A Journey To build a Business-Driven Data Science Capability
Introduction
We live in a world in which data is becoming a key business asset, playing an increasingly central role in the success of a growing number of companies. Data and the ability to transform data into business will become critical in all sectors in the coming years. A good mastery of data and its exploitation can be an important competitive advantage. This means that companies need to equip themselves with the technological and human resources to develop a skill set capable of leveraging data, applying analytical approaches and implementing new dedicated technologies.
Why a Data Science Capability?
Firms are in the process of setting up data-driven capabilities both internally (focus on the enterprise) and externally (focus on customers). Businesses will have to go through a massive digital transformation, including cultural and operational change. This is due to the fact that many companies still apply guidelines from the previous century while using 2020's technologies. One way to update some guidelines on AI projects consists in building a Data Science capability that can help them to make this digital transformation a success.
Business Stakes & Needs
Currently, companies are aware of the importance of including AI in their processes. The stakes are increasing the financial Return On Investment, reducing risks or saving operational time. This awareness is translated in several ways: either by adding an AI vision in the definition of the top management's strategic roadmap to increase market share, or by developing solutions based on AI in the search for disruptive innovation and information exploitation providing a competitive advantage, or by increasing human capabilities by offering decision support solutions or products.
Despite a willingness to transform and add AI elements to current processes, companies may encounter difficulties that can minimize the potential associated AI value. These difficulties can be found at every organizational level.
- At the top management level, there may be a lack of conviction at the sponsor level or a lack of awareness of the opportunities associated with AI, resulting in a lack of a clear global strategy for the deployment of AI-based tools and solutions.
- At the middle management level, there may be a willingness to develop AI solutions but, very often, a lack of structure and organization to deploy into production Proof of Concepts (POC) resulting in the multiplication of unused POCs and therefore a loss of investment. In addition, a lack of communication between managers can lead to redundant investment for the same project in different teams and geographies within an organization.
- At the executive team level, the absence of talent or the possibility to develop this talent can also cause a lack of capacity to carry out projects that are very promising and rich in learning.
From a global perspective, there are major difficulties due to a lack of conviction about the possibilities offered by a data driven company because of a “guts-driven” habit or, ironic but true, a history of investing in technology in the past that was too expensive to allow new investment in new technologies.
The introduction of a Business-Driven Data Science Capability can be a solution allowing an easy transition in the implementation of AI technologies at a lower cost and offering an approach facilitating the transformation towards a data driven company.
What is a Business-Driven Data Science Capability (BDDSC)?
A data science capability is an ecosystem that blends the data, skills, technologies, techniques, culture and processes needed to facilitate the integration of AI within an organization. The objectives of this capability are multiple and concern different themes around data, business and industrialization.
From a Data Aspect
Data is everywhere and must be handled rigorously and precisely in the same way as the development of a product or an offer. This is even more true while digitalization takes ever greater hold resulting in the emergence of devices/services that generate more and more data. In addition, these data can be leveraged by AI use cases to generate new business insights that can be used by companies to better control their activities and thus generate new data.
This growth offers new perspectives, insights and new business action levers for all organizations. In fact, becoming data-driven is the new table-stakes for enterprise success (cf. Accenture and BCG publications).
This is the reason why the capability must possess and share a global data lineage of the different data existing within the company. The lineage allows to locate all datasets (and their associated data dictionary) and their usages (if possible) within an organization and answers questions ranging from the origin of data to its journey through the organization.
Today, most business enterprises are using various types of data lineage software which also includes ETL (Extract, Transform, Load).) operations to clean and prepare data, therefore to get leverageable data. Having a clear vision of the Data within a company is essential because by knowing and mixing data from several entities, it is possible to create unsuspected business value. However, data lineage processes may be time consuming and therefore slow down the value generation process, particularly in constrained time environments.
An alternative consists in identifying use cases first and assessing the related data acquisition complexity. This alternative makes it possible to advance slowly but surely in the digital transformation while identifying the obstacles and needs. This identification makes it possible to define the necessary projects to be implemented to allow the organization to evolve at its own pace according to the available resources and thus establish a roadmap of the next actions to be performed. This approach is usually preferred but does not dispense the data lineage process during the use case realization time.
From a Business aspect
The BDDSC role consists in acculturating and sensitizing the business to the fact that AI is driving the new Industrial Revolution. AI adoption is growing faster than many had predicted. Research from a recent Global AI Survey commissioned by IBM indicates that 34 percent of businesses surveyed across the U.S., Europe and China have adopted AI.
Therefore, the rise in AI adoption to the surge of new tools and services designed to help lower the barriers to AI entry. Those include new ways to fight data complexity, improve data integration and management and ensure privacy.
To facilitate Business adoption, data scientists must master the vocabulary of the business as well as have an understanding of their challenges. This may lead to better identifying opportunities (resolve pain points or increase gain points) in which AI can have a definitive and irrevocable value.
From an industrialization aspect
The capability requires to work with strong IT professionals, having an experience of all existing barriers, making the industrialization of Data Science difficult.
These difficulties may come from a lack of clear Business use cases, a lack of profitable Business goals and last but not least a lack of skills in the company as explained by Hervé Potelle & Laurent Leblond in Management & Data Science.
To be able to handle these difficulties, and it is quite tough, it requires the BDDSC to have a good vision of dedicated technologies, to be close to Business teams and to acquire the appropriate skills to ensure the success of an industrialization.
One Vision: Mandate & Objectives
First of all, a Business-Driven Data Science Capability allows to develop a human-centric, data-led and technology-driven approach which is one of the keys to apply artificial intelligence and thus to get closer, step by step, to an intelligent enterprise. The main activities of a BDDSC can be decomposed into 5 major topics, all of which are equally important to each other:
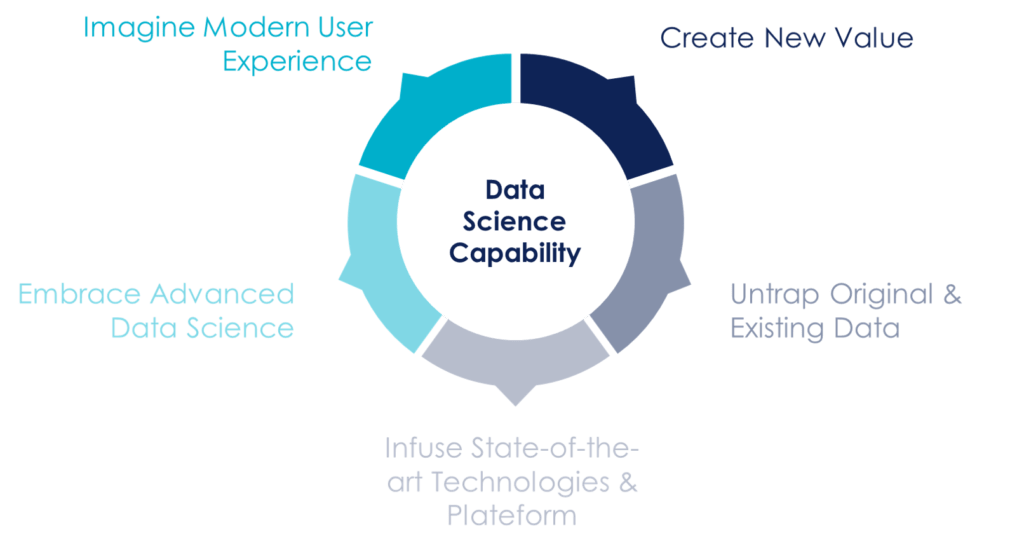
5 main activities covered by a Data Science Capability
Create New Value
By leveraging on existing Data
A first value creator factor is the Data itself, which can be considered as an asset and monetized. These new use cases bring value by expanding a company’s portfolio of offerings. This can include the rather rare case of straightforward selling of the data itself, selling of insights gleaned from data, offering new products or delivering analytics as a service.
By identifying disruptive AI use cases
Use case Identification.
Before starting any Data Science project able to unearth these insights, it is crucial to define the expected impact the use case should generate. Niko Mohr and Holger Hürtgen from McKinsey Digital provides some valuable insights about how to achieve Business impact with Data.
To illustrate with a non-exhaustive list of examples :
- for growth impact, use cases may focus on pricing strategies, churn prevention, cross- and upselling, and promotion optimization among many others.
- For internal process optimization, predictive maintenance, supply chain optimization, and fraud prevention can be cited as use cases example.
To manage all these emerging new use cases, it is crucial to build a dedicated project portfolio with prioritization criteria.
Complexity Estimation
Another aspect to consider consists in assessing the complexity of a use case. Several questions must be addressed to be able to assess this difficulty:
- Are the required data available?
- Are the expected outcomes well-defined?
- Do we possess the required skills to be able to crack down the use case associated business problem?
- Are the algorithms able to scale up and to solve the problem in a humanly reasonable time?
- Are the Business Teams committed to the project?
- Is there an industrialization platform or process?
- Are the IT teams, responsible to look for the run of the use case, identified?
- Is there one team with devOps experience illustrated by Octo responsible for developing the POC and deploying it into production?
If the answer of one of these questions is no, it might be interesting to have a deeper look and to investigate how to transform the "no" into a yes. One way to transform “no” answers to “yes” answers consists in building an agile culture of experimentation as explained by Octo in his publication to help the organization to evolve.
Projecting value from a well-identified use case is necessary but not enough. More aspects have to be deepened such as the ability to prototype and industrialize the products and services resulting from the use cases.
Transforming insights to actions and thus reaping the expected benefits is the best value that can be realized but it requires skills and technologies. These are the required means to make the Business-driven Data Science Capability operational, efficient and capable of achieving the objectives set by the business lines
Untrap Original & Existing Data
To untrap New & Existing Data, it is required to build a Data Supply Chain able to handle either internal data or external Data. Before defining the Data Supply Chain, let us have a deeper look about internal and external Data.
Internal Data
Internal Data is referred to as all Data located within an organization. It can be generated by sensors, various KPI dashboards, logs originated from various tables, data mart or data lakes. As mentioned earlier, a Data Lineage composed by various data dictionaries able to explain data and to indicate the data security level, a list of the corresponding Data Owners (people who possess the Data) and the location of the Data, should be provided to the BDDSC.
In an ideal world, this should be easy to be obtained but in the real world, it is not always the case. Several major difficulties can be found such as either some ignorance of existing data due to management siloes, or a bad definition of data sensitivity level making sensible data accessible to all, or data stored on old databases making any data extractions complicated….
The goal of a BDDSC is not to resolve these problems, but it must be aware of it.
Moreover, a BDDSC is not a data provider but should know the lineage of as much data as possible within the organization in order to be able to respond to the data-driven needs of the business. It must also know the data owners and the level of security associated with sensitive data and respect the procedures around the handling of this data.
External Data
External Data is referred to as all Data that is external to the company. They can be acquired either through partnerships with data providers or through open data.
Some difficulties lie in identifying relevant data corresponding to existing or hypothetical future needs and also in the data cleaning/ingestion process to set up to deal with data quality problems. External data should be explored on purpose but never with a perspective of a possible undefined us .It is important for the BDDSC to know the major data providers, to have knowledge of data that are exploitable in open Data and, if the need arises, to collect the available data for future purposes.
Data Supply Chain
A modern Data supply chain refers to the lifecycle process of Data All actions from its origin to its destruction through different steps such as storage, cleaning, use or transformation to name a few.
The performance of machine learning models are highly correlated to data quality and thus requires a clean and efficient Data supply chain to get the right data. Despite all the innovative aspects of this supply chain, it retains the same weaknesses of a classic supply chain, as mentioned by Katie Lazell-Fairman in "Learning from Machines: The Data Supply Chain", especially for external data, and requires redesigns over time to meet sustainability and performance needs or most simply to upgrade the associated technology.
To build a reliable data supply chain, several unavoidable steps have to be performed :
- Identify where the data comes from and define the sourcing strategy. Leandro DalleMille and Thomas H. Davenport in Harvard Business Review shows insights about how to balance an offensive et defensive strategy.
- Perform several quality checks with respect to quality principles such as accuracy, completeness, consistency, timeliness, validity, and uniqueness as explained by Datatrim.
- Generate a data pipeline to ensure that the right data preparation is performed on the suitable. Alan Marazzi shows how to build a data pipeline from scratch and provide some valuable lessons.
Infuse State-Of-The-Art Technologies & Platform
The Business-drive Data Science Capability must be up to date with the latest technologies and thus have a fast follower position in terms of R&D.
It must also work with solutions that can easily be integrated into the organization's existing technology architecture or propose a new architecture if the organization is too technologically backward.
To define what technology fits the best to a data scientist is not as simple as writing down python code. The job of a Data Scientist has to be split into several aspects such as: programming tools, Data Analysis, Data Visualization, Machine Learning, Data Engineering among many others.
In addition, each of these fields possess their associated and non-exhaustive technologies (tools or libraries) that are constantly evolving. There is no best of breed that can be cited due to the fact that most of these technologies are quite young and are still in development. To stay alert about the latest technological evolution, various authors communicate about the latest trends such as:
- Matt Turck updates regularly an AI technology landscape,
- Simran Kaur Arora on Hackr.io about Data Science tools,
- Kaggle also produces surveys to ask data scientists about the tools they used.
The technological choice has to be performed by the BDDSC Data Scientists depending on their needs and their skills. However, a regular technological watch has to be performed continuously in case some product may become more mature than others.
Embrace advanced Data Science
A Data Science Methodology is an iterative process that follows a step-by-step sequence providing a clear project structure. By iterative process, it means a continuous cycle around the model construction. It gets continuously trained, evaluated and deployed. To improve the model relevancy, the end user has to provide feedback to the Data Scientist to ensure the identification of the right data, the right processes and the right KPIs to monitor.
The Data Science methodology is composed by 4 main topics: Scoping Definition which allows to scope the project and to assess its impact and complexity, Data which handles data acquisition, quality and preprocessing, Model which focus on how to train a model until it fits Business expectations and Industrialization which consists in deploying the model.
This methodology is quite classical and can be found with some variations in the literature like GeeksForGeeks, John Rollins from IBM Big Data & Analytics Hub, Lawrence Alaso Krukrubo also published some valuable insights on Towards AI among many others.
Scoping Definition
Scoping definition starts with understanding the business problem and thus build an issue tree displaying all associated subproblems. Each issue will be analyzed to keep only those that can be answered with AI. To identify the best approach to solve the issue, an hypothesis tree is build using a Mutual Exclusive and Collective Exhaustive (MECE) policy. This method will intuitively lead to a resolution approach that can then be evaluated in terms of feasibility and temporality.
To lower the risk of failure of the project, success metrics are defined during the scoping phase and will be regularly monitored during the project realization. In addition, to ensure that the project is meeting end-user expectation, it is required to apply agile methodologies and thus to organize weekly meetings with all important stakeholders of the project.
Data
Data is key to the success of Data Science realization.
The major challenges rely in identifying the necessary data content, formats, sources and to initiate the data collection process. To facilitate this identification, it is key to identify the business experts likely to facilitate the understanding of the data. As a trivial way of assessing the informative power of the data, they must be able to answer questions related to the subject under analysis such as : ‘what’, ‘where’, ‘when’, ‘why’, ‘who’ (also called the 5 W by towardsdatascience) and ‘how’.
Once the data are identified, feature engineering actions such as derivation of existing variables to create new data are performed on variables to identify relevant and meaningful insights to be validated or not by Business Teams, which must be continually informed of the progress of the analyses.
Scientific approaches such as descriptive statistics and visualization can be applied to the data set to assess the content, quality, and initial insights. Exploring and understanding Data usually takes 80% of overall project time at the time of the first POCs.
Model
The construction of the model is performed in several major steps: the selection of the appropriate mathematical/algorithmic model, the selection of the model evaluation metrics and the consideration of feedback from end-users which allows an iterative improvement of the model's performance.
A large number of publications (like Xiuwenbo Wang on Kaggle or other publications cited earlier in this article) already deal with this topic and it is for this reason that we will not go into technical details.
Model Selection
Model selection focuses on developing models that are either descriptive or predictive. A predictive model tries to either predict a yes/no answer or a finite value based on the input variables.
The data scientist will use a training set which is composed of historical data in which the outcomes are already known. The training set acts like a gauge to determine if the model needs to be calibrated.
To identify the most suitable algorithm, it is required to test several Machine Learning algorithms families. Existing libraries (scikit-learn, panda, pytorch among many others at least equally important) allow to quickly test a large volume of model while taking into account the complexities of variable selection, hyperparameter and other variable optimization constraints.
To be able to identify the best model for the current data, the approach has to be agile and highly iterative until the model converges into satisfactory results.
Model Evaluation
Model evaluation is usually based on some technical KPIs (confusion matrix, distance between realistic and predicted outcomes, segment homogeneity computation, ROC curves, ...).
Evaluation allows the model assessment and allows to verify if the Business problem is fully and appropriately addressed.
To be able to verify the quality, a testing set, also historical data but not known by the model is used. To assess the quality, a confusion matrix is used to rate classification problems. To assess the regression problem, the difference between the predicted value and the real value is computed using several various metrics. An interesting and exploitable list can be found on scikit-learn.
End-User Feedbacks
End Users Feedbacks are necessary for Data Scientists to evaluate the model’s quality and check whether it addresses the business problem fully and appropriately because they are the best to provide feedback on the consistency of the results provided by the model.
They can detect errors, measure its efficiency and share insights crucial for features engineering.
They also can define when the performance of the model is enough for its industrialization.
In order to facilitate feedback, an agile interaction mode with regular meetings with the business community allows to quickly identify ways of improving the model, thus enabling it to achieve performance scores sufficient to meet expectations.
Last but not least, including end-users in the model feedback process also makes it easier to build a tool that perfectly meets their needs and facilitates the associated change management.
Industrialization
Deployment on production is performed when the model has been approved by business stakeholders, while keeping the sponsors informed of the progress of the project to avoid any negative tunnel effects. Deploying a model generally requires specific skills, dedicated technologies and a group of people responsible for monitoring the applications in production.
The industrialization of a Data Science project is, at the time of writing this article, a subject that is both innovative and well-known, if not outdated.
Innovative because the production of Machine Learning models is a recent phenomenon and raises new questions that must be answered with new technologies dedicated to it. This phase is tricky because the production environments at the time of writing this article are not necessarily all dedicated to Data Science, and the implementation must be performed step by step to evaluate the performance of the model and monitor its behavior in a production environment.
well-known because the deployment (Build) and maintenance (Run) processes are already mastered by IT teams for other types of projects.
It is this double state that makes the industrialization of a Data Science project complicated.
When industrializing Data Science projects, we will mention two of the important aspects that must absolutely be taken into account: performance monitoring and end-user feedbacks collection
Model Monitoring
Model Monitoring is crucial to maintain the model operational despite any changes in Data nature or Data interpretation or to detect unexpected context. To be able detect any changes, two types of model monitoring exists as explained by Om Deshmukh in Anlytics Vidhya,: proactive monitoring (test of various data samples which may lead to unexpected behaviors) or reactive monitoring (identification of root causes that led to the bug caught by the monitor).
To ensure efficient monitoring, it is important to define relevant KPIs (Model performance, Data Distribution alternatives, …) and to set up sensors within the Data process.
End User Feedbacks Collection
End User Feedbacks maximizes the project's chances of success as explained by Margaret M. Burnett and comes by collecting results from the model in production. The organization gets feedback on the model’s performance and observes the impact in a real-world environment. Analyzing this feedback enables the data scientist to refine/improve the model, increasing its accuracy, correcting any suspicious behavior or adding any new features.
There is a lot to be written about the best practices for the production of Data Science projects. However, this is not the purpose of this article and further details will not be covered here.
Imagine Modern User Experience
This part is one of the most vital aspects that led to the success of the Data Science project and should be performed while scoping the use case. Much of the friction occurs right at the level where the user and the system meet (in other words, the Dashboard). User Experience starts with a good knowledge of users and a clear understanding of their objectives. If the user experience is not designed to answer user’s needs and objectives, the product outcomes will not be adopted by the end-users and all the work done will have been for naught due to a lack of users.
Nick Kelly define User Experience as a secret ingredient to enhance Analytics success. To get the most suitable user experience, designers are performing Design Thinking actions, Persona definition process described by Jeremie Chaine, or even Theater as explained by Laure Constantinesco to understand end-user's objectives and agile methodologies to ensure fulfilling expectations throughout the duration of the project. Therefore, it is important to equip Business / Functional leads with new tools, to delight end users with personalized journeys and to be able to inspire employees to innovate and co-create the new activity.
To ensure the adoption of the product to any user, it is crucial to identify the UX issues that can be solved with UX expertise coupled with data-driven designs which aims to optimize the end-user design journey which can be defined by an article from Kate Moran and Kathryn Whitenton in "Analytics and User Experience"
To pass all challenges, an agile methodology is applied meaning initiate a first design, defining success KPIs to track before and after design optimization. Moreover A/B and multivariate tests as explained by Antoine Pezé are helpful to improve UX experience with different designs and content variations. Once the data-driven design is set up, it is possible to drive new types of research by creating user surveys to get insights about the product itself and thus to identify optimization opportunities. Tom Hall in UX Planet provides helpful recommendation for creating user surveys.
Conclusion
In this article, we have explained why a Business-driven Data Science Capability can bring value in digital transformation within an organization . We have also described the elements that constitute it, its core business and explained why it must remain close to the front and back office.
The implementation of a Business-Driven Data Science Capability is not obvious and requires taking up many challenges at all levels (technological, human, business and organizational).
If this article has interested you, if you would like to share your own experiences or if you would like to have more information on certain aspects covered in this article, please do not hesitate to contact us !