Apprentissage par renforcement : de la théorie à la pratique
Au travers de multiples exemples, et dans la continuité des articles traitant de l’apprentissage automatique, nous allons explorer le domaine de l’apprentissage par renforcement. Ces méthodes inspirées du vivant permettent aujourd’hui de faire faire à des agents automatisés d’étonnantes tâches dans un cadre de programmation très générique.
Nous allons notamment voir et analyser :
- un robot qui adapte sa façon de marcher en fonction de l’état du sol,
- un groupe d’ascenseur qui cherche à satisfaire au mieux les utilisateurs,
- un robot qui apprend à maintenir un bâton en équilibre instable, un autre qui retourne les pancakes
- un exemple d’application d’apprentissage par renforcement pour les SI
Ces exemples spectaculaires d’applications de l’apprentissage par renforcement me poussent à croire qu’il est parfois possible de piloter un système complexe par des règles simples. En utilisant un modèle suffisamment riche et des algorithmes implémentant ces méthodes de renforcement, nous pouvons fabriquer des agents adaptatifs qui masquent la complexité de leur environnement …
Introduction
L'apprentissage par renforcement se manifeste tous les jours dans notre quotidien, que ce soit lorsque nous marchons, lorsque nous apprenons un nouveau langage de programmation ou lorsque nous pratiquons un sport. Ce processus cognitif essentiel à l'adaptabilité (rappelez-vous d'André Gide « L'intelligence, c'est la faculté d'adaptation ») peut aujourd’hui être modélisé et reproduit artificiellement.
Je vous présenterai quelques exemples décortiqués d'applications concrètes d'apprentissage par renforcement accompagnés des concepts et algorithmes fondateurs.
Ainsi, nous verrons comment nous pouvons simplifier la prise de décision dans des systèmes complexes à partir de règles simples et haut niveau.
Qu’est-ce que l’apprentissage par renforcement
L'apprentissage par renforcement est né de la rencontre entre la psychologie expérimentale et les neurosciences computationnelles. Il tient en quelques concepts clés simples basés sur le fait que l'agent intelligent :
- Observe les effets de ses actions
- Déduit de ses observations la qualité de ses actions
- Améliore ses actions futures
Pour définir un cadre à ce processus, nous allons donc lui apprendre à apprendre.
L'homme fonctionne de cette manière lors de l'apprentissage du vélo, de la marche etc… et les scientifiques peuvent entraîner des animaux à faire des choses surprenantes de cette façon.
L'agent "intelligent" décide d'effectuer une action en fonction de son état pour interagir avec son environnement. L'environnement (ie l'utilisateur chargé de programmer l'agent) lui renvoie un renforcement sous la forme d’une récompense positive ou négative. Charge ensuite à l'agent de maximiser ce renforcement. La récompense correspond ici au critère à optimiser pour la boucle de feedback en théorie de la commande optimale. C’est grâce à cette boucle de rétroaction que l’agent s’améliore.
Considérons quelques exemples afin de plonger doucement en profondeur dans le sujet :
L'escargot mécanique qui s'adapte aux conditions climatiques
La puissance de l’apprentissage par renforcement est parfaitement démontrée dans cette expérience plutôt simple [TEF] réalisée par des chercheurs allemands. En effet, considérons un petit robot motorisé de la façon suivante :
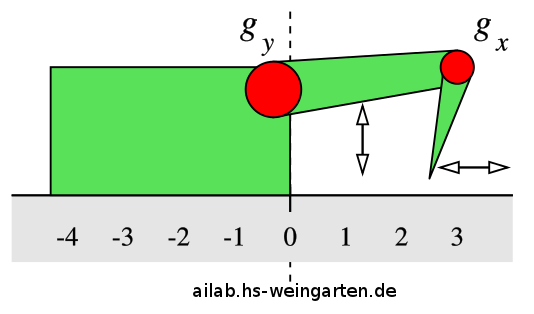
Cet « escargot » dispose d'un bras constitué de deux pièces ayant chacune 5 positions différentes. A la manière d'une petite pelleteuse, le robot peut se déplacer en utilisant ce bras pour s'appuyer sur le sol et avancer.
L'espace d'état est constitué de 5x5 positions qu'on modélisera par un tableau. La récompense est la vitesse du robot ; celle-ci peut être positive ou négative. Le robot doit donc apprendre à avancer.
A partir de chaque état, le robot peut déplacer une de ses deux pièces d'un cran (haut ou bas) sauf aux limites. Visuellement pour nous, il se déplace sur la grille d'états.
On assigne à chaque état s couple des positions des deux pièces une valeur V*(s) qui correspond intuitivement à ce qu'il peut espérer de mieux en terme de récompense s'il joue de manière optimale. V est dite fonction valeur et est initialisée aléatoirement.
Le but du jeu pour le robot est de trouver la suite d'actions optimale (dite politique optimale) afin de maximiser sa récompense sur l'ensemble du trajet. Pour ce faire, le robot se déplace d'état en état, cherchant donc :
- à explorer les états qu’il ne connaît pas (et donc découvrir les récompenses sous-jacentes)
- à aller dans les meilleurs états. Ce sont ceux dont la fonction valeur additionnée de la récompense immédiate est maximale.
Ainsi, le robot explore et exploite.Aparté :
- _P_ourquoi le robot ne doit-il pas se fier uniquement à la récompense immédiate ?
- _P_arce qu'un très bon état peut se cacher derrière une suite d'états désagréables. C'est là l'intérêt de la fonction valeur qui évalue en espérance l'espace d'états.
L'environnement (sol sec ou sol mouillé) est caractérisé par son tableau de récompenses lorsque l'agent transite d'un état à un autre. Ce tableau caractérise complètement l'environnement. Chaque case du tableau correspond à un état. Les quatre valeurs dans chaque case sont les récompenses liées à une transition vers un état adjacent.
Dans ce cas précis (environnement correspondant au sol sec), lorsque les pièces de l'agent sont toutes deux en position 3, et que la pièce de l’extrémité passe dans l'état 2, le robot avance beaucoup ce qui correspond à une récompense de 43. Ce tableau est formé progressivement à partir de l'observation de la correspondance entre couples états-actions et vitesse du robot.

Vidéo du robot apprenant à marcher sur sol sec :
http://www.youtube.com/watch?v=KtdqYAwlMjs
Vidéo du robot apprenant à avancer sur sol mouillé :
http://www.youtube.com/watch?v=yVuJOTD2Gpc
L'agent commence donc par exemple avec V(s)=0 sur sa grille ce qui correspond à l'état de connaissance nulle. Le robot explore son espace d'état et constate s'il a eu une récompense à chaque pas. Il met alors à jour sa fonction valeur avec la connaissance du feedback de l'environnement suivant l'algorithme Value-iteration :
Voici à présent cet algorithme d'itération sur les valeurs.
Le pseudo code suivant extrait de l’article associé à cette expérience illustre la simplicité de cet algorithme :
Etant donné les variables et définitions suivantes :
- ε (ratio d'exploration)
- 0 < γ < 1 (constante de convergence)
- A (ensemble des actions possibles)
- R(s,a) (récompense obtenue en partant de l’état s, et en effectuant l’action a)
- r (tableau des récompenses connues, ie déjà rencontrées)
- s’ (état d’arrivée en partant de l’état s et en effectuant l’action a)
<br>if(rand() < ε) {<br> // choisir une action au hasard parmi A pour<br> // garantir un taux d'exploration ici fixe<br> a = rand(A)<br>}<br>else {<br> // agir selon l'action qui maximise la récompense<br> // immédiate + valeur état suivant<br> a = argmax/A { R(s,a) + V(s’) }<br>}<br>// observer la récompense immédiate obtenue et<br>// la noter dans le tableau des récompenses r<br>r(s,a) = R(s,a)<br>// mise à jour des états<br>for (Etat s in espaceEtats) {<br> // la valeur de l’ état s est mise à jour grâce<br> // à la connaissance de l’environnement acquise<br> V(s) = max/A { r(s,a)+ γ * V(s') }<br>}<br>
Lorsque l'algorithme value-iteration a terminé de converger, V* est complètement définie et le robot a donc une politique dite optimale. Voici cette politique de transition entre états donnée par le tableau de flèches ci-dessous pour chacun des environnements :
Essayez de retrouver le cycle de 6 états dans le cas du sol sec, et le cycle de 2 états* dans le cas du sol mouillé en suivant les flèches.*
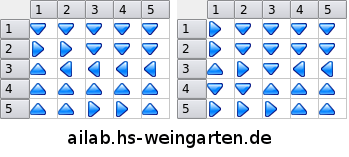
Nous n’avons pas eu à décrire la physique derrière les frottements et glissements dans le contact du robot avec le sol pour trouver un comportement optimal au sens des récompenses fournies au robot. Le robot a donc appris à se comporter différemment en fonction de l'environnement. Il a su faire preuve d'intelligence en adaptant son comportement à l'état du revêtement sur lequel il se déplace.
L’ascenseur qui s'adapte à vos habitudes de travail
L'expérience menée en 1996 par Robert Crites et Andrew Barto [CB] sur l'utilisation de réseaux neuronaux en apprentissage par renforcement montre l'utilité de ce type d'apprentissage pour des problèmes d'optimisation dynamique.
Prenons 4 ascenseurs montés dans une tour de 10 étages.
Chaque étage sauf le premier et le dernier dispose de deux boutons (haut et bas) par ascenseur.
Chaque ascenseur peut être en mouvement. Il peut alors s'arrêter au prochain étage ou passer le prochain étage. L'ascenseur qui est en arrêt peut décider de monter ou de descendre. L'article ajoute des contraintes à l'ascenseur que je ne détaille pas ici.
Commençons par dénombrer l'espace d'état à la louche. Il s'agit d'évaluer le nombre de situations possibles pour lesquelles le système {4 ascenseurs} doit prendre une décision :
- 18 boutons (monter ou descendre) d'appel peuvent être allumés ou non. Il y a donc 2**18** états possibles.
- Chaque ascenseur peut avoir ses 10 boutons (correspondant aux étages) allumés ou non. Il y a 4 ascenseurs, donc 2**40** états possible.
- Chaque ascenseur peut avoir 18 états position-direction possibles (rdc-haut, 1er-bas, 1er-haut, 2ème-bas …). Il y a donc 184 états possibles.
Multiplier les nombres d'états donne à peu près 10**22** ** états possibles**.
L'espace d'état est bien trop grand pour faire une matrice de 10**22** éléments. Deux solutions s'offrent alors à nous : Utiliser un espace d'état modélisé par un nombre relativement petit de variables clés ou utiliser un réseau neuronal dont les couches intermédiaires masquent la complexité du modèle.
Le réseau neuronal implémenté par ascenseur est constitué de :
- 47 neurones points d'entrée
- 20 neurones dans les couches intermédiaires
- 2 neurones de sortie
Les 47 points d'entrée représentent la connaissance de chaque ascenseur du monde extérieur.
Par exemple ici les boutons sur lesquels l'utilisateur qu'il contient a appuyé, le temps écoulé depuis que l'utilisateur a appuyé, ou encore une unité qui dit si l'ascenseur en question est tout en haut avec un passager.
Les 2 neurones de sortie se chargent de synthétiser la décision.
Voici un réseau neuronal modélisé. Chaque neurone pondère les stimulations qu’il reçoit en entrée et stimule à son tour les neurones auxquels il est connecté en sortie :
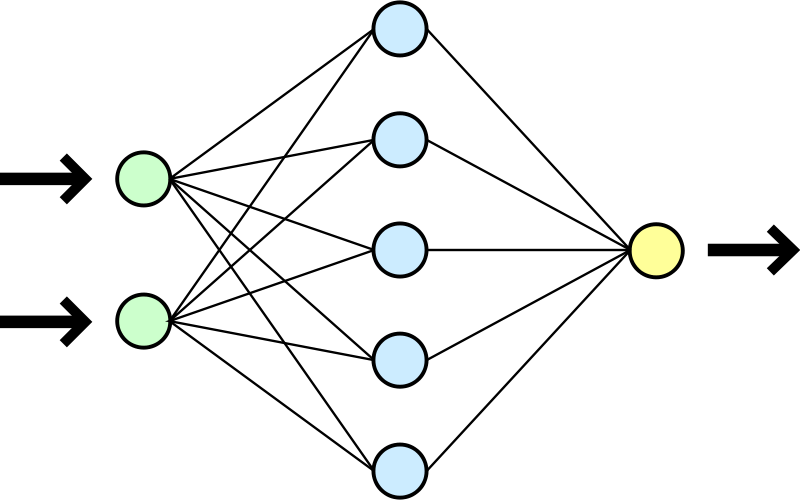
Wikipédia Art. Artificial_neural_network
- Une première difficulté est donc de savoir quels sont les inputs dont aura besoin mon système. Les multiplier complexifie le modèle et ralentit la convergence, les réduire risque d'aboutir à des comportements sommaires.
- La seconde difficulté est de punir correctement mon modèle afin qu'il apprenne. On peut par exemple lui donner comme fonction punition le temps d'attente moyen des utilisateurs ou le pourcentage d'utilisateurs qui attendent plus longtemps qu'un seuil fixé.
Lorsque les agents ont pris une décision, il faut, de la même manière que le réseau neuronal a été codé pour obtenir deux outputs à partir de 47 inputs, rétro-propager l'erreur, à savoir punir les circuits qui ont contribué à « prendre la mauvaise décision », et ce proportionnellement à la punition constatée.Aparté :
- Le réseau neuronal artificiel (ANN) semble être une solution magique aux problèmes où la modélisation est complexe, ou est l’erreur ?
- Les neurones manipulés ici sont très loin de refléter la complexité de leur équivalent physiologique. Les NN ne trouvent pour l’instant que des applications très limitées. Il faut en effet correctement choisir le type de NN, son architecture, les entrées et leur type et régler les nombreux paramètres. De plus, une longue phase d’apprentissage supervisé est souvent nécessaire. Enfin, il faut accepter une certaine tolérance à l’erreur dans les décisions prises par l’ANN. Pour ces raisons, le réseau neuronal artificiel est une grosse boite à outils difficile à maitriser.
Résultats :
Le système s'adapte alors aux utilisateurs (générés aléatoirement par exemple par un processus de Poisson, avec des cycles dépendants des heures) afin de minimiser la fonction punition.
Il a notamment réduit de moitié le temps d’attente au carré obtenu avec le contrôleur d’ascenseur le plus utilisé de l’époque.
Les sources de cette expérience sont disponibles sur le net.
Elle fut codée en FORTRAN et C. Il a été nécessaire de simuler 60.000 heures (soit un peu moins de 7 ans) d'ascenseur ce qui a pris 4 jours sur une station à 100MIPS en 1996. Ses résultats ont démontré qu'il battait tous les algorithmes de load balancing d'ascenseur de l'époque qui sont eux évidemment configurés spécialement pour les ascenseurs.
Le robot qui avait un équilibre sans faille
L'expérience suivante réalisée dans [Ried] présente un robot qui a pour mission de stabiliser un bâton au sommet.
Un modèle de réseau neuronal est également utilisé avec :
- 3 entrées : l'angle du bâton, la vitesse angulaire du bâton et un paramètre de contrôle
- 2 couches cachées de 5 neurones chacune
- 1 neurone de sortie qui donne le déplacement à droite ou à gauche à chaque intervalle de temps (0,1s)
Le principe est là encore le même. L'espace d'état est modélisé par un réseau neuronal et initialisé aléatoirement. On choisit de laisser le robot effectuer une série de mouvements. On récupère les séries temporelles de récompenses et on décide de réaliser un apprentissage offline, c'est-à-dire rétro-propager l’erreur en une seule fois entre deux séries d'entraînement (ce qui dans ce cas permet d’accélérer la convergence de l'apprentissage). Après quelques centaines de batchs, l'agent sait comment il faut se comporter en fonction de la position et vitesse angulaire du bâton.
Je vous laisse admirer le résultat en seulement quelque centaines de phases d'entraînement.
http://www.youtube.com/watch?v=Lt-KLtkDlh8
Il est ainsi possible d'obtenir des comportements automatiques complexes à partir de règles simples dans des environnements fortement non linéaires où les tentatives de résolutions directes seraient difficiles.
Un autre exemple illustrant ce propos est ici (un robot qui apprend à retourner les pancakes) :
http://www.youtube.com/watch?v=W_gxLKSsSIE
Une application au SI
Une application pratique de l’apprentissage par renforcement a été réalisée pour la configuration automatique de machines virtuelles d’un cluster de serveur linux dans un contexte de charge dynamique dans l'article suivant [URL].
Les tests ont été réalisés sous des benchmarks d'e-commerce, de transaction sur une DB et d'application web en général.
Deux problèmes essentiels ont été au cœur de cette étude :
- Réduire le nombre de paramètres à prendre en compte dans la configuration d’une VM afin de cerner l’espace d’état pertinent et d’accélérer la convergence
- Réaliser un apprentissage classique avant de commencer l’exploration afin d’empêcher l’agent de prendre des décisions aberrantes (et économiquement dangereuses) lorsqu’il est mis en service. Le modèle sous-jacent est alimenté par l’historique de charge et de paramétrage des VMs (donc des couples inputs-paramètres output-récompenses). L’agent dispose donc d’une base de connaissance avant de prendre des décisions dans un contexte réel.
Voici les conditions de l’expérience qui a été mené pour les machines virtuelles :
- 3 paramètres pertinents ont été choisis pour chacune des 3 VMs utilisées.
- 3 actions sont possibles sur chaque paramètre : incrémentation, décrémentation ou invariance de celui-ci.
- Les récompenses sont définies par le SLO (service level objectives) auquel on soustrait le temps de réponse (d’autres formes de récompenses sont proposées)
Le modèle choisi pour réaliser l’apprentissage par renforcement est là encore un réseau de neurones dont les inputs sont les différentes variables d’environnement y compris le paramétrage des VMs, et les outputs les différentes actions à mener sur chaque paramètre de chaque VM. L’utilisation du réseau de neurones permet de ne pas avoir à représenter l’espace d’état sous forme de tableau (120 000 états possibles) comme pour l’exemple du système d’ascenseurs.
Les résultats obtenus montrent une adaptation rapide à des changements de charge (itérations 30 et 60) par rapport à la vitesse d’un administrateur qui doit manuellement paramétrer le système, et de meilleurs choix par rapport aux configurations par défaut (réalisées à partir d’heuristiques pour chaque typologie d’environnement). Voici une des situations
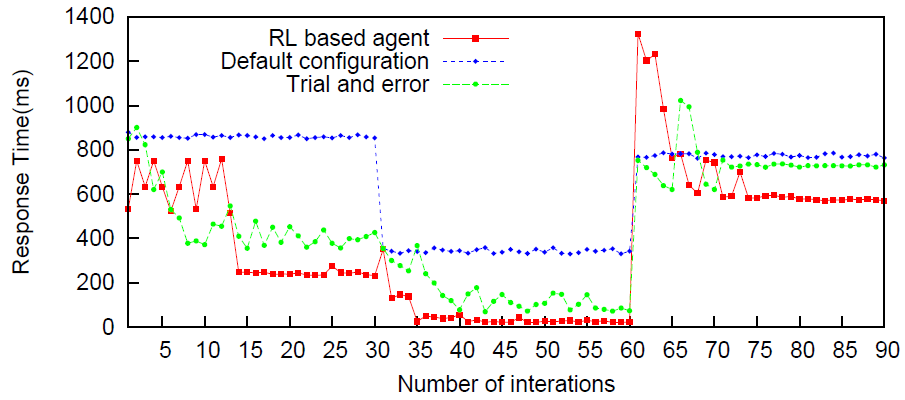
URL: A unified reinforcement learning approach for autonomic cloud management
Néanmoins la faiblesse de cet algorithme réside dans le modèle d’apprentissage au début. Celui-ci doit être suffisamment précis pour empêcher l’agent d’explorer des états non pertinents (ce qui ralentit la convergence vers un état optimal mais ne l’empêche pas). Enfin, cet algorithme perd bien entendu son intérêt dans le cas de VMs à durée de vie courte. De tels algorithmes de paramétrage automatique pourraient également être appliqués à des logiciels ou frameworks présentant un degré de complexité important (grande interdépendance des paramètres par exemple) et pouvant être reconfigurés sans arrêter les services.
Conclusion
A travers ces exemples, nous avons pu commencer à cerner l’utilité de l'apprentissage par renforcement. Aujourd'hui, la complexité de la multitude de systèmes d'informations qui nous environnent appelle naturellement à une automatisation des processus et de leur paramétrage adaptatif. Tandis que les méthodes d'apprentissage statistiques classiques commencent à trouver un écho dans le monde du big data, le renforcement comme moyen d'inférer un comportement complexe à partir de critères simples peine encore à trouver sa voie.
Bibliographie
[CB] Improving Elevator Performance Using Reinforcement Learning (1996), Robert Crite, Andrew Barto
[Ried] Neural Reinforcement Learning to Swing-up and Balance a Real Pole (2005), Martin Riedmiller
The vision of autonomic computing (2003), J. O. Kephart, D. M. Chess
Quelques expériences d’apprentissage par renforcement en lien avec les SI