Automatiser les déploiements de projets de Machine Learning. Partie 1 : la construction de modèles
Cet article fait partie de la série “Accélérer le Delivery de projets de Machine Learning”, traitant de l’application d’Accelerate dans un contexte incluant du Machine Learning. Il peut être lu indépendamment, mais si vous n’êtes pas familier avec Accelerate, ou si vous souhaitez avoir plus de détails sur le contexte de cet article, vous pouvez lire l’article introduisant cette série. Vous y trouverez également le lien vers le reste des articles pour aller plus loin.
Dans Accelerate, l’automatisation des déploiements fait référence à l’aptitude à déployer son logiciel dans n’importe quel environnement en un clic. On automatise les déploiements pour réduire les risques associés à une mise en production :
- en minimisant les manipulations faites par un humain, et diminuant ainsi le risque d’erreur humaine lors des déploiements ;
- en permettant de déployer rapidement une version de notre logiciel dans un environnement de test, permettant aux équipes de le tester au plus vite après le développement.
Lorsqu’on parle de déploiement automatique d’un système comportant du Machine Learning, il s’agit d’automatiser deux choses :
- la construction de l’artefact modèle, processus appelé en Machine Learning l’entraînement ;
- le déploiement du service d’inférence.
| Service d’inférence | Pipeline de construction de l’artefact modèle | |
| Rôle | Sert les prédictions | Produit un modèle à partir de données et de code |
| Enjeu | Pouvoir déployer une nouvelle version du modèle utilisable par le logiciel à la demande | Pouvoir lancer un entraînement à la demande |
La réponse face à ces deux enjeux dépend des besoins particuliers auxquels ce système répond. Google le montre très bien dans cet article, résumant les différentes aptitudes MLOps à mobiliser selon la situation.
figcaption {color: grey; text-align: center; font-style: italic}
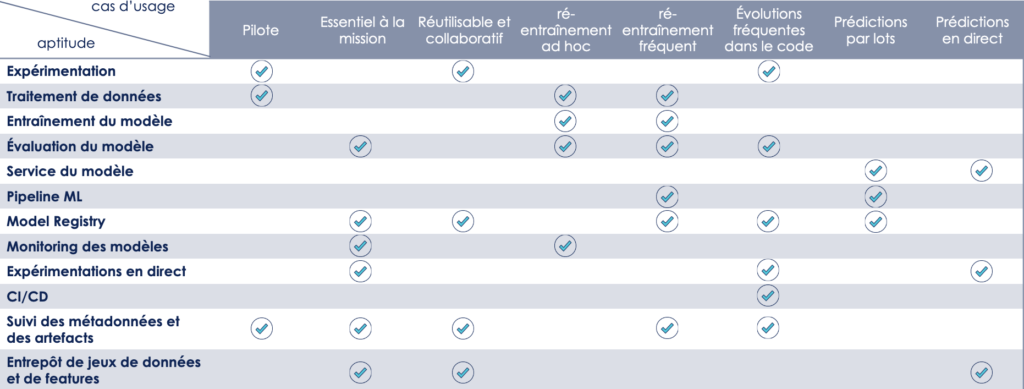
Traduction du tableau comparatif issu de l’article de Google sur les aptitudes MLOps
Dans cet article, nous nous concentrons sur l’automatisation de la construction de l’artefact modèle, un sujet à la croisée de l’intégration continue et de l’automatisation des déploiements. Nous nous intéressons aux enjeux du déploiement de nouveaux modèles au sein du logiciel dans un autre article.
Comment industrialiser la construction de son modèle de Machine Learning
Lorsqu’on déploie un modèle, il ne suffit pas, comme dans la plupart des déploiements logiciels, de déployer une “photo” de notre code (package, conteneur…), mais de déployer une photo du code et du résultat d’un processus d’entraînement à partir de code et de données. Nous vous proposons quelques bonnes pratiques pour automatiser la création de cet artefact particulier qu’est le modèle.
Demandez-vous : et si je n’en avais pas besoin (YAGNI) ?
Et si vous aviez en fait une tâche en moins à réaliser ? Se lancer dans l’industrialisation de l’entraînement du modèle uniquement lorsque le besoin se fait ressentir peut vous faire gagner un temps considérable. Et si un seul entraînement suffisait ? Ce n’est alors pas aberrant de construire son artefact modèle sur la machine d’un Data Scientist avec un minimum de précautions (comme versionner son code, son modèle et ses données, tester son code...), puis passer à autre chose.
Au contraire, il se peut que vous ayez souvent besoin de changer votre algorithme d’apprentissage, d’adapter votre modèle à de nouveaux contextes, ou que vos données changent très rapidement. Il sera alors pertinent, en effet, d’automatiser l’exécution de cette partie centrale de votre logiciel. Cependant, le temps que vous aurez pris pour jauger la situation vous aura permis de gagner plus de connaissances sur vos besoins en pratique (qui diffèrent souvent grandement de vos besoins en théorie), et d'adopter une architecture émergente.
Déterminez les événements qui devraient déclencher un entraînement
En machine learning, le changement de comportement du logiciel peut provenir d’un changement dans le code, mais aussi des données. Le besoin de relancer la construction de l’artefact modèle ne vient donc plus uniquement de la livraison d’une nouvelle version du code le produisant. En prenant en considération les besoins des utilisateurs, en discutant avec le métier et en observant le comportement de votre système en production (à travers le suivi de KPIs et le suivi du monitoring), vous serez capable de déterminer quels évènements devraient déclencher la construction de l’artefact modèle.
| Cas de figure | Exemple | Événements déclencheurs possibles |
| 1. Les données traitées par le système ressemblent toujours aux données d’entraînement initiales dans le temps | Déploiement d’un modèle de détection automatique d’objets sur une même chaîne de production | - Déploiement d’une nouvelle version du code |
| 2. Les données traitées par le système évoluent lorsque le modèle change de contexte | Déploiement d’un modèle de détection automatique d’objets sur une chaîne de production produisant les mêmes produits mais dans une autre usine (ex : production de pièces d’avion) | - Déploiement d’une nouvelle version du code<br>- Action manuelle du métier, du data scientist ou de l’utilisateur |
| 3. Les données traitées par le système évoluent avec le temps | Déploiement d’un modèle de détection automatique d’objets sur une chaîne de production dont les produits évoluent (ex : production de sièges automobiles) | - Déploiement d’une nouvelle version du code<br>- Action manuelle du métier, du data scientist, du développeur ou de l’utilisateur<br>- Alerte du système de monitoring<br>- Tâche récurrente automatisée |
Concentrons-nous sur le troisième cas de figure. Contrairement aux deux premiers, il peut ici être pertinent d’automatiser la construction du modèle, notamment si les données sont très changeantes. Nous pensons néanmoins que, dans un premier temps, il est plus judicieux de commencer par un entraînement enclenché manuellement. Cela permet à la fois de mener cette automatisation par petits pas et de rassurer un métier potentiellement frileux. Il est également envisageable de déclencher des entraînements automatiques à intervalles réguliers ou en réponse à des événements dans des environnements de testing, uat, pré-prod ou shadow prod, afin de faire quelques tests en amont, tout en gardant le déploiement de l’artefact en production grâce à un clic.
Si on opte pour une automatisation, on s’interrogera alors sur la méthode : vaut-il mieux lancer un entraînement en réponse à un événement ou de façon récurrente ? Tout dépendra de :
- la facilité à identifier des événements justifiant la construction de l’artefact ;
- leur fréquence ;
- la durée d’un entraînement ;
- son coût ;
- la capacité à déterminer un laps de temps après lequel relancer un entraînement.
Choisissez le bon outil pour le déclenchement de l’entraînement
Il va bien sûr dépendre du ou des évènements déclencheurs que vous retiendrez. Voici quelques exemples d’implémentation :
| Événement déclencheur | Exemples d’implémentations |
| Déploiement d’une nouvelle version du code | Intégrer l’entraînement à la pipeline de CI/CD (Gitlab CI, Github Actions, ...):<br><br>- en y ajoutant une étape d’entraînement<br>- ou en y appelant une pipeline dédiée (sur Airflow par exemple)<br>- ou en y appelant un service d’entraînement (post sur une API déclenchant un entraînement, appel d’une lambda…) |
| Action manuelle du data scientist ou du développeur | - Script à exécuter en local ou en distant<br>- Pipeline à déclencher manuellement (par une commande ou une interface graphique, comme celle d’Airflow)<br>- Service à appeler manuellement (post sur une API déclenchant un entraînement, appel d’une lambda…)<br>- Clic sur une interface graphique dédiée |
| Action manuelle du métier | - Pipeline à déclencher manuellement à travers une interface graphique, comme celle d’Airflow<br>- Clic sur une interface graphique dédiée |
| Action manuelle de l’utilisateur | - Clic sur une interface graphique dédiée |
| Alerte du système de monitoring | - Déclenchement automatique d’une pipeline (présente dans un outil de CI ou Airflow par exemple)<br>- Service à appeler automatiquement (post sur une API déclenchant un entraînement, appel d’une lambda…) |
| Tâche récurrente automatisée | - Déclenchement programmé d’une pipeline (présente dans un outil de CI ou Airflow par exemple)<br>- Appel programmé à un service (post sur une API déclenchant un entraînement, appel d’une lambda…) |
Ne mettez pas vos notebooks en production
En phase d’exploration, l’entraînement est typiquement déclenché à la main par le Data Scientist dans un Jupyter notebook. Admettons que nous décidions de garder un entraînement manuel pour la construction du modèle à déployer en production. Il reste alors la question du code du notebook qui, lui, ne devrait pas servir à la production. En effet, ce format, très pratique pour visualiser les données, essayer plusieurs modèles et les comparer entre eux, l’est moins pour produire des modèles à la demande. Il n’est pas aisé d’y intégrer des tests automatiques, de refactorer son code, de le versionner ou de collaborer en utilisant cet outil. En bref, maintenir un modèle sur un notebook est une mauvaise idée. Lors de l’industrialisation, l’enjeu sera donc de sortir l’entraînement du modèle que l’on souhaite déployer du notebook, afin de pouvoir le maintenir et automatiser son exécution.
Comment ? Nous sommes convaincues que les tâches d’exploration doivent être traitées comme des spikes : leur objectif est de répondre rapidement à une question et d’acquérir de la connaissance. Le code produit par un spike est jetable : une fois la question répondue, nous serons en mesure de mieux cadrer notre problématique (par exemple, quel modèle déployer ?) et développer proprement une solution pour l’implémenter.
Cependant, lorsqu’on ne fonctionne pas encore de cette façon-là et qu’on a accumulé beaucoup de notebooks, nous pouvons y récupérer notre code afin d’en faire des scripts, exécutables par un pipeline de CI/CD.
Pour cela, nous commençons par fabriquer un harnais de sécurité, sous la forme d’un test d’acceptance, qui sera en mesure de nous dire facilement si à un moment de l’opération d’extraction de notre code, quelque chose se passe mal. Concrètement, nous utilisons notre notebook, dont nous allons fixer le comportement. Le test d’acceptance consiste à vérifier qu’on récupère bien les mêmes données en sortie (modèle, prédictions…) lorsqu’on lui donne les mêmes données en entrée. Ainsi, si le retour de notre notebook varie après modification, nous savons que quelque chose cloche. Pour que cela marche, il nous faut d’abord mettre de côté des données qui nous serviront de test. Nous faisons ensuite en sorte d’enlever toutes les sources d’aléa du notebook, en fixant la seed lors de l’échantillonnage, du train-test split ou dans les algorithmes d’apprentissage. Nous pouvons ensuite faire tourner ce notebook, au comportement déterministe, afin de récupérer les résultats, que nous gardons précieusement. Pour vérifier que nous n’avons rien cassé, il suffit de le faire tourner et vérifier que nos résultats sont toujours les mêmes.
Une fois le harnais en place, nous pouvons modifier notre notebook pour extraire notre code de feature engineering, d'entraînement et d’évaluation. Nous commençons par remplacer le code des cellules par des fonctions. Nous les copions-collons sur un fichier .py et les importons pour les utiliser dans notre notebook - dans le but de maintenir notre test d’acceptance. Ces fonctions pourront ainsi être testées, pour une meilleure maintenabilité, et surtout appelées par des scripts de feature engineering d’entraînement ou d’invocation (en accord avec la règle #32 du Machine Learning selon Google).
Automatisez la création d’environnements permettant l’entraînement du modèle
L’entraînement d’un modèle a besoin de ressources permettant le traitement de données en batch. Dans certains cas, cette étape nécessite l’utilisation d’un hardware spécifique, comme des GPUs dans un contexte de deep learning. Ainsi, l’entraînement, qui n’a généralement pas besoin de tourner en continu, utilise des ressources relativement chères. C’est pour cela qu’utiliser des environnements éphémères, construits et aussitôt détruits, est souvent une bonne idée. D’où la pertinence d’utiliser le Cloud et l’infrastructure as code****.
Concrètement, il s’agit d’automatiser la mise en service d’un environnement d’entraînement en utilisant des outils comme :
- Terraform, qui permet de créer des ressources (espace de stockage, machine virtuelle…) répondant à certaines spécifications (taille du stockage, GPU, RAM, nombre de coeurs, système d’exploitation…) ;
- Les CLIs des services de Cloud, qui remplissent souvent le même rôle que Terraform ;
- Ansible, qui permet d’automatiser l’initialisation d’un serveur en installant par exemple des packages, en lançant des services…
Enrichissez votre CI et complétez votre versionnement en y intégrant les spécificités du ML
Enfin, afin de sécuriser la construction de l’artefact modèle, il est judicieux de compléter les vérifications automatiques permettant de valider que les artefacts que vous vous apprétez à déployer sont conformes au comportement que vous attendez. Pour cela, il est pertinent d'ajouter à la CI les tests spécifiques au ML. Finalement, soulignons l’importance de versionner et tracer les différentes composantes de votre système de ML afin de savoir ce que vous avez a en production à un instant T et être en capacité de revenir rapidement à une version antérieure en cas de soucis après déploiement.
Conclusion
En résumé, il nous semble essentiel de s’interroger sur le contexte au début d'un chantier d’automatisation, avant de se lancer sur une solution technique. Quel est le besoin d’entraînement ? Y a-t-il besoin d'entraîner le modèle une seule fois ? A l’initiative de qui ? En réponse à quels événements ? Le contexte est-il changeant ? Une fois ces questions répondues, il sera plus facile de vous interroger sur l'architecture et l'outillage technologique. Allez-vous plutôt intégrer votre pipeline d’entraînement dans votre CI / CD ? Mettre en place des solutions d’orchestration de type Airflow ? Créer des services et des interfaces dédiées pour les entraînements ? Quelques bonnes pratiques nous semblent cependant essentielles :
- éviter de mettre des notebooks en production ;
- investir sur de l’infrastructure as code afin de versionner et faciliter la construction d'environnements permettant d’entraîner les modèles ;
- traiter le code permettant de produire le modèle comme du code applicatif : le versionner et le tester.
Il nous apparaît donc primordial d’avoir une approche centrée utilisateurs, permettant d’adapter et de faire émerger une architecture en réponse à un contexte. Nous pensons donc que la première question à se poser lorsqu’on souhaite automatiser la construction de modèles est : à quel besoin suis-je en train de répondre ? Dans un contexte de Machine Learning, il nous semble également important de considérer les spécificités du cas d’usage, notamment la volatilité dans la distribution des données. Pour répondre à ces enjeux, il est utile d’échanger entre les différents acteurs techniques (data scientists, développeurs, opérations) et non-techniques (métier, utilisateurs). En somme, l’automatisation de la construction de modèles n’est pas un problème qui se règle en mettant en place un outil et appelle à une réflexion systémique plus poussée.