Comment optimiser un job Spark
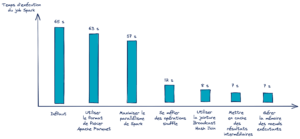
Exemple de gain de temps sur un cas d’usage exemple
Spark est aujourd’hui un outil incontournable pour le traitement de données volumineuses. Cette technologie s’est imposée comme la plus sollicitée et recommandée pour de nombreuses applications business en data engineering. La dynamique est d’ailleurs soutenue par les offres de services managés comme Databricks qui permettent de s’affranchir d’une partie des coûts liés à l’achat et à la maintenance d’un cluster de machines distribués pour le calcul. Les fournisseurs de Cloud les plus importants proposent également des services d'intégration de Spark (AWS EMR, Azure HDInsight, GCP Dataproc).
Spark est couramment utilisé pour appliquer des transformations sur des données, structurées dans la plupart des cas. Deux scénarios motivent particulièrement son recours. Le premier est lorsque les données à traiter sont trop importantes vis-à-vis des ressources de calcul et de mémoire à disposition. C’est ce que l’on appelle le phénomène big data. Enfin, c’est également une alternative lorsque l’on veut accélérer un calcul, en mettant à contribution plusieurs machines au sein d’un même réseau. Dans ces deux cas, une préoccupation majeure est alors l’optimisation du temps de calcul d’un traitement nommé job Spark.
Pour répondre à cette problématique, l’approche visant à augmenter les ressources allouées dans un cluster est de plus en plus observée. Cette tendance est accentuée notamment par la facilité et le coût de location de puissance de calcul auprès des fournisseurs de Cloud.
L’objectif de cet article est de proposer et détailler une stratégie d’optimisation d’un job Spark lorsque les ressources sont limitées. En effet, nous pouvons influer sur de nombreuses configurations de Spark avant de recourir à l’élasticité du cluster. Cette stratégie peut ainsi être expérimentée en premier lieu.
Afin d’éviter une recherche exhaustive de la meilleure configuration, ce qui est naturellement très coûteux, car d’une complexité exponentielle, cet article exposera les principaux leviers sur lesquels nous pouvons jouer en priorité pour maximiser nos chances de réduire le temps de calcul. Chaque étape sera matérialisée par une recommandation expliquée au regard du fonctionnement de Spark.
Concrètement, la stratégie exposée est dite gloutonne, c’est-à-dire que l’on fait le meilleur choix à chaque étape du procédé sans retour en arrière. La démarche est illustrée par un fil conducteur en six recommandations.
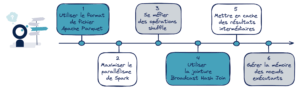
Ligne directrice avec 6 recommandations
L'objectif est de fournir une méthodologie claire et facile à tester sur différents cas d’usage. Il convient dès lors de tester ces recommandations sur un exemple partageable et de mettre à disposition un code template permettant de réitérer cette expérience sur un autre job Spark.
Application sur un cas d’usage exemple
Afin de tester la stratégie d’optimisation proposée dans cet article, nous avons utilisé un cas d’usage “jouet” pour construire un job Spark. Le traitement permet de grouper des villes françaises selon des variables météorologiques et démographiques. Cette tâche est appelée classification non supervisée ou clustering en Machine Learning. L’exemple illustre des fonctionnalités courantes d’un pipeline en Spark, c'est-à-dire une phase de prétraitement des données (chargement, nettoyage, fusion de différentes sources, feature engineering), l’estimation des paramètres d’un modèle de Machine Learning, et enfin l’écriture sur disque des résultats. De plus amples détails sur cette expérience sont disponibles sur le dépôt du code.
En suivant pas à pas les recommandations détaillées dans cet article, nous pouvons observer l’influence des différentes optimisations effectuées sur le graphique suivant.
Les configurations trouvées sont certes une solution sous-optimale. Néanmoins, cela offre une perspective beaucoup plus rapide qu’une recherche exhaustive, situation que l’on cherche absolument à éviter en traitement big data.
Un rappel rapide sur Spark et quelques notions utiles pour la suite
Spark en quelques mots
Apache Spark est un framework de calcul distribué à grande échelle. Il permet notamment un stockage des résultats intermédiaires en mémoire (RAM et disque), ce qui en fait un outil très efficace.
Les traitements au cœur de Spark utilisent massivement la programmation fonctionnelle pour résoudre le problème du passage à l’échelle en big data. C’est donc naturellement que le code source est codé essentiellement en langage Scala.
Néanmoins Spark propose également des APIs en Python, Java, R et SQL plus haut niveau, offrant des possibilités quasi équivalentes et sans perte de performance désormais dans la plupart des cas (hors fonctions UDF par exemple). Le projet est open source et sous licence Apache 2.0.
Le schéma ci-après décrit le fonctionnement classique d’un traitement Spark dans un cluster de calcul distribué.

Le Spark driver, également appelé noeud maître, orchestre l’exécution du traitement et sa répartition entre les Spark executors (également appelés noeuds esclaves). Le driver n’est pas forcément inclus dans le cluster de machines utilisées pour le calcul, il peut être un client externe. Le cluster manager gère les ressources disponibles en temps réel du cluster. En ayant une vision plus large que l’application Spark, il alloue au driver Spark les ressources demandées si elles sont disponibles. Dans cet article, l’utilisation du cluster manager ne sera pas abordée.
Décomposition d’un job Spark
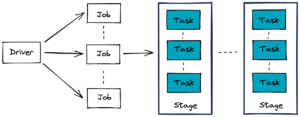
Un job Spark est une succession de stages, eux-mêmes constitués de tasks. Plus précisément, on peut le représenter par un graphe dirigé acyclique (Direct Acyclic Graph, DAG). Un exemple de job Spark est un pipeline de traitement de données de type ETL (Extract Transform Log). Des stages composent ce DAG. Ils sont souvent délimités par un transfert de données dans le réseau entre les nœuds exécutants, comme une opération de jointure entre deux tables. Enfin, une task est une unité d’exécution dans Spark qui est assignée à une partition des données. Un stage est décomposé en tasks.
Lazy Evaluation
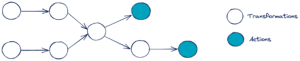
La Lazy Evaluation est une astuce souvent utilisée pour des traitements de données volumineuses_._ En effet, lorsque celles-ci excèdent la place en mémoire, il est nécessaire d’établir une stratégie pour optimiser le calcul. La Lazy Evaluation est ainsi une méthode pour déclencher un traitement uniquement lorsqu'une action Spark est invoquée et non une transformation Spark.
![]()
Exemples d’actions et de transformations
Concrètement, les transformations ne sont pas effectuées tant qu’une action n’a pas été appelée. Spark peut ainsi préparer un plan logique et physique d’exécution en vue de réaliser l’action de manière plus optimale.
Prenons un exemple pour en comprendre l’intérêt. Une action est invoquée pour renvoyer au driver la première ligne d’une table qui a subi plusieurs transformations. Spark peut alors réorganiser le plan d’exécution des transformations précédentes pour obtenir cette première ligne transformée plus rapidement en gérant la mémoire et les calculs. En effet, dans cet exemple, seule la partition contenant la première ligne du tableau a besoin d’être traitée. Cela soulage grandement la mémoire et les calculs en traitement inutile.
Transformations wide and narrow
Parmi les transformations opérées par Spark, on distingue deux catégories: les transformations wide et narrow. La différence entre ces deux types est le besoin d’une redistribution des partitions de données dans le réseau entre les nœuds exécutants. Ce phénomène important est appelé un shuffle dans la terminologie Spark.
![]()
Les transformations wide nécessitant un shuffle sont naturellement les plus coûteuses. Le traitement est plus long en fonction de la taille des données échangées et la latence réseau dans le cluster.
Comment modifier les configurations d’un job Spark ?
Il y a trois façons de modifier les configurations d’un job Spark:
En utilisant les fichiers de configuration présents dans le dossier racine de Spark. Nous pouvons par exemple personnaliser les fichiers standardisés suivants:
- conf/spark-defaults.conf.template
- conf/ log4j.properties.template
- conf/spark-env.sh.template Ces modifications affectent le cluster Spark et toutes ses applications.
En ligne de commande à l’aide de l’argument --conf Ex :

- Directement dans le code de l’application Spark Ex:

L’ordre de précédence entre ces trois méthodes se fait par ordre de lecture. Les valeurs définies dans les fichiers de configuration sont considérées en premier lieu. Ensuite, ce sont les arguments passés en paramètres de spark-submit. Et enfin celles configurées directement dans le code de l’application via le SparkSession le plus souvent.
Ces paramètres de configuration sont visibles en lecture seule dans l’onglet Environment de l’interface graphique de Spark.

Dans le code associé à cet article, les paramètres sont définis directement dans le code de l’application Spark.
Etape préliminaire: Mesurer si une optimisation est nécessaire
Optimiser un traitement est une étape coûteuse en temps et donc en argent sur un projet. Celle-ci doit donc être justifiée au préalable.
En règle générale, les contraintes sont liées au cas d’usage et sont définies en accord avec les différentes parties prenantes dans le service-level agreement (SLA). Il est alors primordial de mesurer les métriques importantes (ex: temps de traitement, mémoires allouées, etc…), et de vérifier leurs conformités dans le respect du SLA.
Estimer le temps nécessaire pour optimiser un code et atteindre un objectif précis n’est pas simple. Cela demande souvent de l’expérience en ingénierie logicielle. Cet article n’a pas cette prétention, mais vise plutôt à fournir des leviers actionnables rapidement.
D’autre part, ces recommandations fournissent des pistes d’amélioration. Il peut-être alors intéressant de les confronter à un profiling de son traitement au préalable. Cela permettra de cibler les recommandations les plus pertinentes.
1ère recommandation: Utiliser le format de fichier Apache Parquet
Le format Parquet est officiellement un stockage orienté colonne, en réalité il s’agit plutôt d’un format hybride entre un stockage ligne et colonne. Il est utilisé comme format pour des données tabulaires. Les données d’une même colonne sont stockées de façon contigüe.
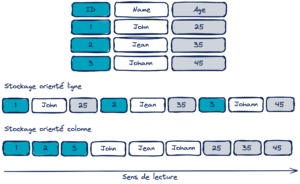
Ce format est particulièrement souhaitable lorsque l’on effectue des requêtes (transformations) sur un sous-ensemble de colonnes et sur des données volumineuses. En effet, cela permet de charger en mémoire seulement les données associées aux colonnes nécessaires.
Par ailleurs, le schéma de compression et l’encodage étant propres à chaque colonne selon le typage, cela améliore la lecture / écriture de ces fichiers binaires et leurs tailles sur disque.
Ces atouts en font donc une alternative très intéressante par rapport au format CSV. C’est d’ailleurs le format recommandé par Spark et celui par défaut en écriture.
Si Spark est utilisé avec Databricks, un autre format particulièrement intéressant est le format delta proposant des outils d’optimisation automatiques. Dans cet article, nous nous focaliserons sur la version open source de Spark. Néanmoins le lecteur intéressé est vivement invité à explorer l’intégration de Spark dans l’écosystème Databricks.
2ème recommandation: Maximiser le parallélisme de Spark
Spark puise son efficacité dans sa capacité à traiter plusieurs tâches en parallèle et avec un passage à l’échelle. Dès lors, plus on lui facilite le découpage des tâches, plus celles-ci seront effectuées rapidement. C’est pourquoi l’optimisation d’un job Spark passe par la lecture et le traitement d’autant de données que possible en parallèle. Et pour atteindre ce but, il est nécessaire de fractionner un jeu de données en plusieurs partitions.
Partitionner un dataset est une façon d’arranger les données en sous-ensembles configurables et accessibles en lecture par bloc de données contigües sur disque. Ces partitions peuvent ainsi être lues et traitées de manière indépendante et en parallèle. C’est cette indépendance qui permet un traitement massif de données. Idéalement, Spark organise un thread par tâche et par cœur de CPU. Chaque tâche est relative à une partition distincte. Ainsi, une première intuition est de configurer un nombre de partitions au moins aussi important que le nombre de coeurs CPU à disposition. Tous les cœurs doivent être le plus souvent occupés durant l’exécution du job Spark. Si l’un d’entre eux est disponible à un moment, il doit pouvoir traiter une tâche associée à une partition restante. L’intérêt premier est d'éviter les goulots d’étranglement en découpant les stages du job Spark en un grand nombre de tâches. Cette fluidité est indispensable dans un cluster de calcul distribué. Le schéma suivant illustre ce découpage entre les machines du réseau.
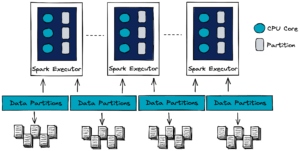
Les partitions peuvent être créées:
- A la lecture des données en configurant le paramètre spark.sql.files.maxPartitionBytes (par défaut à 128 MB). Une situation idéale est lorsque les données sont déjà organisées en plusieurs partitions sur disque. Par exemple, un jeu de données au format parquet, sous la forme d’un dossier contenant des fichiers de partitions de données d’une taille entre 100 et 150 MB.
- Directement dans le code de l’application Spark à l’aide de l’API Dataframe. Un exemple:

Cette dernière méthode coalesce permet de décroître le nombre de partitions en évitant un shuffle dans le réseau.
On pourrait être tenté d’augmenter le nombre de partitions en baissant la valeur du paramètre spark.sql.files.maxPartitionBytes. Néanmoins, ce choix peut engendrer le phénomène du small file problem. Il se produit une dégradation des performances en I/O en raison des opérations effectuées par le système de fichiers (par ex. ouverture, fermeture, listage des fichiers), ce qui est souvent amplifié avec un système de fichiers distribué comme HDFS. Il peut également y avoir des problèmes de scheduling si le nombre de partitions est trop important.
En pratique, ce paramètre doit donc être défini de manière empirique en fonction des ressources disponibles.
3ème recommandation: Se méfier des opérations shuffle
Il existe un type de partition spécifique dans Spark appelé partition shuffle. Ces partitions sont créées pendant les stages d’un job impliquant un shuffle, c’est-à-dire lorsqu’une transformation de type wide (e.g. groupBy(), join()) est effectuée notamment. Le réglage de ces partitions impacte à la fois le réseau ainsi que les ressources disques en lecture/écriture.
On peut modifier la valeur de spark.sql.shuffle.partitions pour contrôler leur nombre. Par défaut, celui-ci est à 200 ce qui peut-être trop élevé pour certains traitements, et se traduit par un nombre trop important de partitions échangées dans le réseau entre les nœuds exécutants. Il convient d’ajuster ce paramètre en fonction de la taille des données. Une intuition peut être de commencer par une valeur égale au moins égale au nombre de coeurs CPU dans le cluster****.
Spark stocke les résultats intermédiaires d’une opération shuffle sur les disques locaux des machines esclaves, la qualité des disques notamment en lecture/écriture a donc son importance. Par exemple, l’usage de disques SSD améliorera sensiblement les performances sur ce type de transformations.
Le tableau ci-dessous décrit les principaux paramètres sur lesquels nous pouvons également influer.

4ème recommandation: Utiliser la jointure Broadcast Hash Join
Une jointure entre plusieurs tables est une opération courante. En contexte distribué, un volume de données important est échangé dans le réseau entre les nœuds exécutants pour la réaliser. En fonction de la taille des tables, cet échange entraîne de la latence réseau, ce qui ralentit le traitement. Spark offre plusieurs stratégies de jointure pour optimiser cette opération. L’une d’entre elles est particulièrement intéressante si elle peut être choisie, il s’agit du Broadcast Hash Join (BHJ).
Cette technique convient lorsqu’une des tables fusionnées est “suffisamment” petite pour être dupliquée en mémoire sur tous les nœuds exécutants (opération de broadcast). Le schéma ci-dessous illustre le fonctionnement de cette stratégie.

La seconde table est classiquement décomposée en partitions réparties entre les nœuds du cluster. En dupliquant la plus petite table, la jointure ne nécessite ainsi plus d’échange important de données dans le cluster hormis le broadcast de cette table au préalable. Cette stratégie améliore donc grandement la vitesse d’exécution de la jointure. Le paramètre de configuration Spark à modifier est spark.sql.autoBroadcastHashJoin. Par défaut, sa valeur est de 10 MB, c’est-à-dire que cette méthode est choisie si une des deux tables a une taille inférieure à cette grandeur. Si l’on dispose de ressources mémoires suffisantes, il peut-être très intéressant d’augmenter cette valeur ou de la fixer à -1 pour forcer Spark à y recourir.
5ème recommandation: Mettre en cache des résultats intermédiaires
Pour optimiser ses calculs et gérer les ressources mémoires, Spark utilise notamment la lazy evaluation et un DAG pour décrire un job. Cela offre la possibilité de pouvoir recalculer rapidement les étapes en amont d’une action si besoin, et donc de n’exécuter qu’une partie du DAG. Pour tirer pleinement avantage de cette fonctionnalité, il est alors très judicieux de stocker des résultats intermédiaires coûteux si plusieurs opérations les utilisent en aval du DAG. En effet, si une action est invoquée, son calcul pourra se baser sur ces résultats intermédiaires et donc rejouer une sous-partie du DAG.
Prenons l’exemple du DAG suivant:
Pour obtenir les résultats des deux actions, les traitements à effectuer sont décrits dans les deux DAG ci-après.

Afin d’accélérer l’exécution, on peut décider de mettre en cache des résultats intermédiaires (ex. le résultat d’une jointure de tables).
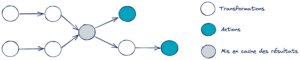
Désormais le traitement de la deuxième action est simplifié. A noter que lors de la première action les résultats n’ont pas encore été stockés en mémoire.

Si cette mise en cache peut améliorer la rapidité d’exécution d’un job, elle a néanmoins un coût lors de l’écriture en mémoire et/ou disque de ces résultats. Il convient donc de tester à différents endroits du pipeline de traitement si le gain de temps total l’emporte. C’est d’autant plus pertinent lorsqu’il y a plusieurs chemins sur le DAG.
Exemple d’un gain de temps avec une mise en cache d’une table simulée à deux colonnes :

L’exécution a duré 2,5 secondes

_L’exécution a duré 147 ms_N.B. La mise en cache, comme toute transformation Spark, est opérée lorsqu’une action est invoquée. Si le calcul de cette action n’implique qu’une sous-partie des données, alors uniquement les résultats intermédiaires concernant cette sous-partie seront stockés. Dans l’exemple précédent, si l’action take(1) collectant la première ligne avait été appelée, seule la partition contenant cette première ligne aurait été mise en cache.On peut mettre en cache une table, par exemple après un chargement depuis le disque ou une transformation, à l’aide de la commande suivante:

Les différentes options de mise en cache sont décrites dans le tableau ci-dessous:

La liste complète des options est disponible ici.
6ème recommandation: Gérer la mémoire des noeuds exécutants
La mémoire d’un exécuteur Spark se décompose de la façon suivante:
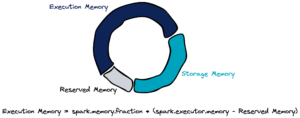
Par défaut, le paramètre spark.memory.fraction est fixé à 0,6. Cela veut dire que 60% de la mémoire est allouée à l’exécution et 40% pour le stockage, une fois retirée la mémoire réservée. Celle-ci est de 300 MB par défaut et est utilisée pour prévenir les erreurs de type out of memory (OOM).
Nous pouvons donc influer sur les deux paramètres suivants:
- spark.executor.memory
- spark.memory.fraction
Conclusion
Au cours de cet article, nous avons détaillé une stratégie d’optimisation d’un job Spark. Son principal objectif est de fournir un cadre pour toute personne désireuse d’optimiser un traitement tout en disposant d’un temps restreint pour le faire. L’approche gloutonne en six concepts entend aller à l’essentiel pour maximiser les chances de réduire le temps de calcul. Le schéma qui suit résume le fil conducteur en associant les recommandations proposées à chaque étape.
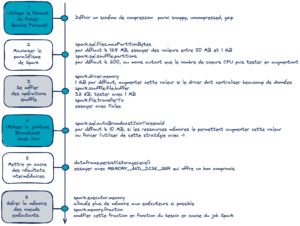
L’intérêt de chaque étape de ce procédé a été expliqué en lien avec le fonctionnement de Spark. En effet, même si des recommandations sur les configurations sont proposées, il est essentiel de bien comprendre les rouages internes. Chaque cas d’usage présente des spécificités propres, et aucune méthode ne peut être universelle. En cela, cet article constitue donc une mise en bouche de l’optimisation en Spark.
Pour aller plus loin
- Cet article vise à éviter le recours systématique à l’allocation dynamique de ressources dans un cluster pour accélérer un traitement. Néanmoins, celle-ci est bien sûr à considérer pour aller plus loin. Spark met à disposition les paramètres suivants pour gérer l’élasticité d’un cluster en fonction de la charge de travail : spark.dynamic_Allocation.enabled, spark.dynamicAllocation.minExecutors, spark.dynamicAllocation.schedulerBacklogTimeout, spark.dynamicAllocation.maxExecutors, spark.dynamicAllocation.executorIdleTimeout._
- De nombreuses autres stratégies de jointures de tables sont offertes par Spark: https://databricks.com/fr/session/optimizing-apache-spark-sql-joins
- Spark accorde bien sûr une importance particulière à l’optimisation de ses traitements. Pour étudier plus finement les rouages internes et projets en cours, les liens suivants peuvent être utiles: projet Tungsten, optimiseur Catalyst et Adaptive Query Execution (une nouveauté de la version 3.0)
- Séries d’articles sur le blog OCTO concernant les mécanismes internes de Spark : épisode 1, épisode 2 et épisode 3. Et également sur le moteur d’exécution Tungsten: Planification et exécution d’une requête SQL.