Améliorer la performance des jobs Hadoop sur HDInsight
Cela fait quelque temps que j’expérimente des Tips & Tricks sur mes algos pour traiter de la data de façon performante et comme ça a été plutôt concluant dans mon cas, j’ai mis tout ça au propre pour les partager ici avec vous.
Les quatre optimisations que je présente ici vont faire passer le temps d’exécution de 45 minutes à moins de 3 minutes. La plus importante étant le passage d’un script Pig à un code MapReduce. Je tiens à préciser que cet article n’est pas une comparaison de performance, il se base sur les connaissances que je possède à un instant T. Il est volontairement subjectif, il explique mon cheminement et les solutions que j’ai trouvées pour résoudre mes problèmes. Cependant, le blog Octo est un endroit de partage et je vous invite vivement à commenter et partager votre expérience.
Mon use case est simple, je POC avec un cluster Hadoop instancié sur Azure, je reviendrai plus tard sur quelques avantages et inconvénients là-dessus, mais pour les personnes qui voudraient en savoir plus :

Mon cluster est composé de 4 nœuds, totalisant 24 cœurs et 24 Go de RAM. Ma donnée se trouve être les logs de Wikipédia récupérés au préalable sur Page view statistics for Wikimedia projects. Je passe la récupération et la préparation des logs qui n’est pas à l’ordre du jour.
Pour vous donner un ordre d’idée, le cluster contient 1,3 To de données qui correspondent à l’année 2014 incomplète à l’heure où j’écris ces lignes. J’ai placé toute cette donnée sur un stockage persistant dans le Cloud Azure appelé Azure Storage Vault (ASV). Ce stockage est « branché » au cluster Hadoop. Un cluster HDInsight utilise par défaut ce système de fichier à la place d’HDFS et stream la donnée d’entrée, puis utilise HDFS pour les étapes intermédiaires des jobs.
La version HDInsight utilisée pour ces tests est la 3.0 qui embarque Hadoop 2.2. Voici la documentation sur les versions embarquées par HDInsight.
Deux points :
- L’utilisation d’ASV comme système distribué en lieu et place d’HDFS me permet d’alimenter en données ce système de fichier distribué sans qu’un cluster Hadoop soit instancié. Je fais donc de grosses économies d’argent.
- J’ai la possibilité de consulter les résultats de mes jobs Hadoop d’une autre manière que par l’utilisation des commandes « hadoop fs » ou via l’interface WebHDFS. Il existe pour cela une API d’accès à ASV dans plusieurs langages et plateformes (Java, .Net, Javascript, PHP, Python, etc…) ainsi que des explorateurs de fichiers. En voici un que je vous conseille : CloudXplorer dans sa version gratuite 1.0
Parler de performance quand les données transitent par le réseau ?
En effet, le principe de base d’Hadoop et du paradigme Map Reduce est bien la co-localisation des binaires avec la donnée. En passant par des plateformes cloud comme HDInsight la donnée n’est pas présente sur les nœuds physiquement (si on utilise ASV à la place d’HDFS, ce qui est par défaut), mais dans un système de fichiers externe. On perd donc l’avantage de départ qui consiste à déplacer le code vers la donnée et non l’inverse (Moving data to compute or compute to data ? That is the Big Data question).
Mais l’équipe d’Azure a ré-architecturé ASV il y a 2 ans pour anticiper l’arrivée du service HDInsight.
Dans le schéma ci-contre, HDInsight se situe sur les « Compute Nodes » alors que les données sont situées sur des Blobs ASV comme l’explique Denny Lee dans son billet Why use Blob Storage with HDInsight on Azure, anciennement dans la Team SQL Server.
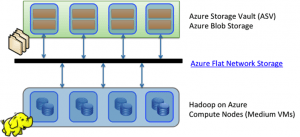
Azure a déployé un système appelé Azure Flat Network Storage (ou Q10) en 2012 pour apporter aux clients une très haute disponibilité de la donnée. Le résultat donne une performance « similaire » à HDFS en lecture (c’est-à-dire : 800Mo/s) et est plus rapide en écriture. Lorsqu’un nouveau fichier est persisté sur HDFS il écrit sur le premier nœud, puis une fois la tâche terminée il réplique sur le deuxième et après passe à la réplication sur le troisième nœud. ASV lui duplique aussi 3 fois la donnée dans le Datacenter local, il commence par la persister une première fois puis fonctionne en asynchrone pour les deux réplications. Ce qui explique la « réactivité » d’écriture sur ASV (en réalité l’écriture physique est aussi rapide). Dans son état de l’art de 2013 sur les stockages cloud, l’entreprise Nasuni explique que le système Q10 opté par Microsoft est 56% plus rapide que le second en écriture et de 39% en lecture sur ses benchmarks.
Que fait le Job ?
Avec les logs de 2014 récupérés, nous avons un fichier texte de 400Mo environ, par heure de la journée. Ce fichier contient le nom des pages Wikipédia, la langue de ces pages et le nombre de visites sur ces pages. Une ligne d’exemple :
fr Coupe_du_monde_de_foot_du_Bresil 1898299
Le nom des fichiers contient la date et l’heure auxquels il se réfère.
Exemple : pagecount-201400617-1800000.txt => de 18H à 19 H, le 17 juin 2014
L’algorithme
Mon programme possède trois filtres :
- Filtrer par langue d’intérêt (je ne sais pas lire le chinois)
- Filtrer par date et ainsi restreindre l’analyse à un jour, un mois ou toute une année.
- Filtrer certains noms de page de Wikipédia inintéressants dans notre cas. Par exemple : index, Accueil, undefined.
Deux GroupBy :
- Grouper les éléments par nom de page pour totaliser les nombres de visites par page.
- Grouper les éléments par langues pour le top 10 de chacune des langues.
Un OrderBy Desc :
- Ordonner les éléments par ordre décroissant du nombre total de visites pour chaque langue.
Un Top :
- Limiter le résultat me semble indispensable sachant que pour une journée le nombre de records est égal à 180 millions.
Le script PIG qui en découle :
REGISTER wikipedia.jar;
DEFINE CustomInput wikipedia.pig.FileNameTextLoadFunc('20140605');
DEFINE SIM wikipedia.pig.SimilarityFunc();
records = LOAD $in USING CustomInput AS (filename: chararray, lang: chararray, page: chararray, visit: long);
filterbylang = FILTER records BY lang == 'fr' OR lang == 'en' OR lang == 'de';
restrictions = LOAD $restrictionFile USING TextLoader() AS (page: chararray);
joinbypage = JOIN filterbylang BY page LEFT OUTER, restrictions BY page USING 'replicated';
deleteRestrictedWords = FILTER joinbypage BY SIM(filterbylang::page, restrictions::page) == false;
groupbypage = COGROUP deleteRestrictedWords BY (filterbylang::page, filterbylang::lang);
sumrecords = FOREACH groupbypage GENERATE group.lang, group.page, SUM(deleteRestrictedWords.filterbylang::visit) AS visit_sum;
groupbylang = GROUP sumrecords BY lang;
top20 = FOREACH groupbylang {
sorted = ORDER sumrecords BY visit_sum DESC;
top = LIMIT sorted 20;
GENERATE group, flatten(top1);
};
store top20 into $out;
CustomInput est une UDF (User Defined Function) de type Load que j’ai implémenté pour parser le nom du fichier log et récupérer la date afin de la fournir dans chaque record. De plus, dans ce CustomInput j’ai placé un InputPathFilter de mon cru afin de filtrer dès le départ la fenêtre temporelle sur laquelle je fais mon analyse (une journée, une semaine, un mois, etc…). Ça évite notamment de récupérer toute la donnée de 2014 (= beaucoup moins de transit réseau), pour ensuite avoir à la filtrer dans le Map.
SIM est une UDF de type Eval (on l’utilise afin de filtrer les records qu’on ne veut pas dans le résultat final => les restrictions). Elle teste la similarité d’une expression par rapport à une autre. Il y a un peu de calcul.
Lancement du script sur le cluster
Je lance le script Pig sur une journée, ce qui correspond à environ 8,5 Go de texte. Et là, j’attends… J’attends même super longtemps pour avoir un résultat puisque le job Pig va tourner pendant près de 45 minutes !!

J’ai récupéré dans la console les logs de Pig pour les analyser. J’en ai fait des beaux graphiques !
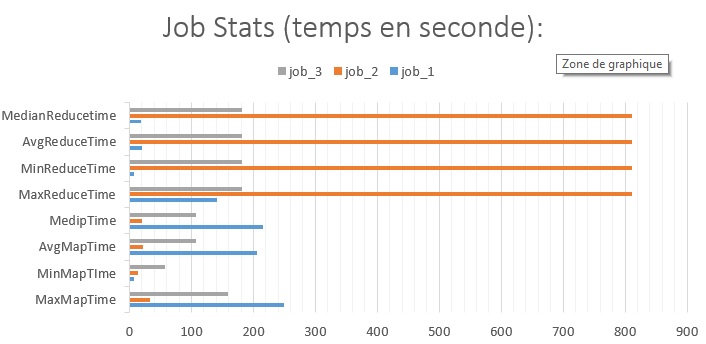
Pig a créé trois jobs Map Reduce :
- 1er job : filtre par langue, fait la jointure entre les records et les restrictions, filtre les pages valides ;
- 2ème job : opère le regroupement des pages avec le même nom et totalise les visites ;
- 3ème job : regroupe par langue les pages, puis limite pour chaque langue à 20 pages ;
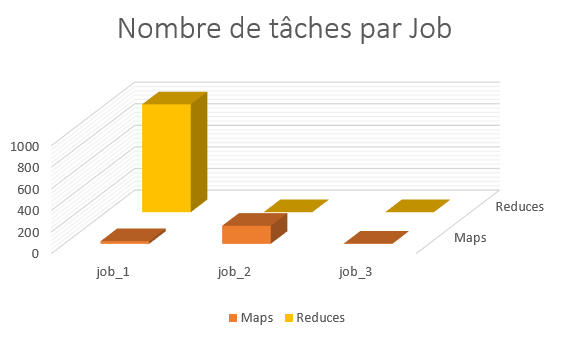
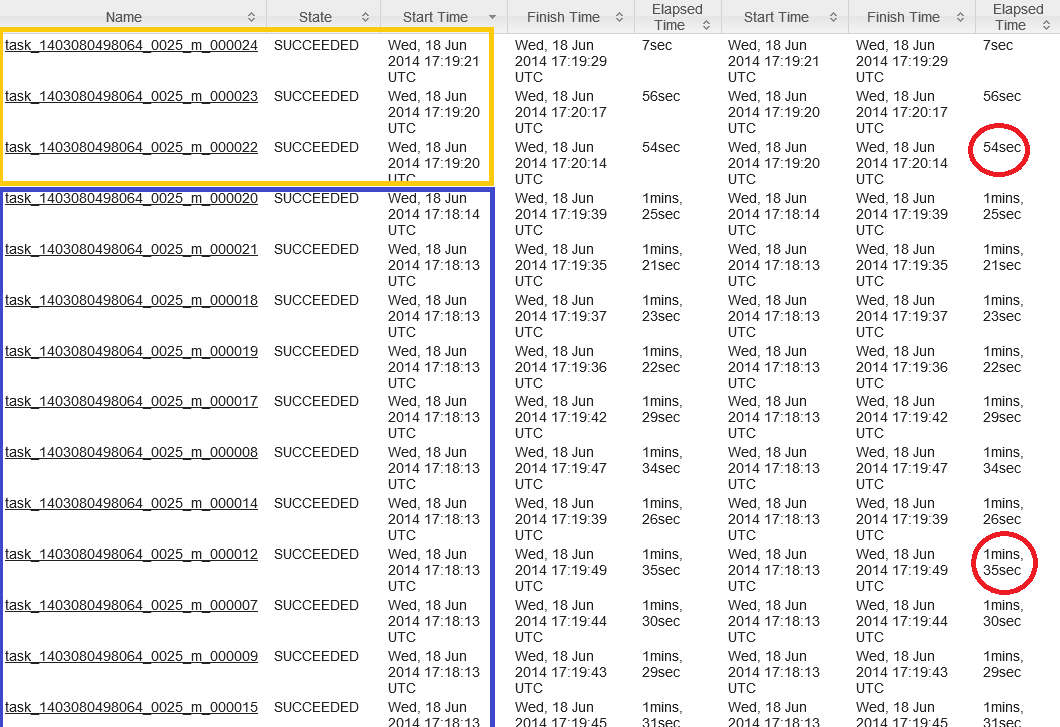
D’après le graphique ci-dessus je m’aperçois que Pig crée un nombre considérable de tâches de reduce dans le premier Job (999 !). En fait, Pig procède par une jointure de type « Reduce side » entre les deux data-set (celui avec les logs Wikipédia et celui avec les restrictions, beaucoup plus petit). Notre cluster possède 4 nœuds, j’ai alors 22 containers. Pig est assez intelligent pour setter le maximum de reducers possible. Donc les 999 tâches sont traitées par 22. Si je prends la moyenne des tâches de reduce pour le job_1 (dans le graphique Job_Stats) qui est de 20 secondes :
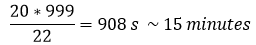
J’ai trouvé mon « bottle neck ». Je m’arrête ici pour le script Pig, j’ai fait le choix de ne pas l’optimiser (ce qui serait possible) pour m’intéresser aux optimisations sur le paradigme MapReduce et supprimer ces 999 reducers.
On casse tout, et on recommence
J’écris donc mon propre code Java « from scratch », produisant strictement le même résultat afin de comparer. Et c’est là où ça devient intéressant. Pour les curieux, le code est sur Github à cette adresse : https://github.com/BenJoyenConseil/octo-hadoop-perf
Vous avez la possibilité de récupérer dans le repository le script Pig ainsi que les deux UDF qui sont utilisées dans ce script. En cadeau bonux, il y a des tests, donnant un aperçu de comment tester du code MapReduce (PigUnit existe aussi pour les scripts).
Première optimisation : passer à un code MapReduce
En accord avec l’article de Ilya Katsov, MapReduce Patterns, Algorithms, and Use Cases que je vous conseille de lire, je choisis un mélange d’algorithmes de types Filtering et GroupBy and Aggregation.
Voici en quelques points les choix optés :
- Mettre les restrictions dans le cache local avec la méthode job.addCacheFile() pour filtrer dans les tâches de map directement (Join Map Side). Je pars du principe que le data-set de restrictions n’est pas volumineux (quelques Ko seulement).
- Filtrer les langues avec le même procédé que pour les restrictions.
- La clé de sortie du mapper est la langue. Les records seront répartis à l’appel du HashPartitioner par langue sur les reducers (lors du shuffle). Un reducer sera en charge de traiter en entier une langue. L’idéal étant d’avoir autant de reducers que de langues filtrées.
- La valeur de sortie du mapper est un Objet contenant le nom de la page et le nombre de visites en attributs.
- Le reducer fait un top 10 par langue des records qui lui arrivent.
Mon main Java lance successivement 5 fois le même Job tout en mesurant à chaque fois le temps d’exécution, puis écrit à la fin la durée moyenne d’exécution.
Je vous donne les résultats directement. Le moins que je puisse dire est que le gain de temps est conséquent.
| Job (sur 1 journée) | temps d'exécution (s) |
| Job 1 | 402 |
| Job 2 | 385 |
| Job 3 | 406 |
| Job 4 | 393 |
| Job 5 | 383 |
| Moyenne (min) | 6,5 |
BOUM ! Ce job met en moyenne 6 minutes 30 à traiter ce que faisait Pig en 45 minutes. L’accélération est flagrante, mais je ne suis pas encore satisfait. Je vais donc sur HDInsight pour ouvrir le dashboard Web de monitoring appelé Hadoop Yarn Status.
Deuxième optimisation : utiliser un Combiner
Je sélectionne une des 5 applications (le job est lancé 5 fois de suite) dans la section « Applications », puis je clique sur Tracking Url.

Dans le résumé du Job, je clique ensuite sur Counters et voici ce que je vois :
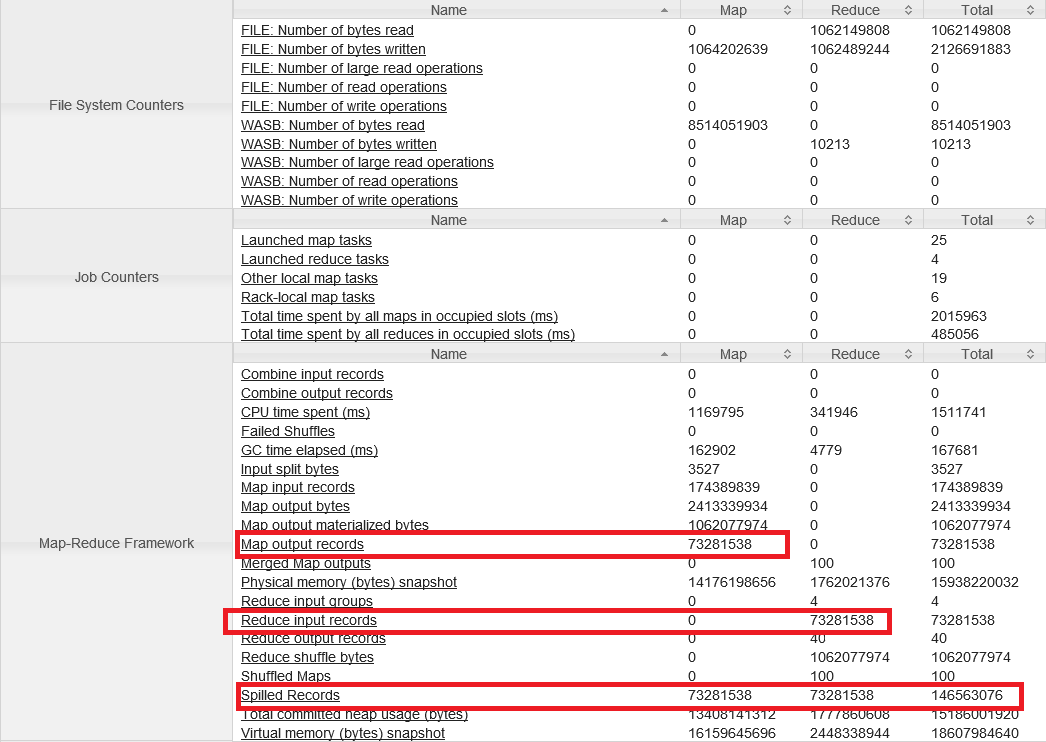
Le cluster possède 4 machines et 24 cœurs, ce qui fait 23 « task containers » (24-1). Mon job analyse 4 langues, j’ai donc modifié le nombre de reducers à 4. Donc il ne reste plus que 19 containers pour les mappers. Les mappers peuvent absorber beaucoup de données car ils sont nombreux, alors que les reducers reçoivent 2, 5 fois moins de données alors qu’ils sont 5 fois moins nombreux. La phase de map récupère 174 millions de records et filtre 73 millions de records valables pour le reduce. Il n’y a donc qu’un facteur de 2.4 ce qui ne diminue pas assez le volume de records pour l’étape finale (c’est-à-dire : en avoir que 10 par langue).
On constate, de plus, que les 73 millions de records sont « spillés » deux fois, une fois dans le map et une autre dans le reduce. Ce qui revient à un total de 146 millions de records écrits sur disque (le spill est le moment où le ContextBuffer est trop rempli et est vidé sur disque pour continuer).
D’après le Hadoop Definitive Guide : Third Edition, l’utilisation d’un Combiner serait une solution. Minimiser le nombre de records qui transitent pendant la phase de Shuffle & Sort vers les reducers. La deuxième solution serait de faire un top 10 intermédiaire dans les mappers, et d’écrire dans le contexte seulement les 25 top10 = 250 records (car il y a 25 splits pour une journée, donc 25 mappers).
J’opte pour la solution 1, avec pour Combiner la classe Reducer que j’ai déjà écrite. Cela me fait gagner du temps par rapport à implémenter une logique supplémentaire dans le Mapper, et puis en plus ce n’est pas son rôle !
Les résultats s’améliorent encore et j’arrive à passer sous la barre des 4 minutes pour analyser 1 journée.
| Job (sur 1 journée) | temps d'exécution (s) |
| Job 1 | 205 |
| Job 2 | 201 |
| Job 3 | 198 |
| Job 4 | 195 |
| Job 5 | 197 |
| Moyenne (min) | 3,32 |
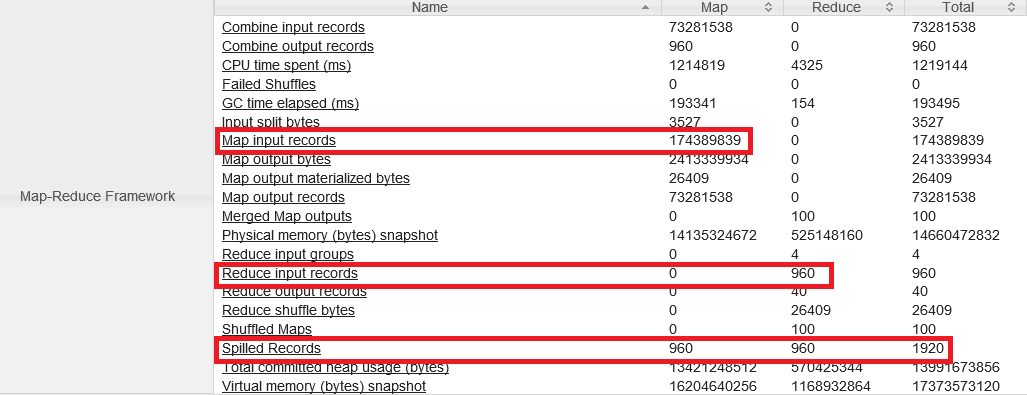
Je constate maintenant que le nombre de records passé aux Reducers a franchement diminué, ainsi que le nombre de records spillés.
Troisième optimisation : plus de containers pour les tâches map
Avec l’utilisation du Combiner, ma stratégie ne requiert que peu de ressources pour le reduce. La plupart des traitements se font coté map, l’algorithme est plus efficace car il est devenu mieux parallélisable. Cependant, quand j’observe le dashboard lors de l’exécution du job, toutes les ressources ne sont pas utilisées. En effet, au lieu d’avoir 22 mappers pour remplir la capacité maximale du cluster, je n’en ai que 18.
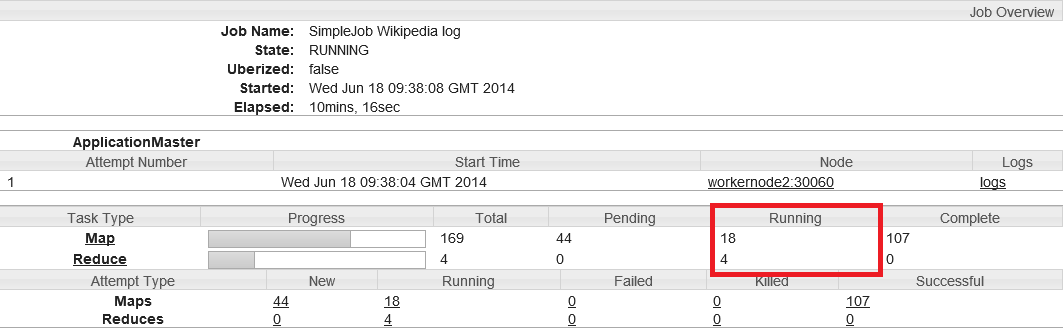
En réalité, Hadoop réserve des containers pour les tâches de reduce dès la fin du premier mapper afin que les reducers puissent commencer à télécharger les records et à les fusionner pendant que les autres mappers finissent leur travail. C’est plutôt intéressant, niveau performance, quand il y a beaucoup de records en sortie des mappers à transférer par le réseau vers les reducers et qu’il existe trop de splits pour terminer les calculs en un seul passage.
Attention : il faut distinguer deux choses lorsque l’on parle de reduce. Comme l’explique Ed Mazure dans sa réponse, la phase de reduce est composée de trois parties.
- Récupération des records en sortie de map (de 0 à 33%)
- Fusion des records ayant les mêmes clés (de 33 à 67 %)
- Application de la méthode « reduce » surchargée par l’utilisateur (de 67 à 100%)
De mon côté, très peu de records sortent des mappers grâce au Combiner, donc j’ai plutôt intérêt à utiliser le maximum de containers pour la phase de map plutôt que d’utiliser des containers pour les reducers qui se tournent les pouces.
Deux propriétés dans la configuration du cluster vont m’être utiles :
- mapreduce.jobtracker.maxtasks.perjob => cette propriété peut être mise à -1 pour préciser que le cluster prendra autant de containers disponibles pour la phase de map.
- mapreduce.job.reduce.slowstart.completedmaps => cette propriété sert à spécifier le pourcentage (compris entre 0 et 1) de complétion des mappers à partir duquel les reducers sont instanciés et commencent à récupérer les records.
Je modifie la valeur de mapreduce.job.reduce.slowstart.completedmaps à 1.0 (la valeur par défaut est 0,05), pour que les reducers ne commencent qu’une fois toutes les tâches map terminées.
Je teste à nouveau :
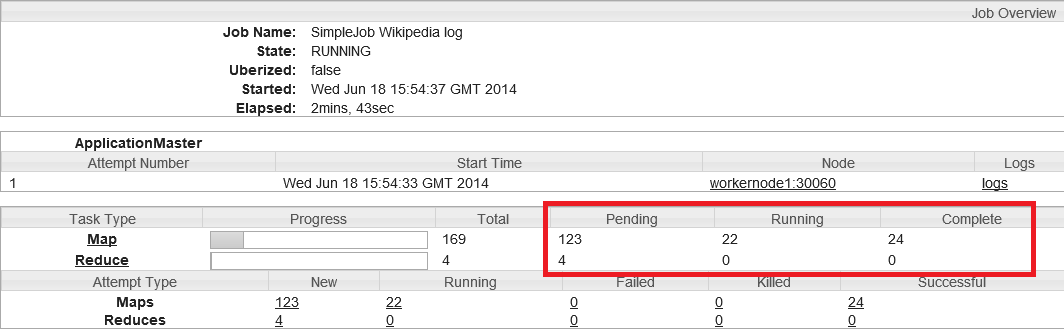
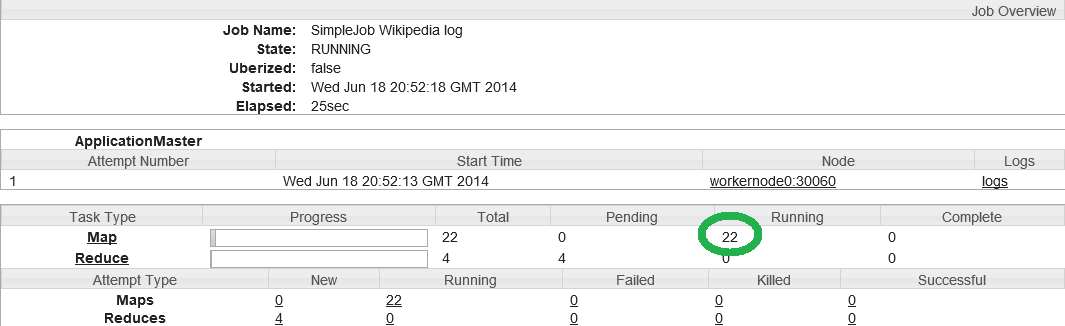
On peut voir dans la colonne Complete que 24 tâches map sont déjà traitées (plus de 5%), pour autant le cluster continue de réserver les containers aux tâches map qui sont au nombre de 22 dans la colonne Running.
| job | temps d'exécution (s) |
| Job 1 | 183 |
| Job 2 | 168 |
| Job 3 | 172 |
| Job 4 | 170 |
| Job 5 | 164 |
| Moyenne (min) | 2,856666667 |
Quatrième optimisation : la taille d’un split
Travailler sur Azure amène à streamer la donnée d’ASV vers nos nœuds de calcul. Ceci peut être un inconvénient à la performance même si Q10 donne de bons résultats. Mais cet inconvénient peut se tourner en avantage. En effet, le concept de block sur HDFS est à la base de la distribution du calcul sur les nœuds. La donnée est découpée en splits prenant en compte les blocks sur lesquels la donnée est distribuée. On a plutôt intérêt à ce moment-là d’enregistrer la donnée avec une taille de block spécifique afin d’anticiper le traitement qui s’en suit. Un nœud traite le block local, à partir du moment où il doit le récupérer d’un autre nœud, on perd.
Avec ASV, je pars du principe que de toute façon mes nœuds auront à télécharger les données où qu’elles soient : la co-localisation du code et de la donnée n’est plus utile. De ce fait, je constate en utilisant un TextInputFormat que 25 splits sont générés, pour une journée de 25 fichiers.
Autant jouer sur la taille des splits, de manière dynamique pour optimiser le nombre de mappers qui exécuteront le traitement et en faire une seule vague. Pour cela, je prends le nombre total de bytes à l’entrée du job, puis je le divise par 22 containers (ou un multiple du nombre de containers possibles).
L’avantage que j’en ai : tous les splits vont être traités en une seule fois, j’évite le comportement par default : les 22 premiers splits sont traités dans la première vague, puis 3 splits sont traités dans la deuxième vague avec 19 containers inutilisés. Ce qu’indique la capture à suivante -->
Le temps total d’exécution des tâches map équivaut à la tâche la plus longue de la première vague ajouté à la tâche la plus longue de la deuxième vague (en orange) :
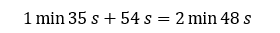
C’est dommage, autant n’avoir qu’une seule vague qui dure un tout petit peu plus (2 minutes). Pour régler ce détail, j’utilise alors un InputFormat particulier : CombineTextInputFormat. Il permet de fusionner plusieurs fichiers d’entrée, on l’utilise notamment pour des jobs s’exécutant sur beaucoup de petits fichiers afin d’éviter l’overhead d’une nouvelle instance de mapper procédant à un calcul très court.
De mon côté, je ne l’utilise que pour une seule chose : spécifier la taille du split, et c’est lui qui va se charger d’agréger les fichiers entre eux et de découper la donnée en split. Ensuite, les mappers « streameront » directement le nombre de bytes précis équivalent à 1/22 de la taille globale.
Et les résultats :
| Job (sur 1 journée) | temps d'exécution (s) |
| Job 1 | 162 |
| Job 2 | 161 |
| Job 3 | 171 |
| Job 4 | 159 |
| Job 5 | 157 |
| Moyenne (min) | 2,7 |
J’ai fait une petite courbe d’évolution histoire de me rendre compte de la progression :
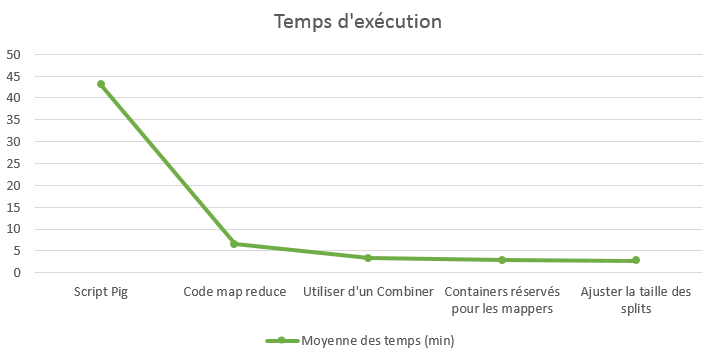
L’évolution de la courbe varie peu après le passage de Pig à un code MapReduce. Mais si je me focalise sur l’évolution entre le premier code MapReduce sans optimisation et le dernier avec toutes les optimisations, le temps d’exécution a diminué de plus de la moitié.
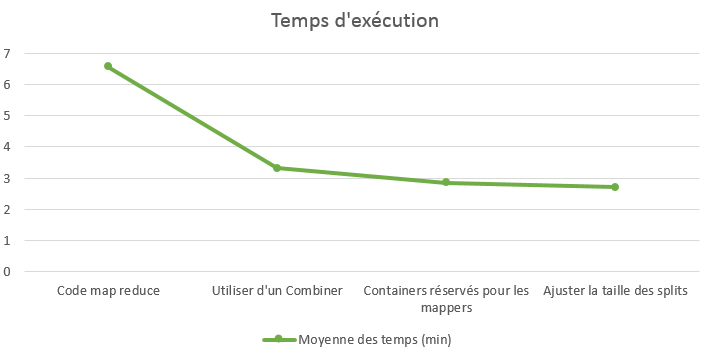
Gagner 10% sur un job qui dure 3 minutes n’est pas très représentatif mais à l’échelle d’une journée, ça représente 2 heures et de demi. Ça peut être intéressant de grappiller quelques pourcents quand vous avez beaucoup de jobs à lancer, avec une utilisation forte de votre cluster. On peut se demander le gain des optimisations après l’application d’un Combiner par rapport au temps passé. C’est pourquoi j’ai lancé la comparaison sur une semaine entière :
- avec l’utilisation d’un Combiner seulement : 16 minutes 45 s en moyenne
- avec l’ajustement de la taille des splits : 12 minutes 28 s en moyenne
C’est la fin
J’estime que mon algorithme est suffisamment optimisé pour la suite qui serait de le faire tourner sur toute une année. L’analyse est lancée avec 220 mappers pour découper les 1,3 To, ce qui (théoriquement) lancera successivement 10 vagues de mappers. Le job mettra 3 heures à s’exécuter.
Pour aller plus loin, je pourrais regarder du côté de l’équilibrage de mes mappers, afin qu’ils avancent tous à la même vitesse (il y en a certains qui mettent 10 minutes de moins que d’autres). Il serait peut-être plus pertinent de découper les splits par nombre de records plutôt que par nombre de bytes, cette technique prendrait donc en compte la fin des fichiers. Mais ce sera pour un autre article.
Je vous invite à lire aussi les références ci-dessous qui pourront vous aider à votre tour sur l’amélioration de la performance de vos jobs MapReduce.
Les leçons apprises :
- La performance sur des stratégies de parallélisation dépend fortement de l’infrastructure sur laquelle elles s’exécutent. A nous de faire les réglages pour adapter le code à l’infrastructure.
- L’efficacité d’un algorithme MapReduce se trouve dans la capacité à mettre le maximum de calculs et traitements dans les mappers.
- Même si le job s’exécute rapidement, explorer les métriques du tableau de bord Hadoop pour déceler des problèmes éventuellement masqués avant de passer à l’échelle.
- Les optimisations sans mesure ne servent à rien. Je ne l’ai pas retracé ici, mais c’est la première erreur que j’ai faite : chercher à optimiser le code alors que le problème était ailleurs.
Avec tous ces Tips, plus la doc en dessous vous allez être invincibles !

Références :
- Le fichier de configuration MapReduce mapreduce-default.xml d’Hadoop avec la description de chaque propriété ;
- MapReduce Patterns, Algorithms, and Use Cases sur le site Highly Scalable Blog pour comprendre quel algo correspond à quel cas d’usage avec une pseudo implémentation MapReduce à l’appui ;
- 10 MapReduce Tips sur le blog Cloudera ;
- 12 keys to keep your Hadoop Cluster running strong and performing optimum, d’Avkash Chauhan ;
- Hadoop Performance Tuning le livre blanc de la société Impetus ;
- Why use Blob Storage with HDInsight on Azure de Brad Sarsfield et Denny Lee;
- The State of Cloud Storage de l’entreprise Nasuni ;
- Tuning Hadoop on Dell PowerEdge Servers par Donald Russell ;
- My recent experience with Hadoop ;
- http://www.youtube.com/watch?v=fXW02XmBGQw