A maintainable Flex architecture
With the Flex framework, we are able to quickly develop a GUI that works, especially through the MXML language. Indeed, this language is an effective way to describe the interface with a few lines of code.
The problem occurs after the POC step is done, MXML code complexity increases, ActionScript code which implements event handlers, services calls or business logic creeps slowly into the MXML code. After some time, it becomes harder to figure out where data being displayed come from (ie. which code updated it ?), which code calls a service and from where the service arguments come from.
In this post, we will see some good practices which help in keeping a high level of maintainability for Flex applications.
Separation of concerns
The first step is to separate concerns of the application code. Why ? Because by using a unique method to collect data (eg. from a form), to prepare them for a remote service call, to call that service and to update the view, it's hardly testable thus finding a bug becomes very tricky.
We will start by the data model which can be isolated in separate classes. With this, data to be updated will be easier to identify. For example, when the result of a service call arrives, received data will be placed in this data model. Then, you no longer need to worry about data updates, they are unique and are gathered in a single place : the model. We can create, for example, a model per screen of the application.
Then, services calls can also be encapsulated in dedicated classes to avoid writing the same technical code 3 times in 3 different ways. It will allow to easily add common features to those services calls like authentication and/or exception handling. It will also be easier to replace these classes by mocks in our tests.
Separation of concerns is not a new practice and is part of many GUI design pattern like MVC, MVVM or MVP, but it never hurts to remind ourselves of it from time to time. With Flex, we can find many frameworks like Cairngorm, PureMVC or Mate (and many others) which will help you to implement separation of concerns and thus improve the maintainability and testability of your application. Just keep in mind that these frameworks are not mandatory to get a good maintainability. Code organization rules are enough if they are defined and shared among the developers of the project. They are only a mean to apply those rules.
Data propagation
The second step is to define how data spreads across the application to ease its debugging (ie. to better understand where data comes from and where it goes) and to ease reuse and testability of written Flex components.
The view of a Flex application is defined as a tree of components (MXML and ActionScript) like this :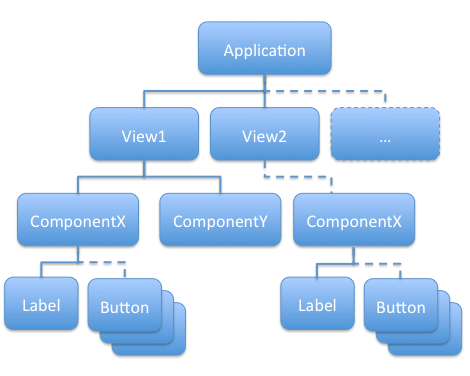
The tree nodes are containers components (*Box, Canvas, List, ...) containing other simple components (Label, Button, ...) or other containers. Even with a separation of concerns between models, services calls and the view, it's still possible for any components to be binded directly to the data model and to call services. Thus, these components cannot be reused in any other context : they depend on data with which they are binded to and cannot be used to display any other data. To remove this limitation, you should inject data which these components are working with. It is the same for services calls, if a component is to be reused in an other context (which needs to call another service or not call any service at all), we need to remove the dependency to any service call (ie. the component won't be aware a service call is done when some event occurs).
A solution to these 2 problems of dependency is to push them to the parent component :). This parent component can then, either throw it back again to its parent (and add some information if needed), or be dependent to the data model and any services. Actually, at a certain level in the components hierarchy (by ascending it), it's not possible to talk about reusability (this could be at the root component level) and having dependencies there is not a problem anymore.
We then get a data propagation which looks like this : 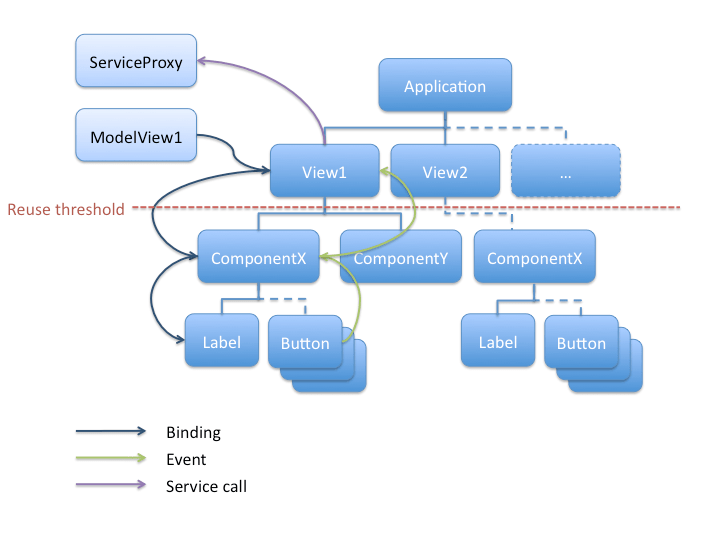
Data goes down the hierarchy via data binding (i.e. a component binds its attributes to its child components attributes) :
In View1.mxml :
<Componentx title="{modelView1.viewTitle}" />
In ComponentX.mxml :
<mx:Label text="{title}" />
And data goes up through events dispatched by the lowest components in the hierarchy. These events are redispatched (with code or by using the bubbling mechanism which make them automatically ascend the hierarchy of components) or transformed into an event of higher level by parent components.
In ComponentX.mxml :
<mx:Button click="dispatchEvent(new AddItemEvent(this.item))" />
In View1.mxml :
<Componentx addItem="serviceProxy.addItem(event.item)" />
This operation allows you to define a clear API of developed components :
- Exposed attributes receive data as an input
- Data goes out via events dispatched by the component
It then eases the testability of developed components.
Conclusion
With these 2 principles applied to a Flex application, it should resist better to code size growth and be longer maintainable. However, we must keep in mind that these principles might not be sufficient and new ones should be elaborated with the context of the project in mind to ease code readability in its whole.