Avec Gemini Nano, voyez l'IA vie en rose !
Depuis quelques années, presque tous les projets informatiques ont un point commun : les équipes qui les développent se demandent “quand et comment on pourrait rajouter de l’IA à notre solution ?”
Au début de la GenAI on a surtout vu émerger beaucoup de chatbots améliorés, avec peu ou pas de valeurs ajoutées dans la plupart de nos produits. Mais au fur et à mesure que la technologie gagne en maturité et que les équipes se l’approprient, de plus en plus d’exemple de produit où l’IA apporte une vraie valeur à l’utilisateur. On peut citer par exemple le “Jeu de rôle” boosté à l’IA de Duolingo, ou encore Rufus d’amazon qui vous aidera (poussera ?) à acheter le bon produit en analysant pour vous des centaines de retours clients.
Pour éviter que votre application ne soit dépassée par vos concurrents, la pression de réussir à intégrer ce nouvel outil devient donc de plus en plus pressant. Pour autant, au moment de se lancer dans l’implémentation, deux obstacles majeurs se trouvent souvent sur notre route :
- La protection des données de l’utilisateur : même avec un modèle hébergé à l'intérieur de notre SI, faire transiter des données personnelles à travers un LLM peut exposer ces données à des attaques.
- Le coût de l'hébergement du modèle : ce n’est pas un secret, les LLMs sont gourmands en ressources, et héberger un modèle ayant vocation à être appelé par vos utilisateurs a un fort risque de faire exploser votre facture auprès de votre fournisseur de cloud préféré.
C’est à ce moment que Gemini Nano arrive et apporte la réponse parfaite à ces deux problèmes !
Alors Gemini Nano c’est quoi ? Et bien c’est le moteur d’IA générative “poids plume” de Google pour être embarqué (à terme) sur tous les smartphones Android. En utilisant Gemini Nano, nos problèmes disparaissent : les données ne quittent pas le téléphone, donc elles restent protégées. Et le téléphone hébergeant le modèle, c’est gratuit pour nos serveurs !
Évidemment, ces avantages viennent avec quelques défauts, sinon vous n’auriez pas besoin d’entendre parler du sujet dans un obscur blog d’une ESN parisienne. Je vous propose dans la suite de cet article de parcourir l’expérience d’un développeur se lançant dans l’exploration de Gemini Nano.
Les premiers pas : peu de devices compatibles mais un démarrage assez rapide
Commençons par le commencement : trouver la documentation. Jusque là, tout est simple, une recherche Google “Gemini Nano” et le premier résultat nous emmène au bon endroit. Pour les plus curieux d’entre vous, je vous invite à parcourir les quelques pages disponibles si vous voulez en apprendre plus sur le fonctionnement interne de Gemini Nano. Pour les autres, je résumerais ce que j’y ai appris en trois points importants :
- Gemini Nano est installable sur un device Android via deux applications système : Android AICore et Private Compute System.
- Elle n’est disponible que sur une liste assez courte de devices que nous pouvons résumer : les derniers device haut de gamme de la plupart des marques (Exemples: Pixel 9 et 10, Samsung Galaxy S25…).
- Pour appeler le modèle depuis notre application, il faut passer par le SDK ML Kit de Google (ce que nous allons faire dans la suite de l’article).
Une dernière étape avant de se lancer dans le code, il nous faut suivre une petite doc d’installation pour mettre à jour les deux applications mentionnées et nous pouvons nous lancer dans le développement de “Positive Thinker” une application qui va vous faire voir le côté positif de la vie (le code est disponible ici).
Comme dit plus haut, la manière recommandée d’utiliser Gemini nano est de passer par le SDK ML Kit. Sur la page d'accueil, le SDK nous informe des fonctionnalités disponibles :
- Résumé : résumer des articles ou des conversations sous forme de liste à puces.
- Relecture : peaufine les contenus courts en améliorant la grammaire et en corrigeant les fautes d'orthographe.
- Réécriture : réécrivez des messages courts dans différents tons ou styles.
- Description de l'image : générez une brève description d'une image donnée.
- Requête : générez du contenu textuel à partir d'une requête personnalisée, multimodale ou textuelle uniquement (utilisation classique de l’IA, comme une discussion avec Chat GPT).
Nous allons toutes les parcourir dans l’article, mais comme il faut bien commencer quelque part, je vous propose de partir sur la fonctionnalité de requête, qui me semble la plus fun du lot.
Nous l’utiliserons d’abord dans le cadre d’une fonctionnalité de discussion avec Coach Gnocchi, notre coach de vie positive. C’est parti !
La fonctionnalité de base : le prompt
L’implémentation
Les exemples d’implémentation présents dans cet article sont volontairement réduits pour le pas trop l’allonger. Mais la totalité du code utilisé est présent dans le ficher MainActivity.kt si vous voulez le réimplémenter de votre côté.
Commençons d’abord par importer la librairie dans notre build.gradle :
implementation("com.google.mlkit:genai-prompt:1.0.0-alpha1")
Nous pouvons maintenant instancier notre client qui servira d’interface avec le modèle, vérifier sa disponibilité et lancer notre premier prompt :
private suspend fun generateContent(userMessage: String) {
generativeModel = Generation.getClient()
val status = generativeModel.checkStatus()
if (status == FeatureStatus.AVAILABLE) {
val prompt =
"""Imagine que tu es un chien dont le rôle est de me faire comprendre que ma vie est super bien.
J'ai dit le message suivant : $userMessage
Je voudrais que tu me montres, en tant que chien qui parle français, le bon côté des choses dans ce que j'ai dit, en moins de 100 mots"""
val response = generativeModel.generateContent(prompt)
val coachGnocchiAnswer = response.candidates.firstOrNull()?.text ?: ""
}
}
Et voilà, rien de bien compliqué ! À noter que si votre device n’est pas compatible, que ce soit parce qu’il n’est pas dans la liste ou que les applications exposant Gemini Nano ne sont pas à la bonne version, vous recevrez un FeatureStatus.UNAVAILABLE. Si il n’est pas encore téléchargé (FeatureStatus.DOWNLOADABLE), le SDK permet de lancer et de suivre son téléchargement.
Vous pouvez voir que le message de l’utilisateur est enrichi avec le prompt maison pour le fonctionnement de Coach Gnocchi. Tout est en place, plus qu’à builder l’application pour apprécier le résultat !
Le résultat
Je ne vous détaille pas ici l’implémentation graphique de l’écran, ce n’est pas le sujet de l’article mais il est disponible dans le github du projet. Passons directement au résultat :
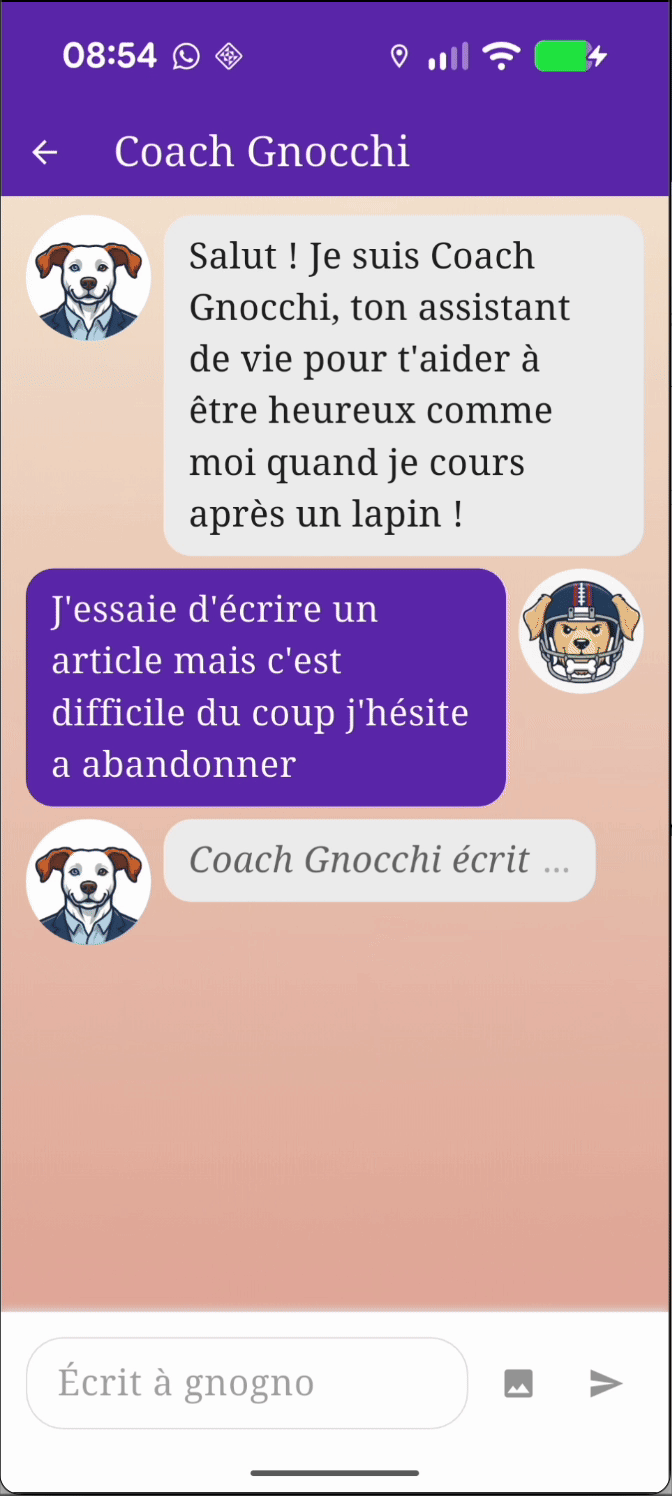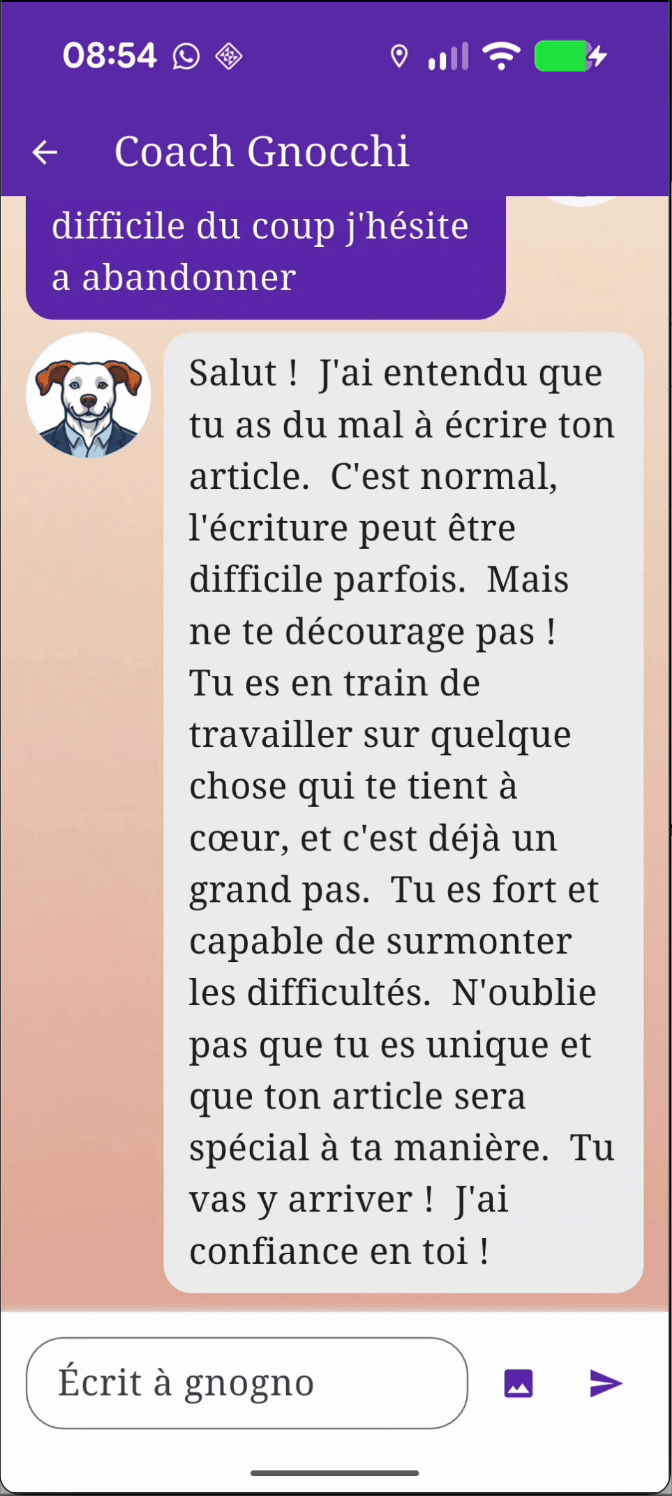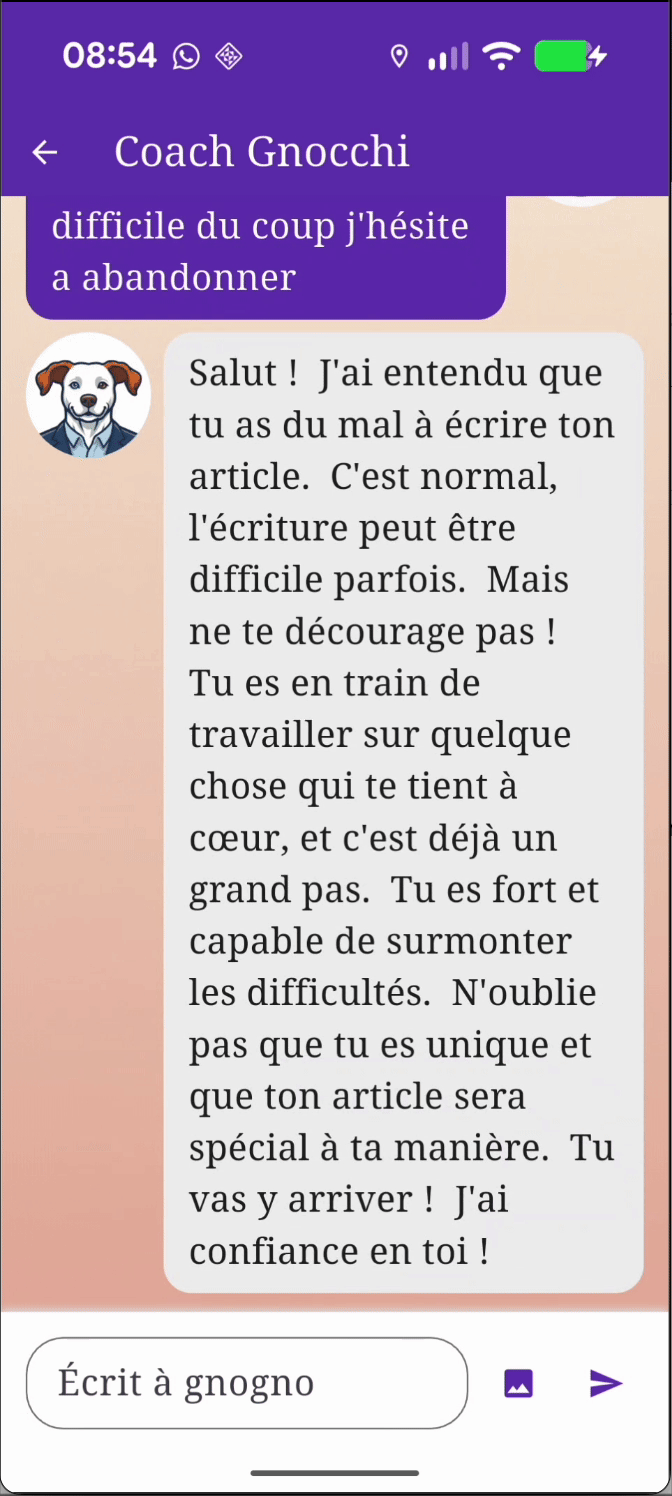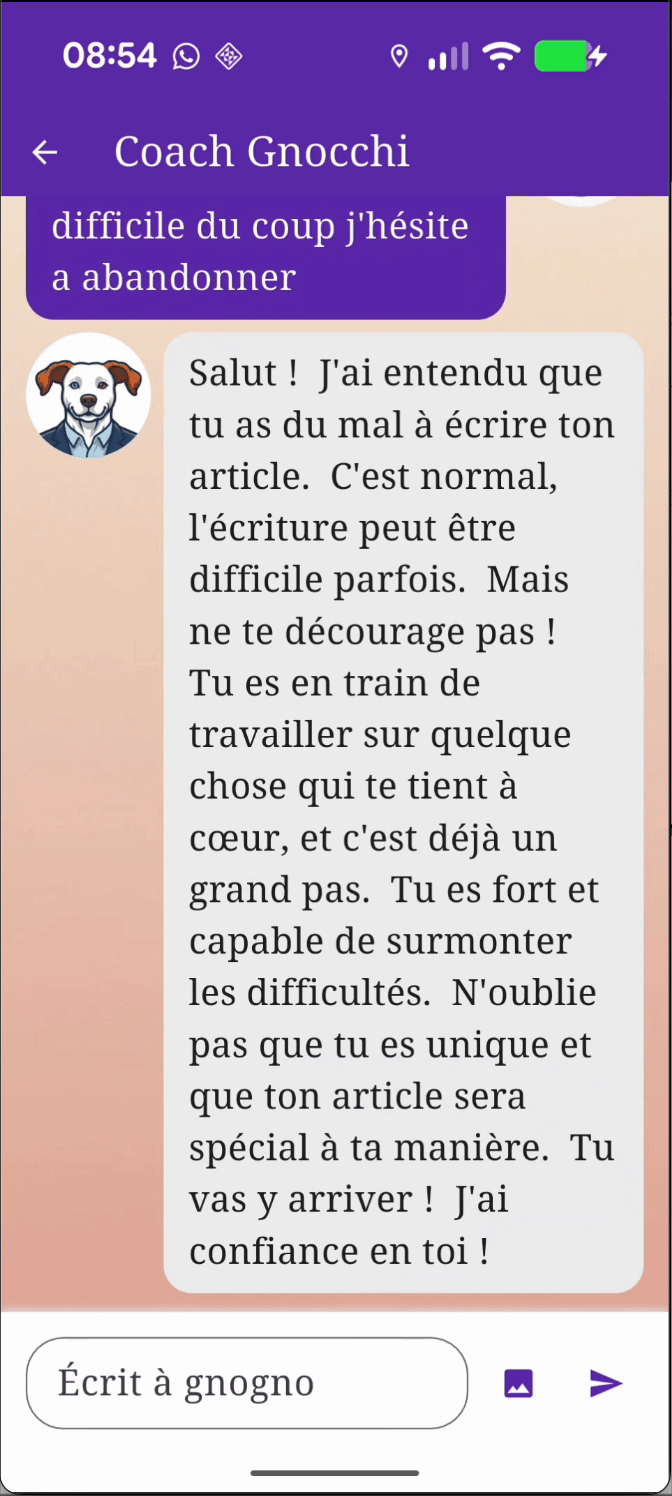
En quelques secondes sur mon Pixel 9 Pro (6 d’après mon chronomètre), Gemini Nano nous répond, avec une qualité plutôt correcte, même s' il y a de temps en temps quelques fautes de français.
Je vous laisserais tester chez vous d’autres prompts et je vous donne mon ressenti après en avoir lancé quelque uns :
- Le temps de réponse augmente fortement avec la taille maximale que vous donnerez à la réponse du modèle. On sent vite les limites de puissance du modèle.
- La qualité d’expression est au rendez-vous, mais la capacité d’analyse du modèle est très limitée. Petit exemple, je lui ai demandé ce que je peux faire après m’être coupé à la jambe : il m’a recommandé de prendre un bain chaud et de mettre de la glace !
- J’y reviendrai plus tard, sur un cas un peu plus complexe, mais le modèle retourne régulièrement des erreurs inattendues, notamment dues à un contenu jugé violent ou inapproprié.
J’en ressors avec un sentiment mitigé, entre la satisfaction d’un modèle facilement utilisable, presque “plug and play”, mais déjà de fortes limitations qui apparaissent.
La fonctionnalité sympa : l’analyse d’image
Essayons maintenant d’enrichir un peu Coach Gnocchi. C’est bien de pouvoir lui décrire ma journée, mais est-ce que ce ne serait pas plus pratique de lui envoyer directement une photo ?
Ça tombe bien, une des fonctionnalités de Gemini Nano est justement d’analyser les images !
L’implémentation
Comme pour le prompt, on commence par importer la librairie dans notre build.gradle :
implementation("com.google.mlkit:genai-image-description:1.0.0-beta1")
Retournons dans notre activity, et ajoutons une méthode qui permettent d’utiliser, la fonctionnalité d’analyse d’image :
private fun describeImage(filePath: String, result: MethodChannel.Result) {
val options = ImageDescriberOptions.builder(context).build()
val imageDescriber = ImageDescription.getClient(options)
val bitmap = BitmapFactory.decodeFile(filePath)
prepareAndStartImageDescription(bitmap, imageDescriber, result)
val imageDescriptionRequest = ImageDescriptionRequest
.builder(bitmap)
.build()
val imageDescription =
imageDescriber.runInference(imageDescriptionRequest).await().description
}
Pour rester dans le thème de notre coach de vie, nous utiliserons le retour de cette analyse et la rajouterons dans un prompt en utilisant la méthode vue au dessus.
val imageResult = describeImage(filePath);
val finalPrompt = """Imagine que je t'envoie l'image avec la description suivante : $imageResult.
Tu es un chien qui doit me faire voir la vie en positif.
Je veux que tu me la redécrive, en tant que chien qui parle français, en moins de 100 mots, et de manière beaucoup plus positive.""";
val result = await generateResponse(finalPrompt);
Le résultat
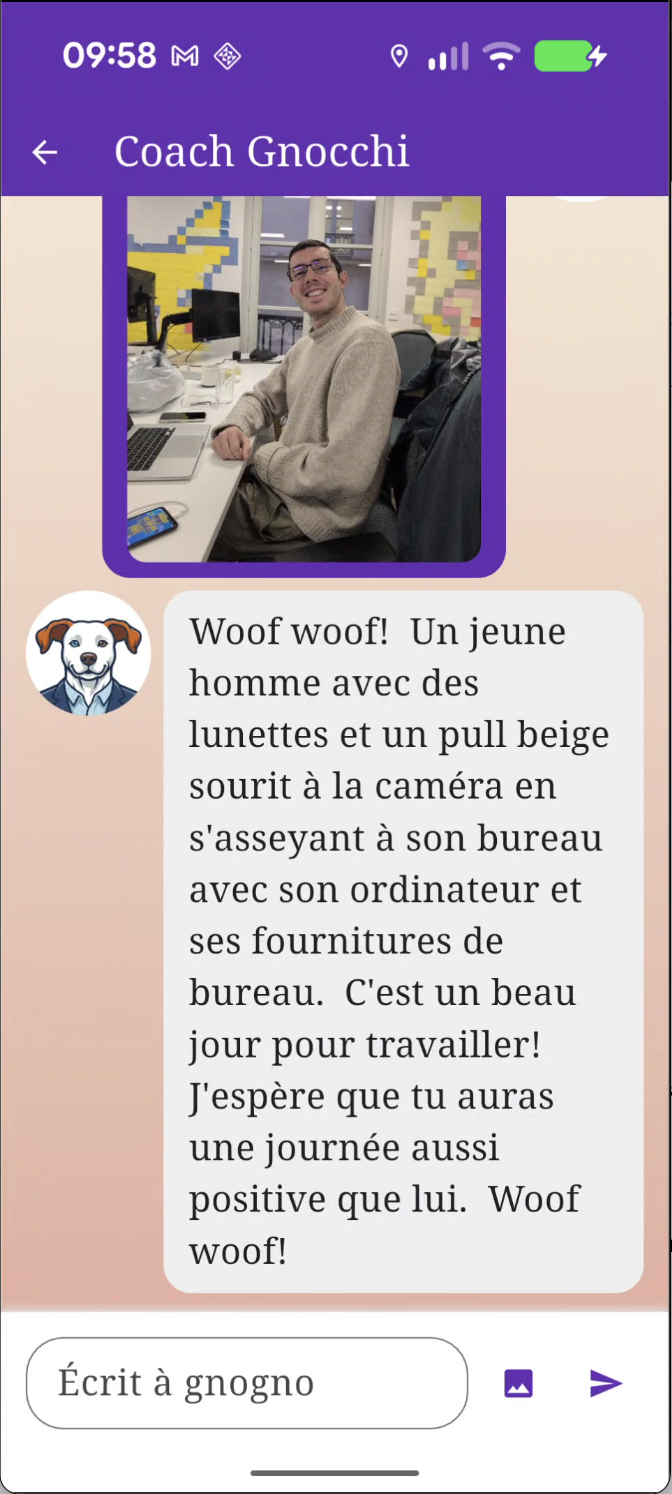
Tadaa ! Ça y est, notre coach est capable de se baser sur les images qu’on lui envoie. Et les retours sur l’analyse d’image sont encore meilleurs que sur le prompt !
- Le temps de réponse est vraiment satisfaisant (la plupart du temps entre 3 et 5 secondes)
- Les détails majeurs de l’image sont presque toujours bons, et le modèle arrive même à analyser certaines expressions
- On a toujours quelques erreurs sur des détails plus secondaires. Par exemple, sur l’image du dessus, lors d’une deuxième analyse, le modèle m’a dit que le mur avait des dessins en Lego (alors qu’ils sont en post it).
Cette fois-ci, le sentiment est plus agréable. Sans atteindre une entière satisfaction, on se rapproche quand même fortement de l’attendu. Si la précision que nous attendons de l’image n’est pas très forte, Gemini Nano nous permettra probablement de remplir nos cas d’usages.
Les dernières fonctionnalités : retravailler du texte
Le reste des fonctionnalités offertes par Gemini Nano étant un peu moins “fun” je vous propose de les regrouper et de passer plus rapidement dessus. Nous parlons des fonctionnalités de résumé, réécriture et relecture.
L’implémentation
Chaque fonctionnalité correspond à un import gradle séparé, ce qui nous donne :
implementation("com.google.mlkit:genai-summarization:1.0.0-beta1")
implementation("com.google.mlkit:genai-rewriting:1.0.0-beta1")
implementation("com.google.mlkit:genai-proofreading:1.0.0-beta1")
Puis l’implémentation est très similaire à celle de l’analyse d’image. Pour abréger un peu je ne vous mets ici que la partie importante de l’implémentation, et je vous laisse regarder les docs complètes pour plus de détails (résumé, réécriture et relecture).
Pour le résumé, l’API est simple et ne prend qu’un texte d’entrée en paramètre.
val summarizerOptions = SummarizerOptions.builder(context)
.setInputType(SummarizerOptions.InputType.ARTICLE)
.setOutputType(SummarizerOptions.OutputType.THREE_BULLETS)
.setLanguage(SummarizerOptions.Language.ENGLISH)
.build()
summarizer = Summarization.getClient(summarizerOptions)<br><br>val summarizationRequest = SummarizationRequest.builder(textToSummurize).build()
val summarizationResult = summarizer.runInference(summarizationRequest).get().summary
Nous pouvons choisir de customiser notre résumé entre un article ou une conversation, puis choisir le nombre de “bullets” entre 1, 2 ou 3. L’API de résumé est disponible aujourd’hui en anglais, japonais ou coréen.
Pour la relecture, l’implémentation est très similaire :
val options = ProofreaderOptions.builder(context)
.setInputType(ProofreaderOptions.InputType.KEYBOARD)
.setLanguage(ProofreaderOptions.Language.FRENCH)
.build()
proofreader = Proofreading.getClient(options)
val proofreadingRequest = ProofreadingRequest.builder(textToCorrect).build()
val response = proofreader.runInference(proofreadingRequest).get().results
val proofreadingResult = response.last.text
Nous pouvons choisir de corriger soit un texte, soit un message vocal. Et les langages disponibles sont un peu plus fournis : Anglais, Japonais, Allemand, Français, Italien, Espagnol et Coréen.
Enfin, pour la reformulation :
val rewriterOptions = RewriterOptions.builder(context)
// OutputType doit être parmis les suivants: ELABORATE, EMOJIFY, SHORTEN, FRIENDLY, PROFESSIONAL, REPHRASE
.setOutputType(outputType)
.setLanguage(RewriterOptions.Language.FRENCH)
.build()
rewriter = Rewriting.getClient(rewriterOptions)
val rewritingRequest = RewritingRequest.builder(textToRewrite).build()
val response = rewriter.runInference(rewritingRequest).get().results
val rewritingResult = response.last.text
Nous avons ici quelques options en plus, notamment pour choisir le type de reformulation que nous voulons avoir. La liste des langages est la même que pour la relecture.
Le résultat
Pour voir le résultat de ces différentes fonctionnalités, je vous propose de les combiner dans une fonctionnalité plus complète : la construction d’un résumé positif d’un article. Nous allons d’abord choisir un article venant du site The Guardian, récupérer son contenu sous forme de texte par API puis :
- Le résumer avec l’API de résumé
- Traduire le résumé de l’anglais vers le français avec l’API de reformulation
- Injecter des ondes positives dans l’article avec l’API de prompt
Je vous mets ici le résultat des différentes étapes, en dehors du texte initial qui serait très long.
Le résumé en anglais
* A £160m busway through
Coton Orchard, a 24-hectare (60-acre) traditional orchard, is being examined for an off-road busway.
* The GCP and Cambridgeshire county council propose the busway for housing growth, congestion reduction, and sustainable travel, but it has been opposed by many.
* The inquiry examines the potential for biodiversity loss, with the GCP claiming it has delivered 20% biodiversity net gain, but ecologists argue it misclassifies the orchard.
La traduction du résumé
Un projet de busway d'une longueur de 160 millions de livres sterling, traversant l'orangerie traditionnelle de Coton Orchard (un domaine de 24 hectares), fait l'objet d'une étude. Il est proposé pour répondre à la croissance démographique, réduire la congestion et favoriser les transports durables. Cependant, ce projet a suscité de nombreuses oppositions. L'enquête examine notamment le risque potentiel de perte de biodiversité. Le GCP affirme avoir atteint une augmentation nette de 20% de la biodiversité, mais les écologistes contestent cette évaluation, arguant que l'orangerie n'est pas correctement classée.
La version finale en plus positif
Super Nouvelles
1. Busway de 160 millions de livres sterling pour Coton Orchard !
Un projet ambitieux de busway de 160 millions de livres sterling traverse l'orangerie traditionnelle de Coton Orchard, un domaine de 24 hectares ! Ce projet révolutionnaire vise à répondre à la croissance démographique, réduire la congestion et favoriser les transports durables.
2. Biodiversité en hausse, mais pas convaincue !
Le GCP affirme avoir atteint une augmentation nette de 20% de la biodiversité, mais les écologistes contestent cette évaluation. Ils estiment que l'orangerie n'est pas correctement classée et que le projet pourrait nuire à la faune et à la flore locale.
3. Un projet innovant pour un avenir meilleur !
Ce busway représente un investissement majeur pour l'avenir de Coton Orchard et de la région. Il permettra de réduire l'impact des transports sur l'environnement et de créer un lien plus fort entre les différents quartiers.
Et voilà !

La combinaison de ces trois réécritures successives du texte va nous demander d’attendre une quinzaine de secondes avant d’avoir le rendu final. Ce n’est donc pas encore l’idéal. Mais malgré tout nous sommes capables de mener à bien notre cas d’usage !
Un autre problème apparaît également dès lors que l’on va essayer d’utiliser la fonctionnalité sur des articles traitant de sujets plus “sensibles” : [ErrorCode 4] Request doesn't pass certain policy check. Please try a different input
L’IA va donc refuser de traiter certains sujets s'ils ne remplissent pas ses “Policy check” qui traitent notamment de violence, harcèlement, mais aussi “fake news”.
Par exemple, en essayant de résumer un article ayant pour titre ‘Gestapo tactics’: Bruce Springsteen condemns Trump’s ICE crackdown, le modèle nous retournera systématiquement cette erreur.
Pour rester dans le thème de l’application, nous choisirons tout de même de rester sur une note positive : pour un coût de 0€ TTC, et en sans mettre en danger nos données, notre application a pu faire tout ce que nous lui avions demandé. Enfin, la plupart du temps !
Alors on en pense quoi finalement ?
Si on laisse de côté l’amusement que peut procurer le développement d’une application comme Positive Thinker, qu’est-ce qu’on a pu en retirer ?
- Une technologie pas encore accessible à tous : Le SDK est toujours en bêta et son accès reste restreint à une poignée d'appareils haut de gamme. Pour l'instant, l'utilisateur final doit souvent s'enrôler de lui-même pour utiliser les fonctionnalités qu’on développerait. On est loin d'un déploiement massif.
- Une puissance limitée et spécialisée : étant habitués à des modèles beaucoup plus complexes, il faut réduire ses attentes pour ne pas être déçu par Gemini Nano. C’est un modèle compact, conçu pour des tâches de surface et qui atteint ses limites très vite si on sort de son utilisation recommandée.
- Un manque de fiabilité frustrant : de par ses capacités limitées, le modèle a des limites très fortes (et non réglables) sur la sensibilité du contenu qu’il peut manipuler. Ce qui amène un volume de requêtes en erreur assez important quand on s’y essaie.
- Un potentiel immense : Malgré ses défauts, la promesse de Gemini Nano reste partiellement tenue. Dans un usage limité certes, mais nous avons la capacité d’utiliser l’IA générative pour un coût nul (financier comme écologique) et avec une protection des données totale. Une fois arrivé à maturité, il nous ouvrira des possibilités encore nouvelles par rapport aux modèles en ligne et enrichira toujours plus l’expérience de nos utilisateurs.
À noter : pour les utilisateurs de certains téléphones Android (les pixels 9 et 10 par exemple) Gemini nano est déjà utilisé par le clavier natif et propose des options de correction et de reformulation, et également par Talkback (l’outil de lecteur d’écran) pour vocaliser le contenu des images.
Pour celles et ceux qui veulent aller plus loin : quelques points auraient pu être abordés dans cet article mais ne l’ont pas été par manque de place :
- Gemini Nano est également accessible sur chrome desktop avec des contraintes légèrement différentes et des API similaires
- Gemini Nano n’est évidemment pas la seule manière d’embarquer de l’IA directement dans nos applications. Nous pouvons par exemple utiliser Gemma et son modèle Gemma 3n adapté aux smartphones. Gemma présente le désavantage de devoir stocker le modèle à côté de l’application, ce qui fera exploser sa taille de stockage (prévoir que votre application occupe au moins 4Gb sur le téléphone de vos utilisateurs). Mais Gemma a l’avantage de pouvoir être sur-entrainé pour coller au plus proche de vos besoin avant d’être envoyé sur les devices de vos utilisateurs, pour une expérience de meilleure qualité.