Apache Spark, ai-je besoin d'autre chose ? - Compte rendu du talk de Benoit Meriaux à la Duck Conf 2019
Pourquoi Spark ?
Dans tous les SI complexes, on a la nécessité d’effectuer des traitements sur un grand volume de données. La réponse traditionnelle est celle des batch de traitement, qui consiste à sélectionner un ensemble de données similaires via, par exemple, une requête SQL, puis d’effectuer les traitements en série sur chaque donnée. Ce modèle de traitement a l’avantage d’être simple. Néanmoins, il présente de sérieux inconvénients :
- Il scale difficilement. On programme souvent les batch pour s’exécuter lorsque le SI "dort" (les batch tournent souvent la nuit)
- Aucune résilience. Que se passe-t-il en cas d’erreur ? Il faut le relancer le matin et on perd une journée de productivité car les données concernées n’auront pas été mises à jour.
- Tire sa simplicité du fait que les traitement se font en différé. Le SI stock un état à l’instant t, et le batch changera cet état à un instant ultérieur. Aucune gestion du temps-réel.

Qu’est ce que Spark ?
Spark est un framework de calculs distribués open source. En 2018, il s’agit du premier framework de Big Data avec 31 % de parts de marché, et 29 % de croissance par rapport à 2017.
Evolution de Spark
Spark a été créé en 2009 par des étudiants de Berkeley, puis offert à la fondation Apache en 2014, qui a tout de suite cru en son potentiel et en a fait un de ses projets phares. Plusieurs jalons ont suivi:
- v1.0 (2014)
- v1.3 DataFrame API, introduisant une représentation des données plus structurée
- v1.5 Le projet Tungsten, optimisant des performances sur tous les plans
- v2.0 Le streaming structuré, offrant une vraie approche streaming par opposition aux micro-batch utilisés dans les versions 1.*
- v2.4 Le projet Hydrogène, avec un focus sur l’utilisation de frameworks de machine learning type PyTorch ou Tensorflow.
Architecture de Spark
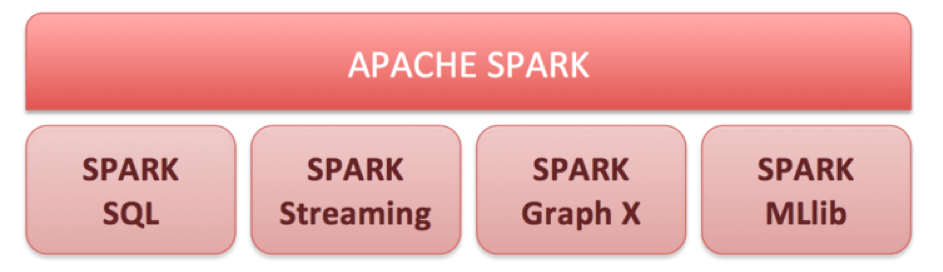
Spark est structuré autour d’un module coeur et de 4 autres modules qui ont vu le jour progressivement. Le projet est totalement open source .
Spark et les architectures distribuées
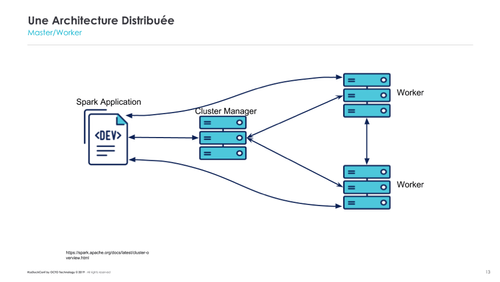
Par définition, les architectures distribuées sont basées sur applications qui communiquent entre elles à travers le réseau. Cela implique de sérialiser les données, c’est-à-dire les préparer dans un format d’échange. Cette sérialisation coûte cher aussi bien en CPU (sérialisation/désérialisation) qu’en réseau (bande passante).
Par conséquent, il est nécessaire de bien partitionner les données afin que les traitements puissent être au mieux distribués. Par exemple, la donnée “Utilisateur” peut regrouper des sous-groupes à volumétries complètement différentes. Si un traitement distribué ne différencie pas des utilisateurs normaux (quelques opérations par semaines) et des utilisateurs business (centaines d’opérations par mois), la distribution sera inefficace.
Spark et la gestion des données en temps-réel
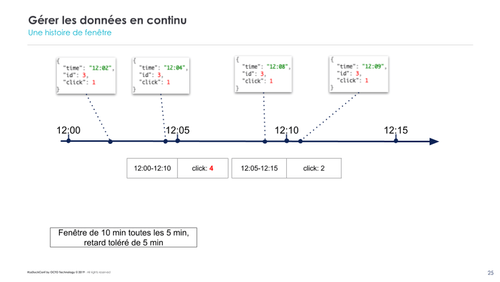
Spark est capable de traiter les données en temps-réel via son module de streaming. Cela se base sur deux paramètres : le windowing et le watermarking.
Le windowing permet de définir la granularité temporelle durant laquelle les événements enregistrés seront traités en même temps. L’alternative serait de fonctionner en pur évènementiel et de lancer les calculs à chaque événement, ce qui n’est pas réaliste.
Le watermarking permet de définir une fenêtre de tolérance afin que des traitements puissent intégrer des événements arrivés en retard.
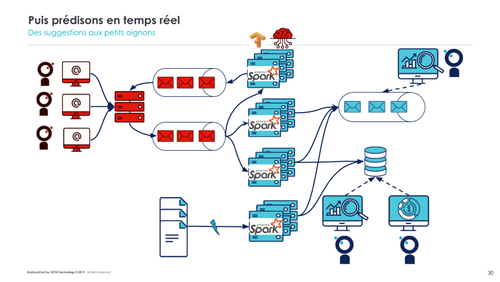
Spark et l’intelligence artificielle
Toutes les données collectées en temps-réel par Spark peuvent également être analysées en temps-réel, afin de fournir des informations. Exemple : le black friday, qui ne dure qu’une journée. Durant le black-friday, Spark peut fournir des données afin que les publicités puissent s’adapter en temps-réel.
Conclusion: Spark, ai-je besoin d’autre chose ?
Spark se positionne comme un framework puissant et versatile. A lui seul, il couvre la majorité des cas d’usage, à l’intersection des tendances actuelles : Calculs distribués, Big Data, Machine Learning, IA…
Retrouvez la présentation complète sur Slideshare
Take-aways:
- Les architectures distribuées sont le paradigme moderne qui permet de répondre aux enjeux modernes de multiplication des données.
- Dans ce paradigme, le design for failure est le bon mindset à adopter, comme nous le rappelle le CTO d’Amazon: “Everything fails all the time”. Les équipes ops, dev et métiers doivent être éduquées.
- Le cloud est prêt. Tous les Géants du Web proposent des solutions SaaS industrialisées (Amazon EMR, HDInsight, DataBricks…)
- Dans les traitements distribués, attention à la partition des données. La sérialisation nécessaire à la communication entre services coûte cher en CPU ainsi qu’en bande-passante réseau.
- Il permet de récolter et d’analyser en temps-réel les données. Attention aux paramètres de windowing.