Batman rises in Monte-Carlo
I had the chance, with Alexis Flaurimont, to speak about the usefulness of parallel programming at Breizh C@mp this year. One of the goals was to demonstrate that parallel programming is a lot easier to code than a couple of years ago.
During the presentation, we used the Monte Carlo method. It is, I must confess, an embarrassingly parallel algorithm. Perfect to demonstrate that parallelization can greatly improve an application performances.
The Monte Carlo method is usually explained by calculating Pi. It consists of calculating statistically something that we can't calculate mathematically. Pi is in fact a bad example since it's more efficient to calculate it using power series. I'll let you read the Wikipedia article for a longer explanation but let just say that the idea is to randomly draw values and decide what they worth. The average worth value of all the draws will approximate the real answer. The more we draw, the closer we are from the real answer.
From where I stand, Pi just ain't no fun. So I picked Batman instead. To calculate the area of the Batman logo to be precise. Much more amusing. I've based my calculation on the Batman equation" that was circling around Internet last year.
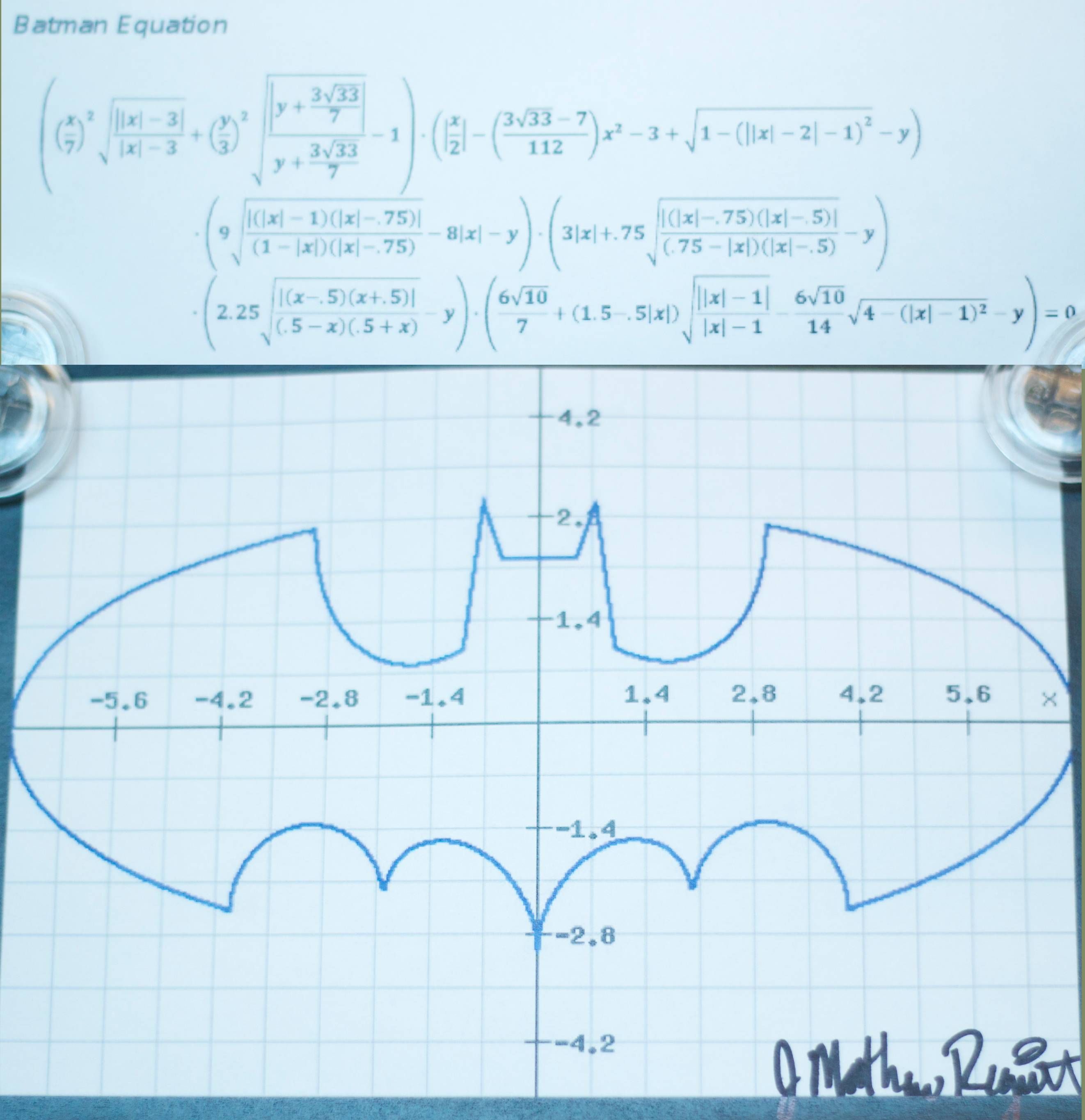{kind=link}
With a lot of minutia and helped by Wolfram Alpha, I've coded it in Java. Please note that the Wolfram Alpha equation is wrong. I'll look at how to tell them without success. If someone knows how, please leave a comment. Here's the fix: 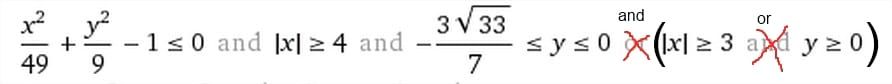
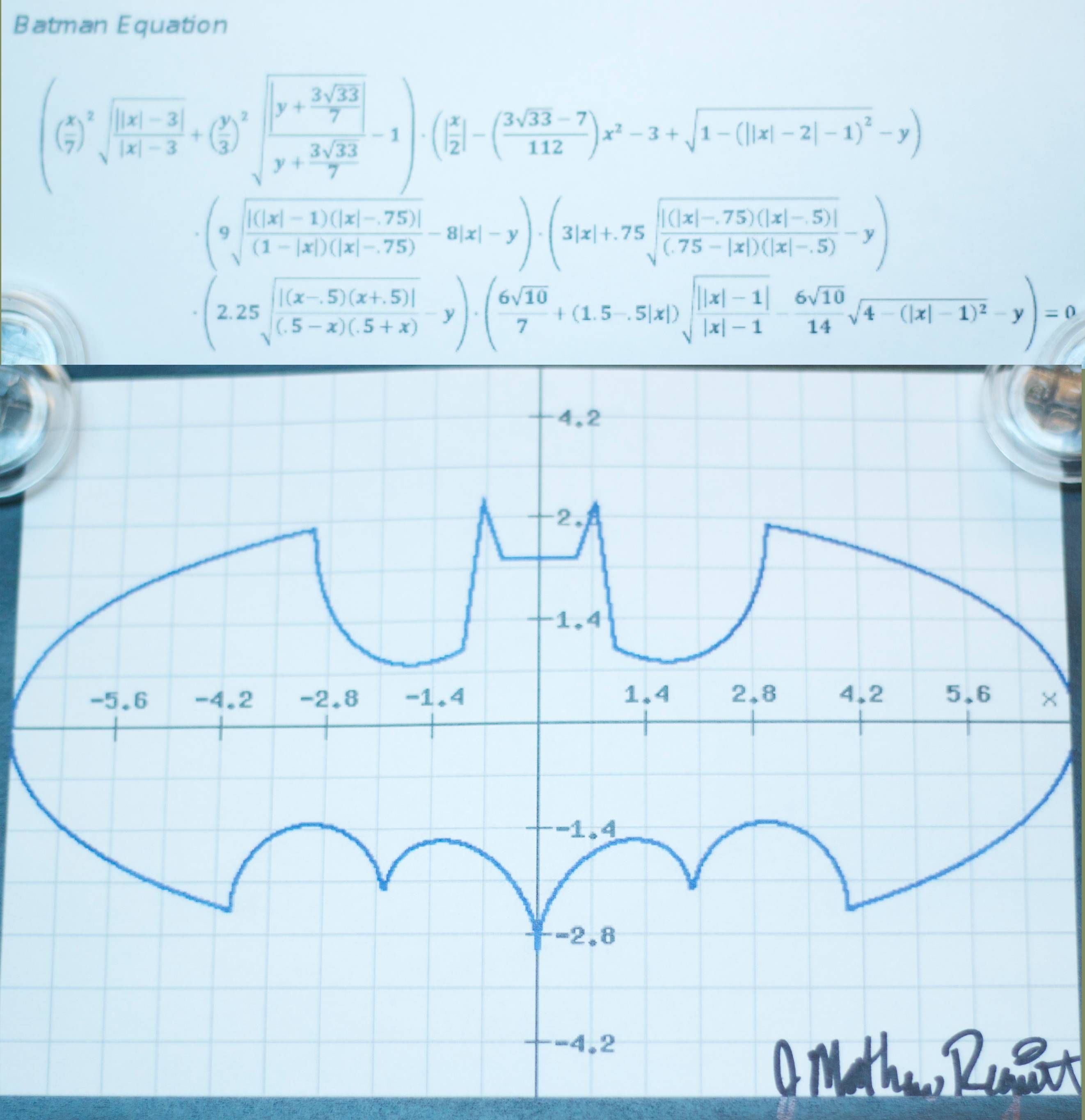
The code is on Github. Visually, it looks like that:
There's also a Pi calculating version, but, since it's just a circle, as I said, it ain't no fun. But useful to test the Monte Carlo implementation. Back to Batman. Quite nice visually, but that was more useful in conference than here. What we want here is to compare the performances. For that, we use a 30 seconds execution of each. The goal is to perform as much draws as we can. I did three implementations:
- Sequential: A loop does on draw after the other
- Parallèle: A ForkJoinPool launch parallel loops on each available CPU
- GPU: Aparapi is used to calculate on the GPU
To give you an idea, here's a snippet of the sequential code:
MonteCarloCalculator calculator = instantiateAlgorithm(constructor, 0);
new MonteCarloCmd(calculator).run();
Quite obvious. We call a calculator that loops. In parallel it's a bit more complex but not much:
ForkJoinPool pool = new ForkJoinPool(); // pool creation
for (int i = 0; i < pool.getParallelism(); i++) {
MonteCarloCalculator calculator = instantiateAlgorithm(constructor, i); // one calculator per CPU
pool.execute(new MonteCarloCmd(calculator)); // we launch the parallel execution on the pool
}
try {
latch.await(TIMEOUT, TimeUnit.SECONDS); // and wait for everything to be done
} catch (InterruptedException e) {
throw new RuntimeException(e);
}
pool.shutdown(); // close the pool (that can be reused if needed)
The real code on GitHub is a bit more complicated because I've put in place a listener pattern to give some feedback while it's running. This implementation is in fact penalizing the parallel algorithm since it requires data aggregation using atomic references and optimistic updates during the run. Than wouldn't be necessary in a traditional implementation.
For the curious among you, here the Java version of the Batman equation:
// Wings bottom
if (pow(x, 2.0) / 49.0 + pow(y, 2.0) / 9.0 - 1.0 = 4.0 && -(3.0 * sqrt(33.0)) / 7.0 = 3.0 && -(3.0 * sqrt(33.0)) / 7.0 = 0) {
return true;
}
// Tail
if (-3.0 = 0 && 3.0 / 4.0 = 0) {
return true;
}
// Ears inside
if (1.0 / 2.0 = 0 && y >= 0) {
return true;
}
// Chest
if (abs(x) = 0 && 9.0 / 4.0 - y >= 0) {
return true;
}
// Shoulders
if (abs(x) >= 1.0
&& y >= 0
&& -(abs(x)) / 2.0 - 3.0 / 7.0 * sqrt(10.0) * sqrt(4.0 - pow(abs(x) - 1.0, 2.0)) - y + (6.0 * sqrt(10.0)) / 7.0
+ 3.0 / 2.0 >= 0) {
return true;
}
return false;
To compare the implementations, a benchmark have been done on a Quadruple Extra Large GPU cluster at Amazon. We had 16 CPU cores and 996 GPU cores. Here are the results for the 30 seconds execution:
- **Sequential:**179 786 000 draws
- Parallel: 709 731 000 draws
- GPU: 12 582 912 000 draws
In parallel, we get let improvement than I was hoping for. We surely can do a better job. As I said, the implementation is penalizing the parallel execution. And it's not that terrible since it shows a nice demonstration of the Amdahl's law. One thing to remember: The sequential version is using only one CPU while the parallel one is using them all. While keeping a relatively simple implementation.
On the GPU side, the simplicity effect is less obvious. The good news are that Aparapi is quite refreshing. The library is translating the kernel (the part that runs on the GPU) bytecode into an OpenCL implementation which is called through JNI. It's developed by AMD. You can cook a matrix calculation example in about 10 minutes. However, doing a Monte Carlo is a bit more complicated. Here are some issues you might encounter.
- You can use only really simple JDK classes. For instance,
java.util.Randomjust doesn't work - GPUs don't like conditions ("if"). To get good performances, you have to modify your code into a linear computation
- For some reason, bitwise (&, |, ^) operations are silently not working
On top of that, you won't get with Aparapi the performances as high as you would get with CUDA. But the gap is slowly closing. For instance, there are new annotations helping the memory management. Data localisation in memory is really important on a GPU. Still, you surely noticed that, without any optimisation effort, the GPU version is 17 times faster than the parallel one!
I'll conclude like this:
- Sequential, you already know about it, it's reassuring, no need to think too much... and it's slow
- Parallel, not that complicated after all. A lot complexity hidden from the developer. Indeed, the GitHub code is in fact much more complicated than required
- GPU, I'll say it's refreshingly easier than 2 years ago, but we are not in the commodity realm yet. It's not that hard, but you need to make sure you really need it before using it
Meanwhile, let Batman rise in parallel. 