Au-delà des Mots-Clés : Améliorer la Recherche en Ligne grâce au Knowledge Graph
Introduction
Dans notre vie quotidienne, nous sommes habitués à chercher des articles en utilisant des mots-clés. Ces mots-clés aident les moteurs de recherche à trouver des articles correspondant à nos demandes. Cependant, cette approche présente certaines limites. Imaginons le scénario suivant :
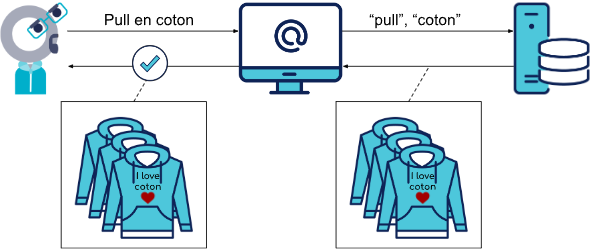
Bob est à la recherche d'un pull en coton. Il se rend sur sa plateforme préférée et effectue la recherche "pull en coton". Le moteur de recherche va alors chercher dans sa base de données tous les articles associés aux mots-clés "pull" et "coton" pour les lui présenter.
Maintenant, imaginons que Bob soit allergique au coton et cherche en réalité un pull sans coton. Reprenons le même schéma.
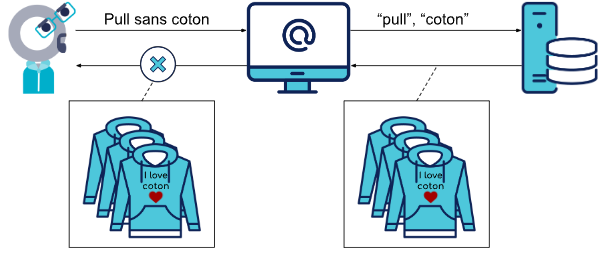
Bob obtient alors des résultats qui ne correspondent pas à son besoin. Cela met en évidence les limites de ce système traditionnel dans lequel la machine ne comprend pas le sens sémantique de la recherche. À l'heure actuelle, de nombreuses plateformes de vente en ligne rencontrent ce problème, ce qui peut provoquer de la frustration chez les utilisateurs.
Dans cet article, nous cherchons une solution pour réduire l'écart sémantique qu’il existe entre les besoins des utilisateurs et les articles associés. Pour cela, intéressons-nous au Knowledge Graph.
Le Knowledge Graph, c'est quoi ?
Pour comprendre la notion de Knowledge Graph (K.G.), décomposons le en 2 notions clés : “Knowledge” et “Graph”.
La théorie des graphes
La théorie des graphes est une discipline mathématique qui étudie les relations entre les objets et les entités sous forme de graphes. Un graphe est composé de nœuds (ou sommets) reliés entre eux par des arêtes (ou liens). L'une des premières contributions importantes à cette théorie remonte au 18ème siècle, lorsque le mathématicien suisse Leonhard Euler s'est intéressé au problème des sept ponts de la ville de Königsberg.
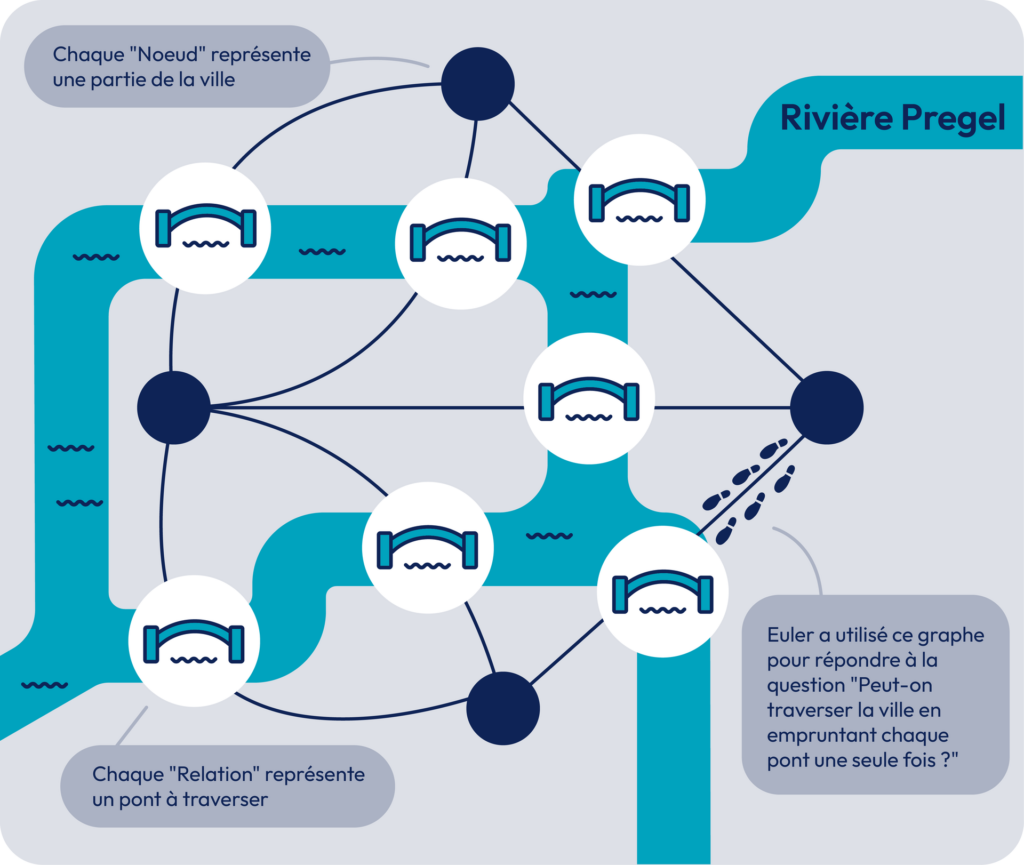
Le problème des sept ponts consistait à savoir s'il était possible de parcourir la ville en passant une seule fois sur chaque pont et en revenant à son point de départ. En analysant le problème sous forme de graphe, Euler a démontré que la solution était impossible, car certaines zones étaient connectées par un nombre impair de ponts, rendant le parcours complet impossible.
Cette contribution d'Euler a jeté les bases de la théorie des graphes et a ouvert la voie à de nombreuses avancées ultérieures. Aujourd'hui, la théorie des graphes est utilisée dans de nombreux domaines, y compris la recherche opérationnelle, l'informatique, la biologie, les réseaux sociaux, et sert de socle à la construction de Knowledge Graphs.
Pour aller plus loin :
L’ouvrage “Advanced Graph Theory and Combinatorics, Rigo, 2016 ” explique plus en détails ce qu’est la théorie des graphes ainsi que les différents uses cases associés.
Le.s Knowledge Graph.s
Un Knowledge Graph, également connu sous le nom de réseau sémantique, représente un réseau d'entités du monde réel, c'est-à-dire des objets, des événements, des situations ou des concepts, et illustre les relations entre eux. Ces informations sont généralement stockées dans une base de données graphe et visualisées sous la forme d'une structure en graphe, d'où le terme « graphe de connaissances ».
IBM
Un Knowledge Graph est une représentation structurée des connaissances et des relations entre différents concepts. Il s'agit d'une approche qui vise à organiser les informations de manière sémantique, permettant ainsi aux machines de comprendre le sens des données et d'établir des liens entre elles.
Dans un Knowledge Graph, les connaissances sont représentées sous forme de nœuds et les relations entre ces connaissances sont représentées sous forme d'arêtes. Cela crée un réseau interconnecté de données qui facilite la recherche, l'exploration et la découverte d'informations pertinentes.
Prenons l’exemple d’un groupe d’amis :
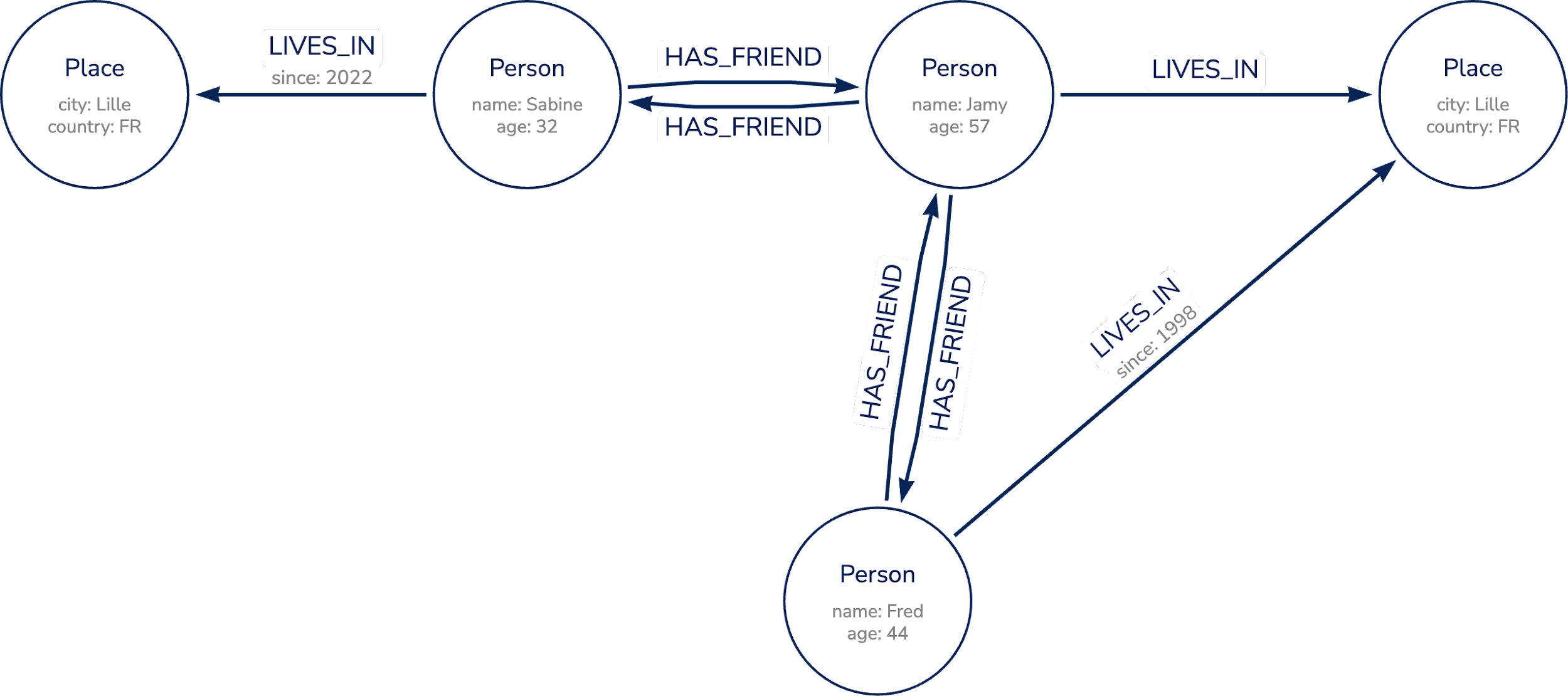
Ici, il est trivial pour toute personne, quel que soit son domaine d’expertise, de comprendre ce diagramme. En ajoutant du contexte sémantique entre nos différentes entités, on crée alors une histoire pouvant être racontée à la fois par un humain, mais également comprise par une machine. On approche alors la computation du langage naturel, tel que le présente Stephen Wolfram.
Alors, qu'est-ce qu'un langage computationnel ? C'est un langage permettant d'exprimer les choses d'une manière computationnelle et de capturer les façons de penser computationnelles à leur sujet. Ce n'est pas simplement un langage pour indiquer aux ordinateurs ce qu'ils doivent faire. C'est un langage que les ordinateurs et les êtres humains peuvent utiliser pour représenter des façons de penser computationnelles. C'est un langage qui donne une forme concrète à une vision computationnelle de tout. C'est un langage qui permet d'utiliser le paradigme computationnel comme cadre pour formuler et organiser ses pensées.
S. Wolfram
En résumé, le Knowledge Graph est un outil puissant qui transforme les données en connaissances exploitables, améliorant ainsi l'expérience utilisateur et ouvrant de nouvelles possibilités dans divers domaines tels que la recherche d'information, le commerce électronique, la recommandation de contenu, le partage de connaissance au sein d’une entreprise et d'autres. Etudions maintenant comment l’utiliser pour répondre à notre cas utilisateur.
AliCoCo : Alibaba Cognitive Concept
Au cours des cinq dernières années, des chercheurs employés par Alibaba, le géant chinois du commerce électronique, ont étudié une problématique similaire à celle que nous avons présentée. En 2020, ils ont publié un concept novateur appelé AliCoCo, qui utilise le Knowledge Graph pour répondre à ce besoin.
Le concept se détaille de la façon suivante :
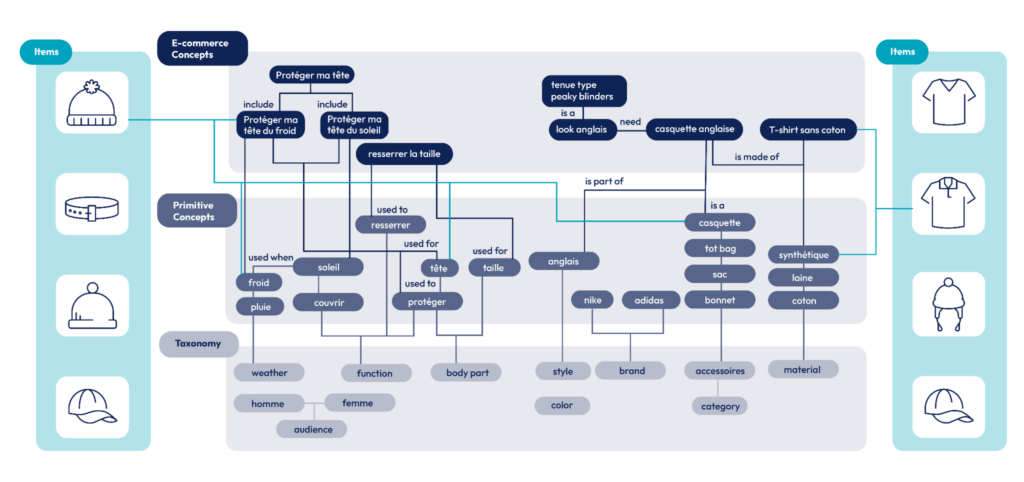
On distingue 4 couches :
__La __taxonomie correspond au vocabulaire de base de notre projet. Sa conception se fait manuellement, réunissant les différents acteurs pour s’aligner sur un vocabulaire commun (ubiquitous language).
Les primitive concepts représentent une extension du vocabulaire défini. On l’obtient en le minant de sources différentes (fiches produit, historique de recherches, blogs, etc.).
__Les __e-commerce concepts sont les scénarios d’achat utilisateurs. Autrement dit, ce sont les besoins que l’on espère retrouver dans la barre de recherche des utilisateurs. Ceux-ci sont construits à partir des primitive concepts en mettant en place des règles sémantiques.
__Les __items correspondent aux produits proposés à la vente. Ils sont à la fois rattachés aux e-commerce concepts et aux primitive concepts.
En interconnectant ces quatre couches sémantiques, Alibaba a réussi à répondre à de nombreux besoins tels que “cuisiner une tarte aux pommes”, ou “comment me protéger du soleil”. Le concept est actuellement déployé en production sur les sites Alibaba et AliExpress, et les chercheurs continuent d’innover sur le sujet.
Pour aller plus loin :
Alibaba a publié un deuxième papier présentant une deuxième itération du modèle AliCoCo. Vous le retrouverez ici
Réalisation d’un moteur de recherche sémantique
Après avoir vu la théorie, amusons-nous avec ce concept. Pour réaliser ce moteur de recherche sémantique, nous allons nous baser sur les données provenant d’un retailer spécialisé dans la mode. L’idée est de travailler avec un domaine suffisamment restreint pour pouvoir obtenir un résultat rapidement. Je vous propose donc de travailler sur la catégorie “accessoires” de leur site.
Notre plan d’action est le suivant :
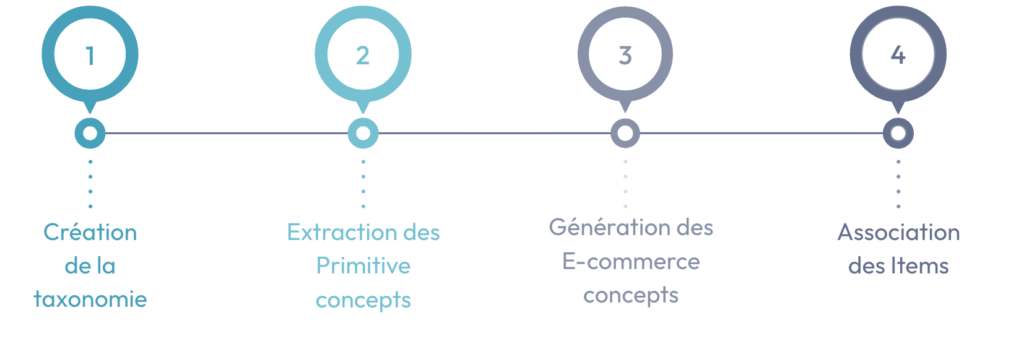
1. Création de la taxonomie
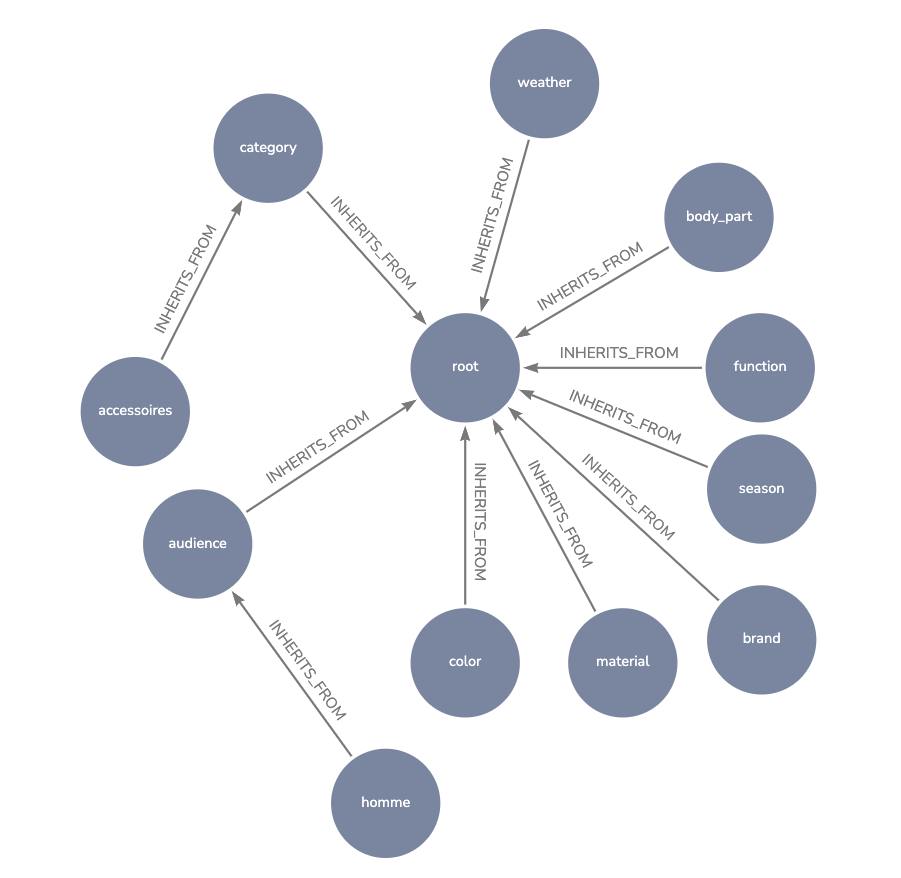
Pour commencer, alignons nous sur le vocabulaire que nous allons utiliser. Pour des accessoires, définissons les termes :
Catégorie de l’article → category
couleur → color
la fonction du produit → function
la partie du corps associé → body_part
etc.
L’objectif ici n’est pas de définir tout le vocabulaire d’une traite. Travaillons sur cette taxonomie de manière itérative, en la complétant au fur et à mesure de l’évolution de notre besoin.
2. Extraction des primitive concepts
Afin d’extraire les primitive concepts, nous avons besoin de données produit. Basons nous sur les titres et url des articles comme base d’information. De cette base, nous avons besoin d’extraire des informations corrélées avec la taxonomie générée.
Les titres n’étant pas formatés de la même manière, nous allons utiliser un Named Entity Recognition personnalisé, capable de reconnaître les informations souhaitées (couleur, catégorie, matière, etc.). Commençons par créer des données d'entraînement en annotant 1000 titres de produits sélectionnés indépendamment de leur catégorie.
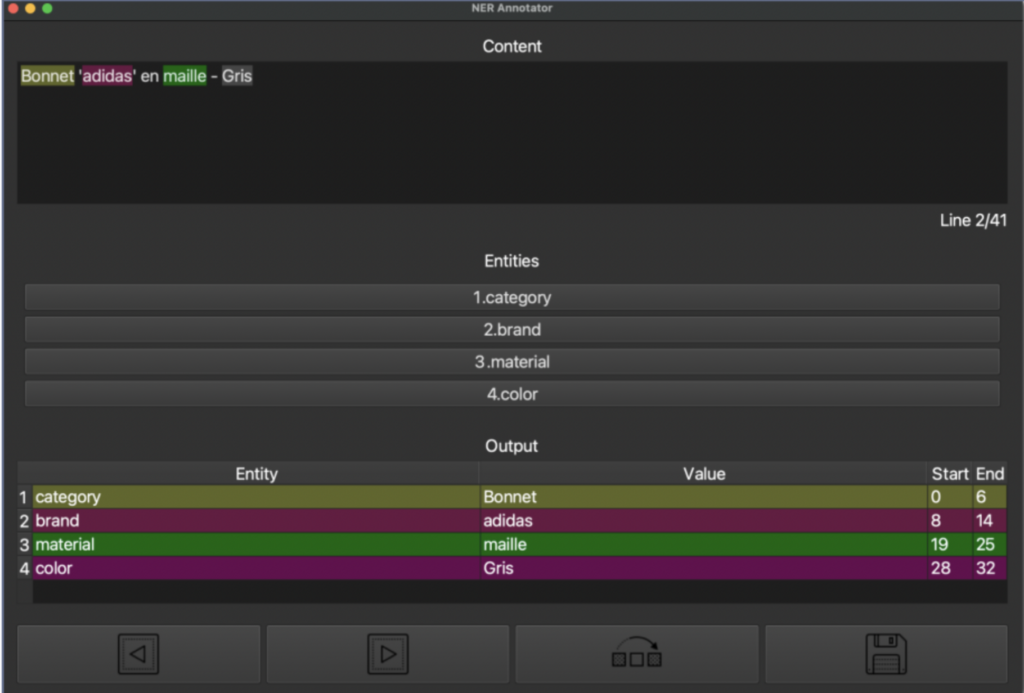
Une fois ce dataset créé, nous devons entraîner notre modèle, en prenant une répartition entrainement/test de 80/20. L’évaluation du modèle est globalement bonne (93.6% au f1-score), seulement notre modèle ne détecte que peu de matières(66.7% au f1-score).
Il est maintenant temps d’utiliser ce modèle pour extraire nos primitive concepts. Grâce à celui-ci, nous en obtenons 70.
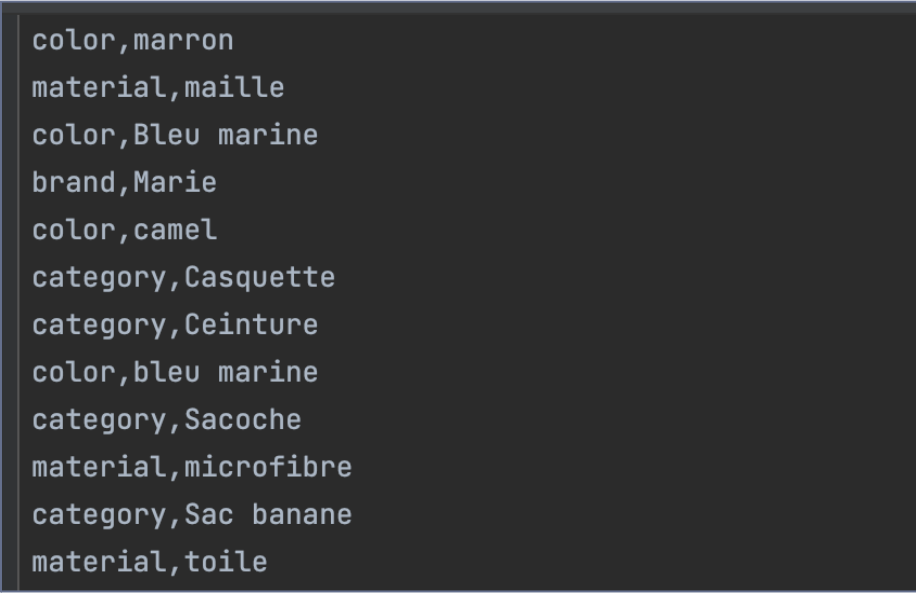
Malgré cette première extraction, certains pans de la taxonomie n’est pas connectée. Il nous manque notamment :
la météo
la partie du corps
la fonction de l’article
Pour combler ce manque, nous allons réaliser manuellement des templates avec ces informations.
json<br>[<br> {<br> "category" : "accessoires",<br> "sub_category": "sac",<br> "function": ["ranger ses affaires", "organiser ses affaires", "transporter des objets"],<br> "keywords" : ["sac", "tote bag", "pochette", "sacoche"]<br> },<br> {<br> "category" : "accessoires",<br> "sub_category": "ceinture",<br> "function": ["serrer", "resserrer"],<br> "body_part": "taille",<br> "keywords" : ["ceinture"]<br> },<br> {<br> "category" : "accessoires",<br> "sub_category": "foulard",<br> "function": ["proteger"],<br> "body_part": "cou",<br> "weather": ["vent", "froid"],<br> "keywords": ["foulard", "tour de coup"]<br> }<br>]<br>
Une fois nos primitive concepts générés, il nous reste à les connecter à notre taxonomie dans une base graph Neo4j.
3. Génération des E-commerce concepts
Dans un premier temps, définissons les règles sémantiques à utiliser.
<function> le/la <body_part>
<function> du/de la/ <weather>
<function> le/la <body_part> du/de la/ <weather>
Ces règles nous servent, via les primitive concepts, à créer nos premiers scénarios d’achat. C’est donc en interrogeant la base sur les primitive concepts que nous générons cette nouvelle couche.
4. Association des items
Pour terminer ce POC, il nous reste à connecter les produits (items) aux e-commerce concepts. Pour cela, commençons par les relier aux primitive concepts. S’en suit, via différentes requêtes Cypher, l’association des items aux e-commerce concepts.
<br>MATCH (pc:PrimitiveConcept)-->(:PrimitiveConcept{label:'taille'}),<br> (pc:PrimitiveConcept)-->(:PrimitiveConcept{label:'serrer'}),<br> (pc)<-[:IS_A*0..]-(:PrimitiveConcept)<-[HAS_CHARACTERISTIC]-(i:item)<br>RETURN id(i)<br> <br>
json<br>[<br> {<br> "title": "apples",<br> "count": [12000, 20000],<br> "description": {"text": "...", "sensitive": false}<br> },<br> {<br> "title": "oranges",<br> "count": [17500, null],<br> "description": {"text": "...", "sensitive": false}<br> }<br>]<br><br>
5. Résultats
Félicitations ! Vous venez de créer votre premier moteur de recherche sémantique.
Notre Knowledge Graph se compose ainsi de :
- 176 noeuds
- 407 relations
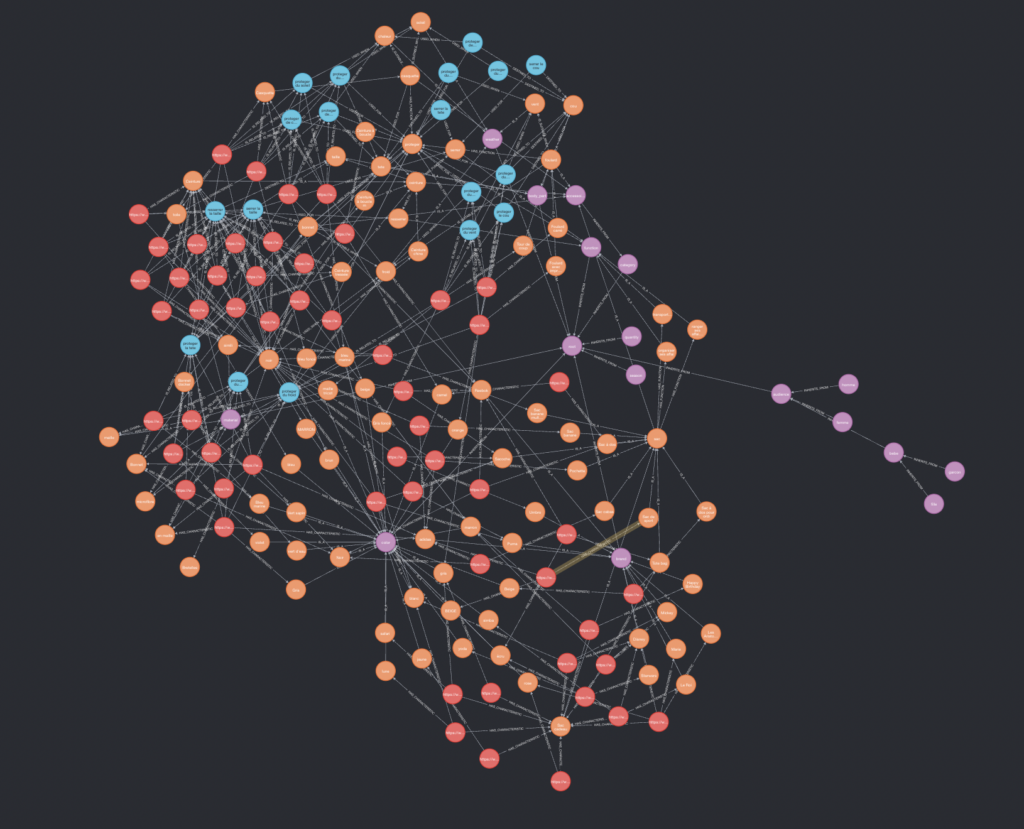
Il ne nous reste qu’à tester le résultat obtenu selon différentes recherches.

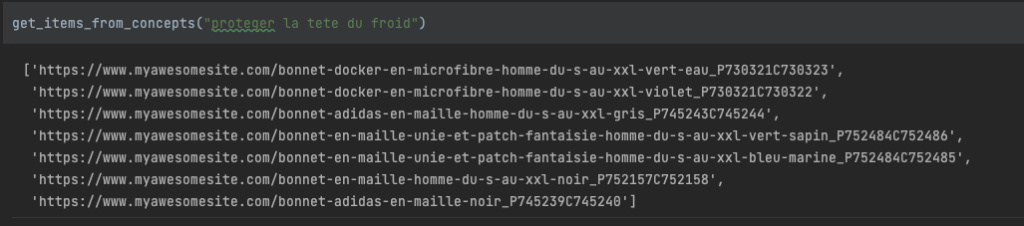
Les résultats obtenus semblent assez prometteurs. Seulement, avez vous bien suivi l’ensemble des étapes ? Cela vous semble-t-il accessible si nous envisageons de travailler sur l’ensemble des articles de la plateforme ? Examinons ensemble les limites actuelles afin de pouvoir envisager une mise à l'échelle de ce modèle.
Limitations du concept AliCoCo
L’une des principales limitations liée à ce concept, est la complexité liée à la création de ce knowledge graph. Comme nous l’avons vu, le domaine sur lequel a été implémenté le POC est très restreint, et a nécessité de nombreuses actions humaines. Si nous prenons par exemple la création de la taxonomie, l’obtenir peut nécessiter de longues semaines de travail. En effet, bien qu'itérative, le plus complexe est de réunir, et mettre d’accord l’ensemble des acteurs sur le vocabulaire du projet.
Aussi, l’extraction des concepts, bien qu’elle puisse être automatisée, nécessite une vérification humaine afin d’être grammaticalement correcte. Dans le papier, Alibaba nous explique utiliser la “foule” pour vérifier la véracité de ces concepts minés par leurs algorithmes.
Enfin, pour être affordant pour nos utilisateurs finaux, notre moteur de recherche doit avoir une base d’e-commerce concepts suffisamment importante. En effet, ces concepts sont les scénarios d’achat utilisateur. Si ils ne sont pas suffisants, ou suffisamment précis, il est probable que l’utilisateur ne perçoive pas les bénéfices de ce système.
Conclusion
A travers cet article, nous avons vu ensemble une première approche de communication Homme-Machine via le langage naturel. Les concepts de moteurs de recherche sémantique semblent être un moyen efficace de parvenir à combler le gap sémantique entre les produits et les besoins utilisateurs, même s’il présente certaines limites. En effet, la construction du Knowledge Graph associé demande beaucoup d’efforts humains pour obtenir un résultat affordant pour l’utilisateur.
Ces derniers mois, nous avons également pu observer l’apparition des Large Language Models, notamment ChatGPT, avec lequel nous pouvons tenir de longues discussions en langage naturel. Dans un prochain article, je vous propose d’étudier ensemble comment nous pourrions utiliser les LLMs pour proposer une sélection d’articles en lien avec le besoin de l’utilisateur.