Architectures composables
Introduction
Concernant l’architecture, l’enjeu phare de cette année 2024 sera de bâtir des architectures composables.
L'architecture composable est un concept qui vise à créer des systèmes flexibles et adaptatifs où les composants peuvent être assemblés et réassemblés - comme un système LEGO® - pour répondre à des besoins spécifiques sans nécessiter de reconstruction complète ou de modifications majeures. Le saint Graal tant espéré dans les DSI pour architecturer leurs systèmes.

Pourquoi maintenant ?
Dans un contexte socio-économique sous tensions qui induit la nécessité d’une efficience opérationnelle accrue, les architectures composables permettent de répondre aux enjeux croissants d’agilité et d'innovation en offrant plusieurs caractéristiques :
- La modularité : les systèmes sont conçus en composants distincts et autonomes qui peuvent être connectés ou déconnectés facilement.
- L’interopérabilité : les composants peuvent interagir les uns avec les autres à travers des interfaces normalisées (API).
- La scalabilité : les systèmes peuvent être découpés en sous-systèmes en corrélation avec des équipes qui en sont responsables.
- La réutilisabilité : les composants sont conçus pour être réutilisables dans différents contextes.
- L’évolutivité : l'architecture permet d'ajouter, de retirer ou de modifier des composants en gardant sous contrôle la complexité.
- Le découplage technologique : chaque composant peut indépendamment tirer parti de technologies et de stacks techniques spécifiques qui répondent aux usages (et combiner une approche « best of breed » BUILD et BUY).
En substance, les architectures composables sont la promesse de pouvoir remplacer ou faire évoluer des parties du système facilement, plutôt que d’avoir à maintenir ou faire évoluer un système global complexe.

MACH Architecture : « One architecture to rule them all ? »

En 2024, les architectures MACH, telles que définies par la MACH alliance, gagnent en popularité. Ce style d’architecture vise à concevoir des systèmes composables, en prônant 4 principes fondamentaux :
- Microservices,
- API-first,
- Cloud-native,
- Headless.
Mais pourquoi diantre en parler en 2024 ? Si ces principes fondamentaux existent depuis longtemps (POO ~1980, SOA ~2000, API REST ~2000-2010, microservices ~2014, cloud computing ~2016), nous assistons aujourd'hui à une stabilisation des pratiques, des principes de conception, des technologies et des écosystèmes sur la base de ces quatres principes fondamentaux qui ont fait leurs preuves.
Si nous ne prônons pas à tout prix la MACH alliance, l'acronyme « MACH », qui a le vent en poupe, a le mérite de poser une vision d’architecture dont l'ambition est d’être la plus « future-proof » possible en bâtissant des systèmes composables, évolutifs et scalables. En outre, nous savons à quel point il est important de définir une vision d’architecture, pour aligner l’ensemble des acteurs tech autour de principes directeurs, afin de donner un cadre de cohérence d’architecture. Il ne faut cependant pas en faire une loi d'airain, et se laisser une liberté dans les choix architecturaux en fonction des besoins qui émergent et savoir sortir du cadre quand cela est nécessaire (voir Architecture pragmatique).
Détaillons maintenant les quatres caractéristiques fondamentales de la MACH Architecture.
Microservices
Définition
Les microservices sont des composants applicatifs autonomes sur un périmètre fonctionnel délimité, mettant en jeu des silos verticaux sur trois couches :
- des interfaces (par exposition API ou via la publication d’événements au travers d’un bus par exemple),
- des règles de gestion (code métier),
- une solution de persistance indépendante.
Les microservices sont pertinents dans les contextes de fort besoin de modularité et/ou, d’indépendance des équipes. Le découpage d'une application en modules de taille plus petite (les microservices) permet en théorie de faciliter l'organisation et le fonctionnement des équipes. Ainsi, une équipe responsable d'un ou plusieurs microservices est totalement autonome sur son périmètre et peut développer et déployer son ou ses composant(s) de manière indépendante.
Les trois promesses phares
- Scalabilité : découper un monolithe qui ne « scale » plus techniquement et organisationnellement, pour « sortir de l’ornière », c’est-à-dire permettre de délivrer fréquemment, sans régressions pour améliorer le time to market.
- Découplage organisationnel : permettre de faire évoluer et déployer un service en limitant les impacts sur les autres systèmes.
- Le service est déployé comme un service isolé.
- Le service peut évoluer indépendamment des autres (tout en respectant un contrat d’interface).
- Découplage technique : chaque composant peut indépendamment tirer parti des technologies et des stacks techniques spécifiques qui répondent aux usages (par exemple une BDD relationnelle ou graph) et de combiner des approches BUILD & BUY.
Les trois points de vigilance
- Maîtrise des systèmes distribués : l’approche microservices, par sa nature distribuée, induit une complexité technique et organisationnelle (souvent sous-estimée) liée à la gouvernance qu’il convient de mettre en place pour assurer la cohérence globale du système. En pratique, l’approche microservices requiert une grande maturité des équipes sur trois domaines de compétences :
- Software Craftsmanship pour gérer la complexité du développement de systèmes distribués (transactions, atomicité, procédures de rattrapage, eventual consistency, troubleshooting, mutation testing, etc).
- Agilité pour gérer la synchronisation des équipes et backlogs (agile at scale, scrum of scrum, etc).
- DevOps pour gérer l'infrastructure as code, le design for failure, l’auto-scaling, tests de charge, chaos monkey, etc.
- L’entropie du SI : L'adoption des microservices impacte fortement la complexité et donc la productivité des développements tant que le système reste simple, par rapport à un monolithe. Ainsi, les architectures microservices repoussent la complexité dans l'intégration inter services et augmentent ainsi l’entropie des SI. L’architecture microservice doit donc être mise en œuvre à partir d’une certaine complexité. (Voir le principe de monolith-first).
- Granularité : Enfin, l’abus de microservices - probablement en raison du nom - a pu entraîner un micro-découpage des systèmes et accroître anormalement la complexité. Ce n’est pas une limite intrinsèque à ce type d’architecture mais plus une mauvaise utilisation du concept par sa systématisation qui résulte souvent d’une approche dogmatique et d’un manque de recul (Voir les notions de granularité et de DDD).
API-first
Définition
L’acronyme « API » pour Application Programming Interface désigne une interface normalisée par laquelle une application offre des services à une autre application.

Aujourd'hui, les entreprises souhaitent partager proposer un accès à leur système d'information via une API. Dans ce contexte, le terme API désigne en fait une Web API, c'est-à-dire la couche d’exposition d’un système sur l'internet, via le protocole HTTPS (en pratique, souvent des API REST ou GraphQL).
Le développement d’une API porte donc essentiellement sur la logique d’exposition des ressources métiers et le système de persistance sous-jacent. Cela comprend la conception des requêtes, des réponses et des formats de données. Une fois l’API définie, les développeurs peuvent créer des applications qui utilisent les ressources exposées. On parle de mashup quand les applications finales reposent sur la composition de plusieurs ressources provenant éventuellement de systèmes disjoints. L'interface utilisateur peut ainsi être développée par des équipes dédiées, expertes dans l'implémentation des parcours utilisateurs et de problématiques telles que l'accessibilité et l'ergonomie.
Le pattern « API-first »implique de commencer par bâtir une API, pour chaque fonctionnalité du système, puis la consommer y compris en interne, aussi bien par des applications back que pour construire les UI destinées aux utilisateurs finaux (souvent des applications web ou mobiles).
Dans une optique d'amélioration continue, l'idée est d'être soit-même utilisateur des services exposés, afin de vivre la même expérience que les clients consommateurs d'APIs, selon le pattern « Eat Your Own Dog's Food », et ce, afin de réduire la boucle de feedback.
En particulier, avec une approche « API-first » :
- On commence par concevoir et définir les API du système que l’on appréhende comme des ressources facilement consommables, puis on implémente les fonctionnalités métier pour soutenir ces API.
- Il ne suffit pas d’exposer via des API les fonctionnalités nécessaires à la couche de présentation (UI) dans le cadre d'une démarche Headless (que nous détaillons plus bas), mais d'offrir une couverture API totale qui couvre l’intégralité des fonctionnalités métier du système**.**
- En particulier, les ressources communes (envoi de mail, édition PDF, etc) deviennent des enablers et accélérateurs pour les applications métiers
Pour aller plus loin
Pour aller plus loin sur la thématiques des API, vous pouvez approfondir trois sujets clés :
- Quelle modélisation pour vos API et comment les designer : API REST ou GraphQL ?
- Comment sécuriser ses API ?
- Comment manager ses API ?
Cloud-native
Définition
Une application cloud-native est une application conçue spécifiquement pour être déployée et exécutée dans un environnement cloud, en tirant pleinement parti des services managés et des avantages offerts par le cloud computing — scalabilité, résilience, élasticité, automatisation des déploiements et doit respecter les twelve-factor app.

Les deux caractéristiques phares
On identifie d’autres caractéristiques clés des applications cloud-native :
- Architecture Microservices : Les applications cloud-native sont généralement conçues selon une architecture distribuée, où différents microservices et fonctions Serverless peuvent fonctionner de manière indépendante, communiquer via des API et être développés et déployés de manière flexible.
- Utilisation de services managés : afin que les développeurs puissent réduire la complexité opérationnelle et se concentrer sur le développement d'applications. Ces services sont génériques et configurables afin de s’adapter facilement aux besoins des produits sans avoir à réinventer la roue à chaque fois et permettent en principe une accélération du time to market :
- Services de calcul :
- Serveurs stateless (Compute Engine, EC2) : des instances de calcul évolutives et configurables pour exécuter des charges de travail.
- Containers as a Service (EKS, GKE, ECS) : pour exécuter des applications conteneurisées.
- Functions as a Service (Lambda, Cloud Functions) : pour exécuter du code sans avoir à gérer les serveurs.
- Services de persistence :
- Stockage objet (S3, Google Cloud Storage) : pour stocker et de récupérer des données.
- Bases de données managées (Amazon RDS, Google Cloud SQL) : pour des bases de données.
- Services de mise en réseau :
- Réseaux privés virtuels (VPC, Virtual Private Cloud) : pour créer un réseau privé isolé dans le cloud.
- Load balancers : pour répartir automatiquement le trafic entre plusieurs instances d'application afin d’assurer une haute disponibilité.
- Les outils plus classiques DNS, CDN, gestion des terminaisons SSL, etc.
- Services de surveillance et de journalisation :
- Services de surveillance (CloudWatch, Stackdriver) : pour surveiller les performances, la disponibilité et l'utilisation des ressources.
- Services de journalisation (Cloud Logging, CloudTrail) : pour collecter, stocker et analyser les journaux d'application et d'infrastructure pour le débogage.
- Services de sécurité :
- Services de gestion des identités et des accès (IAM) : pour gérer les accès aux ressources cloud de manière sécurisée en traitant les aspects authentification et autorisation.
- Services de calcul :
Les quatre points de vigilance
Néanmoins, si l’accélérateur cloud et ses services managés sur étagère sont devenus une nécessité dans de nombreux cas pour répondre aux enjeux d’agilité, d’accélération du time to market et d**'innovation**, il convient d’aborder le sujet move to cloud de manière holistique, en intégrant notamment les aspects :
- De maîtrise des coûts et volumétrie (désamorcer via une stratégie FinOps une facture cloud qui peut grimper en fonction du trafic),
- De souveraineté au regard des données manipulées et du contexte métier,
- De risques de vendor lock-in / cloud lock-in,
- De l’expertise des équipes in situ sur le DevOps et les Hyperscalers.
Pour aller plus loin
- Les enjeux du Cloud en 2023 : quels choix pour quels besoins ?
- Les légendes du Cloud : mythes et réalités
- Pour un move to cloud ... sans casse :)-1)
Headless
La caractéristique la moins galvaudée de l'acronyme MACH est probablement l'aspect Headless !

« Le Headless, c’est couper la tête ! »
Définition
L’architecture Headless consiste à séparer la couche de présentation de la couche business et contenu, qui est exposée via des API omnicanales et agnostiques du terminal utilisateur.
Un chantier « Going headless » consiste donc à passer d’un système monolithique à un écosystème « best of breed » pour permettre de livrer de manière indépendante les composants front et back, et d'offrir des expériences premium aux utilisateurs sur l’ensemble des touchpoints et canaux digitaux.

Les trois promesses phares
- ATAWAD : en séparant la couche de présentation de la couche business et contenu que l'expose via des API omnicanales et agnostiques du terminal, nous apportons une réponse concrète aux enjeux « l’ATAWAD » : Anytime, Anywhere , Any Device. Cela nous permet de délivrer une expérience cohérente sur tous les touchpoints, ou que soient nos utilisateurs, en concevant autant de frontaux digitaux que nécessaire qui viennent consommer une même couche API.
- Offrir des expériences premium dans un monde où les paradigmes UI évoluent à vitesse grand V. Ainsi les frontaux digitaux sont souvent des front-end web ou des applications mobiles, mais aussi des devices IoT voire des assistants conversationnels LLM basés sur de l’IA générative qui semblent se multiplier et pourraient impacter à terme la manière dont nous bâtissons nos interfaces utilisateurs.
- Amélioration du T2M et de l’agilité : Améliorer la réactivité et la souplesse pour répondre aux besoins business souvent marketing.
Les trois points de vigilance
- Pour la partie frontend
- Une UI responsive et mobile first basée sur une bibliothèque de composants
- Une accessibilité totale
- La prise en compte des contraintes SEO
- L’optimisation de la webperf
- Pour la partie CMS Headless
- La migration de données depuis le CMS intégré
- La formation des contributeurs marketing sur les nouveaux workflow de publication
- Pour la partie Core business
- L’exposition des données et services via API (voir API-first)
Pour aller plus loin
- Mardi 21/05 de 9h15 à 10h : S’inscrire au Comptoir OCTO - Headless
Architecture pragmatique
Comme abordé à la section MACH Architecture : One architecture to rule them all ?, il est important de rester pragmatique et de se laisser une liberté dans les choix techniques en fonction des besoins qui émergent et savoir sortir du cadre quand cela est nécessaire.
Appliquer sans discernement les principes des architectures MACH et sans tenir compte du contexte peut être contre-productif et amener à des solutions trop complexes (ou trop tôt) au regard des besoins réels.

« Si le seul outil que vous avez est un marteau, vous tendez à voir tout problème comme un clou ». — Abraham Maslow
Un des principes fondamental lié à cette approche pragmatique est de prendre des décisions au moment où c'est nécessaire :
- Il est rarement pertinent d’essayer d’anticiper l’ensemble des besoins futurs; ceux-ci évoluent régulièrement et les décisions prises un an à l’avance ne sont souvent plus adaptées quand il faut les mettre en œuvre un an plus tard.
- La « Continous architecture » que nous détaillons dans ce papier porte cette approche d’architecture pragmatique, en se focalisant sur les besoins architecturaux réels drivés par les besoins métiers avérés.
Monolith first & Majestic monolith
Démarrer avec un monolithe, quitte à le découper plus tard, est une approche pragmatique. Martin Fowler l’a constaté : les architectures microservices qui ont réussi sont souvent parties d’un monolithe : https://martinfowler.com/bliki/MonolithFirst.html
Partir d’un monolithe permet de repousser la définition des périmètres des microservices à un moment où notre expérience sur le fonctionnement réel du système permettra de déterminer les domaines pour lesquels un microservice apporte plus de valeur que la complexité qu’il génère.
En outre, le monolithe permet dans un premier temps de se concentrer sur le fait d’apporter de la valeur métier et d’aller vite, pour par la suite, être découpé en services supportant les différents domaines métier.
Partir d’un monolithe certes, mais un monolithe modulaire, évolutif : l’apprentissage de l’usage est crucial pour savoir comment modulariser son monolithe avec un design émergent. Préparer le découpage en séparant les zones de responsabilités entre les différentes couches métiers mais aussi techniques. On parle alors de « monolithe modulaire » ou de « majestic monolith ».
Il faut se souvenir que les architectures microservices fonctionnent bien dès lors que les frontières sont stables entre les services. Toute refactorisation de fonctionnalités entre services est beaucoup plus difficile que dans un monolithe. Même les experts sur un domaine métier maîtrisé ont des difficultés à fixer des limites dès le départ du projet. D’où l’idée de démarrer avec un monolithe modulaire et ensuite aller vers des architectures microservices si besoin.
Pour rappel, les microservices constituent une architecture utile, avec pour conséquence une entropie du SI qui augmente, ainsi qu’une complexité et des coûts accrus.
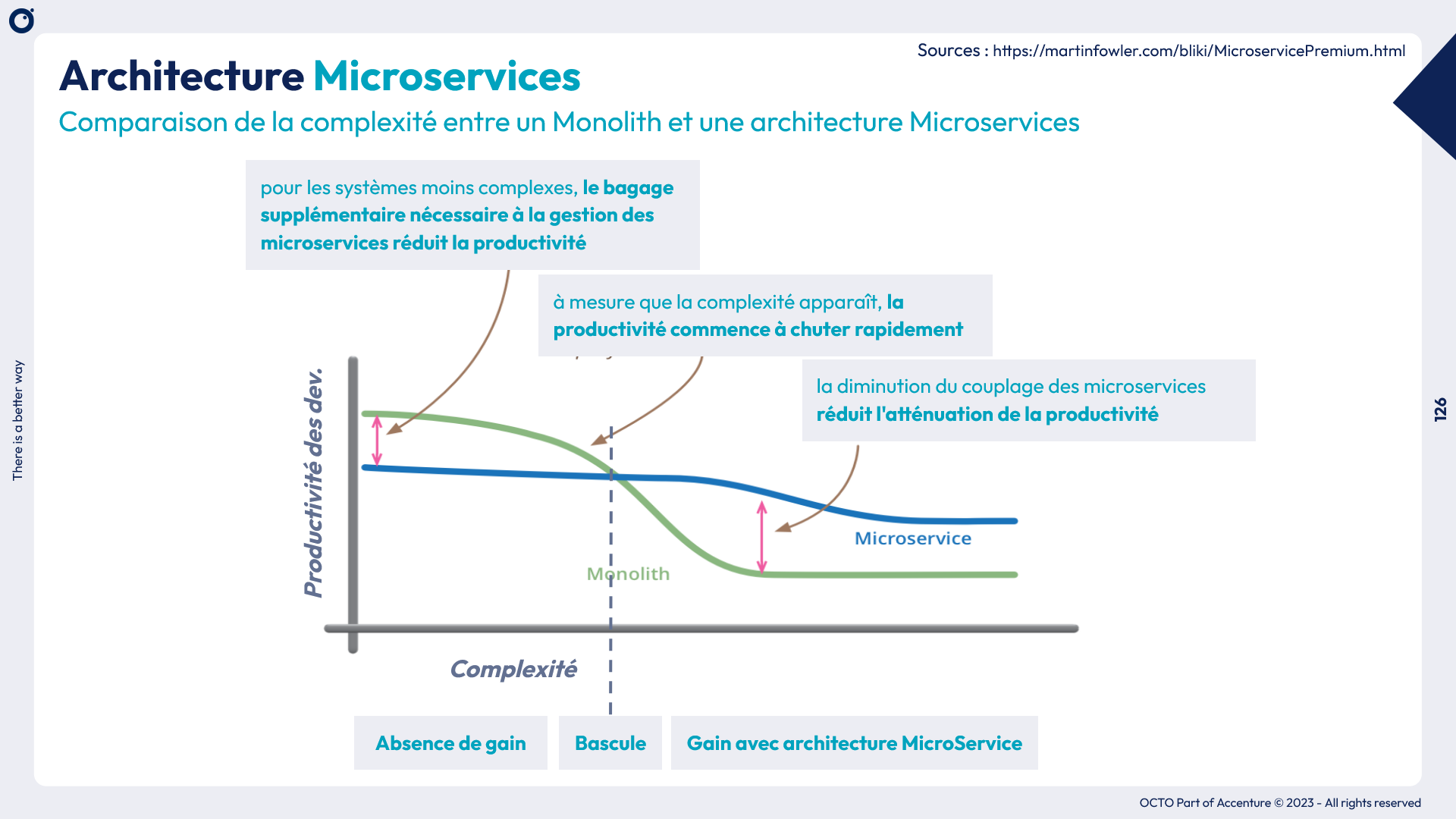
Comparaison de la complexité entre un Monolith et une architecture Microservices
(Sources : https://martinfowler.com/bliki/MicroservicePremium.html)
Enfin, il est possible que certains composants du système n'aient en définitive pas besoin de la scalabilité ou de l'indépendance offertes par les microservices, et dans ce cas, on pourrait choisir de conserver ces composants dans une architecture monolithique.
Granularité et DDD (Domain Driven Design)
Lorsque l’on découpe son système en sous-systèmes, la question de la granularité est primordiale, et nos retours d’expérience ont démontré qu’il fallait à tout prix éviter un hyper-découpage par services/ressources avec une granularité trop fine. Imaginez un instant un système découpé en 1000 microservices exposant chacun une route (endpoint API) avec sa base de données dédiée. 🤯
Il y a donc une notion de « bonne granularité » pour le découpage en microservices, qui est souvent plus celle d’un découpage par domaines métier (DDD), avec une API documentée dont le versionning garantit aux utilisateurs que les appels entre les différents endpoints fonctionnent. Il ne faut donc pas se focaliser sur le terme “micro” de “microservices” et plutôt se focaliser sur un découpage en services autonomes et cohérents, sans présupposer de leur taille qui oriente le découpage, celui-ci devant être plus métier que technique.
“In general, microservices should cleanly align to bounded contexts.”
— Sam Newman, Building Microservices
Le DDD (https://www.octo.academy/catalogue/formation/ddd01-ddd-domain-driven-design/) propose des outils pour identifier et délimiter les domaines métiers. Les Bounded Contexts (BC) sont idéaux pour définir les domaines dans les modèles de CleanArchi ou Archi hexagonale. Un BC représente une partie de la solution, correspondant à un ou plusieurs domaines métier, porte une responsabilité spécifique, délimité par des frontières explicites. Un Bounded Context contient des modèles purement internes ainsi que des modèles ou fonctionnalités partagées avec l’extérieur (son interface). Ce type de découpage apporte à la fois un couplage faible car chaque BC expose une interface (et non son modèle interne) et une cohésion métier car les BC épousent les contours des domaines métiers.
Il convient donc de rester pragmatique dans l’approche de découpage d’un système en sous-systèmes.
Event Driven Architecture (EDA) vs API
Par ailleurs, dans la mise en œuvre d’une architecture MACH, il arrive que la mise en œuvre de composants API-first ne soit pas la solution la plus adaptée et qu’une architecture événementielle soit plus pertinente sur certains composants.
Pour essayer de démêler le pour et le contre de la gestion par événement ou par appel d’API, on peut analyser comment gérer le besoin de transactions distribuées dans une architecture à base de microservices.
Le pattern SAGA est vu comme la solution au défi posé par les transactions distribuées. Ce pattern décompose une transaction en plusieurs petites transactions gérables. SAGA ne maintient pas les propriétés ACID sur une grande transaction sur plusieurs systèmes techniques. Chaque petite transaction respecte les propriétés ACID, et le pattern SAGA assure la cohérence globale de l’opération via un mécanisme de gestion de statut et de transactions de compensation au sein d’un workflow.
Il y a deux manières de coordonner une SAGA : l’orchestration et la chorégraphie.
Le premier, l’orchestrateur gère l'enchaînement du workflow qui peut comporter du parallélisme. Le deuxième, dans la chorégraphie, chaque service émet un événement pour déclencher la suite du workflow. Les événements peuvent être traités par un ou plusieurs services.
L’orchestrateur comme le chorégraphe peuvent avoir des logiques “séquentielles” ou “parallèles”.
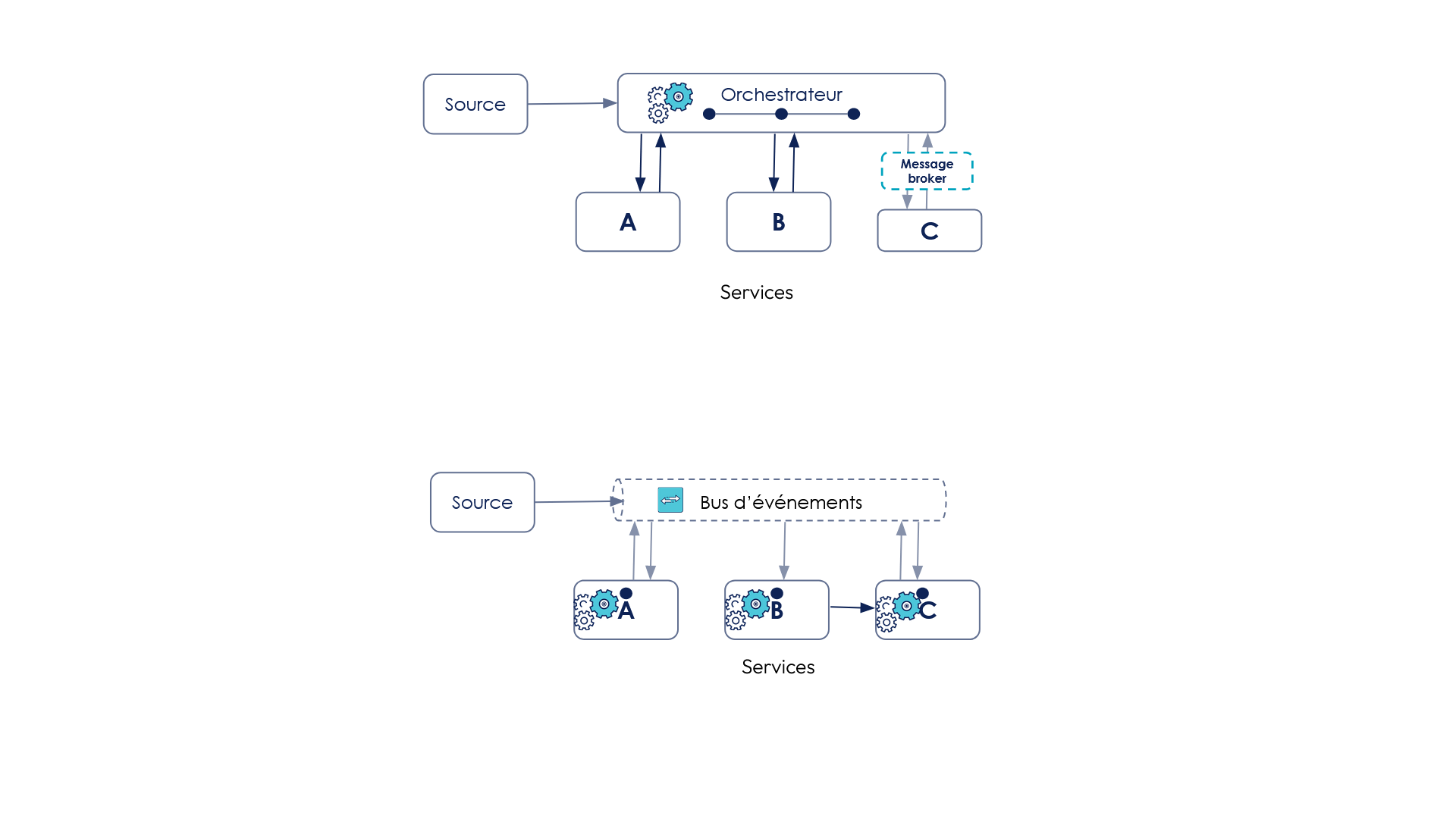
Il y a deux manières de coordonner une SAGA : l’orchestration et la chorégraphie.
Ok mais so what? On y vient !
L’orchestrateur permet de faire des appels “synchrone” (appels d’API par exemple). L’orchestration, consiste en un enchaînement d’actions orchestrés par un coordinateur central qui va contacter dans l’ordre les différents services par appels synchrones (API vers A et B) ou par messages asynchrones (ici vers C).
- Avantages (+)
- Plus facile à tester et à concevoir au sein d’un système centralisé,
- Simplification des services sous-jacents
- Inconvénients (-)
- Il faut gérer la scalabilité et la haute dispo (SPOF), cela peut nécessiter d’avoir un “produit” pour gérer un orchestrateur comme un moteur de workflow (build/buy)
- Qui dit central dit organisation / équipe supplémentaire pour le maintenir
En chorégraphie : les systèmes applicatifs (A, B, C) se débrouillent entre eux; chaque service s'exécute indépendamment en fonction des événements émis par les autres services (publiés dans un bus ou envoyés directement). Pour une transaction distribuée, chaque service publie des événements en retour et doit prévoir un mécanisme de compensation si une étape assurée par un autre service se termine de manière anormale.
- Avantages (+)
- Couplage faible,
- Scalabilité
- Inconvénients (-)
- Garantie de cohérence, observabilité, gouvernance plus difficile
- La gestion des compensations fonctionnelles peut être très compliquée à gérer : en cas d’erreur dans un des services → nécessité un retour arrière sur d’autres applications impliquées dans le workflow. Il est donc nécessaire, avec ce pattern, de mettre en place des mécanismes de rollback, pas au niveau transactionnel de la persistance, mais au niveau du code applicatif.
Enfin, concernant les approches Event-driven, avec la popularisation de la démarche event storming, nous avons également rencontré des cas où les événements étaient utilisés de manière systématique pour tous les échanges entre composants, y compris en local sous prétexte que cela réduisait le couplage ! Hors cela entraînait une complexité inutile. Là aussi il convient de rester pragmatique en employant le pattern d’architecture adapté au besoin.
Conclusion
En 2024, on assiste à l’essor des architectures MACH. Ce style d’architecture a précisément l’ambition de concevoir des systèmes composables et propose une vision d’architecture basée sur quatre patterns d’architecture éprouvés : Microservices, API-first, Cloud-native et Headless.
Cette architecture peut apporter des bénéfices et donner un cap, si l’on sait rester pragmatique en sachant éviter le piège d’un micro-découpage et en se laissant la liberté de sortir du cadre quand cela est pertinent.

Croquerez-vous dans la BIG MACH Architecture ?
Pour aller plus loin sur les Tech Trends : téléchargez OCTO Pulse, la publication qui prend le pouls de la tech !