Accelerating NiFi flows delivery: Part 1
While working in different contexts with NiFi, we have faced recurring challenges of development, maintenance and deployment optimization of NiFi flows. Whereas the basic approach suggests to manually duplicate pipelines for similar patterns, we believe that an automated approach is relevant for production purpose when it comes to implementing a significant amount of ingestion flows relying on a limited set of patterns or, more simply, when it comes to deploying these flows on different environments of execution.
The ability to reach the right level of automation for implementing NiFi flows implies principles such as versioning, code genericity, configuration centralization, automated generation, etc. Out of them, two concepts, “specialization” and “instantiation” of NiFi flows, have emerged and will be exposed in a two-post serie:
- Part 1 (this post): understanding the challenges, NiFi concepts and toolbox, implementing a specialization process through NiFi REST API
- Part 2: implementing the instantiation process and derived features
About NiFi
Apache NiFi is a real-time data ingestion platform that facilitates automation of data processing from various sources. Widely spread through its packaging into Hortonworks offering (Hortonworks DataFlow, now Cloudera DataFlow), NiFi can be a facilitator in building data pipelines at the edge of a data platform, for data ingestion or data exposure.
Whereas handling streaming data flows is one of its primary strengths, do not expect NiFi to be used as an ETL. For instance, ingesting IoT data using MiNiFi (edge) or any message-based data flows are generally ideal use cases for NiFi, but ingesting flat files with a complex integration logic or data through JDBC will not be a good match.
In other words, NiFi acts as a gateway for the data platform by abstracting the heterogeneous input or output ecosystem thanks to its rich library of connectors. It should be focused on message-based data flows and should not be used to build transformation pipelines within the data platform. Although NiFi comes with a GUI, abstracting part of the most technical aspects, it might turn into a complexity factor while tuning performance.
Basics of NiFi
Below are some concepts that will be used in this post and that need to be exposed for a clear understanding.
Processor: a “Processor” is the elementary work unit in NiFi. There are different types of processors with various purposes such as creating, sending, receiving, transforming, routing, splitting, merging and processing data. It can be seen as an elementary piece of a pipeline with inputs and outputs through which data flow. NiFi comes with a rich library of prebuilt processors such as “PutHDFS” or “ConsumeKafka”.
Process Group: a “Process Group” is a wrapper of a group of processors connected to each other to build a pipeline in which data will flow to reach a specific purpose. For instance, consuming messages from a Kafka topic to write them into HDFS is a process group that would, at least, be composed of two processors (“ConsumeKafka” and “PutHDFS”). Note that process groups can be nested into each other.
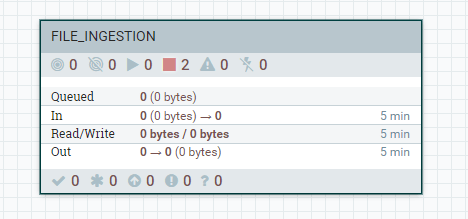
A “FILE_INGESTION” process group as seen in NiFi UI
What it looks like inside a process group in NiFi UI
Note that the term “flow” is generally used to designate a data pipeline i.e. a process group. Therefore, “flow” and “process group” designate the same concepts in NiFi.
Template: NiFi embeds a native “template” feature which aims at accelerating the development of flows by duplicating existing and saved patterns. This feature is being taken over and enriched with NiFi Registry, especially to facilitate version control.
About templates, from HDF 3.1 blog series part 2: Introducing the NiFi registry:
NiFi had support for using flow templates to facilitate SDLC [software development life cycle] use cases for a long time, but templates weren’t designed/optimized for that use case in the first place: no easy version control mechanism, not user friendly for sharing between multiple teams, no handling for sensitive properties, etc. But, now with the NiFi registry, you can get version control, collaboration, and easy deployment – significantly shortening the SDLC process, and accelerating flow deployment to achieve faster time to value.
Understanding the challenges
Need for adaptability
During a project lifecycle and similarly to any other piece of code, NiFi flows go through a multiple environments chain (e.g. development, integration, preproduction, production). Each environment having specific settings, the properties of processors may vary based on the execution environment. Therefore, the ability to adapt NiFi flows properties on deployment is mandatory : this is the specialization process.
Specialization can be defined in NiFi context as the ability to apply a configuration set to a NiFi flow and its processors to make it specific to a given environment or usage without editing its logic.
Need for factorization
While implementing data pipelines, similar patterns can be recurring. To optimize development and maintainability and to accelerate new use case implementation, generic NiFi flows can be created once and instantiated as many times as required : this is the instantiation process.
Instantiation that can be defined in NiFi context as the ability, from a generic NiFi flow, to generate new ones that may then be specialized to meet a specific use case.
How can specialization and instantiation help?
Let’s take the example of a basic “Kafka to HDFS” pattern which consumes messages from a Kafka topic and writes into HDFS files:
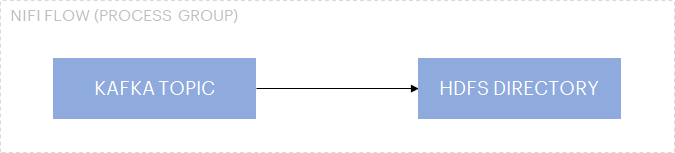
Basic pattern “Kafka to HDFS”
Assuming that multiple data pipelines actually rely on this “Kafka to HDFS” pattern, at least two scenarios can be envisioned to handle such a case:
- Either redevelop from scratch this pattern for each pipeline or copy-paste an existing NiFi flow implementing a similar pattern to adapt it (NiFi template native feature)
- Or build a NiFi flow once (“master”) and then industrialize its instantiation and specialization
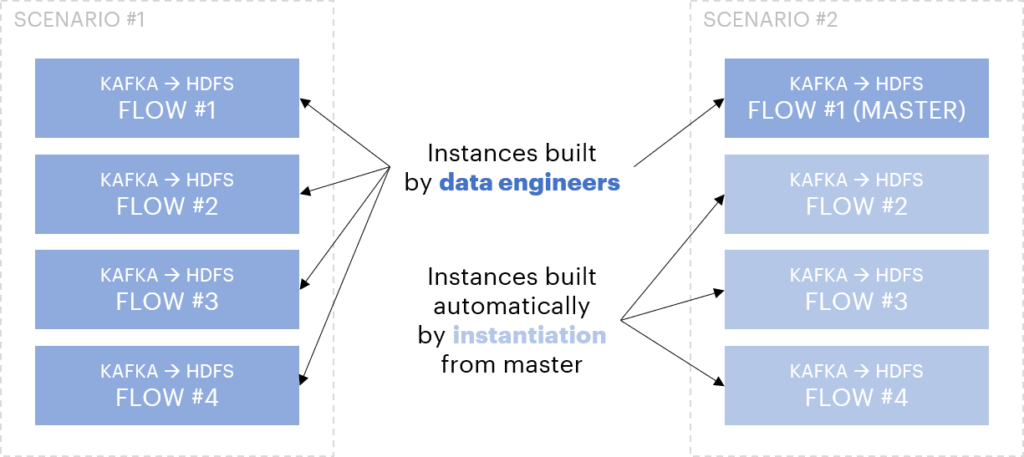
Overview of the two implementation scenarios
The first scenario consists in a decentralized model where the pattern is rebuilt each time from scratch or from copy-pasting an existing similar NiFi flow. The second one, much more interesting, is rather close to a centralized model with only one NiFi generic flow (master) built, maintained and synced with all the instances generated from the master.
At the end, keep in mind that the number of replicated items is the same in both scenarios, only the way to build them is different. In the second scenario, which is the one detailed in the following sections, the automation of the creation of any new NiFi flows based on an existing generic one (instantiation) and its specialization improve developers productivity, increase factorization and reduce delivery and maintainability costs.
Implementing specialization
Specializing a NiFi flow consists in setting values to variables of processors of a NiFi flow so that it can be contextualized and used for a specific purpose without altering its logic. The first step is to understand how to update properties value of NiFi objects.
NiFi comes with a UI for data engineers to design flows. It relies on calls to NiFi REST API, which is also directly available to any authorized users. This NiFi REST API is extremely rich and allows performing any actions usually done through the UI. Globally, the specialization process consists in orchestrating the right API calls to update a NiFi flow and make it operational.
Back to our Kafka to HDFS flow example: ConsumeKafka processor reads messages from a given topic, sends them to PutHDFS processor, which writes them down into a given HDFS folder. In NiFi UI, it could look like below:
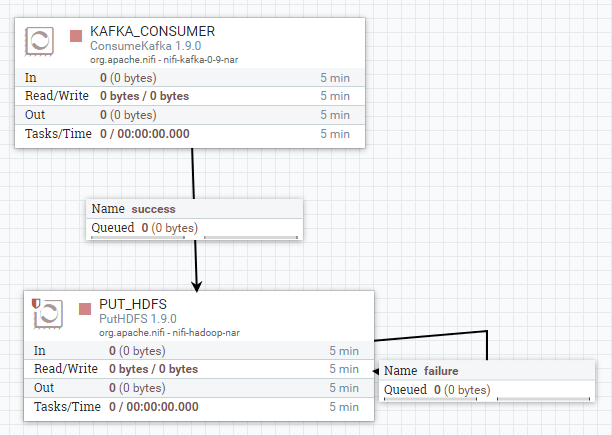
A NiFi flow viewed from NiFi UI
Let’s specialize this NiFi flow by setting the name of the input Kafka topic (framed in red below) in the ConsumeKafka processor. Here are the properties for this processor before updating:
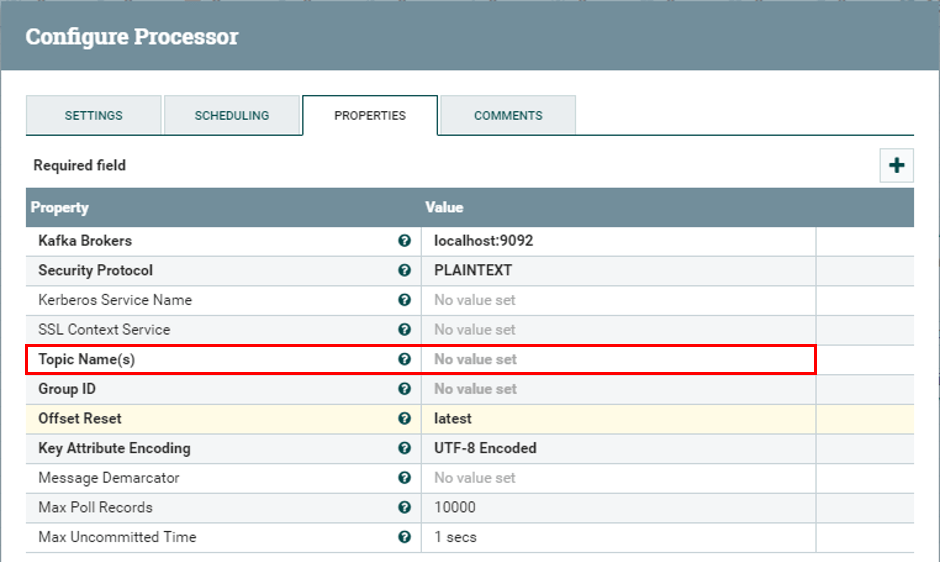
Processor properties before update
Now, running the REST API call:
curl -X PUT \ -H "Content-Type: application/json" \ -d '{"component": { "id":"2f9fb50e-0169-1000-8610-b6b24f84ffd5", "config": { "properties": { "topic":"/dev/mata" } } }, "revision": { "clientId": "2f30251f-0169-1000-443e-571d9105df39", "version":2 } }' http://localhost:8080/nifi-api/processors/2f9fb50e-0169-1000-8610-b6b24f84ffd5
And here is what it now looks like:
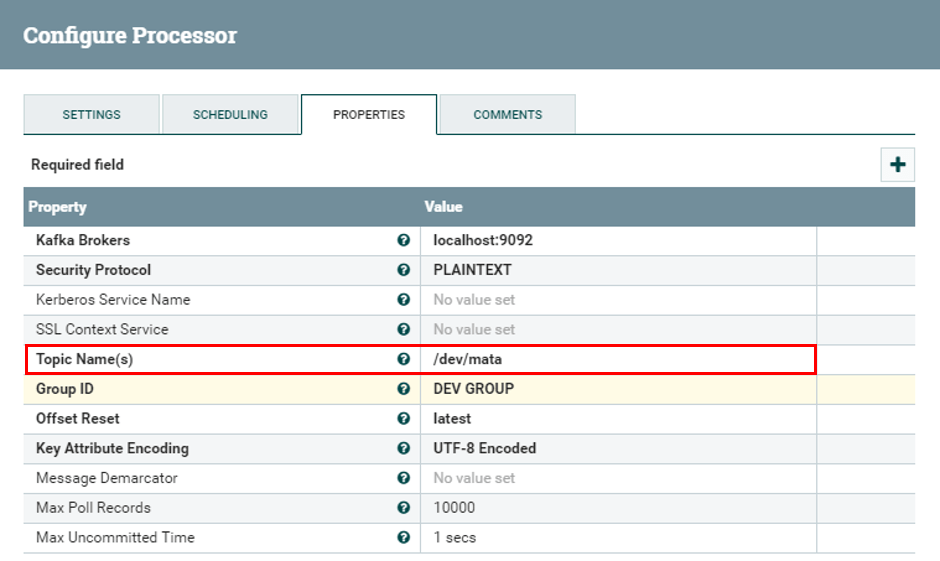
Processor properties after update
Thanks to NiFi REST API, we have been able to update the value of Kafka input topic name with a value for a pre-identified processor. This new value, along with the processor identifier, have been provided to this API call.
This very same procedure can be used to update any property fields as long as the processor identifier and the property name are known. Orchestrating all these updates for all the required variables of processors into a specialization application is a step further to specialization process automation and to making the NiFi flow ready for execution.
Note: be careful however, no consistency checks are run against the new value on NiFi end. Updating properties with inconsistent values can generate serious side-effects that may jeopardize NiFi service health.
Centralizing processors configuration for specialization
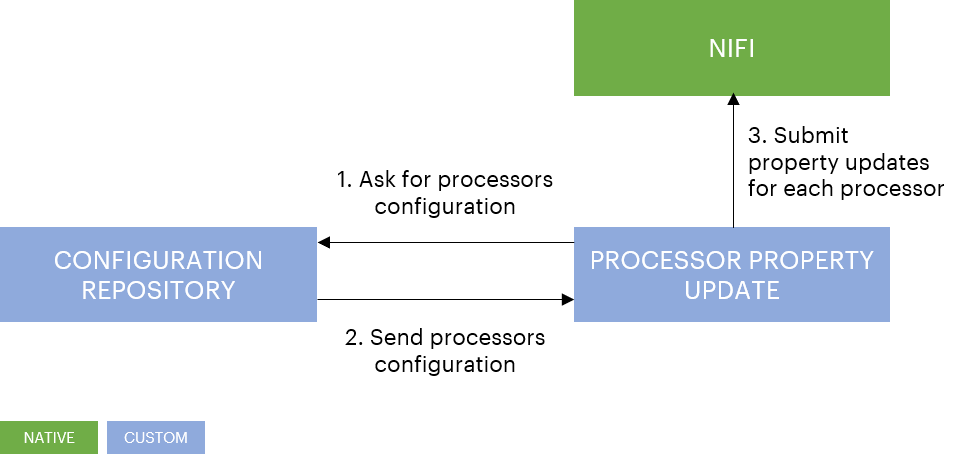
Going even further, the next step is about centralizing required information for specialization into a configuration repository that will act as a reference for the specialization application.
Here is what the structure of such a repository could look like:
| Information | Description | Value Example |
| Flow name | Functional name used to identify a NiFi flow. | INGEST_KAFKA_TO_HDFS |
| Flow identifier | Process group (flow) identifier given by NiFi. A flow in NiFi can be represented as a “Process Group” object, itself composed by one or several processors or sub process groups. This value is generally set by the instantiation stage that will be explained later. | 6be93ac7-1753-9755-a6ce-955a3ff30abe |
| Processors configuration | Values to be applied to processors of NiFi flow. | <JSON object> |
The diagram below depicts interactions between this configuration repository and the specialization application:
Processors configuration information can be modelled as a JSON object such as:
[{"KAFKA_CONSUMER": { "properties": { "topic": "/dev/mata", "group ID": "DEV" } } }, {"PUT_HDFS": { "properties": { "Directory": "/dev/mata" } } }]
In the JSON object, “KAFKA_CONSUMER” and “PUT_HDFS” are both processor names used to identify the processors to be updated. Note that processor names are not unique across NiFi or even within the same process group. Whereas processor names are defined by data engineers and so consistent across all environments where the NiFi flow is deployed, processor identifiers are generated by NiFi and may be different while passing from one environment to another.
Since NiFi REST API uses identifiers to uniquely designate NiFi objects, it is recommended to use processor names in the configuration repository and implement a mapping process in the specialization application that will translate the processor name into its identifier in the execution environment.
Translating a processor name into its identifier
Now we know how to update a processor property and that a configuration repository stores all processor properties to be specialized, we need to industrialize the property update process so that it can be applied to a whole set of identified processors within a process group. But before going further with this, it is important to understand how to handle processors identification since object identifiers in NiFi cannot be known in advance.
Object identifiers generation is actually rather simple: each object of any type in NiFi has got an identifier generated at creation. It is unique across the NiFi instance and this identifier allows to interact with NiFi objects through the REST API. Here is an example value of an identifier: 2f9fb50e-0169-1000-8610-b6b24f84ffd5**.**

Processor identifier viewed from NiFi UI
The process group (the NiFi flow) itself and each of its processors has got a unique identifier. So, how to retrieve easily the processor identifier we are about to update properties of?
A possible solution is about getting a processor identifier indirectly by using its name:
- Request processors configuration for a given NiFi flow known in the configuration repository
- Get processors configuration for this NiFi flow
- Use the REST API to request the list of processors within the NiFi flow (using the process group identifier from the configuration repository)
- Get the list of processors (name and identifier for each) within the NiFi flow
- Filter by processor name and get the corresponding process identifier
- Use REST API to specialize the processors using their respective identifier
The diagram below includes these interactions:

As a quick summary, such an approach would imply that:
- For a given process group, values of processor properties are stored and associated to a processor name, which is known in advance prior to the deployment (chosen by data engineers) contrary to the identifier (generated by NiFi)
- Each processor that is to be updated as part of the specialization process is named after a unique explicit name rather than the default name
Conclusion
Reaching the end of this post, we have been able to implement the specialization process of NiFi flows by using NiFi REST API and automate / massify it through a configuration repository. With the ability to specialize NiFi flows for a given usage, the next step is now to investigate instantiation process aiming at automating NiFi flows creation from a master / generic one. It will be introduced along with NiFi Registry within the part 2.
Orchestrating both specialization and instantiation will result in a key applicative component to accelerate and optimize the delivery of NiFi flows.