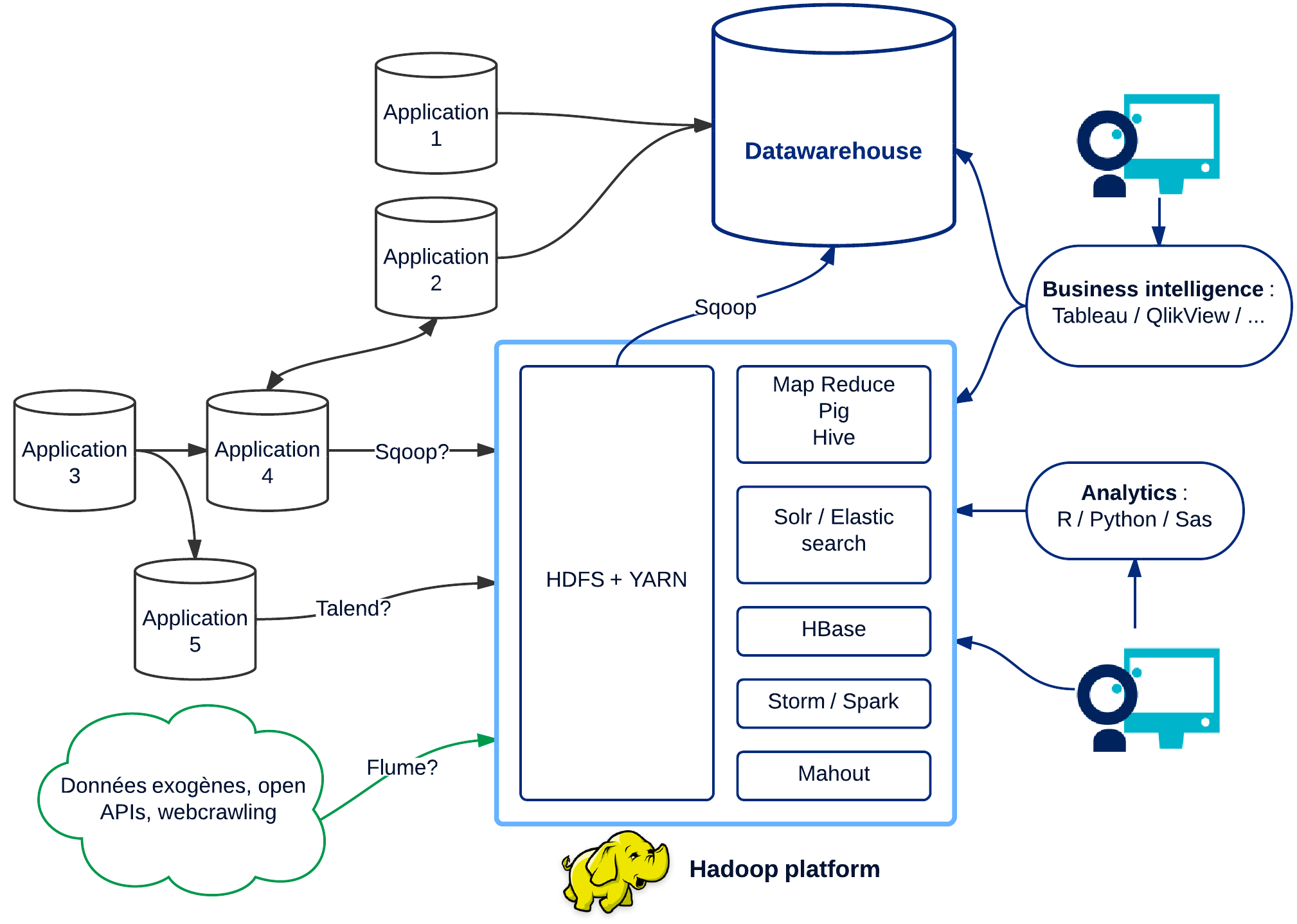
Yes, Hadoop and its ecosystem represent a major player and an incredibly rich tool. However, its usefulness and its role are often misunderstood. Hadoop does not replace the Datawarehouse. Hadoop is not originally made to perform interactive query but large efficient batch processing. Hadoop is not intended to deliver reporting to end-users below the millisecond. Hadoop is not made for real-time stream processing.
It is for this reason that distributions such as Hortonworks expended themselves with various other projects like HBase, Solr or Storm. To understand Hadoop, we have to pay attention to user-patterns and data access. What do we need?
- Perform full scans of my data to compute aggregation, indicators -> MapReduce, Hive, Pig.
- Store large amounts of data in a format that can instantly query a specific object -> HBase
- Process data streams with minimal latencies and large volumes -> Storm
- Analyze or index text documents -> Solr, ElasticSearch
- Train predictive models by learning -> Mahout, H20
In fact, this ecosystem draws its power from its capacity to make atomic data and distribute across several machines what traditional databases try to do alone:
- Indexing
- Transactions
- Low latency/interactive querying
- Full scan / aggregations computing
- Multi-tenancy
We must not see Hadoop as a miracle solution but as a complex bundle of heterogeneous solutions targeting use cases and various access patterns:
Finally, Big Data is not just about large data processing, but their exploitation through sophisticated statistical methods and particularly through machine learning! We must admit Hadoop has a lack of maturity about this subject either regarding Mahout, or R connector or Python that does not actually allow to distribute algorithms. Besides, below the Tera, or even more, you can get away with a bit more of good will without Hadoop with postgesSQL and Python Pandas! We even talk about “Small Data”…
Big Data = Large Data Volumes
No! We actually just saw the complexity of the problem in dealing with access pattern.
Big Data = Volume, Velocity, Variety?
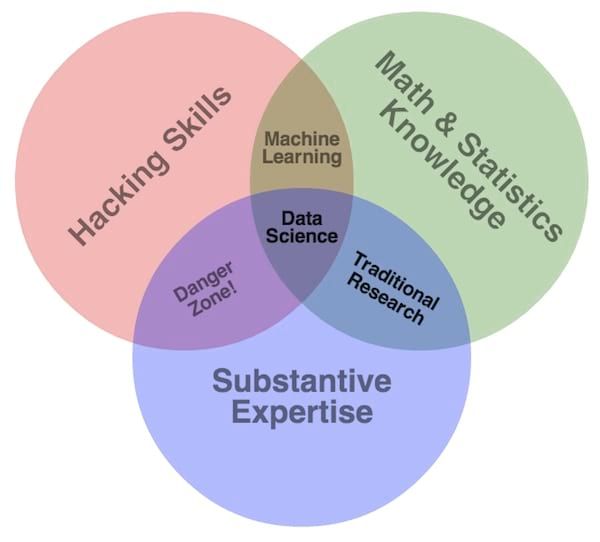
That is better, but the most interesting part dwells in the conjunction between the analytic and the abundance of data that we have at our disposal. Big Data must not be an IT topic, but targeting use-cases and business issue. Too many companies take on Big Data initiative by setting up a Hadoop cluster. Besides, three skills are usually needed to carry out a datascience project and they are not limited to IT:
Big data = unstructured data
We talk a lot about unstructured data and the ability of Big Data technologies. To be honest, let us be clear on the fact that except for companies specialized in the media, most of the data is structured (tables, fields, columns, rows, dates). Within the leftovers, can be attributed much of the free text. To finish? A minority of videos, pictures, sound files. These data are less structured but still possess formats, more or less unified. It would actually be better to speak of multi-structure. Big Data does not have smart ways to deal with this heterogeneity except to say: “load first, model second”. Thus, model the data after loading, if necessary.
Besides, the marketing people are targeting this heterogeneity of formats issue for years. However, tools related to search allow to greatly simplify the use of poorly structured data and methods for process these formats which have been unified (Apache Tika is an example).
Finally, there is a floor to exceed below which it is very complex to analyze at low cost video, data, sound, picture or free text.
Big data = analyze social networks and perform feeling analysis
Analyze social networks data can be very interesting but remains complex and often inapplicable/uninteresting for a large number of business. The main use remaining being analyzing the e-reputation.
Companies’ internal data are already often an untapped gold mine that just satisfy itself with traditional Business Intelligence. A first step would be to transcend multidimensional reporting and reach predictive analysis or unsupervised to detect weak signals.
Yes, this mood paper is full of bias. However, Big Data is a subject in full “Hype” and for which we must be really suspicious towards preachers of good words, gurus and bargainers. Some myths affect in a bad way projects lifecycle, leading towards a negative and erroneous vision. The potential economic benefit related to Big Data has to be studied with care, and driven by the business vision. The investment must be directed and designed more broadly through companies’ digital development to meet specific business needs.