Apprentissage distribué avec Spark
Les solutions big data actuelles se concentrent essentiellement sur l'aspect ETL des traitements. Le modèle MapReduce nous permet d'implémenter facilement des extractions d'informations mais de nombreuses contraintes et limitations apparaissent lors de la conception d'algorithmes de data science.
Par exemple, les algorithmes itératifs couramment utilisés en machine learning sont difficilement intégrables dans les modèles MapReduce: le haut-niveau d'intéraction des données impose une gestion et une synchronisation complexe à différentes phases de l'analyse.
Dans cet article nous nous intéressons à un use case typique en machine learning: la conception d'un modèle d'extraction et d'analyse de texte permettant leur classification. Dans ce cadre nous utilisons un modèle classique: la régression logistique. Notre objectif est de démontrer l'adaptation et l'élégance d'implémentation de ces algorithmes en utilisant le framework de calcul distribué Spark.
Use case
Une banque d'investissement souhaite classer automatiquement les nouvelles financières en fonction de leur contenu. Pour cela elle dispose d'un historique de plusieurs années sur l'ensemble de marchés mondiaux manuellement catégorisée.
L'objectif est ici de construire une architecture permettant:
- Le pré-traitement des news en un format utilisable en machine learning.
- La création d'un modèle permettant la catégorisation automatique en fonction du contenu des nouvelles.
- La classification en temps réel.
Nous allons ici nous concentrer sur le second point.
Données
Pour illustrer cette étude nous nous basons sur le dataset RCV1-v2/LYRL2004 extrait du Reuters Corpus Volume 1, une archive de 800 000 nouvelles financières manuellement catégorisées. Ce dataset est pré-traité (suppression des stop words et stemming) et se présente directement sous la forme de matrices de termes par documents.
Afin de pouvoir alimenter un algorithme d'apprentissage, nous procédons à l'extraction des caractéristiques TF/IDF qui offrent une interprétation fréquentiste des textes. La tâche d'apprentissage est de prédire les articles appartenant à la catégorie CCAT (Corporate/Industrial).
Pour résumer, notre modèle devra répondre à la question: cette nouvelle est-elle de type Corporate/Industrial ?
Nous sommes donc dans le cadre d'un problème de classification binaire.
Calcul du TF-IDF
La mesure TF-IDF (Term Frequency - Inverse Document Frequency) permet d'évaluer l'importance d'un mot dans un document relativement à l'ensemble des documents.

Avec les formules suivantes:
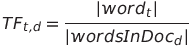
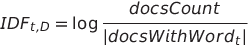
L'extraction du TF-IDF engendre un nombre très important de dimensions: une mesure pour chaque mot apparaissant dans le corpus et ce pour chaque document.
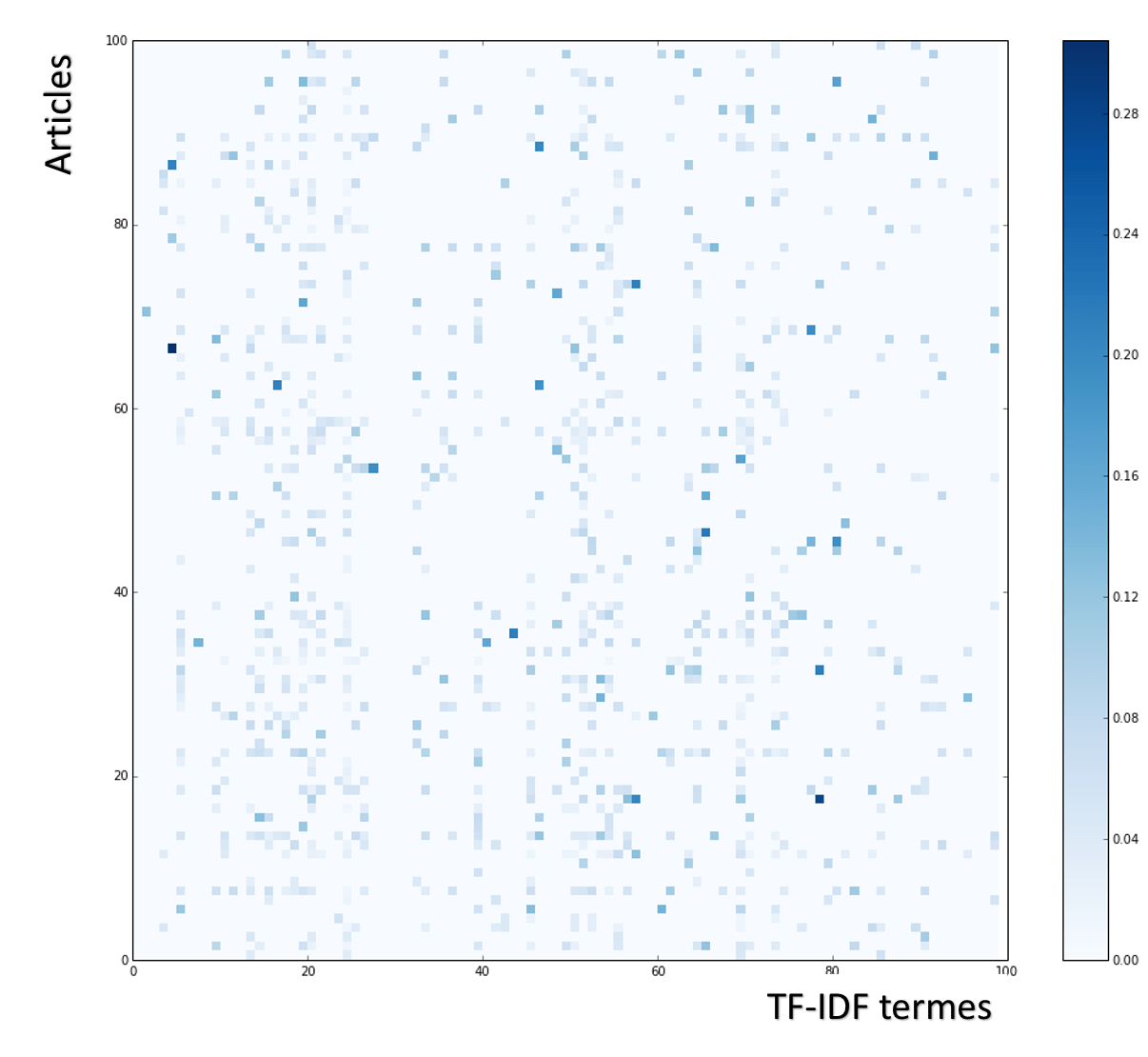
Nous obtenons une matrice de 800 000 documents x 47 152 dimensions. Cette matrice est creuse (i.e. essentiellement constituée de 0), nous avons donc ici un moyen d'optimiser le stockage et les calculs associés à cette matrice.
Nous obtenons les caractéristiques suivantes:
- Nombre de dimensions: 47 152
- Nombre d'exemples d'apprentissage: 781 265
- Nombre d'exemples de test: 23 149
Dans l'image ci-dessous, un extrait du dataset illustrant la distribution des valeurs non-nulles.
Régression logistique
Nous utilisons un modèle de régression logistique pour classer les nouvelles appartenant à la catégorie CCAT. C'est un modèle classique pour les problèmes de classification binaire (cf Wikipedia).
L'important est de comprendre que notre modèle est paramétré par un vecteur de poids w. L'algorithme permettant d'optimiser ces paramètres est une descente de gradient, nous avons donc besoin d'exprimer le gradient de notre modèle par rapport à une fonction de coût.
Modèle
Le modèle logistique avec un vecteur d'entrée xi et un vecteur de paramètres w:
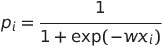
L'implémentation en python de cette fonction.
def logistic(x, w):
return 1.0 / (1.0 + np.exp(-x.dot(w)))
L'estimation de ce modèle utilise le principe du maximum de vraisemblance, nous utilisons donc le gradient de la vraisemblance pour la descente de gradient.
def logistic_gradient(x, y, w):
return (x.T * ((1.0 / (1.0 + np.exp(-x.dot(w)))) - y)).sum(1)
Apprentissage par descente de gradient
C'est un algorithme classique en machine learning. Le principe est simple: la performance de notre modèle est optimisée via la mesure de son erreur sur chacun des exemples de l'apprentissage. Nous dérivons cette mesure et mesurons ainsi l'erreur associée à chacun des paramètres unitaires de notre modèle pour chacun des exemples (i.e. nous mesurons l'influence du paramètre sur l'erreur globale du modèle). Nous utilisons ensuite ces erreurs pour corriger itérativement notre modèle.
Le point important est de comprendre qu'à une itération donnée, le calcul des erreurs pour chacun des couples paramètre/exemple est indépendant, ce qui nous permet une parallélisation naturelle.
Dans notre implémentation, nous allons paralléliser le calcul des gradients et la somme de ces vecteurs de gradients.
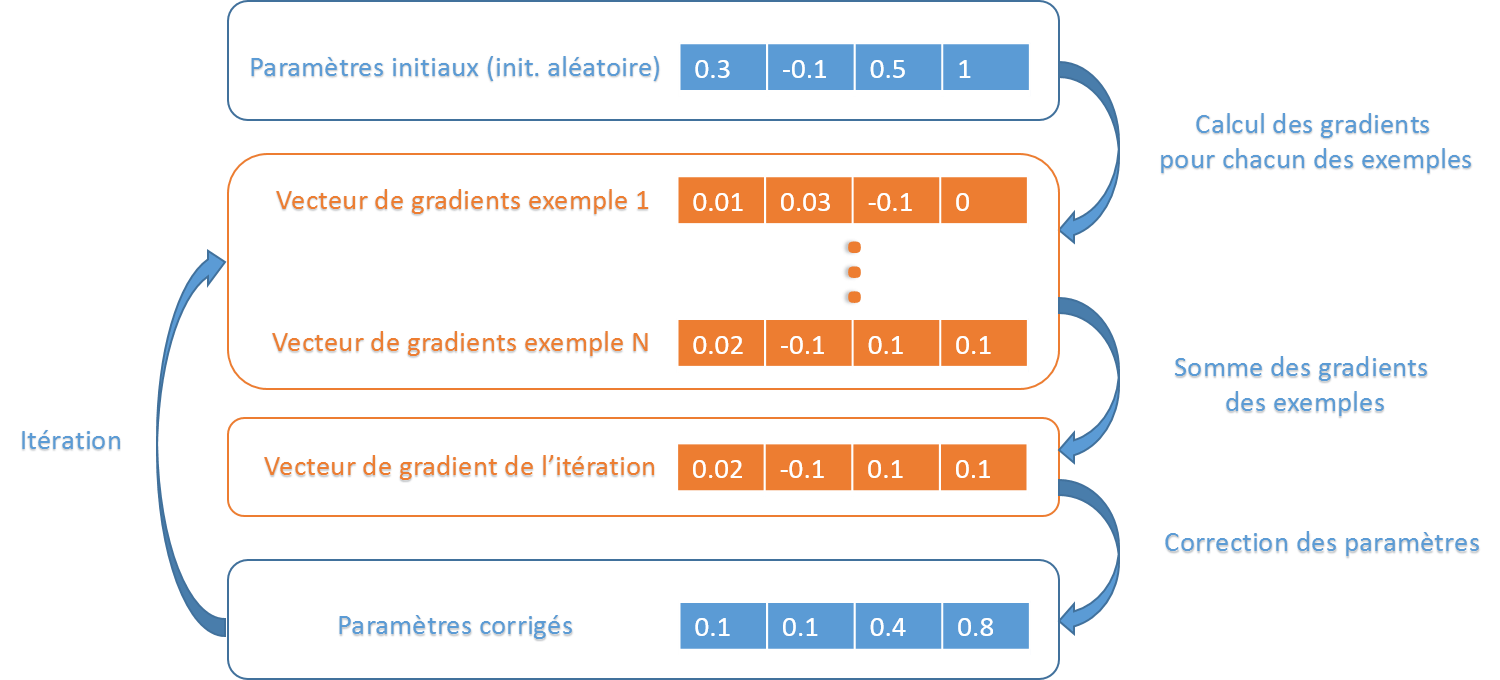
Apprentissage
La phase d'apprentissage du modèle consiste à itérer sur l'ensemble du dataset en corrigant à chaque étape les paramètres afin de converger vers un taux de classification optimum.
Architecture
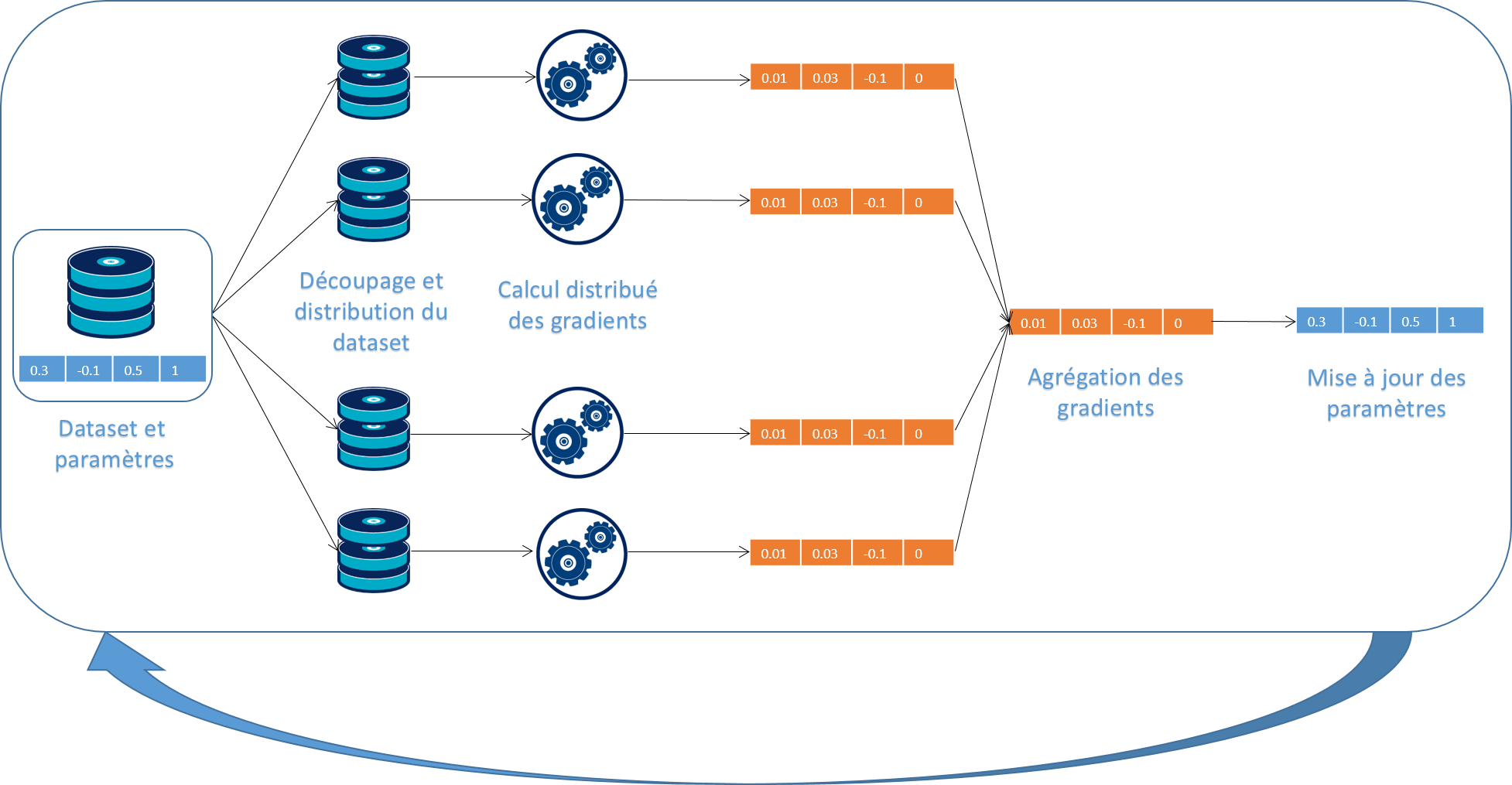
Les points importants de cette architecture:
- Le dataset est découpé et distribué sur les noeuds du cluster.
- Les paramètres sont envoyés à tout les noeuds à chaque nouvelle itération.
- L'agrégation des gradients correspond à une phase reduce, donc opérée également en parallèle.
Distribution des données
Le premier traitement que nous appliquons est le découpage du dataset initial en blocs de données pré-traitées binaires. Les blocs représentent chacun un sous-ensemble du dataset de 1000 exemples directement stockés dans un format binaire gérant les matrices creuses (module SciPy scipy.sparse).
Framework Spark
Nous avons ici choisit d'utiliser le framework Spark qui permet de représenter des problèmes de type MapReduce de manière concise et élégante. Développé au sein du Apache incubator dans le langage Scala, il est utilisé et supporté par de nombreuses sociétés impliquées dans le big data.
L'approche de Spark est résumée en une phrase:
Make data analytics fast - both fast to run and fast to write
Le framework se concentre sur le développement d'algorithmes itératifs où la mise en cache et un haut niveau d’interaction des données est nécessaire. Une fois l'algorithme développé avec l'API Spark, la génération de code et le lancement des calculs sur une machine locale ou en distribué se fait de manière transparente.
Spark facilite l'implémentation de ce type d'algorithme sans forcément exiger une architecture spécialisée. Il permet de s'intégrer avec le modèle MapReduce classique et propose différents mode de clustering:
- Amazon EC2
- Standalone
- Apache Mesos
- Hadoop YARN
Avec évidemment la possibilité de tester localement dans une version multi-tread.
La force de ce framework est d'abstraire l'ensemble des opérations nécessaires à l'adaptation de l'algorithme à l'une ou l'autre de ces architectures. Le développeur ne travaille pas à l'adaptation du code aux différentes topologies de cluster, il se concentre uniquement sur l'algorithme.
Ce framework propose des APIs en Python, Scala et Java.
Implémentation
Nous utilisons l'API Python du framework Spark. Nous avons souhaité utiliser ce langage car Python offre de nombreuses bibliothèques facilitant le calcul scientifique (dans notre cas SciPy et NumPy).
Initialisation
Avant tout, nous importons les bibliothèques Python et Spark nécessaires à l'algorithme:
- pyspark: importation de l'API Spark. L'objet SparkContext va gérer l'ensemble des communications avec le cluster.
- scipy.sparse: importation du module de gestion des matrices creuses. Plusieurs formats de stockage sont disponibles, nous utilisons ici le format csc_matrix "Compressed Sparse Column matrix".
- numpy: utilisé pour les opérations matricielles.
- sklearn.metrics: nous importons une fonction utilitaire nous permettant de calculer le nombre d'exemples bien classés.
from pyspark import SparkContext, StorageLevel
from scipy.sparse import csc_matrix
import numpy as np
from sklearn.metrics import accuracy_score
from svmlightbin import binsplit_dataset_read
from os.path import realpath
Nous initialisons ensuite un objet SparkContext qui centralise l'ensemble des communications avec le cluster.
sc = SparkContext("local[8]", "PythonLR", pyFiles=[realpath("spark.py")])
Algorithme
Nous pouvons ensuite implémenter l'apprentissage de notre modèle.
1. Paramétrage de l'apprentissage.
- NDIM: nombre de dimensions de notre dataset.
- ITERATIONS: itérations de la descente de gradient.
- NTRAINS, NTESTS: nombre de fichiers issus du pré-traitement du dataset.
NDIM = 47153
ITERATIONS = 20
NTRAINS = 1563
NTESTS = 47
2. Initialisation des traitements permettant de distribuer les différents calculs sur notre dataset.
train_files = sc.parallelize(xrange(NTRAINS))
test_files = sc.parallelize(xrange(NTESTS))
train_reader = lambda x: binsplit_dataset_read("train.txt", x)
test_reader = lambda x: binsplit_dataset_read("test.txt", x)
3. Un premier calcul Spark extrait le nombre d'exemples de notre ensemble d'apprentissage et de test.
train_nrows = train_files.map(lambda x: train_reader(x).shape[0]).sum()
test_nrows = test_files.map(lambda x: test_reader(x).shape[0]).sum()
4. Nous initialisons notre vecteur de paramètres w avec des valeurs aléatoires.
w = 2 * np.random.ranf((NDIM, 1)) - 1
5. Nous créons un broadcast de cette valeur. C'est une fonctionnalité de Spark, le broadcast permet de distribuer notre vecteur de paramètres w sur l'ensemble des noeuds.
wb = sc.broadcast(w)
6. Les fonctions utilisées par l'apprentissage:
- La fonction score calculant le nombre d'exemples correctement classés.
- La fonction gradient calculant le gradient pour un sous-ensemble d'apprentissage et un vecteur de paramètres.
- La fonction add permettant d'agréger les gradients.
def score(matrix, w):
Y = matrix[:,0]
X = matrix[:,1:]
pred = logistic(X, w)
return accuracy_score(Y > 0.5, pred > 0.5, normalize=False)
def gradient(matrix, w):
Y = matrix[:,0]
X = matrix[:,1:]
return logistic_gradient(X, Y, w)
def add(x, y):
x += y
return x
7. Nous avons ensuite l'itération de l'apprentissage dont le rôle est de calculer les gradients, les agréger et les appliquer au vecteur de paramètres w.
for i in range(ITERATIONS):
# nous retrouvons ici le pattern typique MapReduce
# map: calcul des gradients pour chaque exemple
# reduce: aggrégation des gradients
grad_sum = train_files.map(lambda x: gradient(train_reader(x).todense(), wb.value)).reduce(add)
w -= 0.1 * grad_sum
wb = sc.broadcast(w)
train_nsc = train_files.map(lambda x: score(train_reader(x).todense(), wb.value)).reduce(add)
test_nsc = test_files.map(lambda m: score(test_reader(m).todense(), wb.value)).reduce(add)
print "Train Score", i, train_nsc / float(train_nrows), "Test Score", test_nsc / float(test_nrows)
Résultats
Après 10 itérations nous obtenons les scores suivants:
- Erreur sur le dataset d'apprentissage 7.5 %.
- Erreur sur le dataset de test 8 %.
Ces scores sont légèrement moins bons que les résultats obtenus via SVM dans la littérature [SVM] (erreur de test ~6%), mais restent néanmoins cohérent avec notre approche dans laquelle nous n'avons pas affiné l'algorithme de descente de gradient. En particulier notre pas d'apprentissage est fixé à 0.1 et n'évolue pas au cours de l'apprentissage.
Autres fonctionnalités de Spark
Data caching
Spark offre des fonctionalités avancées permettant de mettre en cache des résultats intermédiaires afin d'accélérer les calculs. Nous avons pu tester ces fonctions sur des extraits du dataset mais nous avons eu des difficultés de réglage de la JVM sur le dataset complet.
Spark streaming
Malheureusement Spark streaming n'est pas disponible dans l'API Python. Cette fonctionnalité permet d'utiliser le framework Spark sur des streams en temps réel.
Avec Spark Streaming notre algorithme pourrait-être déployé en temps réel sans modifications du code: il serait lancé sur des mini-batchs de données.
Spark MLLib
Depuis la version 0.8 (sortie fin septembre), Spark intègre la librairie MLLib qui propose une implémentation de plusieurs algorithmes de machine learning:
- SVM linéaires
- Regression logistique
Cette librairie n'est pour l'instant disponible qu'à partir de l'API Scala.
Conclusion
Cet article illustre l'apport des frameworks haut niveau dans l'implémentation d'algorithmes type de machine learning:
- Une API qui permet de s'abstraire de la couche d'exécution.
- Des fonctionalités permettant de simplifier des processus complexes, par exemple le broadcast.
- Des mécanismes facilitant l'implémentation d'algorithmes itératifs.
- Une intégration dans les architectures Hadoop existantes.
Cependant ce framework reste encore jeune sur certains points:
- L'API Python est incomplète et ne propose pas l'ensemble des fonctionnalités.
- Le mécanisme de data caching est complexe à mettre en oeuvre et impose un réglage fin de la JVM.
- La documentation manque de précisions sur des parties techniques telles que le data caching.
- L'API est difficile à debuguer.
Références
[SVM] Léon Bottou: Large-Scale Machine Learning with Stochastic Gradient Descent, Proceedings of the 19th International Conference on Computational Statistics (COMPSTAT'2010), 177–187, Edited by Yves Lechevallier and Gilbert Saporta, Paris, France, August 2010, Springer.