Até onde podemos ir com um desktop comum e uma aplicação Java reativa para web?

- versão servlet tradicional: uma servlet e chamada para um web service com Apache HttpClient
- versão servlet assíncrona 3.0: uma servlet assíncrona e chamada para um web service com Apache HttpAsyncClient
- versão 100% reativa: servidor HttpCore NIO e chamada de um web service com ApacheAsyncClient
Em seguida colocamos essas três versões sob testes de carga bastante agressivos para ver o que elas poderiam suportar. Como testar? Os testes foram feitos com Apache Benchmark Qual é a carga que queremos? Para se ter uma idéia, eis alguns números dos gigantes da web. Por segundo:
- Google: 33.000 buscas
- Facebook: 41.000 posts, 30.000 likes
- Twitter: 4.600 twits
Fonte: what happens in just ONE minute on the internet Em termos de connexões simultâneas, se considera normalmente que o desafio final para um servidor web é chegar a suportar 10.000 conexões paralelas. É o famoso problema C10K. Podemos ir um pouco mais longe, mas não muito mais, porque o número de portas TCP disponíveis é 65.536. Além disso, o próprio Apache Benchmark suporta no máximo 20.000 conexões simultâneas.
Nosso objetivo: 10.000 conexões simultâneas e 50.000 requests por segundo.
Os testes realizados
A idéia é simular uma aplicação Java para web típica. Para cada consulta do usuário, a aplicação vai acessar um web service e exibir o resultado ao usuário.
Todo o código utilizado para os testes está disponível aqui: https://github.com/fxbonnet/nio-benchmark A máquina usada: um notebook comum (não é um servidor!!)
- Processador Intel Core i7-3517U 1.90GHz 2 cores, 4 hard-threads (hardware threads)
- Ubuntu 13.10 (3.11.0-12.19 Ubuntu Linux kernel)
- Rede: os testes foram locais
- OpenJDK 1.7.0_51 (OpenJDK Runtime Environment (IcedTea 2.4.4) (7u51-2.4.4-0ubuntu0.13.10.1) OpenJDK 64-Bit Server VM (build 24.45-b08, mixed mode))
Preparação da Ferramenta
Primeiro um rápido teste vazio com o Apache Benchmark:
ab -c10000 -n1000000 http://localhost:8081/war/hello This is ApacheBench, Version 2.3 <$Revision: 1430300 @@ARTICLE_CONTENT@@gt; Copyright 1996 Adam Twiss, Zeus Technology Ltd, http://www.zeustech.net/ Licensed to The Apache Software Foundation, http://www.apache.org/
Benchmarking localhost (be patient)
socket: Too many open files (24)
A máquina não está pronta para suportar tantas conexões simultâneas. Alguns ajustes são necessários, à começar pelo aumento de alguns valores no arquivo /etc/security/limit.conf
# Increases the number of open files by user * hard nofile 65536 * soft nofile 65536 root hard nofile 65536 root soft nofile 65536
Segunda tentativa:
ab -r -c10000 -n1000000 http://localhost:8081/war/hello This is ApacheBench, Version 2.3 <$Revision: 1430300 @@ARTICLE_CONTENT@@gt; Copyright 1996 Adam Twiss, Zeus Technology Ltd, http://www.zeustech.net/ Licensed to The Apache Software Foundation, http://www.apache.org/
Benchmarking localhost (be patient)
Test aborted after 10 failures
apr_socket_connect(): Cannot assign requested address (99)
São necessárias configurações mais detalhadas para permitir uma reciclagem mais rápida de portas. Modificamos então o arquivo /etc/sysctl.conf (o arquivo está disponível com o código dos testes no Github). Aproveitamos também para ajustar o tamanho dos buffers assim como outros parâmetros recomendados para suportar tráfego pesado de rede. No mais, vamos também adicionar o argumento -k na linha de comando para que o Apache Benchmark use keep-alive sobre as conexões, o que deve permitir ir mais longe.
Terceira tentativa:
ab -r -k -c10000 -n1000000 http://localhost:8080/ This is ApacheBench, Version 2.3 <$Revision: 1430300 @@ARTICLE_CONTENT@@gt; Copyright 1996 Adam Twiss, Zeus Technology Ltd, http://www.zeustech.net/ Licensed to The Apache Software Foundation, http://www.apache.org/
Benchmarking localhost (be patient) Completed 100000 requests Completed 200000 requests Completed 300000 requests Completed 400000 requests Completed 500000 requests Completed 600000 requests Completed 700000 requests Completed 800000 requests Completed 900000 requests Completed 1000000 requests Finished 1000000 requests
Server Software: Server Hostname: localhost Server Port: 8080
Document Path: / Document Length: 0 bytes
Concurrency Level: 10000 Time taken for tests: 12.004 seconds Complete requests: 1000000 Failed requests: 1529850 (Connect: 0, Receive: 1019900, Length: 0, Exceptions: 509950) Write errors: 0 Non-2xx responses: 49 Keep-Alive requests: 49 Total transferred: 5194 bytes HTML transferred: 0 bytes Requests per second: 83302.25 [#/sec] (mean) Time per request: 120.045 [ms] (mean) Time per request: 0.012 [ms] (mean, across all concurrent requests) Transfer rate: 0.42 [Kbytes/sec] received
Connection Times (ms) min mean[+/-sd] median max Connect: 0 0 0.2 0 227 Processing: 0 116 116.3 120 266 Waiting: 0 0 1.6 0 252 Total: 0 116 116.3 120 477
Percentage of the requests served within a certain time (ms) 50% 120 66% 230 75% 232 80% 233 90% 236 95% 240 98% 246 99% 251 100% 477 (longest request)
Desta vez o teste passa. Podemos observar a utilização de CPU:
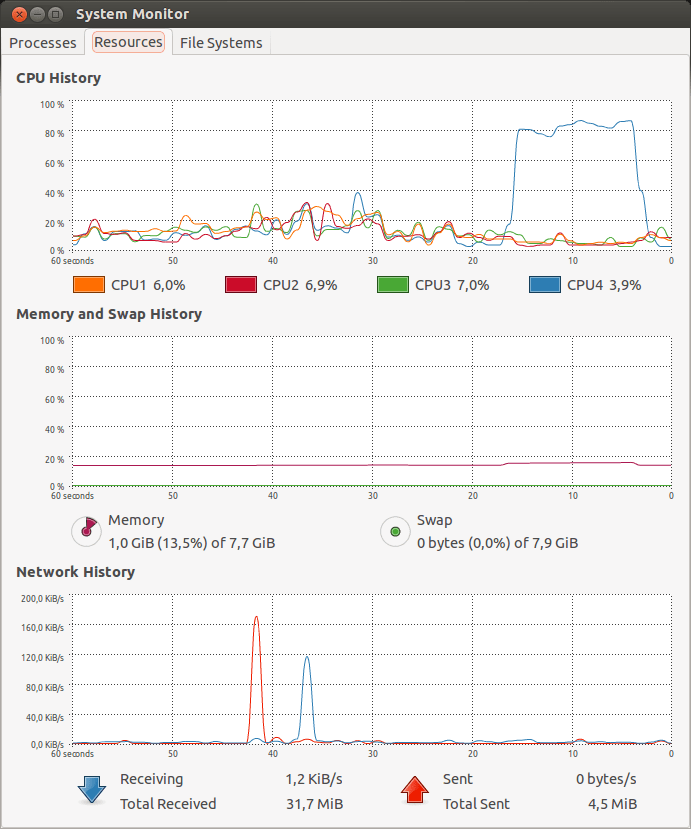
Observamos duas coisas interessantes:
- O Apache Benchmark chega à mais de 83.000 requests/segundo, o que é mais que suficiente para o nosso objetivo
- Ele não chega a usar nem 100% de uma hard-thread, então nossa aplicação poderá usar as 3 outras hard-threads restantes
Preparação do web service usado nos testes
Esse serviço é implementado com ajuda do Apache HttpCore NIO. Ele é monothreaded, o que vai deixar as últimas duas hard-threads para a nossa aplicação a ser testada.
Tecnicamente esse serviço retorna um HTTP response. Poderia ser testado usando um navegador.
Vamos testá-lo com o Apache Benchmark:
ab -r -k -c10000 -n1000000 http://localhost:8081/war/hello This is ApacheBench, Version 2.3 <$Revision: 1430300 @@ARTICLE_CONTENT@@gt; Copyright 1996 Adam Twiss, Zeus Technology Ltd, http://www.zeustech.net/ Licensed to The Apache Software Foundation, http://www.apache.org/
Benchmarking localhost (be patient) Completed 100000 requests Completed 200000 requests Completed 300000 requests Completed 400000 requests Completed 500000 requests Completed 600000 requests Completed 700000 requests Completed 800000 requests Completed 900000 requests Completed 1000000 requests Finished 1000000 requests
Server Software: Server Hostname: localhost Server Port: 8081
Document Path: /war/hello Document Length: 11 bytes
Concurrency Level: 10000 Time taken for tests: 24.268 seconds Complete requests: 1000000 Failed requests: 0 Write errors: 0 Keep-Alive requests: 1000000 Total transferred: 151000000 bytes HTML transferred: 11000000 bytes Requests per second: 41206.84 [#/sec] (mean) Time per request: 242.678 [ms] (mean) Time per request: 0.024 [ms] (mean, across all concurrent requests) Transfer rate: 6076.40 [Kbytes/sec] received
Connection Times (ms) min mean[+/-sd] median max Connect: 0 11 300.7 0 15035 Processing: 55 224 52.3 195 594 Waiting: 55 224 52.3 195 594 Total: 165 235 307.3 195 15381
Percentage of the requests served within a certain time (ms) 50% 195 66% 248 75% 274 80% 279 90% 294 95% 332 98% 351 99% 369 100% 15381 (longest request)
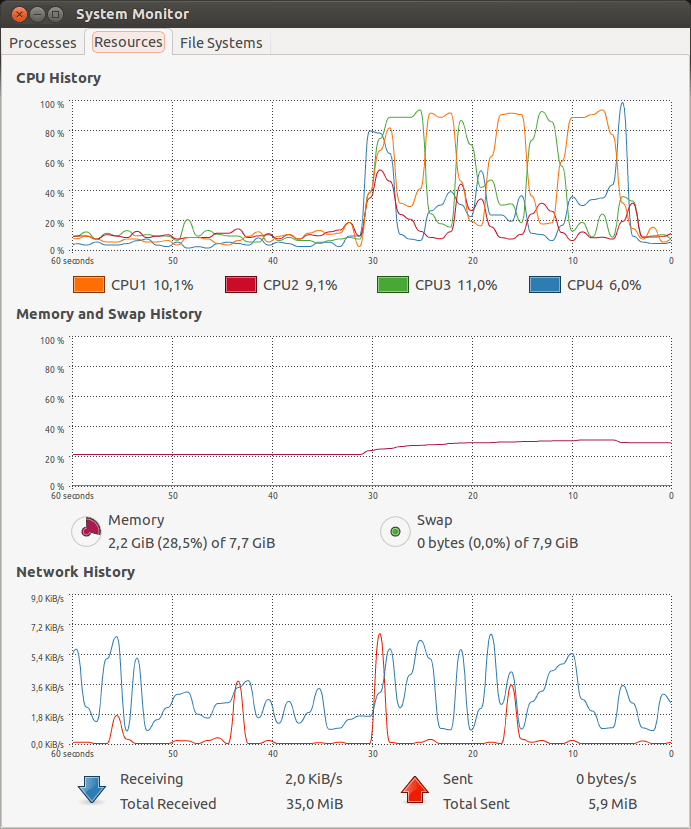
O serviço chega a tratar mais de 40.000 requests/segundo, e sobra CPU suficiente para nossa aplicação de teste.
Preparação das aplicações de teste
Vamos começar pela versão da servlet tradicional:
@Override protected void doGet(final HttpServletRequest request, final HttpServletResponse response) throws IOException { HttpGet httpGet = new HttpGet(HelloServer.SLOW_HELLO_URL); CloseableHttpResponse httpClientResponse = httpClient.execute(httpGet); try { String result = EntityUtils.toString(httpClientResponse.getEntity()); response.getWriter().write(result); } finally { httpClientResponse.close(); } }
Depois a versão servlet assíncrona (as servlets assíncronas surgiram na especificação Servlet 3.0). Para fazê-la realmente reativa, ela usa igualmente um cliente HTTP assíncrono. Por isso o código é um pouco complicado:
@Override protected void doGet(final HttpServletRequest request, final HttpServletResponse response) { final AsyncContext asyncContext = request.startAsync(); HttpGet httpGet = new HttpGet(HelloServer.SLOW_HELLO_URL); FutureCallback<HttpResponse> responseCallback = new FutureCallback<HttpResponse>() { @Override public void completed(final HttpResponse httpClientResponse) { try { String result = EntityUtils.toString(httpClientResponse.getEntity()); response.getWriter().write(result); } catch (IOException e) { sendError(e, response); } finally { asyncContext.complete(); } }
@Override
public void failed(final Exception e) {
sendError(e, response);
}
@Override
public void cancelled() {
}
};
httpClient.execute(httpGet, responseCallback);
}
E por fim a versão 100% reativa, que usa um servidor HttpCore NIO e um cliente HTTP assíncrono:
@Override public void handle(final HttpRequest request, final HttpAsyncExchange httpexchange, final HttpContext context) { HttpGet httpGet = new HttpGet(HelloServer.SLOW_HELLO_URL); FutureCallback responseCallback = new FutureCallback() { @Override public void completed(final HttpResponse httpClientResponse) { try { String result = EntityUtils.toString(httpClientResponse .getEntity()); HttpResponse response = httpexchange.getResponse(); response.setStatusCode(HttpStatus.SC_OK); response.setEntity(new NStringEntity(result, ContentType .create("text/html", "UTF-8"))); httpexchange.submitResponse(); } catch (IOException e) { sendError(e, httpexchange); } }
@Override
public void failed(final Exception e) {
sendError(e, httpexchange);
}
@Override
public void cancelled() {
}
};
httpClient.execute(httpGet, responseCallback);
}
Resultados dos testes
| Configuration serveur | Threads | Application | Hits/s | % erreurs1 |
|---|---|---|---|---|
| Tomcat 8.0.3 connecteur HTTP | 200 | Servlet + HttpClient 4.3.2 | 3 250 | 0,8 |
| Tomcat 8.0.3 connecteur NIO | 200 | AsyncServlet + HttpAsyncClient 4.0.1 | 6 926 | 0,3 |
| Tomcat 8.0.3 connecteur HTTP | 10 000 | Servlet + HttpClient 4.3.2 | 6 456 | 1,3 |
| Tomcat 8.0.3 connecteur HTTP | 10 000 | AsyncServlet + HttpAsyncClient 4.0.1 | 7 433 | 1,7 |
| Tomcat 8.0.3 connecteur NIO | 10 000 | Servlet + HttpClient 4.3.2 | 7 053 | 1,5 |
| Tomcat 8.0.3 connecteur NIO | 10 000 | AsyncServlet + HttpAsyncClient 4.0.1 | 7 405 | 1,6 |
| Tomcat 8.0.5 connecteur NIO | 10 000 | AsyncServlet + HttpAsyncClient 4.0.1 | 3 206 | 0,6 |
| Tomcat 8.0.5 connecteur NIO2 | 10 000 | AsyncServlet + HttpAsyncClient 4.0.1 | 8 108 | 0,05 |
| Jetty 9.1.3 | 200 | Servlet + HttpClient 4.3.2 | 11 834 | - |
| Jetty 9.1.3 | 10 000 | Servlet + HttpClient 4.3.2 | 12 066 | - |
| Jetty 9.1.3 | 200 | AsyncServlet + HttpAsyncClient 4.0.1 | 14 543 | - |
| Jetty 9.1.3 -Xss228k2 | 10 000 | Servlet + HttpClient 4.3.2 | 12 255 | - |
| Jetty 9.1.3 -Xss228k -Xconcurrentio3 | 10 000 | Servlet + HttpClient 4.3.2 | 12 256 | - |
| Jetty 9.1.3 -Xss228k -Xconcurrentio | 10 000 | AsyncServlet + HttpAsyncClient 4.0.1 | 12 664 | - |
| Jetty 9.1.3 -Xss228k -Xconcurrentio | 10 | AsyncServlet + HttpAsyncClient 4.0.1 | 14 065 | - |
| HttpCore NIO 4.3.2 | 1 | HttpAsyncClient 4.0.1 | 16 137 | - |
| HttpCore NIO 4.3.2 | 2 | HttpAsyncClient 4.0.1 | 16 600 | - |
| HttpCore NIO 4.3.2 | 4 | HttpAsyncClient 4.0.1 | 18 291 | - |
1 os erros correspondem a socket timeout, ou seja, quando o Apache Benchmark não recebeu resposta após 30 segundos.
2 a opção -Xss permite definir o tamanho da stack associado a cada thread. Ao reduzí-la, reduz-se a memória usada por cada thread. http://www.oracle.com/technetwork/java/hotspotfaq-138619.html#threads_oom
3 a opção -Xconcurrentio melhora, em teoria, as performances das aplicações que usam um grande número de threads, pelo menos em alguns sistemas. http://www.oracle.com/technetwork/java/hotspotfaq-138619.html#threads_general
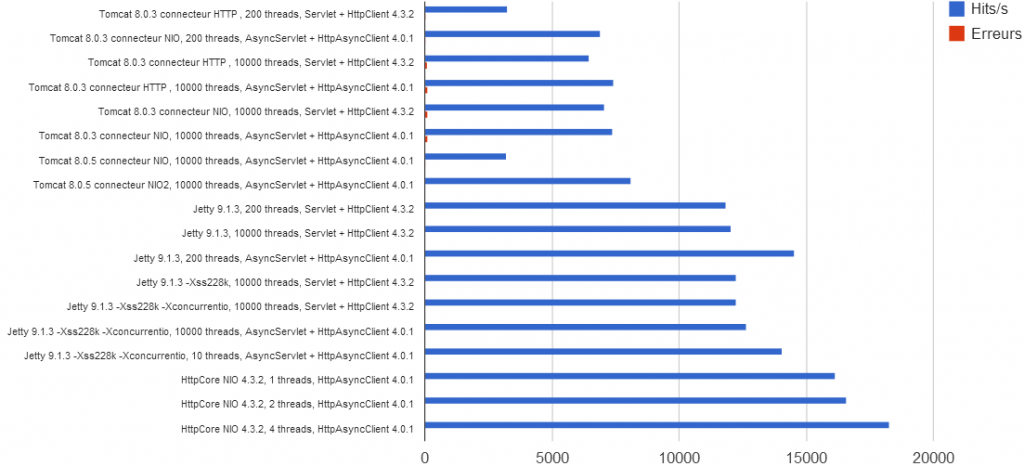
Nota: O Tomcat leva cerca de 30 segundos para encher seu pool com 10.000 threads, e são necessários 2Gb de RAM. Por isso precisamos adicionar a opção -Xmx2048m na inicialização da JVM.
Análise
- O modelo 100% reativo é o que tem melhor performance, com 50% a mais de requests processados em média do que a melhor aplicação tradicional, mesmo bem configurada.
- O modelo servlet assíncrona permite ganhar somente 5% a 20% em relação ao modelo tradicional, talvez por não ser 100% reativo, já que ele entra em modo assíncrono apenas no final do método doGet() e ainda tem que alocar o thread pool do container.
- Para arquiteturas exatamente iguais, uma aplicação reativa terá mais performance com 10 threads do que com 10.000! (ex.: testes com Jetty, com 10 threads 14.065 hits/s, com 10.000 threads 12.664 hits/s, 10% menos).
- Como esperado, os melhores resultados são obtidos ao se dimensionar o número de threads para o mesmo número de hard-threads da máquina (ex.: testes com HttpCore NIO, 18.291 hits/s é o melhor de todos os resultados conseguidos, e não usa mais que 4 threads)
- Onde as aplicações tradicionais precisam aumentar o tamanho do pool de threads e a memória, a própria aplicação reativa configura sozinha por default o número ideal, que é o número de threads disponíveis na máquina, e consome muito pouca memória.
- As aplicações não reativas precisam de um tempo razoável de "aquecimento" (30s) e de mais memória (2Gb). No nosso exemplo, o pico de carga mais pesado causa erros (timeout). Já nas aplicações reativas, o pico é bem comportado.
- Existem grandes diferenças entre os servidores de aplicação (Tomcat ou Jetty), e mesmo de uma versão para a outra. A escolha do conector no Tomcat também tem um grande impacto.
Conclusões
O modelo servlet assíncrona (introduzido na versão 3.0 da especificação de servlet) é interessante porque permite ganhos de performance significativos para os objetivos que se pretende. Por outro lado os servidores de aplicação tradicionais não estão bem preparados para esse tipo de uso, sendo necessário fazer testes e ajustes.
O modelo 100% reativo é o que apresenta melhores resultados (nos nossos testes teve um ganho médio de 50%).
Nós ainda não chegamos nos resultados dos gigantes da web, mas a ordem de grandeza é a mesma (10.000 conexões paralelas, mas somente 18.000 requests/segundo, enquanto nosso objetivo era de 50.000 requests/segundo) mas é preciso lembrar que os testes foram feitos numa máquina de somente 2 cores, 4 threads, que foi usada tanto para rodar a aplicação de teste, o web service de teste e o Apache Benchmark. Por essas razões é um resultado empolgante. Em condições normais seria necessário observar também se a rede tem capacidade de suportar esse fluxo (no nosso caso o teste foi local).
A programação reativa cumpriu o prometido: mais conexões paralelas e mais requests respondidos por segundo utilizando menos memória e menos CPU.
Você quer testar por conta própria? Mais fácil impossível… todo o código usado para os testes está disponível aqui: https://github.com/fxbonnet/nio-benchmark