Architecture Hexagonale : trois principes et un exemple d'implémentation
Documentée en 2005 dans son blog par Alistair Cockburn, l’Architecture Hexagonale est une architecture logicielle qui a beaucoup d’avantages et connaît depuis 2015 un regain d’intérêt.
L’intention originale de l’Architecture Hexagonale est :
Allow an application to equally be driven by users, programs, automated test or batch scripts, and to be developed and tested in isolation from its eventual run-time devices and databases.
Soit en français :
Permettre à une application d’être pilotée aussi bien par des utilisateurs que par des programmes, des tests automatisés ou des scripts batchs, et d’être développée et testée en isolation de ses éventuels systèmes d’exécution et bases de données.
Pour explorer l'intérêt qu'il y a à piloter une application par des tests automatisés, et à la développer et tester en isolation de sa base de données par exemple, je vous conseille cette série sur la pyramide des tests : La pyramide des tests par la pratique.
La promesse est donc assez séduisante, et elle a un autre effet bénéfique : elle permet d’isoler le cœur de métier d’une application et de tester automatiquement son comportement indépendamment de tout le reste. Pas étonnant que cette architecture ait tapé dans l'œil des praticiens de Domain-Driven Design (DDD). Attention, DDD et l’architecture hexagonale sont deux notions bien distinctes qui peuvent se renforcer mutuellement mais qui ne sont pas nécessairement utilisées ensemble. Mais ça, c’est un sujet pour une autre fois !
Pour finir, cette architecture n’est pas très compliquée à mettre en place car elle s’appuie sur des règles et principes simples et peu nombreux. Je vous propose d’explorer ces principes pour voir ce que ça implique concrètement.
Principes de l’Architecture Hexagonale
Détail : Comment on organise le code à l’intérieur et à l’extérieur ?
Détail : Au Runtime
Détail : Inversion de Dépendances à droite
Détail : Pourquoi une Interface à gauche ?
Tester en Architecture Hexagonale
Pour aller plus loin
Références
Principes de l’Architecture Hexagonale
L’architecture hexagonale s’appuie sur trois principes et techniques :
- Séparer explicitement User-Side, Business Logic et Server-Side
- Les dépendances vont vers la Business Logic
- On isole les frontières par des Ports et Adapters
Note sur le vocabulaire : dans toute la suite de l’article, on utilisera les expressions User-Side, Business Logic et Server-Side. Elles viennent de l’article original et sont expliquées dans la section ci-dessous.
Principe : Séparer User-Side, Business Logic et Server-Side
Le premier principe est de séparer explicitement le code en trois grandes zones formalisées.
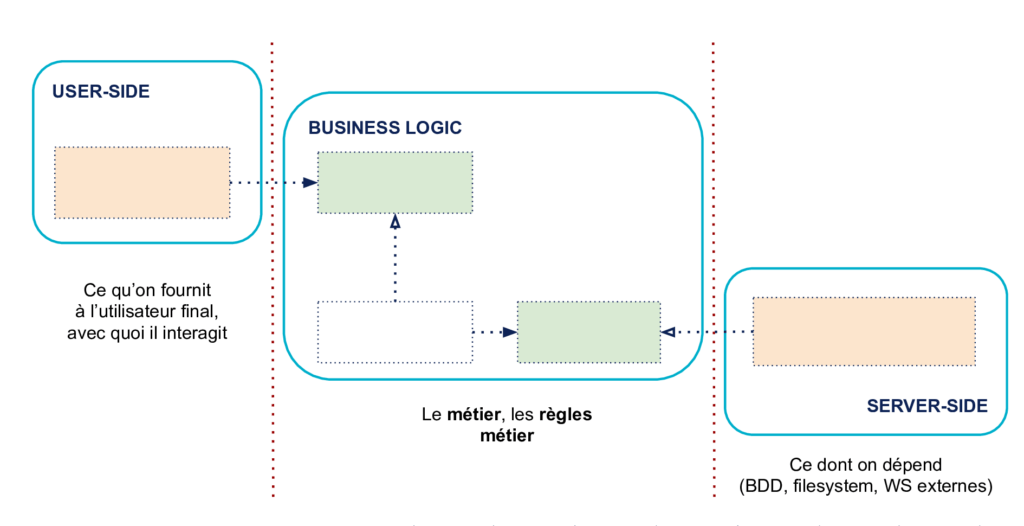
À gauche, la zone User-Side
C’est le côté par lequel l’utilisateur ou les programmes extérieurs vont interagir avec l’application. On y trouve le code qui permet ces interactions. Typiquement, votre code d’interface utilisateur, vos routes HTTP pour une API, vos sérialisations en JSON à destination de programmes qui consomment votre application sont ici.
C’est le côté où l’on retrouve les acteurs qui pilotent la Business Logic.
Note : Alistair Cockburn parle aussi de Left Side.
Au centre, la Business Logic
C’est la partie que l’on veut isoler de ce qui est à gauche et à droite. On y trouve tout le code qui concerne et implémente la logique métier. Le vocabulaire métier et la logique purement métier, ce qui se rapporte au problème concret que résout votre application, tout ce qui en fait la richesse et la spécificité est au centre. Dans l’idéal, un expert du métier qui ne sait pas coder pourrait lire un bout de code de cette partie et vous pointer une incohérence (true story, ce sont des choses qui pourraient vous arriver !).
Note : C'est l'Hexagone dont parle Alistair Cockburn ! Il parle aussi de Center pour cette zone.
À droite, la zone Server-Side
C’est ici qu’on va retrouver ce dont votre application a besoin, ce qu’elle pilote pour fonctionner. On y trouve les détails d’infrastructure essentiels comme le code qui interagit avec votre base de données, les appels au système de fichier, ou le code qui gère des appels HTTP à d’autres applications dont vous dépendez par exemple.
C’est le côté où l’on retrouve les acteurs qui sont pilotés par la zone Business Logic.
Note : Alistair Cockburn parle aussi de Right Side.
Les principes qui suivent vont permettre de mettre en pratique cette séparation logique entre User-Side, Business Logic et Server-Side.
Pourquoi c’est important ?
Une première caractéristique importante de cette séparation est qu’elle sépare les problèmes. À tout moment, on peut choisir de se concentrer sur une seule logique, presque indépendamment des deux autres : la logique applicative, la logique métier, ou la logique infrastructure. On les comprend plus facilement sans les mélanger, et les contraintes de chaque logique a moins d’impact sur les autres.
Une autre caractéristique est qu’on met la logique métier en avant dans notre code. On peut l’isoler dans un répertoire ou un module pour la rendre explicite pour tous les développeurs. On peut la définir, la raffiner et la tester sans embarquer la charge cognitive du reste du programme. C’est important car, au final, c’est la compréhension du métier par les développeurs qui part en production.
Et, pour finir, en terme de tests automatisés (comme on va le voir plus bas), on va réussir à tester avec un effort raisonnable :
- Toute la Business Logic unitairement,
- L’intégration entre User-Side et Business Logic - sans le Server-Side
- L’intégration entre Business Logic et Server-Side - sans le User-Side
Illustration : un petit exemple d’application
Pour illustrer plus concrètement ces principes, on va reprendre le petit exemple utilisé lors de la soirée Alistair in the “Hexagone*”*, proposée en 2017 par Thomas Pierrain (@tpierrain) et Alistair Cockburn (@TotherAlistair) en personne. Note : vous trouverez les vidéos et le code de l'événement en fin d'article.
L’objectif de cette petite application est de fournir un programme en ligne de commande qui écrit des poèmes dans la sortie standard de la console.
Exemple d’utilisation souhaitée :
<br>$ ./printPoem<br>Here is some poem:<br>I want to sleep<br>Swat the files<br>Softly, please.<br>-- Masaoka Shiki (1867 - 1902)<br>Type enter to exit...<br>
Pour illustrer correctement les trois zones (User-Side, Business Logic, Server-Side), cette application ira chercher des poèmes dans un système extérieur : un fichier. On pourrait aussi brancher cette application sur une base de données, les principes seraient identiques.
Dans ce contexte, comment appliquer ce premier principe, à savoir la séparation en trois zones ? Comment répartir le code à gauche (ce qui pilote), au centre (le cœur de métier) et à droite (ce qui est piloté) ?
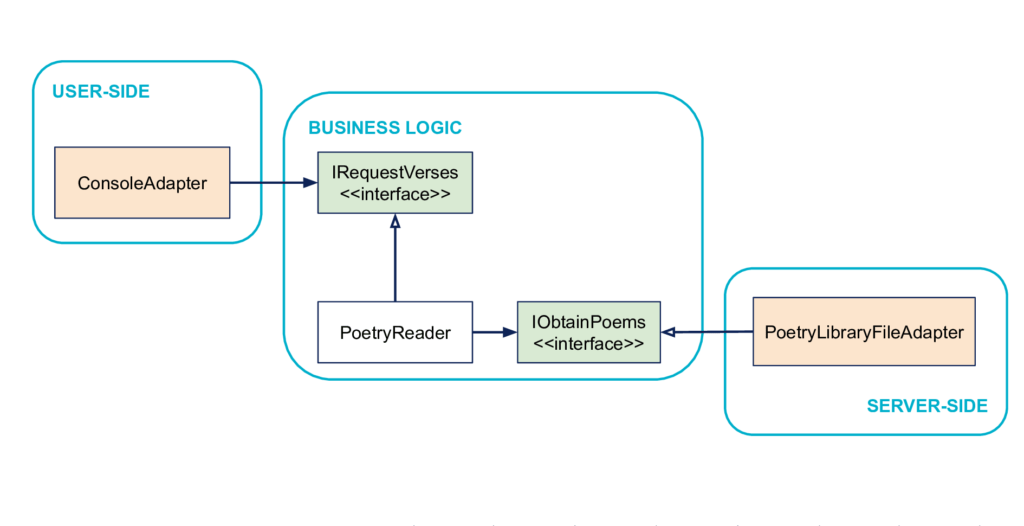
Côté User-Side
Du point de vue de l’utilisateur, le programme se présente comme une application console. Donc la notion de console sera à gauche, du côté User-Side. C’est par la console que l’utilisateur va piloter le métier.
Côté Server-Side
Techniquement, dans notre cas les poèmes sont stockés dans un fichier. Cette notion de fichier va se retrouver à droite, du côté Server-Side. Le métier va effectuer la demande de ses poèmes en pilotant ce côté droit, concrètement implémenté par un PoetryLibraryFileAdapter.
Ici, comme évoqué plus haut, on peut facilement interchanger notre source de poèmes (un fichier, une base de données, un web service...). L'implémentation réelle de la source sous forme de fichier est donc un détail technique (aussi appelé un détail technique d'implémentation)
La Business Logic
Notre cœur de métier dans ce cas, ce qui a de la valeur pour l’utilisateur, c’est la notion de lire des poèmes. On peut matérialiser cette notion dans le code avec une classe PoetryReader par exemple.
Interaction User-Side → Business Logic
Du point de vue métier, peu importe que la demande vienne d’une application console ou autre, c’est un détail technique dont on souhaite pouvoir s’abstraire. C’est précisément une des intentions initiales : “être piloté aussi bien par un utilisateur que par des tests”. Il n’y a donc pas de notion de console dans la Business Logic. Ce que permet notre application en revanche, du point de vue de l'utilisateur (= le service qu'elle lui rend) c'est de demander des poèmes. C'est donc cette notion que l'on va retrouver dans la Business Logic (matérialisé par IRequestVerses) et qui va permettre au côté User-Side d’interagir avec la Business Logic.
Interaction Business Logic → Server-Side
De même, du point de vue Business Logic, peu importe que les poèmes viennent d’un fichier ou d’une base de données, on souhaite pouvoir tester notre application indépendamment des systèmes extérieurs. Pas de notion de fichier dans la Business Logic donc. Pour fonctionner, le métier a tout de même besoin d’obtenir les poèmes. On retrouve donc cette notion d’obtenir des poèmes dans la Business Logic sous la forme de l’interface IObtainPoems. C’est cette notion d’obtenir des poèmes qui va permettre au métier d’interagir avec la zone Server-Side.
Note : à partir d’ici, quand vous lisez les schémas, vous pouvez commencer à observer les flèches qui montrent les relations entre les classes. Une flèche pleine représente une interaction de type appel ou composition. Et une flèche sans remplissage représente une relation d’héritage (comme en UML). Mais pas besoin de tout analyser tout de suite, on va l’explorer en détail plus loin.
Note : les noms IRequestVerses et IObtainPoems représentent bien des interfaces, on en parlera dans un principe à suivre. Pour l’anecdote, la convention de commencer le nom d’une interface par un “i” n’est plus à la mode mais Thomas Pierrain lit les noms des interfaces comme des phrases à la première personne du singulier. IRequestVerses se lit : I request verses par exemple. J’aime bien cette idée.
Principe : les dépendances vont vers l’intérieur
C’est un principe essentiel pour arriver à l’objectif. On a déjà commencé à le voir lors du principe précédent.
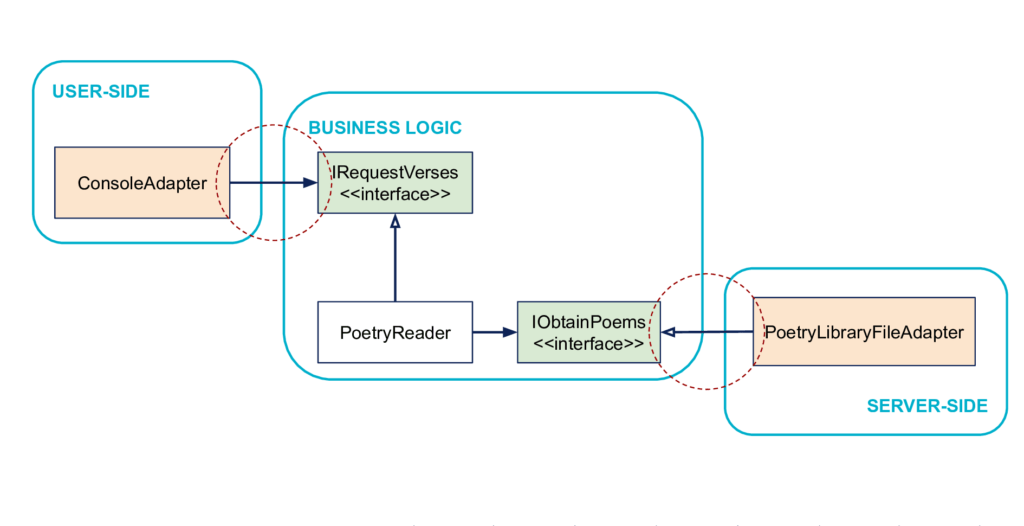
Principe : Les dépendances vont vers la Business Logic
Pour qu’on puisse piloter le programme aussi bien par la console que par des tests, on ne trouve pas de notion de console dans la Business Logic. Donc la Business Logic ne dépend pas du côté User-Side**, c’est le côté** User-Side qui dépend de la Business Logic. Le côté User-Side (ConsoleAdapter) dépend de la notion de demande de poèmes, IRequestVerses (qui définit un mécanisme générique de “demande de poèmes” de la part de l’utilisateur).
De même, pour qu’on puisse tester le programme indépendamment de ses systèmes extérieurs, la Business Logic ne dépend pas du côté Server-Side**, c’est l’inverse : c’est la zone** Server-Side qui dépend de la Business Logic, à travers la notion d’obtenir des poèmes, IObtainPoems. Techniquement une classe du côté Server-Side va hériter de l’interface définie dans la Business Logic et l’implémenter, on va le voir en détails plus loin pour parler d’inversion de dépendances.
Intérieur & Extérieur
Si on voit les relations de dépendance (<<dépend de...>>) comme des flèches, ce principe définit donc la Business Logic au centre comme un intérieur, et tout le reste comme un extérieur (voir figure). On retrouve régulièrement ces notions d’intérieur et d’extérieur quand on discute d’architecture hexagonale. Ça peut même être le point fondamental à retenir et transmettre : les dépendances vont vers l’intérieur.
Autrement dit, tout dépend de la Business Logic**, la** Business Logic ne dépend de rien. Alistair Cockburn insiste sur cette démarcation entre intérieur et extérieur, qui est plus structurante que la différence entre User-Side et Server-Side pour résoudre le problème initial.
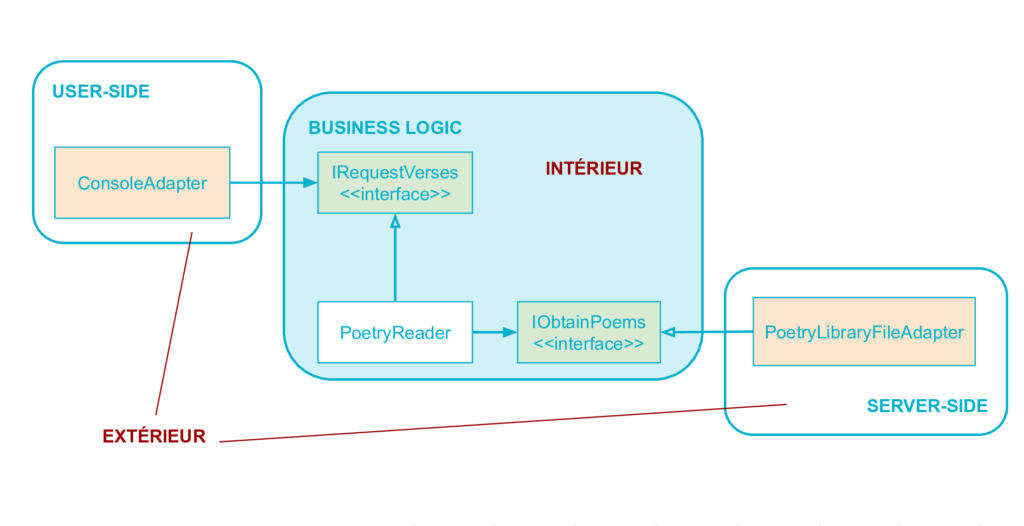
Principe : on isole les frontières par des interfaces
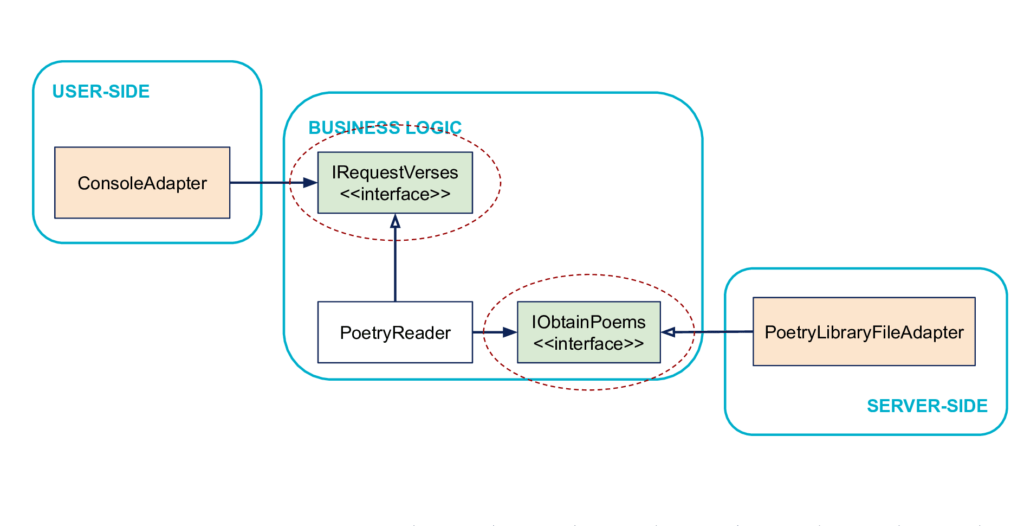
Pour résumer, le code User-Side pilote le code métier à travers une interface (ici IRequestVerses) définie dans le code métier. Et le code métier pilote le code Server-Side à travers une interface définie aussi dans le code métier (IObtainPoems). Ces interfaces jouent le rôle d’isolants explicites entre intérieur et extérieur.
Une Métaphore : Ports & Adapters
L’architecture hexagonale utilise la métaphore de ports et d’adapters pour représenter les interactions entre intérieur et extérieur. L’image est que la Business Logic définit des ports, sur lequel on peut brancher de manière interchangeable toutes sortes d’adapters, à condition qu’ils suivent la spécification définie par le port.
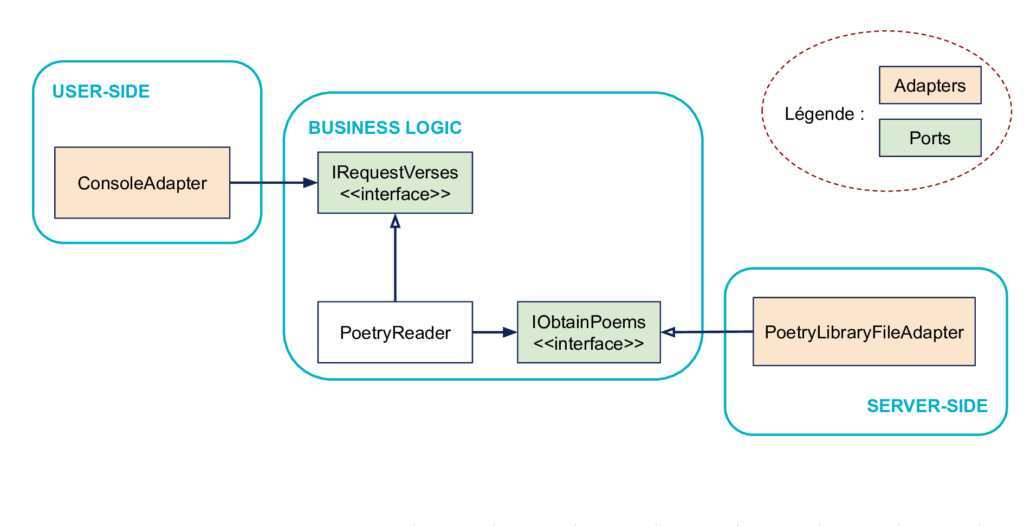
Par exemple, on peut imaginer un port de la Business Logic sur lequel on va brancher soit une source de donnée codée en dur pendant un test unitaire, soit une vraie base de données dans un test d’intégration. Il suffit de coder les implémentations et les adapters correspondants côté Server-Side, la Business Logic n’est pas impactée par ce changement.
Ces interfaces définies par le code métier, qui isolent et permettent les interactions avec l’extérieur sont donc les ports de la métaphore Ports & Adapters. Note : comme mentionné ci-dessus, les ports sont définis par le métier, ils sont donc à l’intérieur.
Les adaptateurs, eux, représentent le code à l’extérieur qui fait la glue entre le port et le reste du code applicatif ou infrastructure. Ici, les adaptateurs sont respectivement ConsoleAdapter et PoetryLibraryFileAdapter. Ces adaptateurs sont à l’extérieur.
Autre Métaphore : l’Hexagone
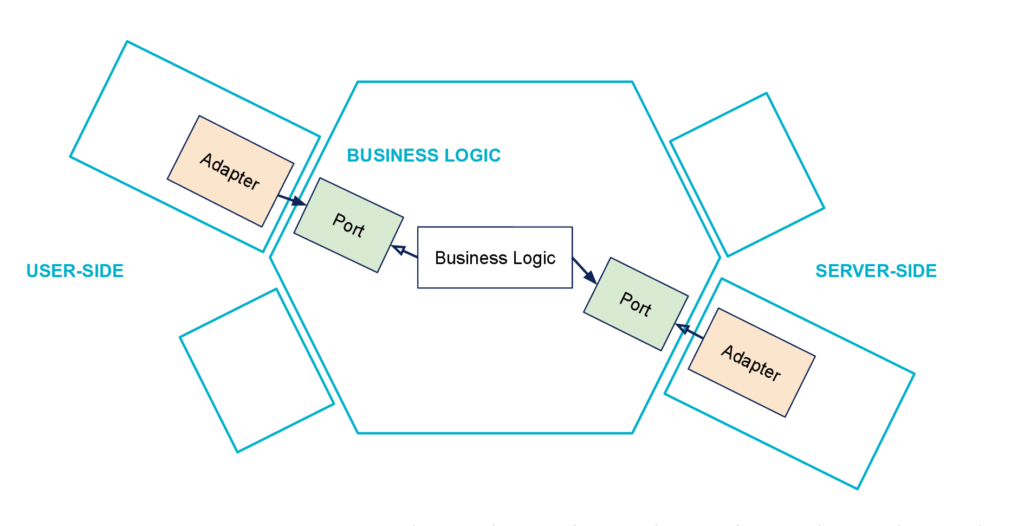
Une autre métaphore qui a donné son nom à cette architecture et celle de l’hexagone, comme on le voit sur la figure précédente. Pourquoi un hexagone ? La raison principale est que c’est une forme facile à dessiner qui laisse la place pour représenter plusieurs ports et adapters sur les schémas. Et il se trouve que même si l’hexagone est assez anecdotique au final, l’expression Hexagonal Architecture est plus populaire que Ports & Adapters Pattern. Sans doute parce-que ça sonne mieux ?
La partie théorique est terminée, il n’y a pas d’autres principes : pour tout le reste, on est libre.
Détail : Comment on organise le code à l’intérieur et à l’extérieur ?
À part les principes vus ci-dessus, on est totalement libre d’organiser le code à l’intérieur de chaque zone exactement comme on le veut.
Concernant le code métier par exemple, l’intérieur, une bonne idée est de choisir d’organiser ses modules (ou répertoires) en fonction de la logique métier.
Une organisation à éviter est de regrouper les classes par types. Par exemple le répertoire des “ports”, ou le répertoire des “repositories” (si vous utilisez ce pattern), ou le répertoire des “services”. Pensez 100 % métier dans votre code métier, y compris pour l’organisation de vos modules ou répertoires ! L’idéal est de pouvoir ouvrir un répertoire ou un module de la logique métier et de comprendre tout de suite les problèmes métier que votre programme résout; plutôt que de ne voir que des répertoires “repositories”, “services”, ou autre “managers”.
Voir aussi à ce sujet :
- https://medium.com/@msandin/strategies-for-organizing-code-2c9d690b6f33
- https://martinfowler.com/bliki/PresentationDomainDataLayering.html
Détail : Au Runtime
Comment instancier tout ça pour satisfaire les dépendances au runtime au juste ? Si vous utilisez un framework d’injection de dépendances, vous n’aurez peut-être pas besoin de vous poser cette question. Mais je pense que pour bien comprendre l’architecture hexagonale, c’est intéressant de voir ce qui se passe au démarrage de l’application. Et pour ce faire, de ne pas utiliser de framework d’injection de dépendances au moins le temps de cet article.
Par exemple, voilà comment on écrira le point d’entrée de l’application si on instancie tout à la main :
<br>class Program<br>{<br> static void Main(string[] args)<br> {<br> // 1. Instantiate right-side adapter(s) ("I want to go outside the hexagon")<br> IObtainPoems fileAdapter = new PoetryLibraryFileAdapter(@".\Rimbaud.txt");<br><br> // 2. Instantiate the hexagon<br> IRequestVerses poetryReader = new PoetryReader(fileAdapter);<br><br> // 3. Instantiate the left-side adapter(s) ("I want ask/to go inside the hexagon")<br> var consoleAdapter = new ConsoleAdapter(poetryReader);<br><br> System.Console.WriteLine("Here is some...");<br> consoleAdapter.Ask();<br><br> System.Console.WriteLine("Type enter to exit...");<br> System.Console.ReadLine();<br> }<br>}<br>
L’ordre d’instanciation est typique, de droite à gauche :
- On instancie d’abord le côté Server-Side, ici le
fileAdapterqui va lire le fichier. - On instancie la classe du Business Logic qui va être pilotée par l’application, le
poetryReaderdans lequel on injecte lefileAdapterpar injection dans le constructeur. - On instancie le côté User-Side, le
consoleAdapterqui va piloter lepoetryReaderet écrire dans la console. Ici on injecte à son tour lepoetryReaderdans leconsoleAdapterpar injection dans le constructeur.
On avait pourtant dit que l’intérieur ne devait pas dépendre de l’extérieur ! Alors pourquoi est-ce qu’on injecte le fileAdapter, qui est du code venant du Server-Side, dans le poetryReader qui est du code appartenant à la Business Logic ?
On peut le faire car, en regardant les schémas et le code, en plus d’être un PoetryLibraryFileAdapter (côté Server-Side), le fileAdapter est aussi une instance de IObtainPoems par héritage.
En pratique, le PoetryReader ne dépend donc pas de PoetryLibraryFileAdapter mais bien de IObtainPoems, qui est bien définie dans la Business Logic. On peut le vérifier en regardant la signature de son constructeur.
<br>public PoetryReader(IObtainPoems poetryLibrary)<br>{<br> this.poetryLibrary = poetryLibrary;<br>}<br>
PoetryLibraryFileAdapter et PoetryReader sont donc faiblement couplés.
Détail : Inversion de Dépendances à droite
Le fait que le fileAdapter dépende du métier pour sa définition (dépendance par héritage ici), mais qu’au runtime le poetryReader puisse contrôler en pratique une instance de fileAdapter est un cas classique d’inversion de dépendances.
En effet, sans l’interface IObtainPoems, le code métier dépendrait du Server-Side pour sa définition, ce qu’on veut éviter :
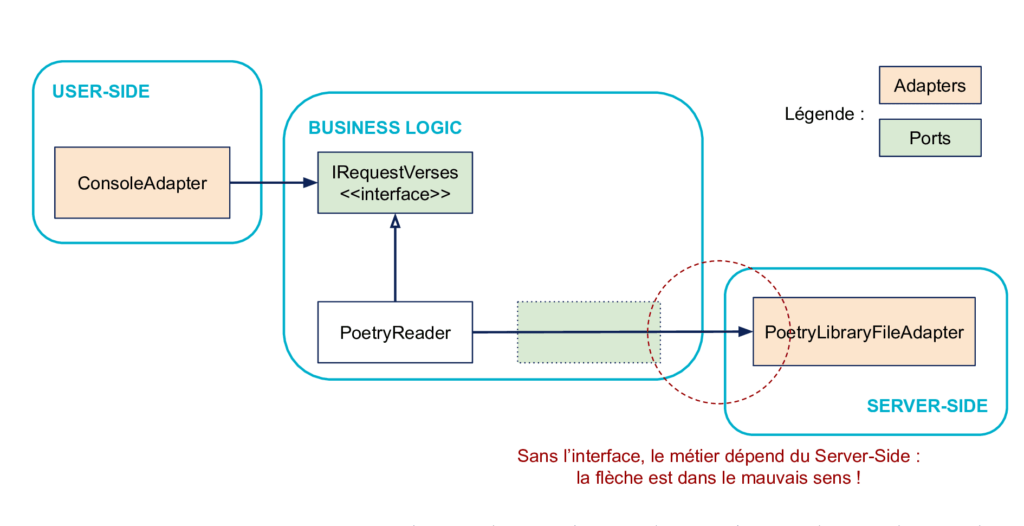
L’interface permet d’inverser le sens de cette dépendance :
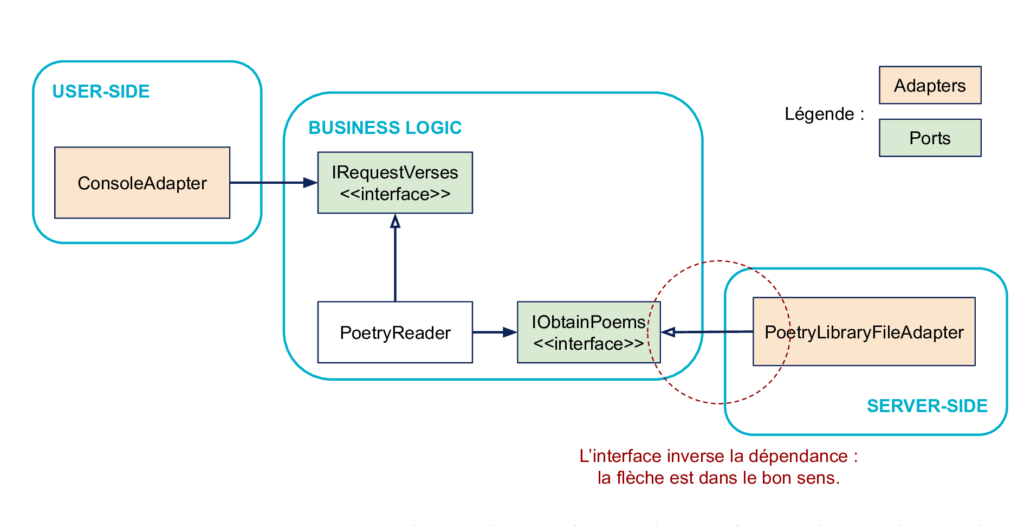
En plus de rendre le métier indépendant des systèmes extérieurs, cette interface à droite permet de satisfaire le fameux D de SOLID, ou Dependency Inversion Principle. Ce principe dit :
- Les modules de haut niveau ne doivent pas dépendre des modules de bas niveau. Les deux doivent dépendre d'abstractions.
- Les abstractions ne doivent pas dépendre des détails. Les détails doivent dépendre des abstractions.
Si on n’avait pas l’interface, on aurait un module de haut niveau (la Business Logic) qui dépendrait d’un module de bas niveau (le Server-Side).
Note : pour les interactions entre côté gauche et code métier, la dépendance est naturellement dans le bon sens.
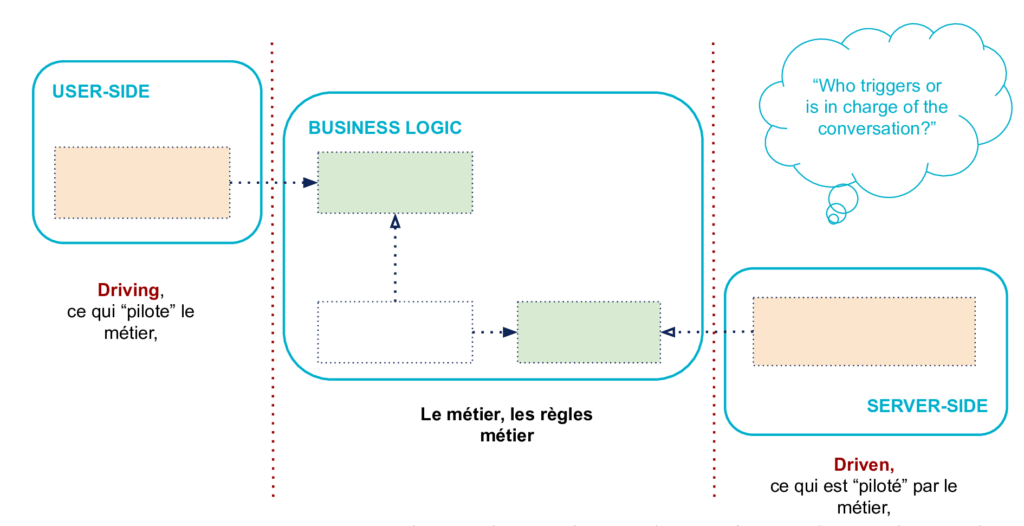
Cette différence dans l’implémentation des interactions est liée à la différence entre les relations User-Side - Business Logic et Business Logic - Server-Side. Rappel : la zone User-Side pilote (drives) la Business Logic, et le côté Server-Side est piloté (driven by) par la Business Logic.
Détail : Pourquoi une Interface à gauche ?
Puisque les dépendances entre User-Side et Business Logic sont déjà dans le bon sens, le rôle de l’interface IRequestVerses n’est pas d’inverser les dépendances.
Pourtant, elle a quand même un intérêt : celui de limiter explicitement la surface de couplage entre le code User-Side et le code Business Logic.
En effet, en pratique la classe PoetryReader peut avoir d’autres méthodes que celles de l’interface IRequestVerses. Il est important que le ConsoleAdapter n’en ait pas connaissance.
Et il se trouve que c’est aussi aligné avec un autre principe de SOLID, Interface Segregation Principle.
Clients should not be forced to depend on methods they do not use.
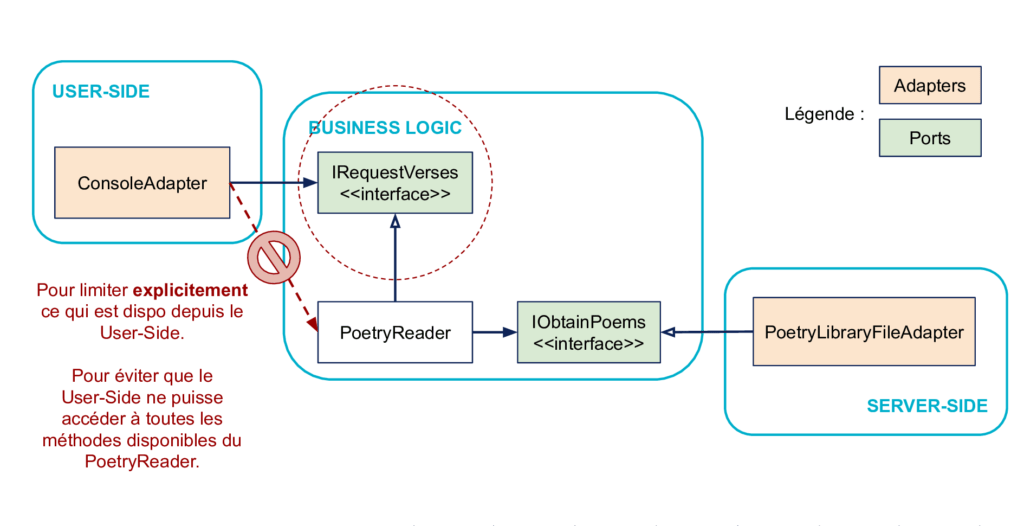
Mais une fois qu’on a saisi l’intention, si un port vers le côté gauche n’a qu’une méthode, et que son implémentation n’a qu’une méthode comme dans notre exemple, est-ce que l’interface est réellement nécessaire ? À fortiori dans un langage dynamique qui va fonctionner par duck typing au final ?
On peut répondre par une question : qu’en pense votre équipe ? Est-ce que l’objectif d’isolation est bien clair pour tout le monde, pas besoin d’interface pour ne serait-ce que déclencher une conversation ? À vous de décider ensemble.
Tester en Architecture Hexagonale
Un bénéfice important de cette architecture logicielle est qu’elle facilite l’automatisation des tests, ce qui fait partie de son intention initiale.
Et on va retrouver la notion de “qui pilote qui”, soit la question : “who is in charge or triggers the conversation?” qui va nous aider à structurer nos tests automatiques.
Comment remplacer le code du côté User-Side ?
Dans le cas général, le rôle du code de gauche peut être directement joué par le framework de test. En effet, le code de test peut directement piloter le code de la logique métier.
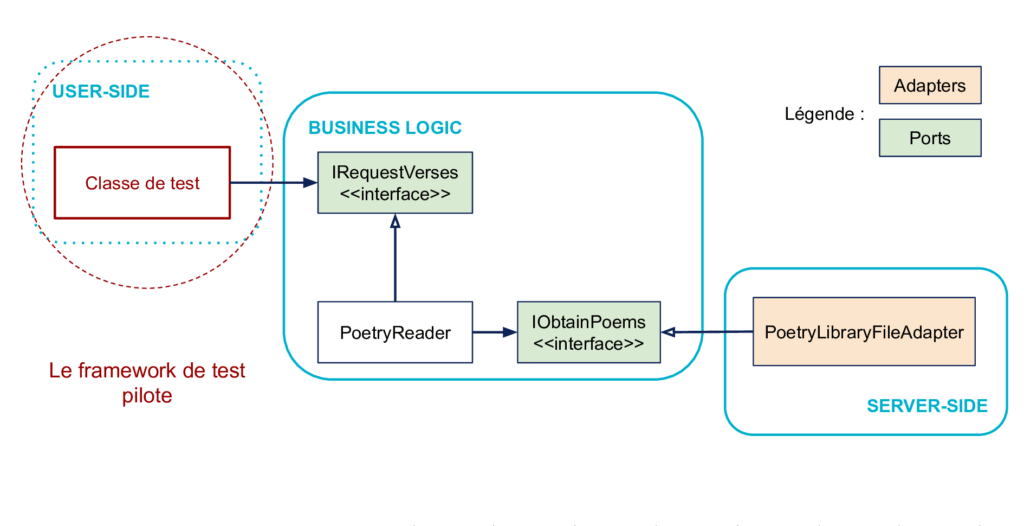
Note : la figure illustre un test d’intégration car la partie droite n’est pas remplacée. On peut aussi la remplacer, voir ci-dessous.
Comment remplacer le code du côté Server-Side ?
Le code de droite doit être piloté par le métier. En général, si on souhaite écrire un test unitaire, on le remplace par un mock ou toute autre forme de test double en fonction de ce qu’on veut tester.
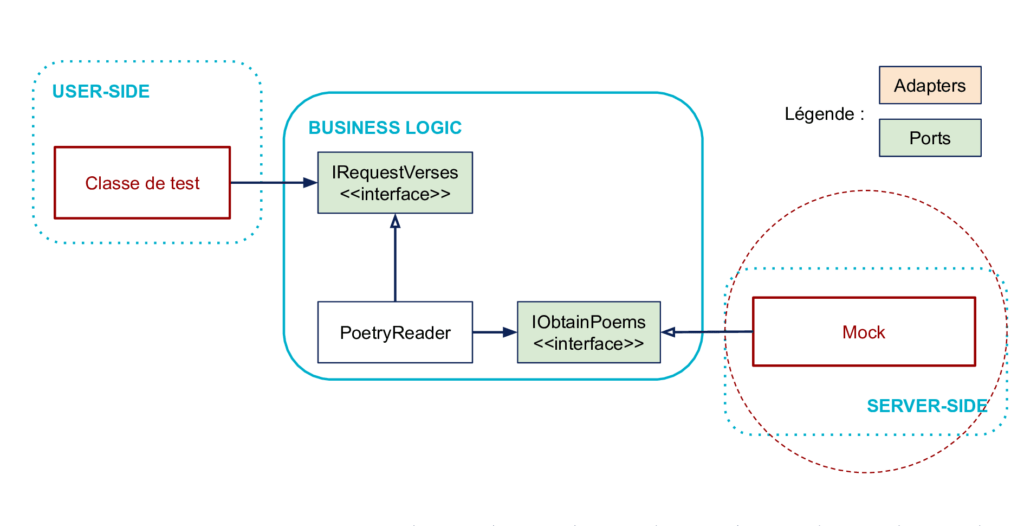
Objectif atteint !
Permettre à une application d’être indifféremment pilotée par des utilisateurs, des programmes, des tests automatisés ou des scripts batchs, et d’être développée et testée en isolation de ses éventuels systèmes d’exécution et bases de données.
Et attention ! Ça n’empêche pas de tester automatiquement votre code User-Side et Server-Side, tout code mérite d’être testé automatiquement. Sur ce sujet, je vous renvoie à nouveau vers la série La pyramide des tests par la pratique.
Et en effet, en combinant ce qu’on remplace ou pas, on voit qu’avec cette architecture on peut tester ce qu’on voulait :
- Toute la Business Logic unitairement,
- L’intégration entre User-Side et Business Logic, indépendamment du côté Server-Side
- L’intégration entre Business Logic et Server-Side, indépendamment du côté User-Side
Pour aller plus loin
Parlez-en en équipe, qui sait déjà faire chez vous ?
Lancez-vous, expérimentez en vrai, sur votre code. Un petit projet perso par exemple, ou un petit projet avec votre équipe. Qu’est-ce qui est facile pour vous, qu’est-ce qui est difficile ?
Voici quelques questions supplémentaires que vous pourrez vous poser pendant l’implémentation :
- Un port peut n’avoir qu’une seule méthode, ou regrouper plusieurs méthodes. Qu’est-ce qui est logique dans votre cas ?
- Même quand il suit bien les principes de dépendances, le code n’est pas nécessairement séparé en trois modules ou répertoires ou packages ou namespaces explicites. Comme dans le code de Thomas Pierrain, j’ai vu plusieurs fois la Business Logic rangée dans un répertoire "Domain*",* et le code User-Side et Server-Side rangé dans un répertoire "Infrastructure". Dans son exemple, l’intérieur est rangé dans le namespace
HexagonalThis.Domainet l’extérieur regroupé dans le namespaceHexagonalThis.Infra.
Rappel : il n’y a pas de silver bullet. L’architecture hexagonale est un bon compromis complexité / puissance, et c’est aussi une très bonne manière de découvrir les sujets qu’on a abordés. Mais ce n’est qu’une solution parmi d’autres. Pour des cas simples, c’est peut être trop compliqué, et pour des cas compliqués, c’est peut être trop simple. Et il y a d’autres architectures logicielles qui valent le coup d’être explorées. Par exemple, la Clean Architecture va plus loin dans la formalisation et l’isolation (avec un zeste de SOLID supplémentaire). Ou bien dans un axe différent mais compatible, CQRS permet de mieux séparer lectures et écritures.
Références
Les vidéos de l’événement Alistair in the "Hexagone*"* sont ici.
Le code de l’événement est sur le github de Thomas Pierrain.
Lisez également ces bons articles sur le sujet :
https://martinfowler.com/bliki/PresentationDomainDataLayering.html
http://blog.cleancoder.com/uncle-bob/2016/01/04/ALittleArchitecture.html
Pour finir, merci à Thomas Pierrain pour m’avoir autorisé à réutiliser son exemple de code, et merci pour les suggestions et les relectures à : Etienne Girot, Jérôme Van Der Linden, Jennifer Pelisson, Abel André, Nelson Da Costa, Simon Renoult, Florian Cherel Enoh, Mathieu Laurent, Mickael Wegerich, Bertrand Le Foulgoc, Marc Bojoly, Jasmine Lebert, Benoît Beraud, Jonathan Duberville et Eric Favre.
Note de mise à jour : dans une première version de l'article, nous avions utilisé les mots Application, Domain et Infrastructure en remplacement de User-Side, Business Logic et Server-Side. Nous sommes revenus au vocabulaire original car cette substitution était ambiguë et inutile.