Apache Kafka 101 : comprendre le fonctionnement du message broker en temps réel
Introduction
Apache Kafka est une plateforme distribuée de streaming de données. Il est essentiellement utilisé comme un broker de messages (bus de messages). Il a été conçu pour des objectifs de performance (millions de messages par seconde) et de résilience (tolérance à la panne). On doit le nom Kafka à Jay Kreps (co-fondateur) et son admiration pour l’écrivain de langue Allemande Franz Kafka qu’il considère comme “un système optimisé d’écriture”. Dans une série d’articles, on va vous présenter les fonctionnalités d’Apache Kafka et comment il s’intègre dans un SI. Ce premier billet introduit les éléments de terminologie d’Apache Kafka.
Contexte
L’architecture bus a pour but d'éviter les intégrations point à point entre les différentes applications d’un système d'information. Les applications publient des messages vers un bus ou broker et toute autre application peut se connecter au bus pour récupérer les messages. Le bus devient un élément central de l’architecture.
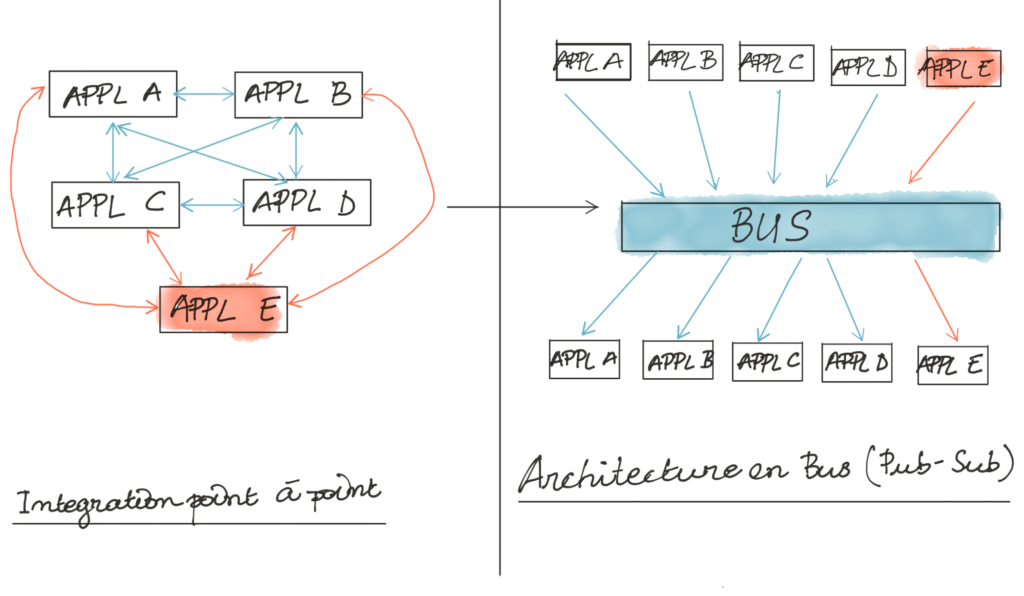
Le projet Kafka a été initié en 2009 chez Linkedin puis rendu à la fondation Apache en 2012. L’idée de ses concepteurs est de garder l’architecture en bus mais d’éviter que Kafka soit le point de contention dans l’architecture. Nous allons voir dans les lignes qui suivent comment Kafka a été pensé à la base pour pouvoir atteindre cet objectif.
Définitions
Le broker de messages est techniquement une instance de votre application Apache Kafka. Vous pouvez démarrer plusieurs instances du broker pour former un cluster.
Un topic est la façon de catégoriser ou de regrouper les messages. Il faut le voir comme un rangement spécial dans le bus pour un type de message donné.
Un topic peut être découpé en plusieurs partitions. Une partition est définie comme une séquence immuable et ordonnée à laquelle on peut ajouter continuellement des messages à la fin (append-only). La partition est l’unité de parallélisation qui permet de gérer les montées en charge de Kafka. Pour être tolérant à la panne on peut décider de répliquer une partition sur plusieurs brokers.
Dans un cluster il y’a qu’une seule partition leader à tout moment. Toutes les autres sont des réplicas.
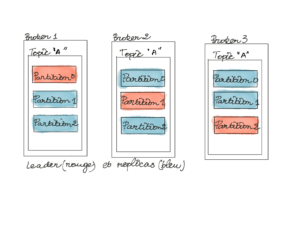
Les partitions réplicas (ISR) sont mises à jour à partir des partitions leaders. ISR est l’acronyme de In Sync Replica. Une partition est considérée comme synchronisée quand elle répond aux 2 critères suivants :
- Si sa dernière requête de synchronisation est inférieure au temps configuré via le paramètre replica.lag.time.max.ms
- S’il elle n’est pas trop en retard par rapport au leader, le seuil de lag de messages étant défini via le paramètre replica.lag.max.messages (Cette dernière propriété n'est plus supportée à partir de Kafka 0.9)
Le leader garde une liste des partitions ISR. Si une erreur se produit sur le follower, ou qu’il est trop en retard par rapport au leader, il est retiré de la liste. Un message est considéré comme committé s’il est présent sur toutes les partitions ISR.
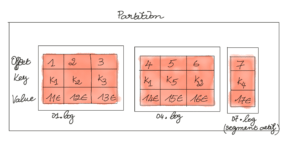
Une partition est représentée par un répertoire sur le système de fichiers. Ce répertoire contient des fichiers .log appelés segments. Les segments ont une taille ou une durée prédéfinie dans la configuration (par défaut 1 Go). Le premier offset du segment est appelé base offset. Le nom du segment est égal au base offset. Le dernier segment de la partition est appelé segment actif. Seul ce segment est capable de stocker les nouveaux messages (append-only).
Un producer est tout système qui publie dans un topic Kafka. Un producer ne pourra ajouter un nouveau message qu’à la fin de la séquence d’une partition mais ne pourra pas supprimer ou réordonner les messages existants. Le producer n’écrit que dans la partition leader. Kafka se charge de synchroniser cette dernière avec les autres partitions réplicas. Un producer, en publiant vers un topic qui a plusieurs partitions, voit son écriture parallélisée sur les disques parce qu’en réalité ses messages sont distribués sur plusieurs partitions.
La propriété acks permet au producer de déterminer quand une requête est considérée comme terminée et s’il doit attendre un acquittement du broker. Cette propriété a 3 valeurs possibles qui sont :
- 0 : envoie le message sans se soucier de l’acquittement du broker
- 1 : envoie le message et ce dernier est acquitté une fois qu’il est écrit sur la partition leader
- -1 : envoie le message et ce dernier est acquitté quand les partitions ISR ont tous reçu le message
En fonction de l’option choisie, vous pourriez perdre des messages ou soit diminuer la vitesse de publication des messages.
Kafka dispose d’un mécanisme interne qui permet de purger les anciens messages pour libérer de l'espace. La politique de rétention peut être basée sur le temps ou la taille des segments. Grâce à ce mécanisme les anciens segments sont progressivement supprimés.
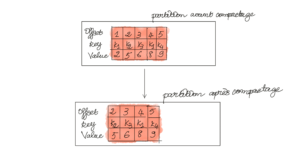
Kafka offre un autre mécanisme appelé le compactage qui permet de purger sur le contenu des messages. L’idée est de supprimer les messages de façon à garder uniquement les derniers messages par clé. Il permet ainsi de retrouver une image instantanée des dernières valeurs de chaque clé qui peut servir dans le cas d’un crash ou d’une restauration d’état.
Un consumer est tout système qui lit des messages dans les topics Kafka. Plusieurs consumers peuvent lire des messages dans le même topic à des rythmes différents. Un offset est un indicateur qui permet de retrouver le premier message non lu pour chaque consumer.
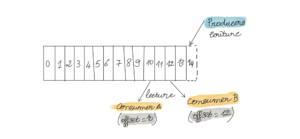
On doit regrouper les consumers dans des groupes appelés consumer group. Ce regroupement se fait quand les consumers ont le même group-id. Les consumers d’un même groupe se répartissent les partitions de façon équitable quand ils souscrivent à un topic.
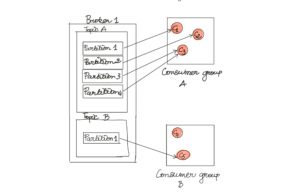
Kafka est un système distribué transparent : l’utilisateur final (consumer ou producer) a l’illusion de travailler avec les topics mais toute la magie s’opère au niveau des partitions. Quand un producer publie un message vers un topic avec plusieurs partitions, les messages sont distribués de façon aléatoire sur les partitions. Pour s’assurer qu’un type de message donné se retrouve toujours sur la même partition, il faut leur assigner la même clé. La garantie d’ordre est au niveau de partition dans Kafka. Ainsi un consumer dépilera les messages d’une partition toujours dans le même ordre que ces derniers ont été publiés au sein de la partition.
Pour certaines opérations comme l’ajout et la suppression d’un consumer au consommer group, il y a un réassignement des partitions aux différents consumers.
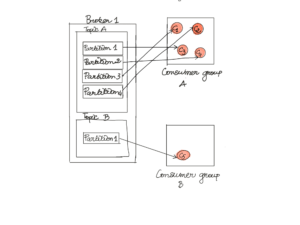
Pour avoir un cluster Kafka performant, il faut arriver à trouver un savant équilibre entre le nombre de partition et la logique de distribution des messages mais aussi le nombre de consumer dans les consumer group.
Conclusion
Kafka diffère des bus de messages traditionnels (ActiveMQ, RabbitMQ...) parce qu’il n'implémente pas le mode point à point (disponible via les queues). Il a été conçu pour permettre un débit de message important (à la publication ou à la consommation) en jouant sur les partitions. Il est aussi tolérant à la panne grâce à la réplication des partitions sur les autres brokers du cluster. Cette première partie a été consacrée à la description du fonctionnement interne d’Apache Kafka. Dans les prochains épisodes, nous allons faire le tour de tous éléments mis à disposition pour intégrer Apache Kafka dans le SI. L’écosystème s’est étoffé au fil des années pour faciliter cette intégration sous l’impulsion de Confluent (la société créée par les ex-employés de LinkedIn qui sont à l’origine du projet).
Pour aller plus loin: “Kafka répond-t-il à mon besoin ?”