Barbadata : pour une gouvernance des données agile
La Gouvernance des données : beaucoup de monde en parle, mais qui l’a déjà implémentée ? Mais d’abord, qu’attend-on vraiment d’une gouvernance des données ?
La gouvernance des données a pour but principal de faciliter la production, la circulation et la valorisation des données au sein du système d’information en accord avec les contraintes propres de l’entreprise.
Peut-on seulement parler de “LA” gouvernance des données : y a-t-il un seul modèle réplicable ou des pattern à adapter ? Et dans le second cas : comment les choisir et comment les adapter aux différents contextes ?
L’objectif n’est pas ici de définir un nouveau framework de gouvernance, mais de lancer quelques idées pour définir une/des gouvernance(s) flexible(s) et adaptable(s) à différents usages des données au sein de l’entreprise.
Récit d’une histoire barbante
Vers la fin des années 90 et début des années 2000, la gouvernance des données se focalisait sur la “qualité” (DQM) celle-ci étant souvent limitée à la qualité “syntaxique” et abordant assez peu les questions de cohérence sémantique, de disponibilité etc…
Cette gouvernance correspondait à deux mouvements connexes au sein des SI :
- le premier correspond à une structuration des processus métier (notamment à travers les ERP) au sein des systèmes (ce qui avait pour effet de fortement modéliser les données au sein de bases relationnelles)
- le second correspond au développement de l’interopérabilité (on découvre que des systèmes construits côte-à-côte, partagent les mêmes types de données et qu’on pourrait tirer avantage d’un échange).
Devant ce double mouvement, la tendance est à la centralisation et à la focalisation sur la cohérence syntaxique : mes modèles doivent converger, je dois m’assurer que ma donnée A provenant du système 1, atterrit bien dans la bonne case du système 2.
Qui plus est, certaines données sont considérées comme centrales parce qu’elles sont parfois partagées par plusieurs systèmes : on en fait des données de référence, traitées par des processus et des systèmes propres : le Master Data Management (MDM).
Tant que la gouvernance des données demeurait sur un périmètre maîtrisé de données, cette démarche était soutenable. Mais avec l’émergence des technologies Big Data et de la transformation numérique, de nouvelles questions se posent. Le Big-Data apportait une promesse : la possibilité de valoriser des données jusqu’à présent considérées comme inutiles, voire comme des déchets.
Mais cette promesse a rapidement été confrontée à plusieurs écueils : la faible connaissance des assets-data de l’entreprise, la difficulté à exposer les données à l’extérieur des systèmes legacy, la qualité de ces données (tant du point de vue syntaxique que sémantique), le volume et la redondance, etc.
La perspective de la gouvernance des données s’est considérablement élargie : elle passe du simple étang à un lacis ressemblant plus ou moins à un fjord, complexe et difficile d’accès.
Vers une famille de gouvernances
L’expérience a montré qu’il n’y avait pas un modèle de gouvernance de données applicable à toute entreprise, mais qu’il doit être adapté à l’entreprise, en fonction de ses contingences : [Weber, 2009].
Weber cite 5 facteurs de contingence à prendre en compte :
- Stratégie de performance et de compétitivité
- Niveau de diversification
- Harmonisation des processus
- Structure organisationnelle
- Niveau de régulation du marché
Si la prise en compte de ces facteurs de contingence permet de s’assurer que la gouvernance est adaptée à l’entreprise, elle ne permet pas de garantir qu’elle est adaptée (et peu s’adapter) à l’ensemble des situations rencontrées au au sein de l’entreprise.
Dès lors, un modèle de gouvernance commun à l’ensemble de l’entreprise ne semble plus être viable : la gouvernance des données doit s’adapter à chacune des situations et usages et contraintes rencontrés.
Pour permettre cette flexibilité, il faut ajouter aux facteurs de contingence, un axe lié à la qualification des données (nature, qualité, unité, accessibilité, valorisation, …).
L’objectif est le suivant :
- maîtriser les données qui doivent l’être (soit qu’elles répondent à des exigences réglementaires, soit qu’elles permettent d’atteindre un objectif stratégique, soit qu’elles contribuent au bon fonctionnement des processus de l’entreprise etc…
- laisser du champ lorsque cela permet d’apporter de la valeur (soit dans une perspective d’innovation, soit pour préserver des ressources, etc…)
Ces critères peuvent s’appliquer sur :
- Un périmètre métier défini (ex : les données de supply chain)
- Des objets métier (ex : les données client)
- Des attributs/propriétés de certains des objets (ex : coordonnées clients)
Il faut également ajouter que les facteurs de contingence peuvent évoluer dans le temps : les principes de gouvernance sur ces données devront donc évoluer en fonction.
Cette “contingence des facteurs de contingence” nécessite de tracer de manière formelle les intentions à la source de décisions prises pour mettre en place tel ou tel mode de gouvernance sur tel ou tel périmètre.
Par exemple : une nouvelle réglementation (telle que RGPD) peut venir apporter une nouvelle contrainte sur le niveau de maîtrise. Une décision stratégique visant à filialiser peut conduire à adopter un mode de gouvernance plus lâche vis-à-vis des données opérationnelles etc…
Hulahup BarbaTruc !
Aux facteurs précités de contingence de l’entreprise, il faut ajouter des facteurs de contingence liés à la donnée : criticité métier, constante de temps, niveau de régulation applicable, niveau de maîtrise, facilité d’accès.
En plaçant les objets de données sur des matrices représentant les 2 axes de facteurs de contingence “entreprise et facteur “data, il est possible de déterminer : leur valeur, le niveau de contrôle et de process à leur appliquer, la nécessité d’utiliser un outillage, …
Par exemple, dans le schéma ci-contre, une matrice permettant de déterminer un style de gouvernance à appliquer en s’appuyant sur la contribution à le facteur de contingence “Stratégie” et le facteur de contingence “criticité métier”.
On ne parlera alors plus de “qualité des données”, mais de “maîtrise”, ce qui permet d’intégrer non seulement la qualité, mais la traçabilité (utile notamment pour les réglementations RGPD), le cycle de vie (“data lineage”) etc...
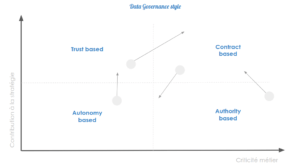
Ce style gouvernance peut être de 4 types :
- Basée sur l’autonomie : la maîtrise des données n’a pas d’impact sur le fonctionnement de l’entreprise ou la mise en oeuvre de la stratégie d’entreprise : les projet s définissent leurs propres règles de gouvernance ;
- Basée sur la confiance : la gouvernance niveau entreprise et le projet se mettent d’accord de manière informelle sur des critères de maîtrise ;
- Basée sur un contrat : le projet s’engage via une convention formelle à respecter des règles sur un périmètre de données spécifié ;
- Basée sur l’autorité : un processus formel permet de contrôler et redresser la qualité des données ;
En fonction du style de gouvernance appliquée, les évolutions sur les données seront prises en compte plus rapidement : une gouvernance basée sur l’autonomie permettra une intégration plus rapide et plus flexible d’une évolution sur la data, tandis qu’une gouvernance basée sur l’autorité nécessitera un temps d’intégration plus long.
Prenons un exemple : une entreprise de vente en ligne souhaite devenir l’acteur le plus performant du marché en proposant des livraison dans l’heure, quel que soit le lieu en France.
Pour y parvenir, elle doit obtenir une visibilité très forte des stocks pour optimiser la correspondance entre les stocks et le lieu de livraison.
Elle devra pour cela travailler :
- sur des données de référence (catalogue produit, référentiel cartographique),
- sur des données de géolocalisation (attachement entre un produit et un lieu de stockage, emplacement du produit en cours de livraison, emplacement des livreurs en temps réel…),
- sur des données opérationnelles (notamment base des stocks) ;
Chacune de ces données n’a pas la même criticité relative (i.e. les uns par rapport aux autres) et celle-ci peut évoluer. De même l’apport de ces données à l’axe stratégique de renforcement de la supply chain est relatif.
Les données de référence seront sans doute positionnées sur une gouvernance de type “Autorité”, les données de géolocalisation sur une gouvernance de type “Contrat”, les données opérationnelles sur sur une gouvernance de type “Confiance”.
En fonction du style de gouvernance adaptée à ces données, il faudra alors définir des modes de gouvernance adaptés à chaque situation :
- modalités de mise à disposition (Synchrone ? Asynchrone ? …)
- modalités de contrôle (Contrôle sur la sémantique, la validité du modèle, la syntaxe etc…),
- modalités de décision (A priori, A posteriori),
- modalités de traçabilité
L’objet de la gouvernance des données est ici de s’adapter - à la manière des fameux “BarbaPapa” - aux différentes situations pour appuyer des use-case et se reconfigurer quand le use-case évolue et n’est plus valide.
En ouverture
Le cadre d’une gouvernance des données, diversifiée et évolutive et posé. Et maintenant comment la mettre en oeuvre ?
Quelque chose est sûr, définir une gouvernance des données dans ce cadre, à travers une démarche top-down n’est pas vraiment approprié. Il vaut mieux la laisser émerger d’elle-même.
L’idée est de partir de la mise en oeuvre des use-case de valorisation des données, qui dicteront des exigences & contraintes très concrètes de gouvernance. Puis des patterns invariants commenceront à voir le jour et pourront être étendus aux autre use-case.
Bien entendu, cette émergence doit être accompagnée, guidée : la gouvernance doit être gouvernée.
Nous aurons l’opportunité d’approfondir ces quelques principes dans des articles à venir...