Au-delà du monitoring technique, l'observabilité du système et des équipes qui le produisent
L’objectif de cet article est de proposer un lien entre observabilité des systèmes techniques et observabilité des organisations.
La littérature, les conférences, les retours d’expérience commencent à être assez riches autour de l’importance de la mesure, du monitoring et de l’observabilité de systèmes techniques. Nous proposons ici d’étudier la transposition de ces concepts, ces modèles, ces automatismes à l’observabilité et au debug de systèmes sociaux-techniques.
Nous allons dans un premier temps revenir sur quelques définitions et concepts régulièrement partagés autour du monitoring, de l’observabilité et du debug de systèmes techniques, puis nous essayerons d’identifier comment transposer ces concepts au monitoring d’organisation, enfin nous parcourons une proposition et quelques pistes pour améliorer l’observabilité de nos organisations.
De l’importance de monitorer ses systèmes
Il est désormais communément admis qu’un système en production DOIT être monitoré. Si nous ne surveillons pas l’état de nos applications ou de nos services, si nous ne mesurons pas ce qu’il se passe à l’intérieur de nos systèmes d’information, alors nous sommes aveugles, nous ne savons pas si notre système vit, nous ne savons pas s'il bouge, nous ne savons pas dans quelle direction, nous ne sommes pas capables de savoir si le service est rendu ou non. Dans un monde où l’outil informatique est au cœur du business, cela revient à dire que nous ne savons pas si notre business se comporte bien ou non.
Le monitoring permet de mesurer différentes caractéristiques d’un système d’information :
- Son exactitude : il fait bien ce qu’il est censé faire, et ne fait pas ce qu’il n’est pas censé faire
- Sa performance : il rend sa fonction avec les performances attendues (latence, temps de traitement…)
- Son efficience : le système ne coûte pas trop cher
- Sa sécurisation : le système rend le service de manière sécurisée (confidentialité, intégrité, disponibilité, traçabilité)
- Sa conformité : le système respecte la réglementation (GDPR…)
On peut également vouloir monitorer notre système pour mesurer sa stabilité et sa disponibilité, cette disponibilité dépend directement :
- Du MTBF : Mean Time Between Failure: Le temps moyen entre deux pannes
- Du MTTD : Mean Time To Detect: Le temps moyen pour détecter une panne
- Du MTTR : Mean Time To Repair: Le temps moyen pour réparer/mitiger l’impact d’une panne
Un bon monitoring permet de minimiser le coût et la durée des pannes dans notre système. On va d’une part réduire l’impact ou la perte financière directe associée à une interruption du service, et d’autre part minimiser le temps et le budget alloué à la réparation du système (et par effet mécanique maximiser le temps alloué à l’implémentation et la livraison d’évolutions par les développeurs).
Pourquoi le monitoring via une collecte de métriques a priori n’est plus suffisant
Le monitoring s’appuie généralement sur une collecte prédéfinie de métriques ou de logs et est assez souvent orienté “ressources” (on sait que tel serveur a remonté telle erreur) plutôt que fonctionnel (je sais que ma release n+1 fonctionne mieux que ma release n, je sais quel cas d’usage ou suite d'événements génère un défaut).
Google propose par exemple 4 “Golden Signals” qui peuvent s’appliquer assez facilement à presque n’importe quel système technique :
- Latence : le temps pour répondre à une requête correctement (hors erreur)
- Trafic : le trafic encaissé par le système (nombre de requêtes/sec...)
- Erreurs : le taux de requêtes qui tombent en erreur (que ce soit de mauvaises réponses, un mauvais contenu renvoyé ou des requêtes qui mettent trop de temps à être traitées)
- Saturation : son pourcentage d’utilisation
Un tel système de monitoring permet généralement de détecter des pannes déjà connues. Il s’intéresse aux “inconnus connus” de nos systèmes : on sait à l’avance où regarder et ce que l’on regarde, on ne sait en revanche ni quand ni pourquoi une panne arrivera (on va monitorer le remplissage d’un disque, mais on ne sait ni quand ni pourquoi il sera rempli).
Le monitoring permet d’identifier des symptômes, mais plus difficilement la cause initiale de ces symptômes. Plus nos systèmes sont complexes, distribués, dépendants de services externes, plus il est compliqué de faire la relation entre symptômes et causes.
Moins les pannes sont prévisibles, plus il est nécessaire de s’intéresser aux “inconnus inconnus”, plus il faut savoir répondre à des questions qui n’ont pas encore été posées, détecter et comprendre la source de pannes dont nous n’avons pour l’instant pas connaissance, des cas pour lesquels nous ne savons à priori rien : nous ne savons pas encore quoi regarder, nous ne savons pas quand regarder, nous ne savons pas où regarder et nous ne savons pas pourquoi un problème arriverait.
Afin de toujours travailler à minimiser le temps moyen de détection et le temps moyen de résolution d’une panne, il est nécessaire de mettre en place des outils/process permettant de diagnostiquer rapidement un système pour comprendre comment une panne est survenue et ce qu’elle implique.
Un bon système est un système observable
On dit d’un système facilement diagnostiquable qu’il est “observable”, c’est un des attributs fondamentaux de tout SI moderne.
Concevoir un système observable, c’est donc construire un système qu’on va pouvoir interroger, et outiller son débug pour rendre son exploration a posteriori possible.
L’observabilité est avant tout un problème de données : nous allons chercher à rassembler un maximum de données sur notre système, sans forcément savoir comment nous allons les utiliser a priori. On va ensuite faire parler ces données dans le but de modéliser les relations entre les différents éléments de notre SI et proposer une vue globale et holistique de notre système de production.
On va chercher à rassembler toutes les données sur :
- Les ressources d’une part (serveurs, services, endpoints d’API…)
- Les transactions entre ces ressources d’autre part
On convient généralement que l’observabilité s’appuie sur 3 types de données :
- Les Métriques : permettent de répondre au "What happened" : permet de savoir que le service est down, que le endpoint met du temps à répondre mais ne donne pas beaucoup plus de contexte car les données sont souvent agrégées (compteurs ou jauges), c’est là où s’arrête généralement le monitoring.
- Les Traces : permettent de répondre au "Where it happened" : les traces récupèrent l'historique d'une requête à travers tout le système, elles permettent d'identifier où a eu lieu l'erreur ou la lenteur de réponse.
- Les Logs : permettent de répondre au "Why it happened" : les logs doivent permettre de récupérer le contexte sur un événement, ils permettent par exemple de savoir que le serveur a répondu une erreur 5xx car le serveur Back-end n'a pas répondu à temps.
Concevoir des systèmes observables, c’est donc construire des systèmes, des outils et des process qui permettent d'avoir des données consistantes et actionnables pour mesurer la performance et diagnostiquer les problèmes. L'objectif est d’instrumenter nos applications et de créer des workflows qui nous aident à identifier et résoudre nos problèmes.
Who watches the watchmen ?
Si on prend un peu de hauteur, notre SI est un système imbriqué dans un système à la manière d’un set de poupées russes : nous avons notre SI, le système technique “produit” qui est l’outil technologique qui rend la valeur business et fonctionnelle et nous avons au dessus ou autour le système socio-technique qui conçoit et livre ce SI, “le système qui produit le système”.
Un système c’est une collection d’éléments ou sous-systèmes connectés entre eux pour accomplir un objectif ou une fonction. On peut comparer notre système de delivery à un SI composé de pleins de petits micros services distribués (PO, Dev, équipes agiles, Ops…) qui échangent des “paquets” (tickets, US, releases…)
Notre système de “production du SI” peut donc être défini comme : “tous les éléments techniques (nos serveurs, notre CI/CD, notre code...) et sociaux (nos collaborateurs, nos interactions entre collaborateurs, nos communautés de pratiques, nos conventions, notre culture...) dont l'objectif est de mettre en production du code informatique.”
Nous venons de démontrer l’importance de rendre nos systèmes d’information monitorables, observables et debuggables afin de pouvoir minimiser l’impact des pannes. Qu’en est-il alors de notre système socio-technique de production/livraison ? N’est-il pas tout aussi important de le rendre monitorable afin de pouvoir facilement mesurer sa performance, son exactitude, son efficience et de le rendre observable afin de pouvoir rapidement identifier et comprendre la cause de certaines “pannes” ou “bug” pour en minimiser les impacts ?
Une proposition : Utiliser la boîte à outils d’Accelerate pour rendre notre système de livraison observable
Accelerate est un livre synthétisant plusieurs années d’études qui cherche à répondre à une question simple : “quelles sont les caractéristiques des organisations technologiques performantes ?”
En se basant sur les réponses du sondage “State of DevOps” de 4 années consécutives, l’étude établit une corrélation forte entre performances de delivery et objectifs organisationnels et financiers des entreprises. L’étude propose entre autres deux artefacts qui peuvent nous servir d’outil de monitoring et d’observabilité :
- 4 indicateurs pour mesurer et monitorer sa performance
- 24 aptitudes pour diagnostiquer et améliorer son delivery
4 Indicateurs pour monitorer sa performance
A la manière des 4 Golden Signals pour le monitoring de systèmes techniques, l’étude Accelerate propose 4 indicateurs pour monitorer la performance de son système de delivery logiciel :
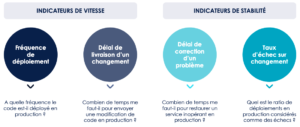
Ces indicateurs s’intéressent à la fois aux performances des activités plutôt orientées “Build” et aux conséquences de ces activités sur le “Run” de notre système technique, ils mesurent bien ce qui est “important pour l’utilisateur” du système de delivery, à savoir la capacité de mon organisation à livrer une nouvelle fonctionnalité rapidement et de manière stable.
Ces 4 indicateurs nous permettent de savoir si notre delivery est performant (est-ce que nous livrons à la bonne vitesse ? Est-ce que nos livraisons sont de qualité ? Arrivons-nous à corriger rapidement en cas de problème ? ), ils peuvent nous aider à identifier des symptômes d’un delivery sous performant ou instable, cependant, ils nous permettent difficilement d’en identifier les causes.
Enfin, pour être tout à fait complet, ces indicateurs sont principalement des indicateurs tactiques qui seront efficaces pour mesurer si nous livrons bien (“Do the thing right”) et vite (“Do it fast”), mais ils seront moins efficaces d’un point de vue stratégique pour mesurer et valider que nous travaillons sur les bonnes fonctionnalités (“Do the right thing”).
24 pierres à soulever pour améliorer la connaissance de son organisation et pour diagnostiquer ses “bugs”
L’étude adosse à ces 4 indicateurs 24 aptitudes techniques, méthodologiques, organisationnelles et culturelles qui aident à diagnostiquer l’ensemble de la chaîne de valeur de notre système socio-technique de delivery :
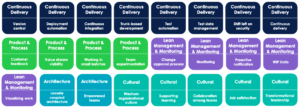
En parcourant cette liste, nous pouvons identifier des aptitudes qui, si elles sont étudiées, donnent des pistes pour rendre le système d’information produit ou le système socio-technique de delivery observable.
Certaines aptitudes s’intéressent directement à rendre observable le système technique :
• Monitoring : Cette aptitude est la plus simple à comprendre, elle s’intéresse directement aux capacités de mesure et de debug du SI énoncées dans la première partie de cet article. Mon équipe dispose-t-elle de moyens de suivi de l’état de ses ressources, services et applications ? Mon équipe dispose-t-elle de moyens de recueil et de collecte d’informations (métriques, traces, logs) facilitant l’investigation et le débuggage de ses systèmes ?
• Proactive Notification : Cette aptitude s’intéresse aux alertes mises en place sur notre SI afin d’assurer la détection des anomalies. On cherche à valider que les erreurs de production (dépassement d’un seuil, variation trop importante d’une métrique…) remontent bien des alertes aux personnes susceptibles de résoudre le problème et que seules les alertes nécessitant une intervention humaine sont remontées. L’objectif est que le SI soit suffisamment bien monitoré pour qu’aucune anomalie ne soit remontée par les utilisateurs sans que les équipes ne soient au courant avant.
• Customer Feedback : Cette aptitude s’intéresse aux techniques et méthodes permettant de collecter et utiliser le retour des utilisateurs pour améliorer le service livré. On cherche à savoir si des moyens de collecte des retours sur l’utilisation du produit existent, si ces retours sont analysés et utilisés pour améliorer le produit, si le développement du logiciel intègre des méthodes dédiées à la collecte de retours des usages (A/B testing par exemple). La collecte du retour utilisateur est un moyen supplémentaire de rendre notre système observable.
• Version Control : Cette aptitude s’intéresse à l’utilisation efficace d’outils de gestion de code pour l’ensemble des artefacts produits (code applicatif, code d’infrastructure, configuration, migrations de données). Quand toute source de vérité est disponible “as code” et versionnée, le simple audit du code et de son historique aide grandement à l’identification de la source d’un problème.
• Test Automation : Cette aptitude s’intéresse aux techniques permettant d’assurer que le logiciel produit est toujours “livrable en production”. On cherche à savoir si l’équipe implémente des tests en même temps (et idéalement avant) d’implémenter de nouvelles fonctionnalités, si les performances de l’application sont testées, si les tests couvrent à la fois les fonctions unitaires, les parcours fonctionnels bout-en-bout et les contrats d’interfaces avec les services tiers. Ces différents tests pourront alors facilement être utilisés pour aider au debug du système en cas de défaillance et pour réduire le champ des “inconnus”.
• Shift left on security : Cette aptitude s’intéresse à la conception de systèmes sûrs intégrant la sécurité à toutes les étapes du cycle de vie du logiciel, de la conception au déploiement. Des équipes sensibilisées aux problématiques de sécurité tout au long du cycle de livraison du logiciel, ce sont généralement des équipes plus à même de comprendre et détecter les causes d’une anomalie dans le futur sans avoir besoin de faire appel aux experts sécurité.
D’autres aptitudes aident plutôt à nous poser les bonnes questions pour rendre observable notre système de delivery socio-technique :
• Value Stream Visibility : L’objectif de cette aptitude est de s’assurer que toutes les équipes qui participent au delivery du SI aient une bonne compréhension et une bonne visibilité de toutes les étapes du flux de travail de la conception à l’utilisation du produit, que les équipes comprennent comment leurs tâches contribuent à apporter de la valeur aux utilisateurs finaux. Cela revient à dessiner, documenter et rendre explicite “l’architecture” du système de delivery socio-technique. On va chercher à identifier toutes les tâches et étapes nécessaires à la création d’une évolution dans un produit : quelles informations doivent transiter d’une étape ou d’une équipe à une autre ? Quelle modèle de collaboration ou “contrat d’interface” doit être mis en place entre les équipes pour assurer un bon fonctionnement ?
• Visualizing Work : Cette aptitude s’intéresse aux moyens mis en œuvre pour faciliter le suivi opérationnel et l’identification des points de contention du système de livraison. On cherche à comprendre comment l’état d’avancement d’une équipe est partagé à l’organisation, comment l’état des tâches, des anomalies ou encore des objectifs de l’équipe sont partagés. On y fait beaucoup référence au management visuel (mise en place de board Kanban par exemple) et de mise en place de mesures du flux (mesure du lead Time, de la taille du backlog, Cumulative Flow Diagrams…). Ce qui est tracé et rendu visible est plus facilement regardé, et donc auditable et débugable. Le management visuel permet de suivre l’évolution des performances de l’organisation dans le temps et d’identifier rapidement les variations de certaines métriques.
• WIP Limits : La loi de Little énonce que le temps de traitement d’une demande est directement proportionnel au nombre de demandes dans un système divisé par la “capacité à faire” du système. Ainsi, moins nous avons de demandes ou de projets en cours en même temps dans le système, plus celles-ci ont de chance d’être livrées rapidement. Cette aptitude s’intéresse donc au management du travail en cours (Work In Progress) par les équipes. L’objectif est de limiter volontairement l’encours des équipes pour rendre immédiatement visible les blocages et les résoudre: quand une limite de tâches en parallèle est atteinte et que toutes les tâches en cours sont “en attente”, plutôt que de commencer une nouvelle tâche, on cherche à comprendre pourquoi cette limite est atteinte et comment débloquer la situation en identifiant des points d’amélioration sur le système de delivery.
• Westrum Organizational Culture : Cette aptitude cherche avant tout à comprendre et qualifier les interactions entre les différents équipiers/équipes, elle s’intéresse à la culture de l’entreprise, à l’implémentation et la valorisation d’une culture générative, c’est à dire une culture qui met en avant la collaboration et le partage d’information au sein de l’entreprise. On va chercher à comprendre si l’organisation promeut le partage des bonnes comme des mauvaises nouvelles, si la sécurité psychologique des collaborateurs est assurée, si les équipes sont incitées à partager et à coopérer entre elles, si l’organisation favorise l’expérimentation et l’apprentissage des éventuels échecs qui en découlent. Une bonne culture du partage est indispensable pour permettre aux collaborateurs de rendre leur organisation observable, de se laisser observer dans un but d’amélioration et non de surveillance ou de sanction.
• Loosely Coupled Architecture : Cette aptitude cherche à comprendre et mesurer l’autonomie des équipes sur leur périmètre, de la conception au déploiement de leurs applications. Une organisation est souvent plus efficace et scalable quand les besoins de coordination entre équipes sont réduits à leur strict minimum. C’est souvent en s’intéressant au couplage entre différents systèmes ou équipes que l’on comprend le mieux ce qui freine la livraison de nouvelles fonctionnalités.
• Collaboration among Teams : Cette aptitude va s’intéresser aux leviers qui permettent aux équipes de travailler ensemble. On va chercher à comprendre si les équipes ont des objectifs alignés, si la performance est mesurée au niveau du collectif plutôt que des individus, si le partage de connaissances est favorisé via l’organisation de rituels ou de communautés de pratiques.
• Transformational Leadership : Cette aptitude s’intéresse au type de leadership qui officie au sein de l’organisation. Est-il plutôt transactionnel (mode carotte/bâton, micromanagement, s’appuyant sur une motivation extrinsèque des collaborateurs) ou transformationnel (management à travers l’organisation et les pratiques, définition d’objectifs s’appuyant sur la mise en place de vecteurs de motivation intrinsèques aux collaborateurs) ?
• Job Satisfaction : Cette aptitude cherche à mesurer le cercle vertueux que créer une bonne satisfaction des employés dans leur travail : plus ils sont satisfaits, meilleur est leur engagement, meilleur est leur engagement plus ils sont satisfaits.
Les collaborateurs qui font partie du système peuvent alors se former/être accompagnés pour devenir des “capteurs” de leur environnement. Ils vont s'entraîner à observer les différentes thématiques autour des aptitudes Accelerate, rassembler les bonnes informations et utiliser ces informations pour améliorer d’abord leur connaissance du système socio-technique, puis améliorer le système de delivery lui-même.
Nous allons ainsi pouvoir utiliser chaque aptitude dans une démarche d’amélioration scientifique bien connue des adeptes du Lean et très proche de ce que nous ferions pour comprendre et corriger un bug technique :
- Mesurer où le système est actuellement
- Identifier où il devrait être pour être performant (le comportement voulu)
- Former des hypothèses sur les raisons de l’état actuel
- Proposer des contres-mesures pour corriger
- Activer les changements et valider (ou non) nos hypothèses
- Recommencer
Avant de partir
Peu importe le système étudié, la mesure est absolument indispensable pour confronter ou (in)valider nos modèles mentaux, nous devons observer nos systèmes pour pouvoir les améliorer.
Cela concerne nos systèmes techniques, le monitoring n’étant plus suffisant pour comprendre et corriger rapidement et efficacement des pannes de plus en plus complexes, mais également nos systèmes socio-techniques, qui comme tout système peuvent “tomber en panne” ou montrer des problèmes de performance qu’il convient de mesurer et corriger le plus rapidement possible pour en minimiser l’impact.
Évidemment, il existe quelques limites à notre proposition de transposition des mécanismes de monitoring de systèmes techniques aux organisations. Un système d’information n’est globalement composé que de 0 et de 1 qui exécutent et rendent le service pour lequel ils ont été assemblés. Une organisation est quant à elle composée d’humains ayant leur volonté propre, leurs sentiments, leur manière d’interpréter les situations et les interactions. Un des pré-requis indispensable pour parvenir à rendre son organisation observable, c’est donc la formation à l’usage positif des métriques dans un but de faire émerger les défaillances, la tolérance face aux remontées de “bugs”, l’utilisation de ces remontées comme opportunités d’amélioration et le support des “responsables” du système pour le faire évoluer et le corriger.
Dans un monde de plus en plus complexe et instable, où la majorité des problèmes à résoudre seront des problèmes nouveaux de l’ordre des “inconnus inconnus”, il devient indispensable d’outiller et former son organisation à pouvoir se mesurer, s’observer, se diagnostiquer et se débugger.
Pour tout savoir sur les enjeux Cloud, DevOps et Plateformes, cliquez ici.