Accélérer le Delivery de projets de Machine Learning
Cet article sert d'introduction à une série plus large, traitant de l'application du framework Accelerate dans un contexte incluant du Machine Learning
Avant de commencer, voici quelques définitions et conventions de nommage que nous adopterons tout au long de la série d'articles :
Machine Learning : “Le Machine Learning est une fonctionnalité qui permet à des logiciels d'effectuer une tâche sans programmation ni règles explicites”. (Source google). Machine Learning est souvent abrégé ML.
Delivery : le processus permettant de mettre un produit entre les mains des utilisateurs finaux. Ce processus inclut la définition, le développement et livraison de la solution.
Machine Learning Delivery : l'expression que nous allons utiliser pour parler de Delivery d'une solution comportant du Machine Learning.
Performance de Delivery : la faculté à fournir de manière fiable, efficace et continue une application à valeur ajoutée à ses utilisateurs finaux.
Proof Of Concept (POC) : on appelle POC un projet limité dans le temps dont l'objectif est de valider la pertinence et le fonctionnement d'un concept incertain associé au produit qu'on veut construire.
Pourquoi avons-nous choisi de rédiger cette série d'articles ?
En tant que consultants dans le secteur de l'informatique, nous avons toujours cherché à améliorer notre Delivery logiciel en nous inspirant de l'état de l'art technologique et méthodologique. Notre objectif est avant tout de livrer rapidement un produit de qualité qui apporte de la valeur à ses utilisateurs.
Dernièrement, nous avons été confrontés à un nouveau type de Delivery : celui de produits incluant du Machine Learning qui embarquent généralement un ou des modèle(s) de ML ainsi qu'un lot de nouveaux paradigmes et difficultés.
Nous observons souvent chez les clients qui cherchent à intégrer du Machine Learning ce qu'on appelle des "usines à POC". Celles-ci ont pour objectif de tester et valider rapidement une hypothèse avant de se lancer dans le développement du produit. Dans ce contexte, on essaye souvent de répondre à la question “Y a-t-il du signal dans les données ?”, ou peut-on résoudre notre problème avec des algorithmes de Machine Learning et les données que nous avons à disposition. Malheureusement, ces POC ont souvent tendance à se multiplier sans jamais aboutir à un projet de Delivery visant à livrer aux utilisateurs un produit avec de la valeur ajoutée. Or, tant qu'un code n'est pas entre les mains des utilisateurs finaux, il n'apporte aucune valeur. Nous nous sommes donc posé la question : quelles sont les pratiques et méthodes à envisager si l'on souhaite faire du Machine Learning Delivery efficace ?
Pour répondre à cette question, nous avons formé un groupe de travail dont l'objectif est de capitaliser et de structurer ce que nous avons appris depuis plusieurs années chez OCTO en termes de Machine Learning Delivery. Ce sujet étant plus récent et moins mature que le Software Delivery, nous nous sommes tournés vers des pratiques qui ont déjà montré leur efficacité sur des projets de développement logiciel et qui sont répertoriées dans le livre Accelerate sorti en 2018. Les auteurs de ce livre y présentent le résultat de 4 ans de recherche sur les caractéristiques des entreprises technologiques performantes.
En quoi consiste Accelerate ?
L'étude Accelerate a démontré que les organisations performantes en delivery atteignent deux fois plus leurs objectifs que les organisations les moins performantes (voir chapitre 2 du livre Accelerate). Elle s'est donc intéressée aux pratiques des organisations les plus performantes et a réussi à faire émerger un état de l'art des capacités à acquérir pour améliorer sa performance de Delivery.
Pour améliorer la performance de Delivery, il faut la mesurer. Accelerate propose deux indicateurs de vitesse et deux indicateurs de stabilité, car cette performance dépend autant de la vitesse à laquelle on délivre que de la stabilité et de la qualité des éléments produits:
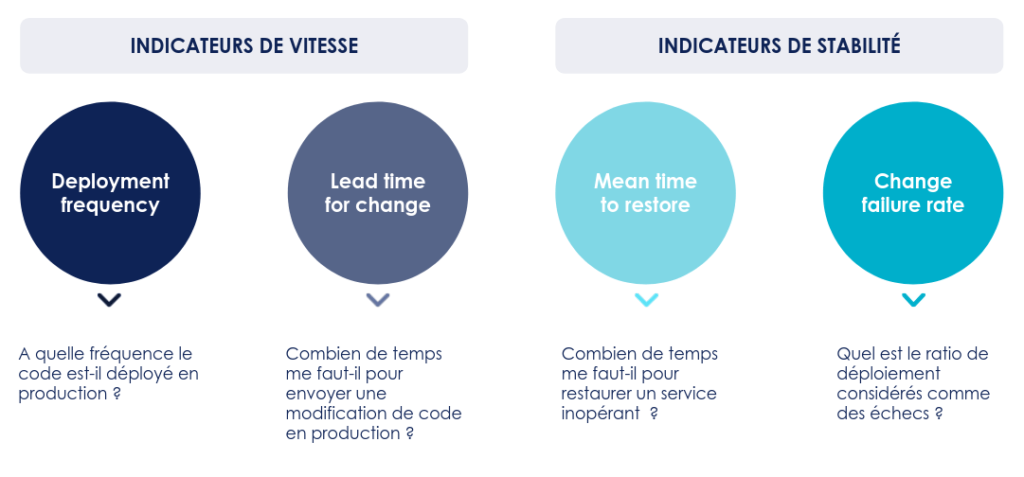
Les 4 indicateurs de performance du Delivery
Les auteurs d'Accelerate ont construit un modèle qui contient les pratiques des acteurs de l'informatique les plus performants selon les indicateurs mentionnés ci-dessus. Ce modèle s’inspire des principaux courants philosophiques du développement logiciel : le DevOps (toute le monde est responsable de la production), le Lean (limitation des tâches en parallèle pour aller plus vite), le Flow (une cadence rythmée) et l’Agile (des cycles courts pour avoir des retours réguliers).
Il comprend initialement 24 capacités, que l'on veut concrètes et mesurables, regroupées en 5 familles.
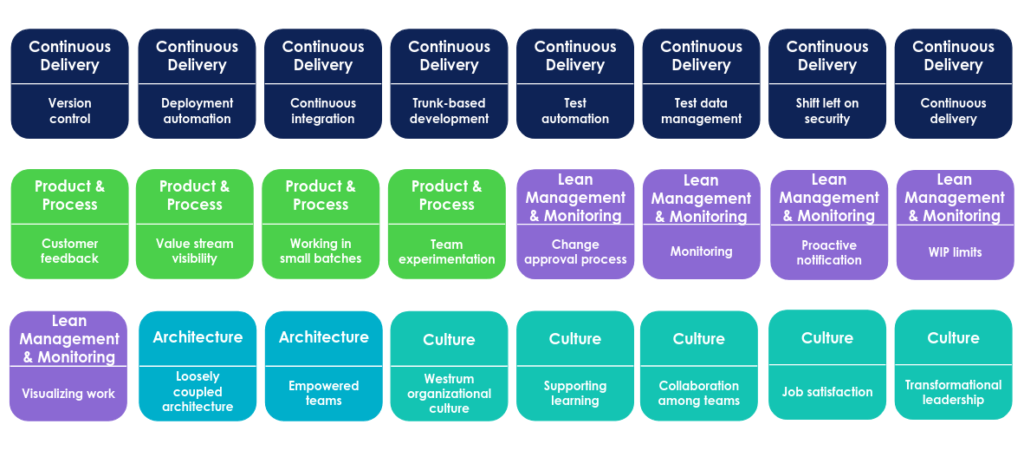
Les 24 capacités du framwork Accelerate
En ce qui concerne leur adoption dans un environnement de développement logiciel, plusieurs recommandations existent, dont la plus importante est d'adopter une approche progressive et durable.
Mais peut-on appliquer le framework Accelerate dans un contexte de Machine Learning ?
Oui c’est possible ! C’est une conviction que nous avons acquise par l’expérience chez OCTO.
C’est possible, car un projet de Machine Learning est un projet de développement logiciel … avec quelques spécificités. On peut citer l’utilisation d’outils dont la maturité est encore à prouver, rendant difficile leur intégration dans un système d’information existant, ou encore l’acquisition de compétences en Data Science et Machine Learning que relativement peu de personnes maîtrisent. On s’expose également à davantage d’incertitudes qui demandent plus d’explorations et d’expérimentations avant d’être levées, souvent partiellement. Les résultats de ces explorations aboutissent à une validation (ou invalidation) de faisabilité en partant de quelques hypothèses plus ou moins fortes.
Après la validation de faisabilité, de nouvelles tâches viennent s’ajouter à un backlog produit classique, telle que l’annotation de données, qui d’ailleurs peut être un défi en soi.
Ces données annotées servent à créer (ou entraîner) un nouveau type d’asset sous la forme de modèles de Machine Learning. Il existe des modèles de Machine Learning entraînables sans données annotées, mais ceux-ci sont plus rares.
Ces nouveaux assets introduisent plusieurs nouveaux défis car ils ont leurs propres paradigmes de déploiement et il faut les monitorer particulièrement. Il faut également gérer leurs cycles de vie avec attention en les **“versionnant” (**au sens logiciel), en les évaluant périodiquement et en les ré-entraînant si besoin pour éviter leurs dérives dues à leurs vieillissements.
En plus de ces challenges à connotation « tech », le ML impose aux organisations et aux équipes des défis méthodologiques et culturels comme :
- Comment découper son temps entre expérimentations, qui sont plus nombreuses, plus susceptibles d'échouer et plus longues qu’en Delivery logiciel, et industrialisation puis livraison d’une nouvelle fonctionnalité ?
- Comment assurer la diffusion des compétences et des connaissances acquises par les Data Scientists ?
- Comment valoriser les expérimentations infructueuses auprès des différents stakeholders ?
- …
Toutes ces questions ont constitué la base de notre travail et nous proposons d’y répondre dans une série d'articles qui contiendront le résultat de nos réflexions et de notre capitalisation autour du Delivery de produit contenant une brique Machine Learning. Nous y aborderons les métriques Accelerate et la performance de Delivery ainsi que chacune des capacités traitées dans Accelerate. Nous détaillerons surtout comment adapter ces méthodes et les appliquer dans un contexte de Machine Learning au travers d'outils, de pratiques ou de méthodes que nous avons identifiés ou expérimentés durant nos différentes missions.
Sommaire
Ici viendront s’ajouter les liens vers les articles de la série à leurs publications.
Westrum Organizational Culture et Machine Learning - Partie 2 : Changer la culture
La gestion visuelle dans un projet de Machine Learning Delivery
Les tests automatisés en Delivery de Machine Learning
La gestion de versions en Delivery de Machine Learning
La gestion des données de tests en delivery de Machine Learning
Comment travailler efficacement par petits incréments dans un delivery de Machine Learning ?
Rendre visible la chaîne de valeur dans un projet de Machine Learning Delivery
Automatiser les déploiements de projets de Machine Learning. Partie 1 : la construction de modèles
Inspirations
Finalement, nous aimerions partager avec vous quelques ressources qui nous ont inspirés et sur lesquelles nous nous sommes appuyés durant nos sessions de travail et de réflexion :
- Nicole Forsgren, Jez Humble, Gene Kim, Accelerate: Building and Scaling High Performance Technology Organizations
- Continuous Delivery for Machine Learning https://martinfowler.com/articles/cd4ml.html
- D Sculley et al., Hidden Technical Debt in Machine Learning Systems https://papers.nips.cc/paper/2015/hash/86df7dcfd896fcaf2674f757a2463eba-Abstract.html
- D Sculley et al., Machine Learning: The High-Interest Credit Card of Technical Debt https://research.google/pubs/pub43146/
- Lucas Bernardi, Themistoklis Mavridis, Pablo Estevez, 150 successful Machine Learning models: 6 lessons learned at Booking.com https://doi.org/10.1145/3292500.3330744
- MLOps: Continuous delivery and automation pipelines in machine learning https://cloud.google.com/solutions/machine-learning/mlops-continuous-delivery-and-automation-pipelines-in-machine-learning