7 choses qu'un développeur doit connaître sur les bases de données
Ceci est la version française d'un article publié en anglais en janvier 2025 sur ce même blog.
Cet article est dédié à Michel Vayssade. Il y a quinze ans de cela, vos cours combinaient les abstractions de haut-niveau et les préoccupations quotidiennes, dans votre style exigeant et humble. Quelle joie de récolter à nouveau les bénéfices de ceux-ci en les appliquant aux bases de données !
Merci à tous les relecteurs: Mathieu Le Morvan - Gabriel Adgeg (OCTO), Anne-Marie Esteves et Guillaume Lelarge (Dalibo).
TL;DR
Développeurs full stack et backend, il y a de grandes chances que vous ne connaissiez pas ce qui suit - et que cela puisse un jour vous sauver la mise:
- la vue pg_stat_activity contient les requêtes en cours d’exécution, pg_stat_statements contient celles qui ont été exécutées - toutes les requêtes pouvant être tracées dans un fichier;
- utilisez un pool de connexion, et assurez-vous lors du scaling côté client que vous n'atteignez pas max_connections;
- activez default_transaction_read_only et statement_timeout lorsque vous vous connectez en production avec un client SQL;
- connectez-vous toujours, même ponctuellement, avec un client SQL;
- si pg_stat_activity mentionne des requêtes qui attendent un verrou, consultez les vues de verrou pour savoir qui le détient;
- lorsqu’une requête SQL a débuté sur le serveur, elle sera exécutée jusqu’à la fin - peu importe que le client se soit déconnecté;
- pour interrompre une requête, utilisez pg_terminate_backend - et préparez-vous à un AUTOVACUUM.
Pourquoi devrais-je lire cet article ?
99% du temps, les développeurs n’ont pas à se poser de questions en matière de bases de données. Du moment qu’ils appliquent ce qu’ils ont appris en formation initiale (un modèle de données solide - et versionné, l’intégrité des données grâce aux transactions, et quelques index pour la performance), tout se passe bien. La base de données est en effet une boîte noire qui fonctionne bien la plupart du temps. Je suis un développeur web, mais je me suis intéressé au fonctionnement interne des bases de données par curiosité: cela me procurait les mêmes sensations grisantes que dans les cours de programmation système Unix/Linux.
Au fil des ans, j’ai réalisé que certaines choses que j’avais apprises pouvaient être utiles à tous; autrement dit, ignorer ces points pouvait se révéler douloureux en production. Plutôt que d’attendre qu’un problème se produise et le résoudre moi-même, je préfère aujourd’hui partager ces connaissances avec vous.
Ma première idée était de publier une “trousse de premier secours”, mais sous l’influence de Tom Kyte (voir l’introduction de son livre "Effective Oracle by Design"), j’ai inclus des connaissances préventives, notamment concernant la concurrence. Un développeur doit savoir tant de choses (au moins 97) que je n’ai gardé que les 7 idées les plus utiles. Pour les mêmes raisons, je ne couvre que PostgreSQL, la base de données relationnelle la plus répandue à ce jour.
Médecine préventive
Sachez ce qui se passe dans votre base de données
TL;DR: la vue pg_stat_activity contient les requêtes en cours d’exécution, pg_stat_statements contient celles qui ont été exécutées - toutes les requêtes pouvant être tracées dans un fichier;
Avant tout - au plus tard lors de la première mise en production : rendez votre base de données observable.
La question n’est pas de savoir si vous devez le faire, mais comment le faire.
Christian Antognini, Troubleshooting Oracle Performance
Lorsque des problèmes se produiront en production (si ce n’est pas aujourd’hui, ce sera demain), il sera trop tard pour vous rendre compte que vous ne savez pas ce qui se passe. Dès le début du projet, dans le walking skeleton - c’est-à-dire la première fois où le code est déployé sur un environnement distant - vous devez être capable de savoir quelles requêtes sont en cours d’exécution sur la base de données.
Il existe une vue native qui vous donnera cette information : pg_stat_activity. Elle mentionne que tel utilisateur a demandé l’exécution de telle requête sur telle base de données, ainsi que son statut: attend-elle la lecture de données sur le disque, ou qu’un verrou lui soit attribué ?
Simplifiez-vous la vie:
- identifiez le composant à l’origine de la requête en alimentant application_name lors de la connexion, par exemple avec le nom du conteneur backend ou de la brique logicielle;
- affichez le texte complet de la requête en augmentant track_activity_query_size.
Une fois la configuration effectuée et les vues facilement consultables (les PaaS fournissent la plupart du temps une IHM web dédiée), vous aurez également besoin de savoir ce qui s’est passé à un moment précis, par exemple vendredi dernier, lorsque les utilisateurs ont remonté que le temps de réponse s’était dégradé. Faites comme avec vos logs de routeur HTTP: envoyez une trace par requête dans la sortie standard, prise en charge par le collecteur de logs. Pour cela, vous pouvez utiliser la fonctionnalité native, qui trace les requêtes une fois achevées. Vous pouvez l’activer sélectivement, par exemple pour les requêtes qui durent plus de 10 secondes, en utilisant log_min_duration_statement. Je vous conseille de commencer par tracer toutes les requêtes; puis modifier la durée de rétention et le seuil de log pour obtenir un résultat optimal. La plupart des plateformes sont équipées d’un monitoring système - CPU, RAM et I/O (stockage et réseau). Si vous rassemblez les logs de requêtes et les métriques système sur une même plateforme de monitoring, vous serez parés lorsque quelque chose se produira en production.
L’étape suivante est de prendre du recul avec un outil qui vous permettra de comprendre ce qui se passe entre l’application et la base de données: un APM. Si la marche est trop haute, vous pouvez collecter facilement des statistiques en utilisant l’extension pg_stat_statements. Sachez qu’elle n’est pas activée par défaut, car elle ajoute un peu d’overhead, mais celui-ci est négligeable la plupart du temps.
Occupez-vous de la concurrence
TL;DR: utilisez un pool de connexion, et assurez-vous lors du scaling côté client que vous n'atteignez pas max_connections
Vous pensez peut-être que les discussions qui concernent la concurrence sont réservées à ceux qui créent des langages de programmation, aux architectes - bref, quelque chose dont vous n’avez pas à vous soucier : quelqu’un d’autre que vous l’a fait au début du projet. Et bien, si vous voulez tirer le meilleur parti des ressources matérielles qui ont été attribuées à votre application, quelques vérifications s’imposent.
Nous allons considérer la situation la plus complexe: déployer une API REST sur une plateforme offrant du scaling vertical automatique, utilisant une base de données. La difficulté réside dans le fait de fournir le meilleur niveau de service à tous les clients logiciels (conteneurs applicatifs), dont le nombre change au fur et à mesure du temps.
Pour cela, il faudra considérer deux niveaux :
- à l’intérieur de la base de données:
- minimiser la création de connexions client : chaque connexion nécessite une création de processus sur l’OS, qui est une opération coûteuse;
- pour les requêtes, utiliser au mieux les ressources limitées : CPU et I/O;
- à l’extérieur de la base de données:
- minimiser les aller-retour réseau nécessaires à l’ouverture de connexions client;
- assurer un niveau de service: servir plusieurs clients, efficacement et équitablement.
Configurer le nombre maximum de connexions
Le nombre maximal de connexions client est imposé par la base de données et configurable.
Pour déterminer quel est le nombre optimal de connexions optimal, la théorie de la concurrence fournit une réponse simple, bien que contre-intuitive. Elle dit qu’il ne faut pas considérer le nombre d’utilisateurs, mais les capacités matérielles de votre base de données : au moins requête en cours de traitement, au plus rapide le temps de traitement d’une requête, au plus rapide le temps de traitement moyen de toutes les requêtes.
C’est aussi contre-intuitif que l’approche Kanban/Lean: un WIP limit bas accélère le débit d’un système. Pour en savoir plus, ne commencez pas la théorie mathématique des files d’attente, mais lisez cet article qui inclut une démonstration en vidéo sur la base de données Oracle.
Entendons-nous bien: si vous voulez vous assurer que le temps de réponse soit satisfaisant, il faut que les capacités matérielles de la base de données soient adaptées à la charge et aux usages. Une application web avec beaucoup d’utilisateurs, manipulant peu de données, lecture et écriture mêlées, n’a pas les mêmes besoins d’une plateforme décisionnelle avec peu d'utilisateurs, manipulant beaucoup de données en lecture. Mon point est que, même avec des capacités suffisantes, une mauvaise configuration du nombre de connexions fera augmenter le temps de réponse.
Ce n’est pas le rôle du développeur de calculer ou de modifier le nombre de connexions, c’est celui du DBA / de l’architecte / du DBaaS. Par contre, assurez-vous que quelqu’un l’ait fait, avant la première mise en service et après chaque modification de matériel.
Utilisez un pool de connection
Si vous ouvrez une connexion à chaque nouvelle requête, alors votre requête peut échouer. En effet, lorsque le nombre maximum de connexions est atteint sur la base de données, toute nouvelle tentative de connexion depuis votre backend échouera. De plus, comme l’ouverture d’une connexion entre un client et un serveur est coûteuse, vous souhaitez ouvrir le moins de connexions possibles.
En séparant la notion de requête et de connexion, vous pouvez vous en sortir : sur une même connexion, effectuez plusieurs requêtes. Il y a plusieurs options d’implémentation, la plus répandue étant un pool de connexion côté client, par exemple sur un backend REST, via une librairie éprouvée. Configurez le nombre minimal de connexions ouvertes au démarrage, le nombre maximal (voir section suivante) et le timeout. Pour vous faciliter la vie, respectez le 12-factor app et passez cette configuration en variable d’environnement.
Configurez le pool en fonction du scaling
Si vous utilisez une seule instance de backend, le nombre maximal de connexions du pool sera celui de la base de données. Enfin presque. Comme vous utilisez des systèmes de monitoring, qui utilisent des connexions SQL, et que vous aurez vous aussi un jour besoin de vous connecter à fin de diagnostic, incluez-les dans le compte : client_pool_max_connexions = database_max_connections - maintenance_connexions. Je vous encourage d’ailleurs à utiliser reserved_connexions pour garantir un accès aux connexions non applicatives.
Si vous utilisez le zero-downtime deployment, il y aura à un moment deux instances actives de votre backend : réduisez d’autant le nombre de connexions du pool.
client_pool_max_connexions = (database_max_connections - maintenance_connexions) / 2
Si vous utilisez plusieurs instances de backend, sans scaling automatique, répartissez les connexions applicatives entre tous les conteneurs : client_pool_max_connexions = (database_max_connections - maintenance_connexions) / client_count.
Avec un scaling horizontal automatique, la méthode la plus répandue et la plus simple est de considérer que tous les conteneurs sont toujours actifs, comme dans le cas précédent. En réalité, tous les conteneurs ne sont pas actifs, et la solution est sous-optimale : des connexions ne sont pas utilisées, et chaque conteneur pourrait ouvrir plus de connexions sans être rejeté par la base de données. En théorie, à l’arrêt d’un conteneur, il est possible de signaler aux conteneurs actifs que de nouvelles connexions sont disponibles. Mais que faire si ensuite un conteneur démarre alors que toutes les connexions sont déjà prises ? Avant de vous engager dans cette voie, vérifiez que les conteneurs utilisent réellement toutes les connexions du pool et que les requêtes SQL sont le facteur limitant des backend.
Conduisez en sécurité
TL;DR: activez default_transaction_read_only et statement_timeout lorsque vous vous connectez en production avec un client SQL
Lorsqu’un développeur se connecte à un environnement distant avec un client de base de données, par exemple psql, il y a un risque - surtout en production. Si vous collez une requête complexe dans ce que vous pensiez être votre environnement local, mais qui était en fait celui distant, vous pourrez ralentir l’ensemble du service. Je n’évoque pas le risque de perdre des données en production en exécutant un UPDATE, car vous n’avez pas le droit d’écriture, n’est-ce pas ? Ah, vous avez ces droits d’écriture “au cas où” ? Et votre chef a dit “un bon développeur fait attention à ce qu’il fait" ?
ne faites que de la lecture
Si vous ne pouvez pas obtenir de compte en lecture seule pour l’instant, vous pouvez au moins activer la lecture seule sur votre session.
SET default_transaction_read_only = ON;
Mieux, faites-le automatiquement avec un hook de pré-connexion, par exemple un fichier .psqlrc.
n’accaparez pas les ressources
Une fois votre session en lecture seule, vous ne pouvez pas corrompre des données - mais vous pouvez toujours dégrader le niveau de service en vous accaparant des ressources. L’accaparement le plus évident est celui des ressources matérielles: si votre requête met plus d’une minute à s’exécuter, il y a de fortes chances qu’elle occupe du CPU et de l’I/O. Sur votre session, activez donc le timeout de requête : si la requête met plus de temps que celui configuré (ici 1 minute), elle sera interrompue.
SET statement_timeout = 60000;
n’empêchez pas l’accès
L’accaparement qui suit concerne non pas pas une ressource matérielle, mais une ressource de données, à savoir une table. Pour chaque table concernée par votre requête, un verrou doit être octroyé - verrou qui sera probablement attendu par une autre session, par exemple le déploiement applicatif qui met à jour le schéma de base de données. Et oui. Cela ne pose généralement pas de problème si vous avez configuré le timeout de requête.
Sauf si. Sauf si vous avez démarré une transaction et ne l’avez pas conclue : les locks ne sont pas libérés à la fin de la requête, ils sont libérés à la fin de la transaction. Prudence donc dès que vous démarrez une transaction multi-requêtes avec BEGIN.
BEGIN;
SELECT * FROM table_one (..)
UPDATE table_two (..)
– les verrous sur table_one et table_two sont toujours détenus par ma session
UPDATE table_three (..)
ROLLBACK;
– tous les verrous acquis depuis BEGIN sont libérés
apprenez à faire marche arrière
De temps en temps, pour résoudre un problème, vous avez besoin de droits en écriture pour le reproduire dans le seul environnement où se trouve le jeu de données lié. Enfin, vous ne voulez pas vraiment modifier les données en production. Vous avez prévu de démarrer une transaction, d’effectuer des actions de type INSERT/UPDATE/DELETE pour comprendre ce qui se passe, puis d’annuler cette transaction, comme si rien ne s’était jamais passé.
En effet, rien ne s’est passé du point de vue des autres transactions. Mais il s’est bien passé quelque chose dans les fichiers de données, sur le stockage: tous les changements effectués par votre transaction sont bien là - même si personne ne peut les voir. J’aimerais vous en dire plus, mais le temps est compté.
En quoi cela nous concerne-t-il ? Ces enregistrements sont inutiles, car ils ne sont plus accessibles. En conséquence, ils utilisent de la place qui pourrait être libérée - et elle le sera, automatiquement, par la base de données. Le processus en charge, appelé VACUUM, utilise lui-même des ressources (CPU et I/O). Dans le cas où vous mettez à jour beaucoup de données, vous pourriez observer une augmentation du temps de réponse dans les minutes suivant votre ROLLBACK. Pour vous en assurer, consultez la vue pg_stat_progress_vacuum : elle vous permettra de suivre l’avancement du VACUUM, et d’estimer sa fin.
TL,DR: connectez-vous toujours, même ponctuellement, avec un client SQL
Ne vous connectez pas au système d'exploitation de la base de données, utilisez un client SQL. Si vous ne pouvez pas faire autrement, changez les choses pour que cela devienne possible.
En effet, si vous vous connectez à l'OS:
- vous avez potentiellement accès au filesystem où se trouvent les données. Cela peut poser un problème de sécurité, car vous n'êtes plus soumis à la gestion des droit (DCL) de PostgreSQL;
- vos actions peuvent avoir un effet inattendu et impacter le service.
Voilà deux exemples entraînant l'arrêt (non souhaité) de la base de données:
- pour arrêter une requête, vous arrêtez le processus avec kill -9 $PID; (source).
- pour monitorer la base de données exécutée dans un docker, vous modifiez l'image pour inclure un healthcheck custom (source).
Il est bien sûr possible que cela ne se produise jamais, parce que vous connaissez la gestion des processus Linux dans le contexte PostgreSQL et Docker. Pour ma part, je préfère laisser ces compétences aux administrateurs systèmes et ne jamais devoir me connecter à l'OS. Simplifions-nous la vie.
Un cas particulier peut se produire pour les traitements longs, par exemple l'export de grandes quantités de données. Il est tentant d'exécuter ces traitements sur le système d'exploitation de la base de données, plutôt que sur un client distant qu'il faut configurer et maintenir en vie, "juste pour une fois".
Je vous encourage pourtant à utiliser un client séparé:
- si vous êtes sur le cloud, il existe des conteneurs one-off pour ce cas d'usage;
- si le besoin est récurrent, utilisez un ordonnanceur léger; il y en a même qui s'exécutent en toute sécurité dans PostgreSQL: pg_timetable, pg_boss.
Dans la salle des urgences
Vous avez lu et appliqué les préconisations de médecine préventive, et malgré cela, la crise se produit : vous voilà en salle des urgences. Que faire ? Pour commencer, sachez que vous êtes en train de lire un article. Et donc qu’il vous est encore possible de vous entraîner aux techniques qui vont suivre avant que cela se produise vraiment.
Vous ne pourrez pas empêcher la crise, mais vous pourrez au moins garder la tête froide alors que ça chauffe sur le channel, que le téléphone sonne sans arrêt et que votre chef vient regarder au-dessus de votre épaule tous les quarts d’heure ”pour aider”.
Commencez par lire ce qui suit, puis enrôlez votre collègue pour qu’il fasse le diable : il devra déployer des versions applicatives avec des problèmes grossiers de performance et exécuter des requêtes malicieuses dans votre dos. Amusez-vous bien ! Vous commencerez ailleurs qu’en production, n’est-ce pas ?
Les verrous sont vos amis
TL;DR: si pg_stat_activity mentionne des requêtes qui attendent un verrou, consultez les vues de verrou pour savoir qui le détient
Les verrous sont la face émergée de l'iceberg de la concurrence, mais ils sont souvent mal compris. J’utiliserais des exemples pour que vous sortiez de cette lecture avec une vue claire, bien que cela rallonge l’article.
les verrous ne sont pas bloquants
Votre outil de monitoring vous montre que certains appels API sont plus longs qu’à l'accoutumée. Vous utilisez votre APM, ou votre connaissance du code associée à la vue pg_stat_activity , pour conclure que cela est dû à la base de données: en l'occurrence, une des requêtes SQL appelées par le endpoint passe la plupart de son temps à attendre l’attribution d’un verrou. Vous pestez contre ces satanés verrous : sans eux la vie serait plus facile. Réfléchissez-y à deux fois: les verrous sont au service de la concurrence; sans eux, les bases de données seraient encore plus lentes, ou incohérentes.
Le périmètre d’un verrou PostgreSQL est le plus petit possible (enregistrement, partition, table), et les verrous sont de plusieurs types. Nombre d’optimisation sont effectuées pour que, à l’exception du DDL, "les lectures ne bloquent pas les écritures, et les écritures ne bloquent pas les lectures".
Ce qui vous fait maugréer, ce ne sont pas les verrous, mais l’accaparement des ressources : si votre requête attend l’attribution d’un verrou, c’est qu’une autre requête ne l’a pas libéré. Les verrous obéissent à une queue FIFO: si une requête a demandé un verrou, il lui sera attribué dans l’ordre de la demande: aucun mécanisme ne permet à une autre requête de lui passer devant. En résumé, votre objectif est d’identifier qui possède ce verrou, et pourquoi il ne l’a pas libéré.
verrous et transactions
Comme évoqué brièvement plus tôt, chaque requête est, par défaut, exécutée dans une transaction atomique, validée implicitement (implicit commit). Ceci dit, vous pouvez englober plusieurs requêtes dans une même transaction en créant explicitement une transaction avec le mot-clé BEGIN TRANSACTION. C’est cela qui rend la recherche de qui détient le verrou si difficile : c’est la transaction qui détient les verrous, pas la requête.
Deux règles s’appliquent:
- les verrous sont demandés le plus tard possible, et non au début de la transaction;
- les verrous sont libérés à la fin de la transaction.
Cela implique qu’une transaction peut demander et obtenir un verrou V1, effectuer une requête, demander un verrou V2 pour la requête suivante, et attendre qu’il lui soit attribué. Pendant ce temps, si une autre transaction a besoin du verrou V1, elle est elle aussi suspendue. Autrement dit : une transaction peut bloquer transitivement N transactions si elles utilisent la même ressource à un moment.
mais qui diable a le verrou ?
La bien nommée pg_locks contient la réponse, mais elle n’est pas adaptée à notre usage direct : nous avons besoin d’une requête hiérarchique pour construire l’arbre des dépendances. Vous pouvez utiliser cette version, voire la déployer en tant que vue sur vos environnements.
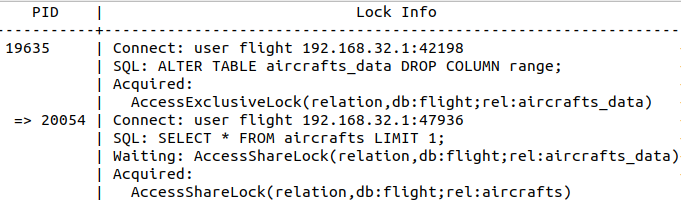
Voilà un exemple de résultat, en utilisant ce modèle de données. Vous pouvez simplifier l’interprétation en supposant que chaque connexion réseau porte une seule session SQL, gérée par la base de données dans un seul processus de l’OS, identifié par un PID. Sur chaque session, une transaction est en cours sur une requête SQL.

Tout d’abord, considérons la colonne PID:
- sur la première ligne, alignée à gauche, est le premier noeud, avec le PID 24936;
- ce noeud est une session qui n’attend aucun verrou: elle peut être en cours d’exécution, ou inactive;
- ce noeud est un noeud racine, car il ne dépend d’aucun autre;
- il peut y avoir plusieurs noeud racine si plusieurs sessions ne dépendent pas les unes des autres (forêt);
- sur la sixième ligne, indenté d’une séquence à droite et précédé d’une flèche, est le premier descendant, avec le PID 19635;
- ce noeud est une session bloquée par son parent, le noeud PID 24936;
- son frère, la session 20054, est lui aussi bloqué par la même session;
- cette structure ne possède ici que deux niveaux, mais en conditions réelles elle peut être aussi profonde que nécessaire, il suffit qu’une transaction en bloque une autre pour ajouter un niveau.
Ensuite, regardons Ia colonne Lock info, où vous trouverez:
- dans SQL, la dernière requête à exécuter;
- dans Acquired, les verrous acquis par la transaction : 24936 a un verrou de niveau AccessExclusiveLock sur une table (relation), aircrafts_data ;
- dans Waiting, les verrous qui ont été demandés et pas encore acquis: 19635 attend un verrou de type AccessShareLock sur la vue aircrafts.
Enfin, dans la colonne state, vous trouverez la date de début de la session et son statut (actif ou en attente).
Si vous n’aviez pas accès à cette vue, mais vous contentiez des sessions dans pg_stat_activity, vous ne pourriez pas savoir que la session 24936 dont la requête est une lecture sur bookings bloque la session 19635 dont la requête est une écriture sur aircrafts_data.
et quand le verrou sera levé ?
Si la transaction sur la session 24936 prend fin, qu’arrivera-t-il ? Vous pourriez penser que les deux descendants, les sessions 19635 et 20054 seront débloquées et exécutées. En fait, la première session à avoir demandé le verrou sur la ressource, 19635, l’obtiendra. Ensuite, PostgreSQL vérifie s’il peut accorder à la session 20054 un verrou de type AccessShareLock sur la même ressource, la table aircrafts_data. Il compare pour cela le niveau de verrou demandé à celui déjà accordé. Le verrou accordé est le plus élevé AccessExclusiveLock, et il met donc en attente cette demande de verrou: 20054 devra attendre.
Dans l’arbre des verrous, la session 20054, qui était un frère de la session 19635, est désormais un descendant.
Pour résumer, vous ne pouvez pas lire directement le futur dans l’arbre des verrous: il vous faudra comparer les ressources et niveaux de verrouillage en vous aidant de la documentation.
Si le scénario choisi vous semble étrange, à savoir deux requêtes dont l’une lit une table et l’autre modifie sa structure, c’est qu’il s’agit de simuler un déploiement en zéro-downtime (ZDD): l’application lit des données alors que le script de déploiement modifie le schéma.
Pour que les objectif du ZDD soient remplis:
- le déploiement doit pouvoir démarrer rapidement : il ne doit pas être bloqué (longtemps) par des transactions applicatives, ici 24936;
- le déploiement ne doit pas impacter le niveau de service : il ne doit pas bloquer (longtemps) les transactions applicatives, ici 20054.
Pour cela, vous pourriez utiliser le site pglocks pour préparer le déploiement:
- identifiez le verrou (ressource et niveau) que votre déploiement demandera;
- ensuite, identifiez les requêtes longues qui pourraient le bloquer;
- et pour finir, vérifier si des requêtes applicatives importantes pourraient être bloquées.
Ne comptez pas sur la base de données pour garder le contact
TL;DR: lorsqu’une requête SQL a débuté sur le serveur, elle sera exécutée jusqu’à la fin - peu importe que le client se soit déconnecté
Qu’est-il arrivé à la requête que vous avez lancée depuis votre ordinateur portable, après que vous ayez renversé votre café dessus ? Et à celle que votre collègue a lancée ce midi sur son ordinateur portable (elle est longue et coûteuse, et personne n’utilise la base de données le midi), après qu’il ait dû le débrancher du réseau pour rentrer chez lui en urgence ? Si la requête était lancée dans une transaction explicite, et que personne n’est là pour la valider, la transaction sera-t-elle annulée, validée, ou en attente d’une réponse qui ne viendra jamais ?
Ces requêtes sont comme des processus orphelins: leurs processus parents ne sont plus vivants. Ces requêtes sont en cours d’exécution sur le serveur (la base de données) alors que le client est parti. Que se passera-t-il ?
Votre chef répondrait que personne ne doit lancer de requêtes depuis son poste, car les machines et le réseaux ne sont pas fiables. Qui plus est, les requêtes devraient être rapides et ne pas durer des heures. Il y a du vrai dans ce qu’il dit, mais même les conteneurs distants à usage unique peuvent avoir des problèmes de réseau. Les timeouts, c’est bien : c’est un moyen simple de vous assurer que votre traitement finisse un jour, que vous n’attendiez pas indéfiniment. Il faut prévoir l'échec, dit le 12-factor app.
La plupart des proxy ont un timeout, par exemple ceux devant les API REST; c’est d’ailleurs pour ça qu’existe le code d’erreur HTTP 504. Que se passe-t-il quand un appel API tombe en timeout, alors que PostgreSQL exécute une requête ? Vous devez l’expérimenter sur votre environnement. Par exemple, le framework REST NodeJs appelé HapiJs laisse la requête s’exécuter sur le serveur de base de données; une fois le résultat disponible, au moment de répondre au client REST, il trouve un socket fermé.
Si cela arrive peu souvent, et que la requête SQL est rapide, l’impact est faible. Mais parfois, si le client de l’API a une stratégie de retry et que la requête consomme des ressources, une escalade peut se produire : la même requête SQL est exécutée encore et encore, et ses résultats sont systématiquement ignorés. Cette situation est facile à identifier si vous monitorez votre API et votre base de données. Théoriquement, vous pourriez modifier le code de votre API pour demander à la base de données d’arrêter la requête. Mais rappelez-vous que vous êtes en salle des urgences: vous allez devoir arrêter ces requêtes SQL.
D’ailleurs, si nous revenons à notre problème de café, que se passe-t-il si le client sql s'est déconnecté ? PostgreSQL n’est pas informé de la déconnexion du client, il continue à exécuter la requête. Il trouve lui aussi porte close lorsqu’il veut retourner les résultats. La seule exception est lorsque le client lui signale son arrêt, par exemple lorsque vous entrez Ctrl-C dans psql: dans ce cas, la requête est interrompue. Dans tous les cas, préparons-nous à devoir arrêter ces requêtes. C’est l’objet du prochain (et dernier ! ) chapitre.
Préparez-vous à la séparation
TL;DR: pour interrompre une requête, utilisez pg_terminate_backend - et préparez-vous à un AUTOVACUUM.
Résumé des épisodes précédents: quelqu’un, ou quelque chose, a lancé une requête en production, et cette requête doit prendre fin, et rapidement.
Bien que cela ne soit pas agréable, cela se produira un jour :
- la requête est invalide, et corrompt les données (un bug!);
- la requête est valide, mais le client s’est déconnecté;
- la requête est valide, mais accapare les ressources et dégrade le service (un bug?);
- la requête est valide, mais là c’est pas le moment (déploiement ZDD).
Dans tous les cas, il vous faut deux choses: un client SQL avec une connexion ouverte, et le PID du processus qui exécute la requête. Si vous avez suivi la médecine préventive, vous avez déjà ces deux éléments.
Il ne vous reste qu’à vous demandez le périmètre de votre action:
- pour mettre fin à la requête SQL, utilisez pg_cancel_backend($PID);
- pour mettre fin à la connexion, requête SQL courante incluse, utilisez pg_terminate_backend($PID).
Si vous arrivez ici en panique et n’avez pas lu le début de cet article, consultez plutôt ce guide pratique. Mettre fin à la mauvaise requête ou de la mauvaise manière (par exemple, en se connectant à l’OS et en tuant le processus) ne résoudra pas votre problème, il ne fera que l’aggraver.
Gardez en tête que si la transaction est annulée, un AUTOVACUUM peut se déclencher, mais comme vous avez déjà lu ce chapitre, vous le saviez déjà, n’est-ce pas ?
Demandez de l’aide
Si vous avez lu et pratiqué ces 7 conseils, et avez toujours des problèmes, c’est le moment de vous tourner vers votre DBA. Comme vous aurez préparé le terrain et connaîtrez mieux le problème à résoudre, il pourra utiliser ses compétences spécifiques - en partant de là où vous êtes arrêtés - plutôt que de faire tout le travail d’investigation.
Un cas typique est “la requête lente” : en observant votre base de données, vous identifiez une requête qui en bloque fréquemment plusieurs autres, pendant plusieurs dizaines de secondes. Comme vous connaissez le modèle de données, vous savez que cette requête devrait manipuler peu de données, et donc être rapide. Lorsque vous sollicitez le DBA avec cette demande claire, il peut trouver ce qui cause cette lenteur. Il utilisera des plans d’exécution, il vous parlera d’index, de partitions et de statistiques. Si toutes ces choses ne vous sont pas familières, peu importe : en travaillant ensemble vous trouvez une solution. Imaginez maintenant que vous n’ayez pas fait ce travail préparatoire et veniez le voir en disant, en tout et pour tout : “cette base de données est trop lente”. Il devrait faire le travail de recherche lui-même, en faisant des hypothèses sur le domaine métier qu’il ne connaît pas, ou en vous sollicitant sans arrêt. Bilan : il passerait beaucoup plus de temps.
Avant que vous partiez tester toutes ces idées sur votre application, laissez-moi glisser une dernière chose dans votre poche, un avertissement de Mikko Hypponen.
Personne n’est remercié pour le travail qu’il a fourni afin d’éviter qu’une catastrophe se produise, et qui ne s’est pas produite