Benchmark des plateformes NLU

Aujourd’hui, de plus en plus de sociétés et de marques décident de s’équiper de chatbots, aussi bien à destination de leurs clients qu’à destination de leurs collaborateurs. Cependant, tous les chatbots ne se valent pas : certains obtiennent de meilleurs résultats que d’autres. La question alors soulevée est : pourquoi est-ce que certains chatbots comprennent, mieux que d’autres, les actions que nous essayons d’effectuer ?
La création d'un chatbot nécessite l'utilisation d'une plateforme composée d'une interface de chat, d'un NLU, d'arbres de dialogue, d'interfaces d'administration, de conception et de supervision. Voici le schéma type du fonctionnement d'un chatbot :
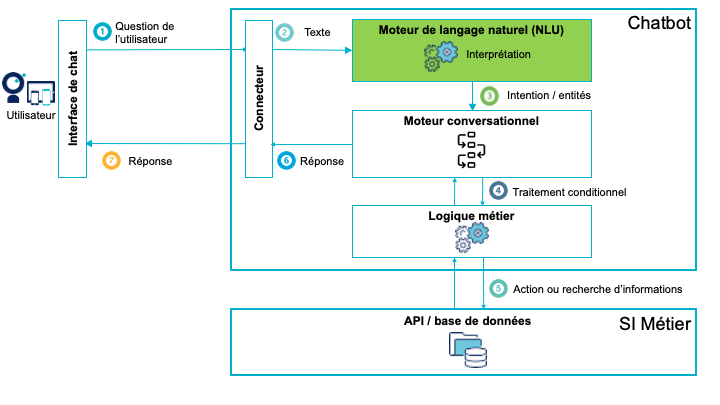
Nous allons essayer d’apporter ici une partie de la réponse. La très grande majorité des chatbots fonctionnent grâce à un moteur de Compréhension du Langage Naturel (Traitement du Langage Naturel, ou NLU en anglais). C’est la brique technologique responsable de la compréhension et de l’interprétation des phrases exprimées par l’utilisateur du chatbot.
Pour faire suite à notre article sur la Comparaison des plateformes de développement de chatbots, nous avons décidé de réaliser un benchmark pour comparer les performances des différentes plateformes. Dans cet article nous nous attacherons uniquement à l'évaluation de la performance du NLU.
1 - Méthode de test
Comment avons-nous fait le benchmark et mesuré les performances des moteurs ?
Pour effectuer le benchmark, nous avons développé une plateforme automatisée qui entraîne, teste et évalue les capacités des moteurs NLU. Son architecture est la suivante :
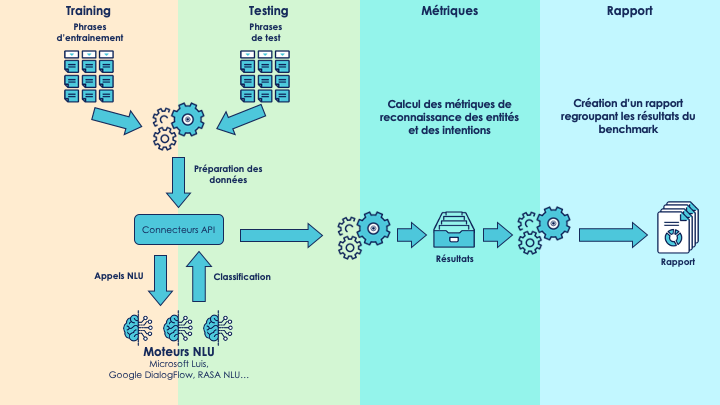
Nos tests ont été réalisés de la manière la plus égalitaire possible, afin d’être certains que nous comparions les moteurs sur les mêmes critères.
Les moteurs de NLU que nous avons choisi de tester sont les suivants :
- LUIS (maintenu par Microsoft)
- Dialogflow (maintenu par Google)
- RASA NLU (open source)
Le fonctionnement de ces moteurs NLU est basé sur du Machine Learning. L'entraînement des moteurs est donc essentiel à leur bon fonctionnement.
Nous avons utilisé le même jeu de données pour tester les moteurs de NLU. Ce jeu de données est composé de phrases en français que nous avons assemblées et annotées pour qu’elles soient utilisables par les moteurs de NLU.
Voici un exemple de ce à quoi ressemble une utterance annotée :

Une fois l'entraînement terminé, nous utilisons de nouvelles phrases pour tester les capacités de reconnaissance des moteurs de NLU. Nous analysons ensuite les résultats de ces tests afin d’obtenir différents graphiques qui comparent les points suivants :
- la qualité de l’extraction des entités
- la qualité de la classification des intentions
- d’autres métriques classiques des modèles de ML (rappel, précision, …)
2 - Explication des résultats
Les graphiques et statistiques présentés ci-dessous représentent les résultats de l’interprétation des phrases fournies au moteur NLU pour réaliser nos tests.
A - La reconnaissance des entités
La première chose que nous avons décidé de tester est la qualité de la reconnaissance des entités par les moteurs NLU. Les mêmes informations sont présentées sous deux formats différents en fonction du niveau de détails souhaité.
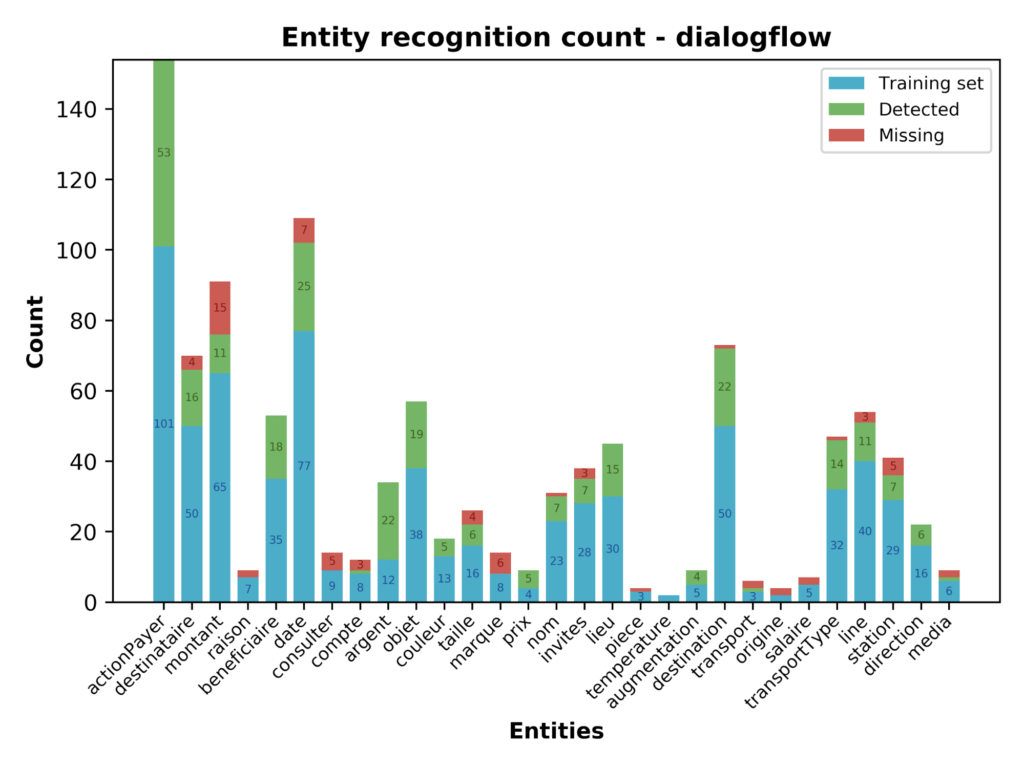
Le premier graphique se présente sous un format de diagrammes en barres. Plusieurs parties sont présentes sur chaque barre :
- la partie bleue correspond au nombre de répétitions de l’entité dans les utterances d'entraînement
- la partie verte correspond au nombre de détections correctes de l’entité lors des tests
- la partie rouge correspond au nombre de fois où il y a eu une erreur lors de la détection d’une entité
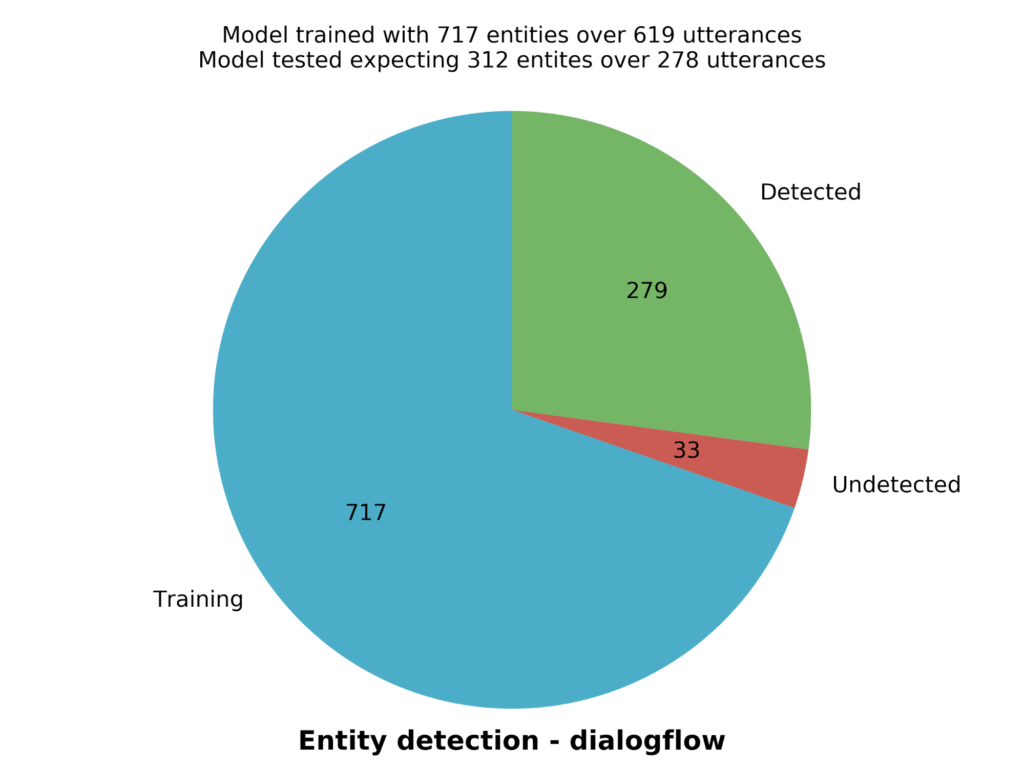
Le second graphique se présente sous la forme d’un diagramme circulaire. C’est une vue plus générale des données qui ont été calculées pour le graphe précédent. Le diagramme se divise en trois parties :
- la partie bleue correspond au nombre total d’entités utilisées pour l'entraînement du modèle
- la partie verte correspond au nombre total d’entités qui ont été correctement reconnues
- la partie rouge correspond au nombre total d’entités pour lesquelles il y a eu une erreur lors des tests
B - La reconnaissance des intentions
La deuxième chose que nous avons décidé de tester est la qualité de la reconnaissance des intentions par les moteurs NLU. Le format de présentation des résultats est le même que pour les entités.
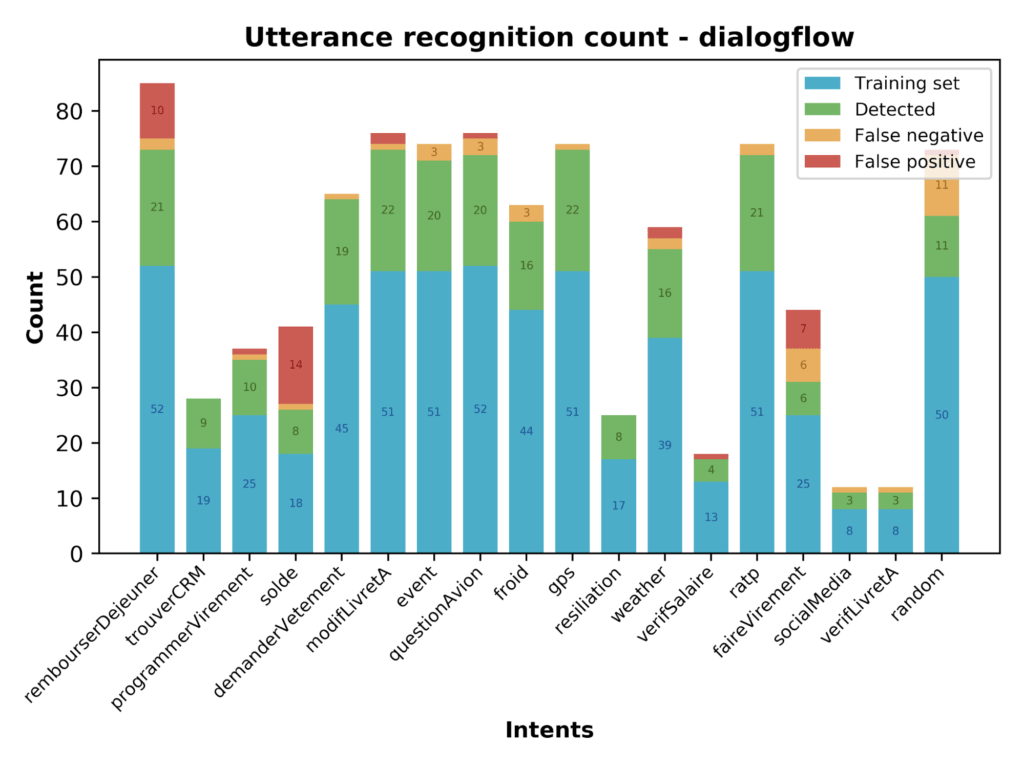
Le premier graphique se présente sous un format de diagrammes en barres. Chaque barre correspond à une intention. Elles sont séparées en plusieurs parties :
- la partie bleue correspond au nombre d’utterances utilisées pendant l’entraînement du modèle
- la partie verte correspond au nombre d’utterances qui ont été classées dans la bonne intention
- la partie jaune correspond aux faux positifs qui sont ressortis lors de la classification des utterances
- la partie rouge correspond aux faux négatifs qui sont ressortis lors de la classification des utterances
Le second graphique se présente sous la forme d’un diagramme circulaire, et représente également une vue d’ensemble des données qui ont été calculées. Le diagramme se divise en trois parties :
- la partie bleue correspond au nombre total d’utterances utilisées lors de l’entraînement du modèle
- la partie verte correspond au nombre d’utterances dont la classification a été correctement réalisée lors de la phase de test
- la partie rouge correspond aux utterances dont l’intention a été incorrectement détectée par le modèle lors de la phase de test
C - La matrice de confusion

Nous avons également choisi de représenter la qualité de la classification des intentions par une matrice de confusion. Les matrices de confusion sont utilisables dans le cadre de l’analyse de tous les modèles d’apprentissage de Machine Learning. Elles sont donc applicables sans problèmes aux moteurs NLU. Les lignes de la matrice correspondent aux résultats obtenus et les colonnes les résultats voulus. Chaque case de la matrice comporte le nombre d'occurrences de chaque cas. Ainsi, plus un moteur aura une matrice proche d’une matrice diagonale, plus cela signifiera qu’il est bon.
D - Le score de confiance
Lors de la reconnaissance d’une phrase, le moteur NLU fournit également un score de confiance par rapport à son résultat. Le graphique qui découle est un histogramme qui montre la répartition de ces scores, tous compris entre 0 et 1.
Certains moteurs NLU auront tendance à avoir des scores de confiance qui sont très répartis sur l’axe des abscisses, alors que dans le cas d’autres moteurs, une différence de 0.05 entre deux reconnaissances sera très significative.
E - Les statistiques de reconnaissance d’intentions
Plusieurs autres métriques sont calculées grâce aux résultats obtenus lors des tests réalisés sur les moteurs NLU. Ces résultats sont présentés sous la forme de diagrammes en forme de barres.
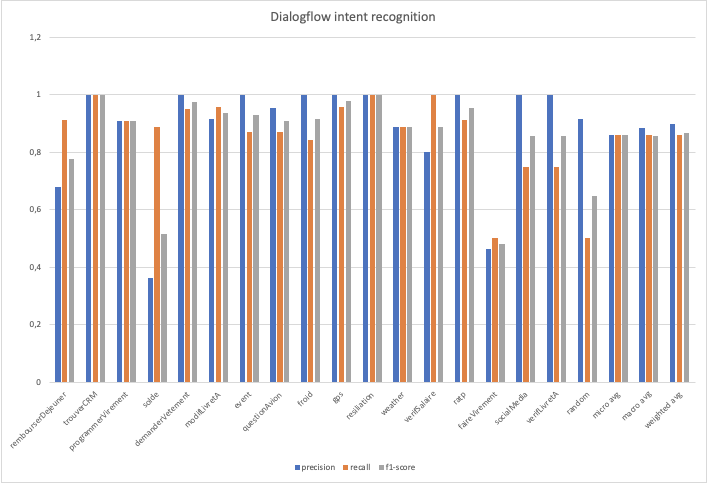
a - Precision
La precision : elle permet de calculer la précision des prédictions du modèle. Elle est calculée grâce à la formule suivante :
b - Recall
Le recall : il permet de calculer le taux de faux positifs dans un modèle. Il est calculé avec la formule suivante :
c - F1 Score
Le f1-score est calculé avec la formule suivante :

Il permet de s’assurer de l’équilibre entre le recall et la précision du modèle.
3 - Résultats et fichier de compte-rendu
Le benchmark que nous avons réalisé a pour vocation de suivre les évolutions qui sont présentées sur les différents moteurs NLU disponibles sur le marché.
C’est pourquoi il sera mis à jour quand des mises à jour importantes auront lieu.
Le détail des résultats de ce benchmark est situé dans un fichier PDF joint à cet article. Des nouveau fichiers seront ajoutés au fur et à mesure de l’évolution des résultats pour vous permettre de suivre leur évolution.
Si vous êtes un éditeur de moteur NLU et que vous souhaitez voir votre moteur dans ce benchmark, contactez-nous et nous verrons comment l’ajouter !
A - Compte-rendu
Le compte rendu complet avec tous les détails et les graphes est disponible dans notre Compte rendu du benchmark NLU au format PDF.
B - Résultats
Le tableau ci-dessous est une comparaison des valeurs obtenues en résultat du benchmark.
Une analyse rapide des résultats nous montre que tous les moteurs ont des performances à peu près égales :
- Dialogflow est le moteur qui a le mieux détecté les différentes entités qui lui ont été présentées
- Luis est le moteur qui a le meilleur résultat au niveau de la classification des intentions
- RASA est le moteur dont le taux de confiance dans ses classifications d’intentions est le plus élevé des trois. Le moteur détecte moins bien les entités que Dialogflow ou Luis, mais se situe entre ces deux moteurs en terme de reconnaissance des intentions.
D’après nos tests, le moteur NLU le plus complet à tous les niveaux semble être Luis.
Cependant, certaines problématiques peuvent faire pencher la balance en faveur d’un autre choix.
Si le besoin principal est la confidentialité, RASA NLU est un moteur open source qui peut être installé on-premise facilement. Le coût sera probablement la nécessité de réaliser un entraînement plus complet.
Si le besoin principal est d’utiliser une plateforme en SaaS, Dialgflow présente le système le plus complet : en plus du moteur NLU, le service propose également de la logique de conversation ainsi que des connecteurs d'intégration.
Luis n'est quant à lui qu'une brique NLU à intégrer dans une solution plus large comme Bot Framework ou Power Virtual Agent.
| Dialogflow | Luis | RASA NLU | |
| Entities | |||
| Detected entities | 279 | 256 | 205 |
| Undetected entities | 33 | 56 | 107 |
| Intents | |||
| Correct intent classification | 239 | 264 | 251 |
| Incorrect intent classification | 39 | 14 | 27 |
| Mean intent classification confidence | 0.76 | 0.9 | 0.92 |
| Intent classification standard deviation | 0.2 | 0.16 | 0.18 |
| Metrics | |||
| Average precision | 0.90 | 0.95 | 0.91 |
| Average recall | 0.86 | 0.95 | 0.90 |
| Average f1-score | 0.87 | 0.95 | 0.90 |
Et pour aller plus loin, vous pouvez évaluer votre stratégie chatbot grâce à notre Quizz sur les bonnes pratiques de création de chatbot.