Amazon SimpleDB, le Harry Potter de Voldemort ?

Voldemort est une alternative aux systèmes internes d’Amazon Dynamo. Disponible en Open Source, cette solution implémente les mêmes patterns que Dynamo et est utilisée par LinkedIn.
Patterns mis en œuvre
Les grands du web ont développé, sous des contraintes de charge, des systèmes de stockage innovants. « Contraints » de partionner la donnée et de respecter le théorème de CAP, qui impose de choisir entre disponibilité et consistance, certains de ces acteurs comme Amazon ont choisi la disponibilité de leur système de stockage et proposent un modèle clé/valeur éventuellement consistant. La disponibilité du système tout d’abord avec la mise en œuvre des principes suivants :
- un mode master/master. Tous les nœuds sont disponibles en écriture. Un mécanisme de répartition de charge permet de dispatcher l’ensemble des requêtes sur l’ensemble des nœuds. L’utilisation de l’algorithme Vector Clock permet de suivre et de conserver les différentes versions ainsi que l’historique des objets notamment dans le cas d’écriture sur différent nœuds « master ». Des échanges protocolaires (type « gossip protocol ») permettent de propager de l’information (serveur perdu…)
- Partitionnement et réplication automatique des données entre les différents serveurs qui composent le cluster de base avec des enjeux d’optimisation des coûts (« commidity hardware ») et de résilience des systèmes. Le consistent hash est utilisé pour la répartition des clés sur les nœuds. Cet algorithme avait été présenté dans le cas de memcached comme un moyen de limiter la perte d’un cache. Dans une solution comme Voldemort, la donnée est persistante et cet algorithme permet de limiter la quantité de données à redispatcher sur les nœuds restants (pour respecter les configurations de réplication, de consistance).
- Un modèle éventuellement consistant qui cherche une alternative à ACID et au Two Phase Commit. Dans cette approche, toutes les versions des objets sont écrites (l’historique est géré par le « Vector Clock »), les conflits éventuels sont détectés et gérés au moment de la lecture de l’objet : mode « Read-Repair ». La réconciliation des objets se fait à la lecture en se basant sur les informations contenues dans le « Vector Clock ». La consistance quand à elle est garantie par le nombre de serveurs possédant la même version de cette donnée. En fait la consistance peut être paramétrée, c'est-à-dire qu’il est possible de définir, type de données par type de données, le nombre de nœuds sur lesquels une donnée doit être écrite pour considérer une écriture valide ou bien (plus intéressant) le nombre de nœuds sur lesquels une donnée doit être lue pour être considérée comme consistante. La configuration fine qu’il est possible de réaliser sur la donnée (nombre de nœuds en réplication….) permet d’adapter l’utilisation de l’espace de stockage à la criticité de la consistance en fonction des cas d’utilisation.
Mais rentrons dans le vif du sujet et regardons d’un peu plus près une solution comme Voldemort.
Stockage de l’information : structure, insertion et récupération des données
Une première étape simpliste consiste à définir la classe que l’on souhaite stocker. Exemple également classique : considérons un objet Client qui propose 3 propriétés que sont son identifiant (key), son nom (lastName) et son prénom (firstName). Les trois propriétés sont de simples chaînes de caractères. Pour stocker cette classe, il vous faudra définir son schéma, c'est-à-dire la liste des attributs qui la compose. Voldemort propose plusieurs façons de stocker l’information ; sur ce coup, j’ai utilisé JSON. Ainsi, il vous faudra modifier un fichier de configuration (store.xml) pour rajouter le schéma suivant :
…
json
{"key":"string", "firstName":"string"...}
Le truc intéressant est que chaque schéma est versionné . Il est ainsi possible d’avoir plusieurs versions et donc plusieurs structures d’un même type de donnée (dans notre exemple Client). Ainsi, à l’insertion, le moteur utilisera la dernière version définie. A la lecture, le moteur utilisera la version adéquate. Vous aurez également noté l’absence complète de contrainte d’intégrité. Autant de vérification qu’il faut reporter et réaliser au niveau de l’espace applicatif. Voldemort propose la notion de Store pour le stockage de ces données. A chaque Store est associé un type de donnée (défini comme précédemment).
int numThreads = 10;
int maxQueuedRequests = 10;
int maxConnectionsPerNode = 10;
int maxTotalConnections = 100;
String bootstrapUrl = "tcp://10.1.100.196:6666";
StoreClientFactory factory = new SocketStoreClientFactory(numThreads, numThreads, maxQueuedRequests, maxConnectionsPerNode, maxTotalConnections, bootstrapUrl);
StoreClient< string , Object> client = factory.getStoreClient("author");
Dans notre traditionnel monde relationnel, un store serait comparable à une table. SimpleDB propose un concept similaire avec la notion de « Domain » Insérer, supprimer ou récupérer des données est on ne peut plus simple. L’API proposée est en effet assez légère et proche de celle d’une Map. Autrement dit, insérer un objet se fait de la sorte (on note quelques similitudes avec les APIs Java permettant d’accéder à SimpleDB et l’utilisation d’une Map et non pas d’un objet Java pour insérer les attributs)
Map< string , Object> authorMap = new HashMap< string , Object>();
authorMap.put("key", "aKey”);
authorMap.put("firstName", "Bret Easton”);
authorMap.put("lastName", "Ellis”);
client.put("aKey”, authorMap);
Récupérer un objet est encore plus simple :
Versioned< object> object = client.get("key1");
En fait, le plus complexe résidera dans la génération (intelligente) de la clé (comment assurer l’unicité ? comment la retrouver ?...)
Réplication et « fail-over »
Gérer le « fail-over » se fait en répliquant la donnée sur autant de machines que nécessaire. Voldemort permet de spécifier ce paramètre dans le fichier de configuration store.xml via l’élement replication-factor. Si la valeur vaut 1, la donnée n’est répliquée sur aucun nœud et en cas de perte du serveur, vos données sont perdues. Sinon, la donnée associée au « store » est répliquée sur autant de nœud que défini.
Les données sont alors réparties en respectant les principes de « consistent hashing » ce qui limite la masse des données à redéployer en cas de perte d’un des serveurs.
Réplication et consistance
Assurer la consistance…Tout un programme dans un modèle « éventuellement consistant »…Contrairement à ACID qui isole, verrouille certaines portions de données, et quelque part séquence les transactions les unes à la suite des autres, ces modèles ont fait le choix de la disponibilité à l’écriture et les éventuelles divergences (et réconciliation) entre données sont gérées à la lecture (mode « Read-Repair »). Comme évoqué précédemment, il est possible de configurer le nombre de nœuds sur lequel la donnée doit être répliquée pour considérer une écriture valide ( W ) ainsi que le nombre de nœuds sur lequel la donnée doit être lue (R) pour être considérée comme consistante. Si de plus, votre configuration respecte la formule magique W+R > N, N étant le nombre total de nœuds sur lesquels la donnée est répliquée, vous êtes dans un modèle consistant : une lecture suivant immédiatement une écriture est garantie de retourner la dernière valeur écrite. Cette configuration se fait au niveau de chacun des « Store ».
Définition du cluster de base
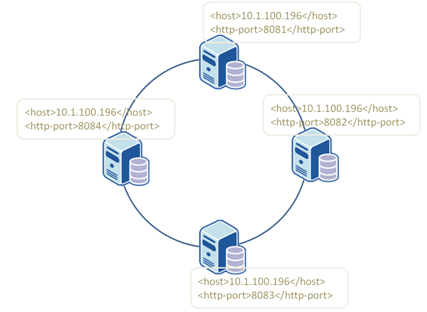
< cluster > < name >mycluster< /name > < server > < id>0< /id> < host>10.1.100.196< /host> < http-port>8081< /http-port> < socket-port>6666< /socket-port> …
< server>
< id>1< /id>
< host>10.1.100.196< /host>
< http-port>8082< /http-port>
< socket-port>6667< /socket-port>
… …
Configuration de la réplication
Au niveau des fichiers store.xml, les paramètres de réplication, nombre de lectures ou d’écritures nécessaires pour garantir la consistance, sont définis :
< store> < name>author< /name> < persistence>bdb< /persistence> < routing>client< /routing> < replication-factor>2< /replication-factor> < required-reads>1< /required-reads> < required-writes>2< /required-writes> …
…
Gestion de la réplication – le test.
Le meilleur moyen de tester la réplication reste de se connecter sur un des nœuds du cluster (hyper simple en ligne de commande) et de localiser la donnée (Voldemort fournit des fonctions permettant – à la sqlplus – de naviguer dans les données) 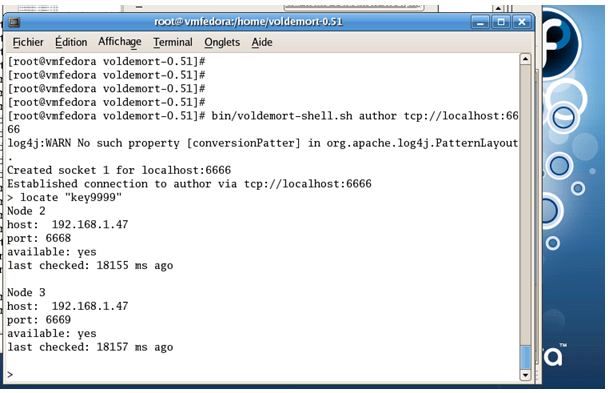
L’écriture de la donnée pour la clé « key9999 » a été dupliquée sur deux nœuds. La lecture de la donnée donne : 
Gestion de la réplication – autre test…
En modifiant légèrement la configuration (en imposant 2) et en arrêtant certaines instances (notamment celles, sauf une, qui contiennent la donnée), la lecture de l’objet est impossible : seul un serveur contient la donnée et la configuration en attend deux…
> get "key1"
: GET operation on store 'author' completed unsuccessfully in 1.98 ms.
Could not connect to node 3 at 10.1.100.196 marking as unavailable for 2000 ms.
voldemort.store.UnreachableStoreException: Failure while checking out socket for 10.1.100.196:6669:
Conclusion
Difficile de conclure une introduction ou un tutorial sur un produit mais deux choses m’ont surpris lors de l’utilisation (en mode POC) de ce produit.
Premièrement, sa simplicité d’installation et d’utilisation. Je n’ai aucune expertise de type « administration des bases de données relationnelles » et certes, ce tutorial reste du niveau introduction et ne fait pas mention des problématiques de la « vraie vie » : celles de la production. Il n’empêche que de prime abord, c’est simple et intuitif.
En second lieu, sa possibilité de « tuning » fin au travers notamment des paramètres de réplication, et un aspect que nous n’avons pas abordé : la notion de partition (les données sont associées à des partitions et il est possible de répartir les partitions sur des serveurs physiques différents – par configuration malheureusement – entre les serveurs physique des bases). Ce « tuning » fin permet d’optimiser l’utilisation de l’espace de stockage en l’adaptant au cas d’utilisation (plutôt orienté lecture ou écriture) et aux types de données (ceux qui nécessitent une forte consistance etc…) ; bref de placer, sur des systèmes fortement sollicités, le curseur entre consistance et performance.
D’autres points surprennent. La définition des structures des données (au format JSON dans notre exemple) me laisse songeur quant à la gestion des champs obligatoires. Bien entendu la gestion des relations (ou plutôt son absence) imposera soit de dénormaliser le modèle soit de gérer les relations sous la forme d’identifiant simple (en stockant simplement l'identifiant de la donnée référencée). Enfin l’absence de langage de requêtage pose des questionnements quand à la faculté de retrouver la donnée une fois stockée, sauf à utiliser des recherches « full-text » : un autre bel enjeu d’architecture.