Apprendre la normalité ou détecter l’anormalité ? – Compte-rendu du talk de Reynald Rivière à La Duck Conf 2022

Reynald est Senior Manager en Data Science chez OCTO et intervient sur des missions de création de services et produits basés sur l’IA et la data. Ayant travaillé sur la Data Science dans plusieurs secteurs d'activité, il nous présente aujourd’hui l’IA appliquée au domaine de la cybersécurité, en tentant de répondre à la question : Apprendre la normalité ou détecter l’anormalité avec l’IA ?
1. Un peu d'humilité pour démarrer cette session
“Tous nos modèles sont faux… mais certains utiles”
Georges Box, statisticien du siècle dernier disait :
Tous nos modèles sont faux… mais certains utiles.
Et tout Data Scientist et tout utilisateur d’IA doit avoir ça en tête. Si quelqu’un vous dit que son modèle est parfait avec une erreur nulle alors :
- soit il n’y a pas besoin de Machine Learning, un simple moteur de règles peut suffire ;
- soit il a créé un “leak” en donnant la réponse à son modèle lors de son entraînement, et en passant en production le modèle sera inutilisable .
Ce qu’il faut retenir : la citation de Georges Box s’applique à de la statistique, mais l’IA et le Machine Learning reposent sur les mêmes bases de statistiques.
Ce qui est important dans la performance du modèle, c’est la réponse qu’il apporte à un besoin métier. En divisant mon erreur par 2, qu’est-ce que cela m’apporte ?
Quelques domaines d’applications
L’IA s’applique dans plusieurs domaines de l’IT :
- la cybersécurité (par exemple pour essayer de détecter le plus tôt possible une cyberattaque),
- la prédiction d’incidents (par exemple pour prédire si un service ou un serveur va se dégrader voire crasher) via la recherche de signaux faibles, dans les ressources de la machine pour essayer d’anticiper les incidents pour les contourner ou réduire leurs impacts sur la qualité de service,
- l’optimisation des coûts du cloud qui ne sont pas encore toujours bien anticipés et maîtrisés,
- la gestion des tickets incident (analyse, classification automatique d’incidents par des bots).
La vocation n°1 du Machine Learning est d’optimiser.
2. Les nouveaux constats & challenges sécuritaires
Quelques exemples de cyberattaques emblématiques
Le groupe de hackers Lapsus$ a récemment fait un combo en hackant 3 poids lourds du digital que sont Nvidia, Ubisoft et Samsung en volant les codes sources des téléphones ou des données internes. Un ensemble de données internes et potentiellement des données utilisateurs se sont retrouvées exposées.
Le groupe pharmaceutique Pierre Fabre s’est fait hacké son système provoquant l’arrêt total de ses sites production pendant 1 mois ! Et cela a mis plusieurs mois à revenir à la normale.
Concernant les hôpitaux, en 2020 il y a eu 27 attaques / an sur des centres hospitaliers, et en 2021 c’était le double. (1)
La cybersécurité est donc devenue un véritable enjeu majeur que les entreprises connaissent depuis des années.
Ces cyberattaques ont des impacts sur l’image de l'entreprise avec une perte de confiance des utilisateurs, mais également des impacts financiers en bloquant l’outil de production, et enfin des impacts sociétaux en bloquant ou perturbant des services de santé.

4 challenges
Pour aborder cette problématique, nous sommes partis de 4 hypothèses que nous avons donc adressés comme des challenges :
- Aucune forteresse n’est imprenable 🡪 quelque soit l’épaisseur ou la hauteur des murs de protection du SI, il y aura un jour une intrusion. Les défenses périmétriques restent nécessaires et indispensables mais ne sont plus suffisantes pour les empêcher. Il faut donc l'anticiper pour pouvoir au maximum contenir cette attaque.
- Nous sommes passés de l’artisanat à l’industrie du hacking 🡪 aujourd’hui c’est fini le geek à lunettes et sa capuche au fond de son garage. Maintenant ce sont des cols blancs, des organisations financées, organisées et structurées voire étatiques. Ils ont une créativité forte et leurs attaques sont donc de plus en plus furtives et subtiles, et donc plus difficiles à détecter. En effet, la majorité des outils actuels se basent sur des patterns, des signatures sur des événements qui se sont déjà passés afin de les détecter lorsqu'ils apparaissent à nouveau. Or on voit de plus en plus d’attaques polymorphes inconnues qui passent donc entre les mailles du filet.
- C’est une course sans fin 🡪 A l’image des gendarmes et des voleurs, les voleurs ont toujours un temps d’avance. Il faut en moyenne 212 jours pour détecter une attaque sur un système d’information et 56 jours pour qu’un hacker soit détecté une fois qu’il est dans la place. (2) Donc le hacker n’est plus dans le SI depuis longtemps lorsque les équipes de cybersécurité découvrent qu’une intrusion a eu lieu.
- L’impact du remote 🡪 cela implique de plus en plus d’ouverture des SI qui les rendent plus vulnérables car on amène une partie du SI chez soi.
Comment pouvons-nous adresser ces 4 challenges ?

Challenge 1 : il faut une approche différente et agnostique.
Challenge 2 : par rapport à ces hackers qui sont financés, il faut avoir une approche “intelligente”.
Challenge 3 : pour lutter contre cette course sans fin, la détection doit être faite beaucoup plus rapidement, avant ces 212 jours qui, d’ailleurs, augmentent d’année en année.
Challenge 4 : il faut avoir une approche “Zero Trust” où on ne fait confiance à personne dans le SI. Cela implique d’avoir une réflexion d’usage personnalisée.
Reynald nous indique comment :
En aidant le quotidien des cyber-analystes, en leur évitant l’effet “sapin de Noël” avec beaucoup de faux-positifs sur les cyber-attaques. Environ 4 alertes sur 5 sont des fausses alertes. (3)
3. Détecter l’anormalité OU apprendre la normalité ?
En Intelligence Artificielle, il est particulièrement important de bien poser la problématique que le modèle de Machine Learning va devoir “cracker”.
Nous cherchons à détecter rapidement une cyber-intrusion connue ou inconnue dans un SI.
Il y a 2 façons d’aborder le sujet
Soit nous détectons l’anomalie avérée en tentant de faire apprendre à un modèle ce qu’est une cyber attaque. La détection d’anomalie, et donc d’anormalité, est assez usuelle en IA et s’applique avec succès à de nombreux cas d’usage de divers domaines métier.
Soit nous inversons complètement la problématique en faisant apprenant la normalité d’usage d’un SI au modèle de ML. Pour le faire réagir lorsqu’il y a un usage non standard du SI.
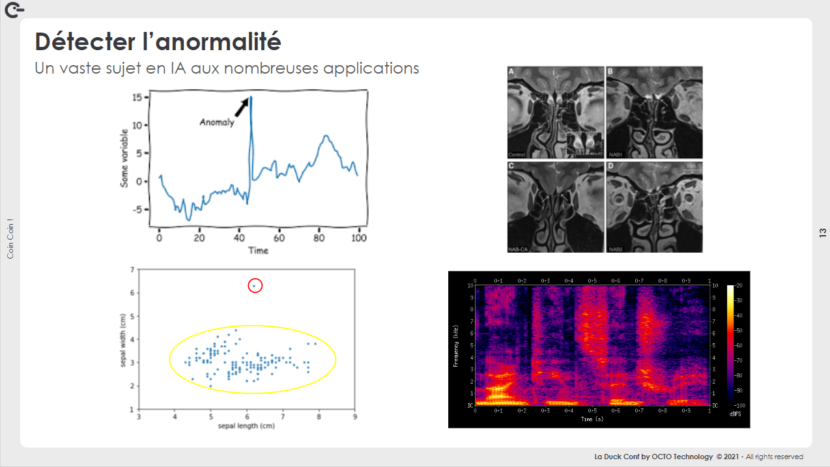
Nous sommes partis sur la 2ème approche : apprendre la normalité.
Quelques exemples d’application de modèles de Machine Learning de détection d’anormalité sur des données non structurées :
- Une analyse d’un spectrogramme de son,
- Une analyse de radios médicales, dans laquelle la médecine a fait de gros progrès ces dernières années avec des résultats spectaculaires.
Quelques exemples sur des données quantitatives :
- L’analyse de la taille d’une fleur,
- Détecter un problème via les capteurs dans une voiture en utilisant des séries temporelles
La détection d’intrusion dans un SI ressemble beaucoup à chercher une aiguille dans une botte de foin. Rechercher un événement à la fois rare au regard de l’activité d’un SI et furtif rend sa détection très compliquée pour un modèle de ML qui risque de remonter plein de faux positifs. Et d’avoir un effet “sapin de Noël” sur la console du cyber analyste.
Nous avons privilégié d’utiliser l’usage du négatif plutôt que la photo, à l’image de la photographie. Donc plutôt que d’apprendre au modèle à détecter une anomalie très rare, on lui fait apprendre la normalité d’usage du SI, d’un service, d’un serveur, des applications, etc.
Ainsi le modèle est capable de réagir lorsqu’il fait face à un usage anormal, non standard du SI.
Comment apprendre la normalité à un modèle de ML ?
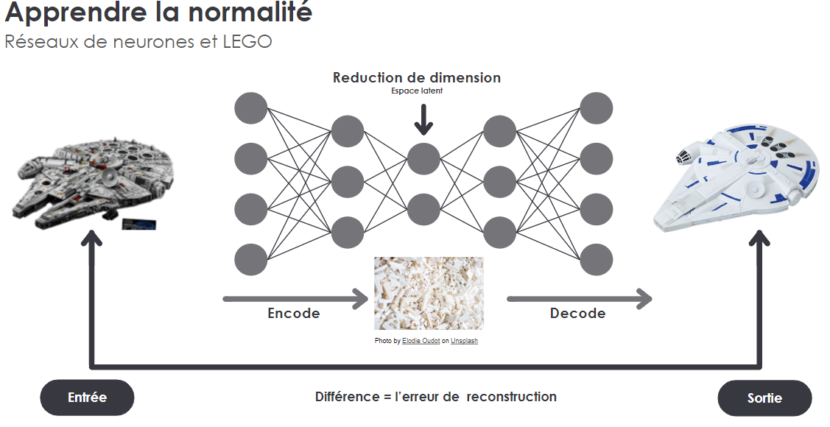
Nous avons utilisé des réseaux de neurones, avec l’exemple du Faucon Millenium en Lego :
- nous donnons au modèle une image de Faucon Millenium parfaite (cf l’image de gauche),
- l’information arrive dans un entonnoir, l’espace latent qui déconstruit le Faucon Millenium en plein de pièces de Lego (cf l’image du milieu),
- puis on lui demande de le reconstruire (cf l’image de droite),
- enfin nous calculons l’erreur entre l’entrée et la sortie, lui demandons de recommencer, et ce jusqu’à que l’erreur soit la plus faible possible.
Si nous appliquons la même démarche à un problème de cybersécurité :
- En entrée à notre réseau de neurones, nous avons une matrice de chiffres représentant par exemple le trafic réseau d’un serveur de mail qui sont les signes de vie d’un serveur (cpu, typologie de flux…). Note : nous nous sommes appuyés sur les conseils d’experts en cybersécurité,
- Le réseau de neurones doit se débrouiller pour la déconstruire et la reconstruire cette même matrice,
- Nous calculons l’erreur. Au début l’erreur est importante car le réseau de neurones ne sait pas reconstruire cette matrice, il est donc devant une situation d’usage qu’il ne connaît pas.
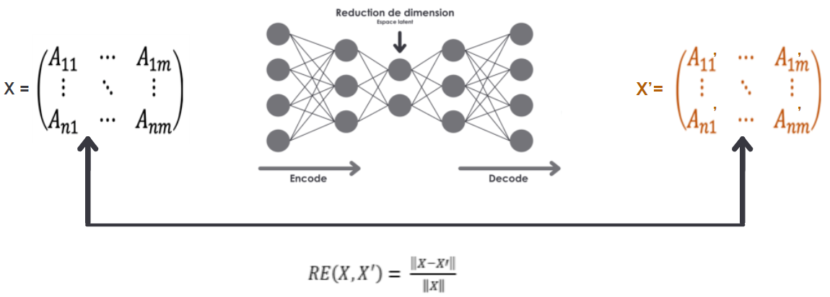
Il est également possible de calculer les différences colonne par colonne, par exemple pour avoir un calcul sur le flux entrant du serveur pour être dans la contention de l’attaque le plus rapidement possible.
Cette approche plus ciblée est une aide à la décision plus ciblée pour les cyber analystes.
||X||= matrice normalisée
Quel jeu de données pour l’apprentissage ?
Nous avons :
- notamment utilisé un dataset d’une université canadienne qui avait des logs et des tags d’attaques,
- supprimé les lignes où il y a des attaques,
- donné le dataset restant au réseau de neurones pour qu’il apprenne la normalité, en calculant une erreur jusqu’à ce que l’erreur soit la plus petite possible dans cette reconstruction,
- analysé ce que lui considérait comme une anormalité et donc une cyber attaque.
Reynald nous dit avoir appris cela :

Sans avoir donné une quelconque information de ce qu’est une attaque, nous avons pu détecter beaucoup d’attaques. Nous avons ainsi pu comparer ce qu’il considérait être une anormalité avec les vraies attaques de notre dataset d’origine. Il a ainsi pu détecter toutes les attaques de type Brute Force, DDoS, Heart Bleed, Infiltration et Port Scan alors qu’il ne les connaissait pas.
Il a été moins bon sur les attaques de type Web Attack et Botnet ARES, et nous avons compris pourquoi : peu d’informations étaient disponibles dans les datasets sur le comportement normal d’un serveur web.
Nous avons donc réussi à faire apprendre la normalité à notre réseau de neurones.
Les 3 étapes de détection d’intrusion

Les 3 étapes sont de :
- capturer le comportement normal du SI (phase d'entraînement du réseau de neurones sur un serveur de fichiers ou de mail par exemple)
- détecter les déviations pour les signaler comme des anomalies (phase d’analyse avec outil d’aide à la décision fourni aux cyber analystes à l’aide de seuils de déclenchement)
- visualiser les résultats et passer à l’action (à travers d’outils de dataviz et notamment avec des graphes qui ont l’aspect de temporalité)
Comment ça se passe concrètement ?
Nous créons des petits agents que nous déposons sur chaque serveur ou service, ces agents ayant déjà été pré-entraînés. Ils seront bien sûr différents dans leur apprentissage selon s’ils concernent un active directory ou un serveur de fichiers, ou un serveur de mail, etc.
L’idée n’est pas de tout protéger, mais ce qui est critique : ce qui concerne la sécurité ou les données personnelles.
Ces agents complètent les systèmes de protection déjà existants ; il suffit donc de les brancher “en Y” sur les flux de logs et d'appliquer les bonnes recettes transformations de données qui sont clés dans la réussite.
Chez OCTO, nous sommes sensibles au “Green AI” avec une démarche d'éco conception et de frugalité dans nos modèle.ous allons plutôt utiliser des petits réseaux de neurones avec des datasets les plus représentatifs et petits possibles pour créer un modèle à l’empreinte énergétiques la plus faible possible.
4. Take Away
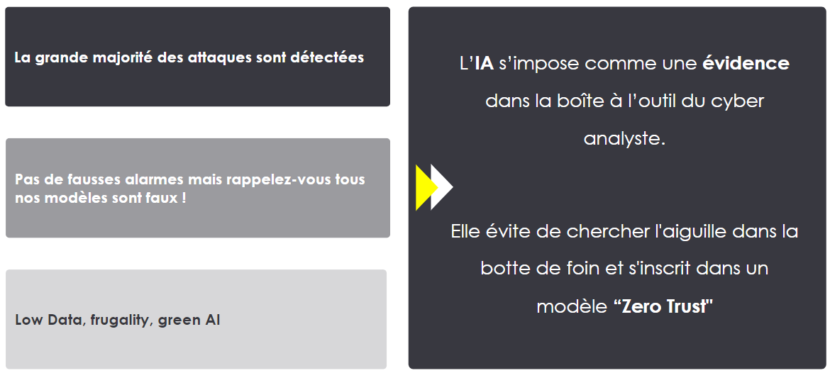
La grande majorité des attaques a été détectée 🡪 c’est normal car nous ne pouvons pas tout détecter.
Pas de fausses alarmes mais tous les modèles sont faux !
Low data / Green AI → on ne cherche pas à gagner epsilon sur le résultat si cela nécessite X fois plus de données ou Y fois plus de temps et donc d’énergie pour l'entraînement du modèle. Ici seulement un dataset de quelques jours nous a permis de construire le modèle de ML avec seulement quelques heures d'entraînement.
Reynald conclut avec 3 Take Away :
L’IA s’impose comme une évidence dans la boîte à outil du cyber analyste. Nos clients nous remontent souvent que les solutions du marché ont un côté boîte noire qui les embête.
Il faut éviter de chercher l’aiguille dans la botte de foin, ce qui est très chronophage, énergivore et souvent peu ou pas efficace.
En l’adossant d’une approche Zéro Trust, nous voyons que cela est efficace.
Références : (1) Cybersécurité des hôpitaux : «27 attaques majeures en 2020 et une par semaine en 2021» - le Figaro 17/02/2021
(2) Cost of a data breach Report – IBM 2021 (FR & EN)(3) One-fifth of cybersecurity alerts are false positives - Security Magazine 15/03/2022