Aerospike : du Clé-Valeur sous stéroïdes
Aerospike est un Key-Value store haute performance édité par la société du même nom, anciennement CitrusLeaf.
Quelques chiffres pour illustrer l’aspect haute performance : on parle ici de plusieurs centaines de milliers à un million d’opérations par seconde par serveur (sur une instance AWS C3.8XL à $1.308 /h) avec 99,9% des requêtes ayant une latence inférieure à 5 millisecondes.
Aerospike (la société) a “Open Sourcé” en juin dernier le fruit de 5 ans de travail afin de s’ancrer dans le panorama des solutions de stockage NoSQL.
En quelques mots, Aerospike est comparable à un Redis mais avec une architecture distribuée shared nothing proposant sharding et réplication permettant ainsi une scalabilité linéaire.
Il est à noter qu’Aerospike est conçu et implémenté pour tirer partie d’un stockage Flash (SSD) en accédant directement aux disk blocks.
Dans les fonctionnalités intéressantes que nous allons détailler par la suite, nous pouvons nommer :
- Multi-DataCenter
- Rack awareness
- Index secondaires
- TTL
- User Defined Functions (MapReduce, …)
Plus que du Clé-Valeur
Aerospike est fondamentalement un key-value datastore ; toutefois il propose des concepts de namespace et set – respectivement équivalents aux notions de schema et table dans le monde relationnel – dans lesquels sont organisés les rows accessibles par key. Chaque row dispose quant à elle de bins typés et nommés que l'on peut assimiler à des colonnes.
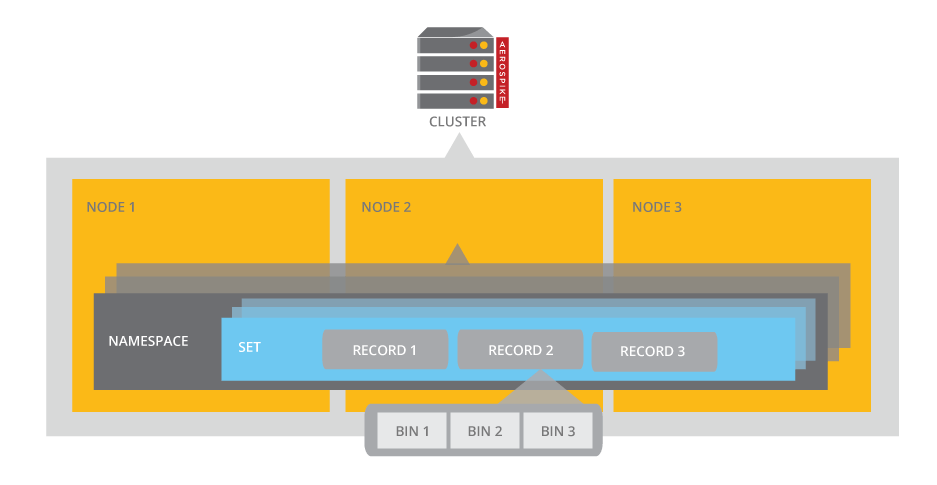
Cela présente l'avantage de pouvoir concevoir ou transposer un modèle de données relationnel dans le contexte key-value sans avoir à recourir à des conventions de nommage exotiques pour les clés comme cela est d'usage dans l'univers clé-valeur notamment dès lors qu’on souhaite stocker des événements ou des séries temporelles.
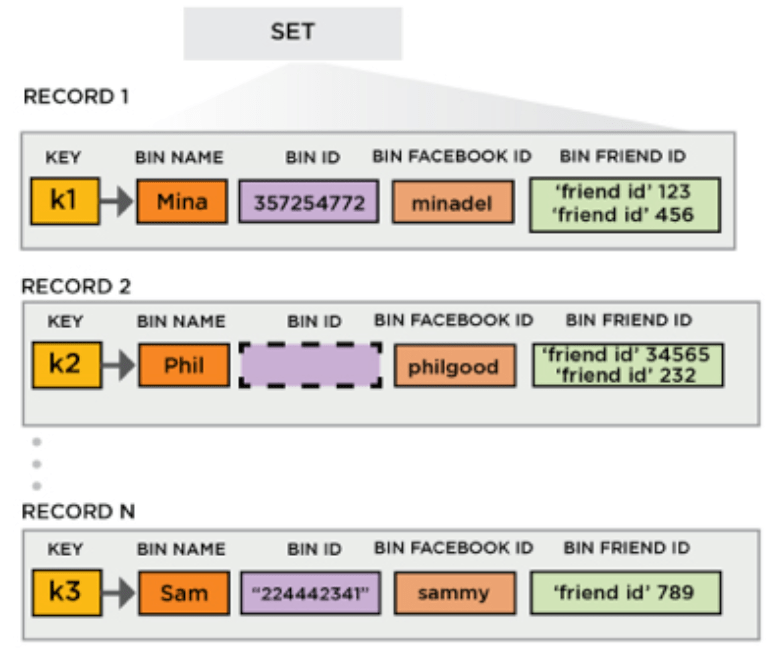
On pourra toutefois regretter que les TTL se positionnent au niveau des rows et non des bins comme cela est le cas sur des solutions orientées colonne (Apache Cassandra) obligeant de fait à gérer manuellement les expirations des valeurs dès lors qu’on a besoin de le faire à cette granularité.
Large Data Types
Les bins peuvent être de types primitifs : String, Integer, BLOB ou riches via les Large Data Types : Map, List, Set & Stack.
Similaires à ce que propose Redis au premier abord en terme de « richesse » de modélisation pour du clé-valeur, la spécificité d'Aerospike sur ce point et que les Large Data Types sont implémentés comme des rows à part entière mais colocalisés avec le row "parent", permettant ainsi de retourner la totalité des données avec un seul accès mémoire/disque.
Index secondaires & AQL
Il est possible de créer des index secondaires sur les bins afin de rendre le requêtage possible sur ces derniers. Il est à noter que les index secondaires sont mis à jour de façon synchrone avec les écritures.
Les requêtes se font alors via AQL (pour Aerospike Query Language) - un SQL-like simplifié. Les index secondaires permettent de filtrer les résultats sur les bin indexés :
aql> SELECT name, age FROM users.profiles WHERE age BETWEEN 20 AND 29 +---------------------------+-----+ | name | age | +---------------------------+-----+ | "Bob White" | 22 | | "Annie Black" | 28 | | "Ricky Brown" | 20 | | "Tammy Argent" | 22 | +---------------------------+-----+ 4 rows in set (0.000 secs)
Agrégations & User Defined Function
Aerospike offre la possibilité d'agréger les données par l'utilisation de User Defined Functions écrites en LUA.
Il est à noter que deux types de UDF peuvent être implémentées
- Record UDF : il s’agit d’une fonction qui sera executée avec chaque row en tant qu’argument. Les cas d’usages sont évidemment les filtrages d’éléments, sélection et/ou modification de bins, …
- Stream UDF : il s’agit ici d’effectuer un traitement read-only sur un ensemble de records. C’est l’approche qui est logiquement adoptée pour effectuer des agrégations à base de MapReduce ou autre. Les Stream UDF peuvent aujourd’hui être exécutés uniquement au-dessus d’index secondaires.
Architecture distribuée garantissant une scalabilité linéaire
D'un point de vue cluster, l'intérêt d'Aerospike réside dans le fait qu'il s'agit d'une architecture shared nothing : chaque noeud du cluster est équivalent aux autres, éliminant ainsi tout SPOF. La gestion du cluster est implémentée par des protocoles P2P de type PAXOS et Gossip afin de détecter les pannes et déclencher un rééquilibrage des données le cas échéant (en cas de perte/ajout d'un noeud).
Comme nous l’avons déjà évoqué, cette approche shared nothing permet également d'offrir une scalabilité linéairement prédictible à l'instar de Couchbase ou Cassandra.
Les drivers pour les différents langages sont des "smart clients" dans le sens où le partitionnement des données sur le cluster est connu des applications clients via les drivers afin d'accéder aux données en un seul saut réseau.
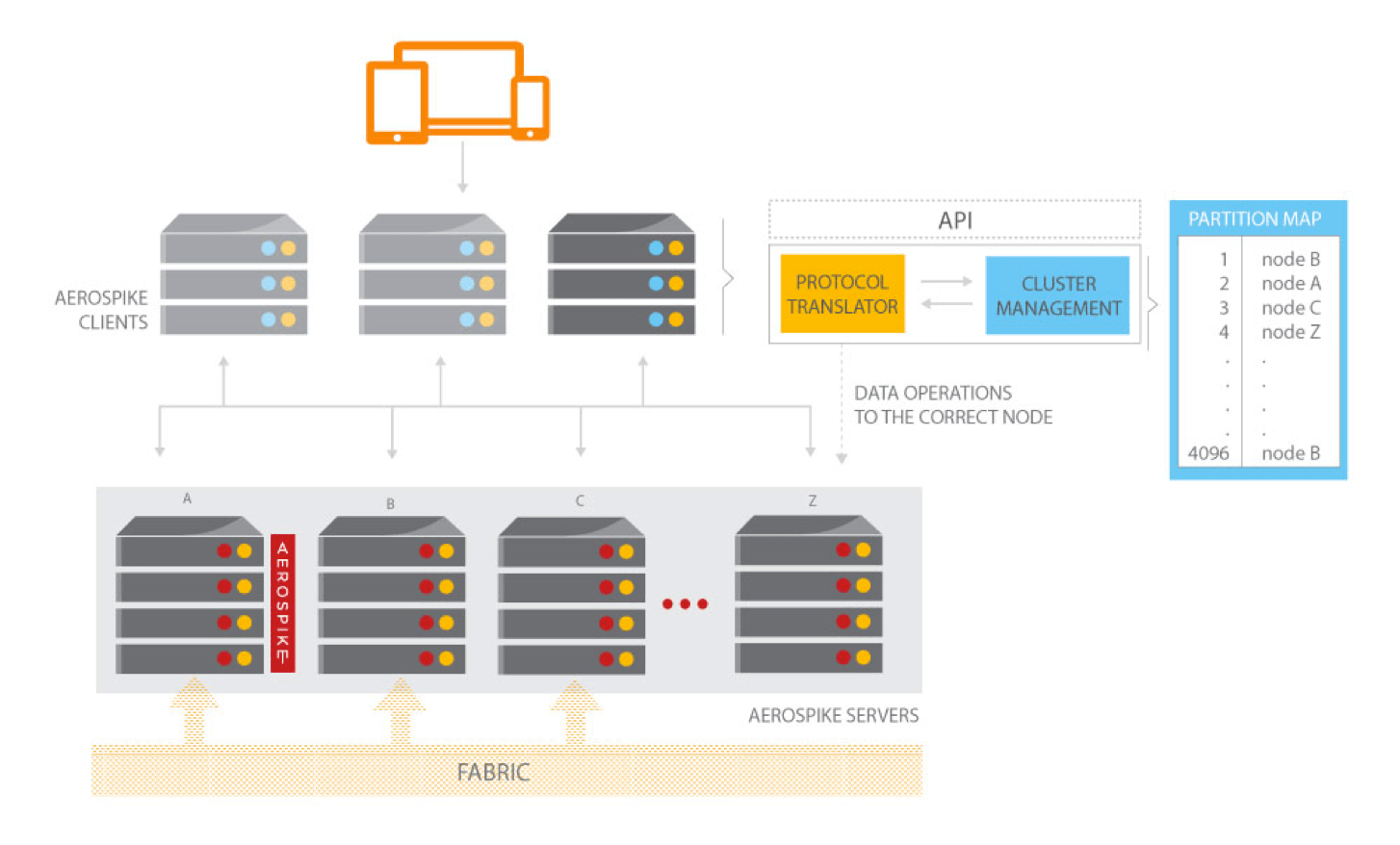
Le nombre de réplication des données est paramétrable au niveau des namespaces et est configuré par défaut pour être synchrone avec les écritures rendant les données de fait immédiatement cohérentes à l’intérieur du cluster.
Un stockage optimisé pour le SSD
Comme toutes les bases de données distribuées, un stockage sur disque local est fortement recommandé par rapport à un stockage réseau (SAN, NAS, …) afin de paralléliser les accès disque et diminuer la latence.
Aerospike est allé plus loin et a fait le choix d’optimiser son produit pour les technologies de stockage Flash. En effet le moteur, écrit en C, court-circuite le système de fichiers et accède directement aux blocs disque.
Aerospike propose plusieurs choix concernant la persistance des données :
- Stockage en RAM uniquement avec ou sans persistance des données sur disque (pas nécessairement SSD)
- Stockage hybride en RAM et SSD
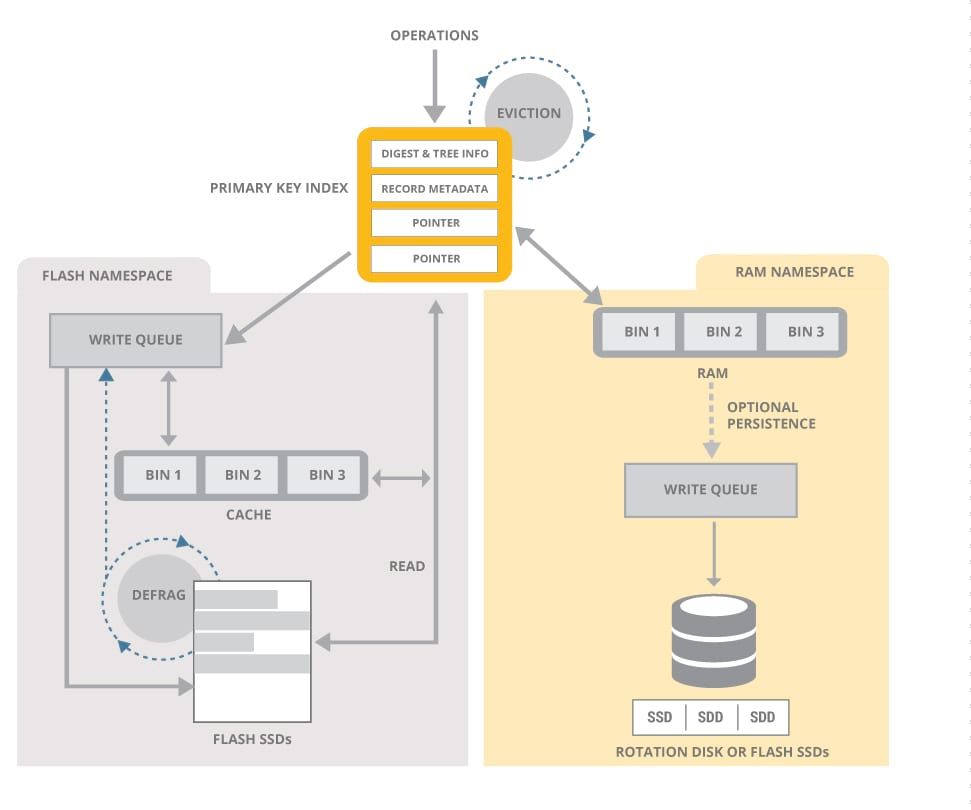
Il faut bien comprendre que le SSD ne doit pas être perçu comme une couche de persistance mais avant tout un moyen d’étendre la RAM.
Là où d’autres technologies NoSQL vont inviter à augmenter le nombre de machines dans un cluster pour y apporter plus de RAM, Aerospike tire son épingle du jeu en mettant à profit le SSD comme un stockage hybride : très basse latence avec des accès optimisés pour être proche des temps d’accès observés sur la RAM (0.6-0.9 ms contre 0.1-0.3 ms) et afin d’assurer la durabilité des données.
Aerospike, pour qui ? Pour quoi ?
L'utilisation comme cache paraît évidente tant pour faire du stockage de session et aller vers du cross-canal par exemple que pour améliorer l'accès aux données d'un système sous-jacent.
Le schéma ci-dessous illustre ce second cas dans l'exemple d'un service de comparaison de voyages en ligne qui a un accès limité (car payant) aux informations de prix auprès des brokers :
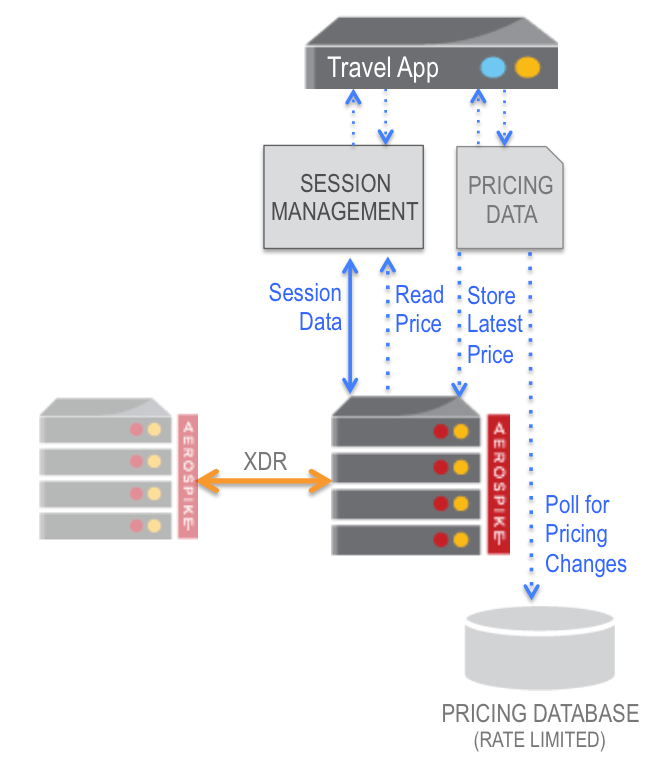
Comme évoqué, un autre cas d'usage est le maintien de contextes utilisateurs en mémoire comme cela est fréquent dans la publicité sur Internet où une faible latence est nécessaire pour afficher des publicités personnalisées parfois via des stratégies de Real Time Bidding. D'ailleurs, la majorité des clients d'Aerospike se situent dans ce secteur.
Il faut savoir que la plupart de leurs clients stockent entre 1 et 100 To de données sur leur cluster Aerospike, d'où l'intérêt économique d'utiliser du SSD plutôt que de la RAM.
Licensing
Du fait d'avoir libéré les sources d'Aerospike en juin dernier, une version Community est aujourd'hui disponible.
La version Enterprise quant à elle est enrichie des fonctionnalités suivantes :
- Multi Data Center (XDR) qui est une réplication asynchrone
- Fast restart qui consiste en une sorte de script de warm up pour peupler la RAM au démarrage et éviter un cold start
- Support 24/7
Vers 2015 et au-delà
Aerospike travaille d'ores et déjà sur un connecteur Hadoop (via les API InputFormat et OutputFormat) dont la première version devrait être disponible d'ici peu.
D'après les échanges que nous avons eus avec les équipes, il semblerait que des travaux soient en cours pour s'intégrer avec Apache Spark.
Notre avis sur Aerospike
Aerospike se positionne très clairement sur la faible latence et propose une solution convaincante en vue des performances annoncées. Notre vision est qu’il s’agit d’une sorte de super Redis puisqu’il vient compléter ses atouts (RAM first, collections Set/List/Map, …) avec des fonctionnalités qui lui font défaut tel que le sharding integré.
Pour comparer Aerospike à une autre solution clé-valeur offrant du sharding, sans considérer l’aspect performance, on peut affirmer que la modélisation et le requêtage avec AQL, aussi simples soient-ils, sont plutôt agréables là où Couchbase nécessite de travailler avec des index secondaires construits de façon asynchrone via du code MapReduce en JavaScript. Sur ce point, il faudra surveiller ce qui va advenir de N1QL - le prometteur langage de requêtage de Couchbase.
Aérospike est une solution qui est plutôt du côté Cohérence et Partitionnement vis-à-vis du théorème de CAP (Cohérence, Disponibilité et Partitionnement), du fait de son système de réplication synchrone de chaque écriture et des mises-à-jour des index, synchrones elles-aussi. Côté applicatif, il faudra donc anticiper de potentielles indisponibilités du système lors de panne d’un noeud, le temps (quelques secondes) pour le cluster de désigner où sont les nouveaux master pour chaque partition (auto-failover).
Nous espérons pouvoir creuser cette question de la disponibilité et également de la tolérance à la partition dans une étude plus approfondie à venir.