API designs for low-connectivity
However some of these actors exist beyond a notoriously bad layer of network: phones. You may find that mobile connectivity has improved on your iPhone but it’s still far from a regular broadband connection or even an antique modem. Also, your users may not have access to this kind of luxury.
In this article, we’ll see how a sound API design can help you mitigate the risks of dealing with users on low-connectivity.
Let’s get one thing out of the way first: I only titled my article this way to lure you in. Low Connectivity is not an edge case. As a matter of fact, the famous fallacies of distributed computing list “The network is reliable” as their first misconception. You should in fact consider that networks will fail you, whichever networks you are considering.
Network failures in the context of an API
For Web APIs, there are two types of failure that we can target (considering timeouts and hard failures are similar). These are most problematic when the client wishes to create or mutate some resources. On mobile networks, this is most often caused by dropped packets resulting in the timeout of the connection. Keep in mind that, from the client’s perspective, these two types of errors are impossible to tell apart.
Failure on request
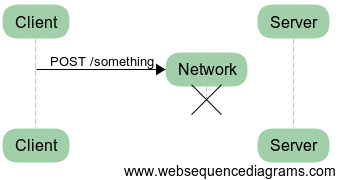
In this first case, the request never reaches the server. Repeating the request, hoping for the network not to fail again, can solve the problem quite easily. In fact, this should be automated. Obviously, this does not work if the network never heals (is your computer even plugged in?).
Failure on response
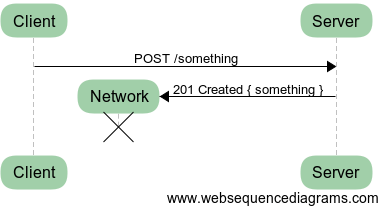
In this second case, the failure happens when the server has processed the request and has replied successfully. However, the response never reaches the client for which it will be impossible to know that the request did in fact work. In this case, retrying the same request might result in a conflict or otherwise unprocessable request for the server.
Since the client has no way of knowing if the request even reached the server in the first place, our mitigation strategy must not depend on whether or not the request has actually been processed.
In real life
I will use a simple use case as an example for the rest of this article.
Consider a delivery system where delivery people are assigned a set of flower bouquets to deliver at different locations. The bouquets haven't been ordered by the person receiving them so we need to inform the buyer when the bouquets have correctlybeen delivered via email or something.
Let’s iterate on this use-case and see what designs we can come up with, while keeping in mind that our network is unreliable.
Idea 1: Posting to an action to trigger a transition
This seems straightforward enough, let’s try this first one. We imagine our bouquet orders as state-machine objects. These state can transition like this: (ordered) → (scheduled) → (delivered). We can use the POST verb on a related URI to trigger the transition.
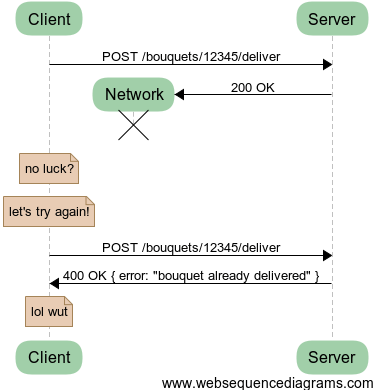
Whoops! In this scenario, the semantics of state machines don’t play well with network failures. The transition from (delivered) to (delivered) is not legal and it causes an error. Although, you may not want to be this strict in your state machine implementation, the concept your are exposing through your API remains the same. It is unclear what should happen when someone is retrying a request for the bouquet order to change state.
As a general rule of thumb, you should avoid resources with an action in their URI. They reveal an API based on procedures rather than resources and it causes problems in distributed systems. POST requests have the same problem, their specification only states that it is the only one to mutate another resource. POST is basically an HTTP wildcard that you should only use when all else fails.
Idea 2: Patching the status of the resource
Alright, let’s not overthink the status of our bouquet orders. Let’s just say they have a “status” field and we PATCH it when we need.
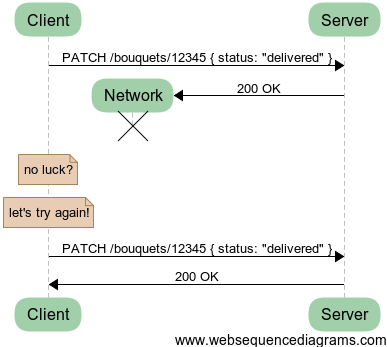
This one seems to work. But in reality there are two problems with it.
First, PATCH is the second least specified HTTP Verb (after POST) and only states that you are mutating the resource at a given URI. There’s no way to tell how the body { status: “delivered” } must affect the resource. Should it remove all other fields? Should it only change this one? Should it add to an array? Should it replace another field? The semantics of patching something imply knowledge of the current state of the resource. In case of a retry, there’s no way to be sure we still have a correct knowledge of this state.
PATCH has the same problems as POST regarding retries: they are not idempotent. Idempotence means repeating this action n times does not change the outcome, n being equal or greater than 1, obviously.
Second, we’ve uncovered another can of worms: concurrent access. If you consider all your actors, you might find yourself in a case where several of them want to PATCH your resource at the same time with different data. Here is one.
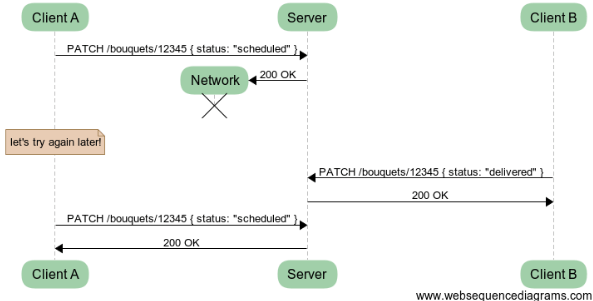
In this case the order was scheduled to be delivered but Client A has no idea and is set up to retry (several times if necessary) until it has a response. Meanwhile Client B has received the list of bouquets to deliver and has delivered the one we’re interested in. The delayed PATCH for the “scheduled” status then succeeds. Please note that at the end we have an inconsistent state AND no errors, which is rather unfortunate.
In order to address this problem, we’d usually try and have the bouquet order behave as state machines but we’ve already tried that… Let’s explore elsewhere.
Idea 3: Putting to a flag
OK, if everyone is so hyped about idempotence on the Internet, maybe we should try one of the idempotent HTTP verbs. In this case, we imagined a resource /isDelivered related to our bouquet order which acts as a simple flag. Our system only cares if the resource exists or not, so what we PUT to it doesn’t really matter.
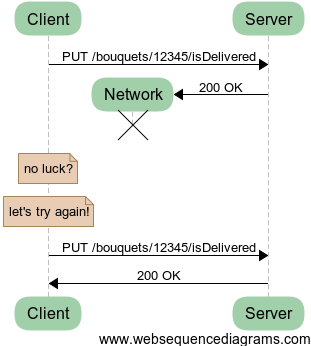
This seems to work. We can have the same sort of related resources for when the bouquet is ordered, scheduled or anything. No matter how many concurrent actors are putting to /isDelivered or /isScheduled and how many times they have to try before success, in the end we have consistency. This works well because you are in fact always adding information, never mutating or removing. This is a key design pattern for resilient systems. You might have heard of append-only databases for example.
This design is a fair one and can get you pretty far. I can see one thing creeping up though. We might want to have additional data regarding the delivery of the bouquet: the date and time of the delivery, the exact location, a signature or a selfie to send back to the buyer (♥‿♥). You could imagine having other related resources like /deliveryDate (which can serve the purpose of /isDelivered by the way), /deliveryLocation and /deliveryImage. However, it can quickly become impractical and also somewhat incoherent. If your PUT /deliveryDate works fine but PUT /deliveryImage fails, some other actors might not get what they expect.
Let’s see if we can do something about that.
Idea 4: Creating a related resource
This time, we’re doing it right. We want all information related to a delivery contained in a single resource which references our bouquet order, the creation of which is done as a single request so it’s never partially there.

We’ve seen this a million times with CRUD systems and we should be able to get it to work. The creation of a resource is just a usual POST on a /deliveries resource which creates it and then we get the URL of that delivery as the Location header in the response.
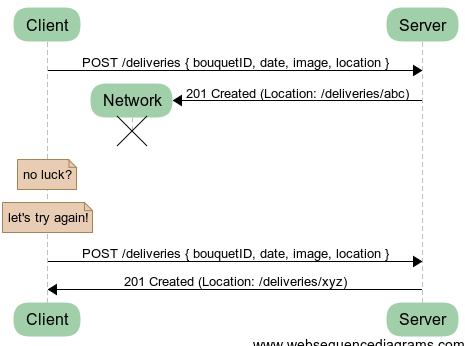
Oh no! We created two resources when we only wanted to create one.
As a side-note, I can tell you that this very problem happened to me when I tried to wire money while on the train. I set up the transfer to quite a large amount, checked everything and hit “send”. About a minute later, I had an error saying something went wrong and I had to retry. I hit it again and it worked fine this time… But in fact, I had just wired twice as much as I intended and only found out days later when I could not pay for anything anymore. Needless to say, it was not very amusing.
Considering this, you might want to forbid creating the same resource twice, like in the following diagram.
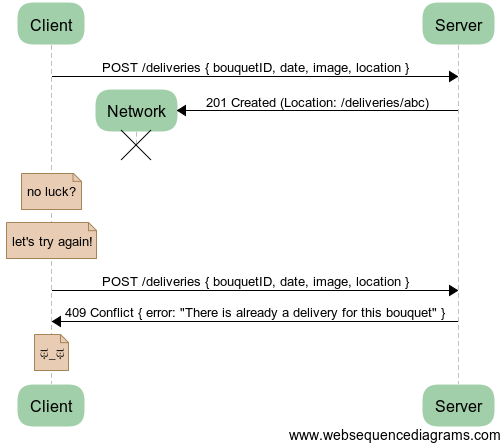
This time, we have our unicity taken care of. But for the client retrying a request, the second time the response is an error, while in actuality everything went rather fine. Why should anyone have to code around and worry about “normal errors”? Chances are these two words made you cringe already. What we’d like is, for a second request for the creation of a delivery resource, the API replaces the resource or otherwise replies with a success code. You can implement it with this design, but there is a way to make this behaviour more intuitive. Let’s check out this idempotent business once again.
Idea 5: Putting a related resource
This is the last design I will present as it includes, in my opinion, all the expectations and behaviour we need for our use-case.
We define a related resource /delivery which contains everything there is to know about the delivery of a given bouquet. The trick here is that there can be only one delivery for a bouquet and the URI implements this requirement. Since the client knows in advance for a given bouquet what is going to be the URI of the related delivery, it can simply PUT the complete resource there.
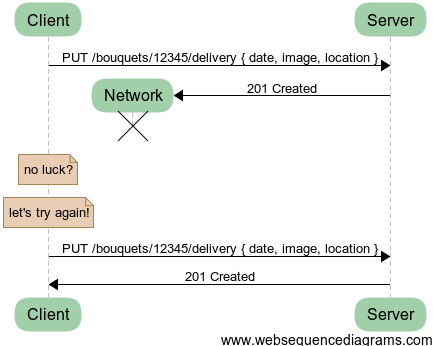
In this last scenario, we get:
- A repeatable request which always yields the same outcome
- All information pertaining to a delivery bundled within a single resource
- A URI which makes it clear how many deliveries there can be for a bouquet
- A reproducible pattern for /schedule, which addresses the problem with concurrent access that we saw earlier between scheduling and delivering since they are now explicit separate resources
Because the semantics of PUT make it idempotent, we can trust that retrying the exact same request will result in the same outcome. Retrying requests safely makes it easy not to worry too much about requests failing due to a fragile network. In turn, not worrying makes you healthier!
Conclusion
As you have seen, depending on your API design, it may be more difficult to recover from a network failure (that will happen). Here is a list of things we can gather from these scenarios:
- Retries are to be expected for any resource on your API, because the network is unreliable
- Create resources where it makes sense (even if it does not equate one-to-one to a model in your persistence layer)
- Idempotent requests like GET, PUT and DELETE play well with cache and retries, their semantics make it easy to reason about redundant actions
- You should prefer idempotent HTTP verbs whenever possible
- Repetition and redundancy are the foundations of robust distributed systems
Next time you are thinking about new API endpoints, ask yourself: “But what if the network fails?” You’d better be prepared for it as it will inevitably happen!
Now tell us. How would you design your API for this use-case ?