5 angles morts pour bien mener son chantier de perf - Compte rendu de la conférence de Jennifer Pelisson à la Duck Conf 2022
La mauvaise performance d’un produit informatique peut provoquer des ralentissements, des erreurs, voire des interruptions de service.
Dans sa présentation à la Duck Conf, Jennifer raconte l’histoire d’une plateforme de réservation d’examens au permis de conduire par des auto-écoles. Dans ce contexte particulier, les utilisateurs sont aux aguets pour récupérer un maximum de places aux dates souhaitées.
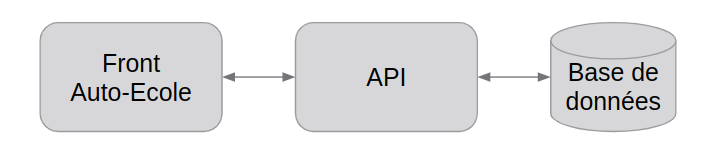
Flux simplifiés des échanges entre les différents applicatifs
Pendant la phase d'expérimentation du produit, la production est tombée pendant 10 minutes à cause des performances. Cette interruption de service a provoqué un rappel à l’ordre sur ce sujet qui n’avait pas été priorisé jusque-là.Plus d’un an après cette interruption, différents chantiers ont été menés, en parallèle d’ajout de nouvelles fonctionnalités. Ce retour d’expérience présente cinq angles morts pour bien mener son chantier de perf.
Angle mort #1 : Que veut-on tester ?
Une fois le constat établi, un regard sur la production a permis d’identifier une fonctionnalité très utilisée, qui sollicitait beaucoup la base de données : la récupération des places d’examens libres et réservées par les auto-écoles.
De cette analyse sont également sortis :
- Un scénario de tir de charge : pour reproduire les comportements identifiés
- Une cible : réussir à passer de 500 utilisateurs à 30000
- Des critères de succès : des temps de réponse acceptables (95 percentile inférieur à 150ms) et aucune erreur
Si votre produit n’est pas en production, il est recommandé de faire des hypothèses en amont.
Exemple d'outil utilisé pour l'analyse du trafic
Distribution des appels API dans le temps
Que les scénarios soient basés sur des hypothèses ou des constats, il est nécessaire d’itérer afin de les adapter régulièrement en fonction des nouvelles informations disponibles.
Angle mort #2 : Comment s’organiser ?
Deux organisations d’équipes ont été mises en place successivement.
Equipe dédiée
Peu de temps après l’incident, une équipe dédiée composée d’un développeur de chacune des 4 équipes a été montée. Cette équipe a permis de consolider le socle technique et de faire rapidement avancer les sujets. Il était cependant compliqué pour une équipe externe d'insuffler la culture des performances auprès des autres équipes.
L’affaire de tous
Une fois le socle mis en place et les gros problèmes de performance résolus, l’équipe dédiée a été dissoute et ses membres sont retournés auprès des équipes de développement. Ils sont restés moteurs des travaux de performance, tout en transmettant les pratiques à l’ensemble des développeurs. Pour pallier la priorisation compliquée entre performance et fonctionnalités, une charge fixe était allouée à chaque itération. Une tech lead transverse assurait le suivi des travaux de performance.
Aujourd’hui, les équipes, qui partagent une base de code commune, intègrent la performance dans leur développement et prennent un maximum d’informations en production.
Angle mort #3 : Comment gérer ses données ?
Il est important que les scénarios soient joués avec des données représentatives. Au départ, les scénarios ont été joués sur des données de production, évidemment anonymisées. La plateforme étant encore en phase d’expérimentation à cette époque, le jeu de données a ensuite été consolidé pour représenter la population cible.
La donnée, ça prend du temps
La consolidation est chronophage, mais pas adaptée à tous les contextes. La vigilance apportée lors de la construction du jeu de données cible est primordiale. Par exemple, l’expérimentation de l’ajout d’un index n’aura pas les mêmes impacts en fonction du volume et de la distribution des données.
La donnée, ça se périme
Certaines données à une date peuvent se révéler obsolètes dans le futur. C’est par exemple le cas du planning d’une auto-école, qui se base sur la date du jour. Pour contourner ce problème, les créneaux d’examens du calendrier ont été décalés toutes les semaines d’une semaine. Ce qui a permis en pratique de garantir la reproductibilité des scénarios.
La donnée, ça se reset
Par ailleurs, certains scénarios modifient les données (exemple : scénario d’inscription d’un candidat à un examen). Une solution de remise à zéro des données doit alors être mise en place.
Angle mort #4 : Comment s’équiper pour tester ?
Dans un premier temps, il est important d’avoir accès à un environnement de performance dédié. L’infrastructure et la configuration de ce dernier doit être le plus proche possible de la production et isolé afin de reproduire des comportements sans influence extérieure et sans affecter de vrais utilisateurs.
Une plateforme de monitoring efficace est primordiale pour s’assurer de comprendre les facteurs limitant et identifier des pistes de correction. Les travaux apportés à cette plateforme pour les performances contribuent aussi à la production.
Pour lancer les scénarios et améliorer le feedback, des pipelines gitlab-ci ont été construites. Différents types de jobs ont ainsi été créés, pour :
- allumer / éteindre l’environnement pour rationaliser les coûts
- mettre à jour les données
- paramétrer et lancer différents scénarios
- déployer des parties importantes rapidement, pour accélérer la boucle de feedback.
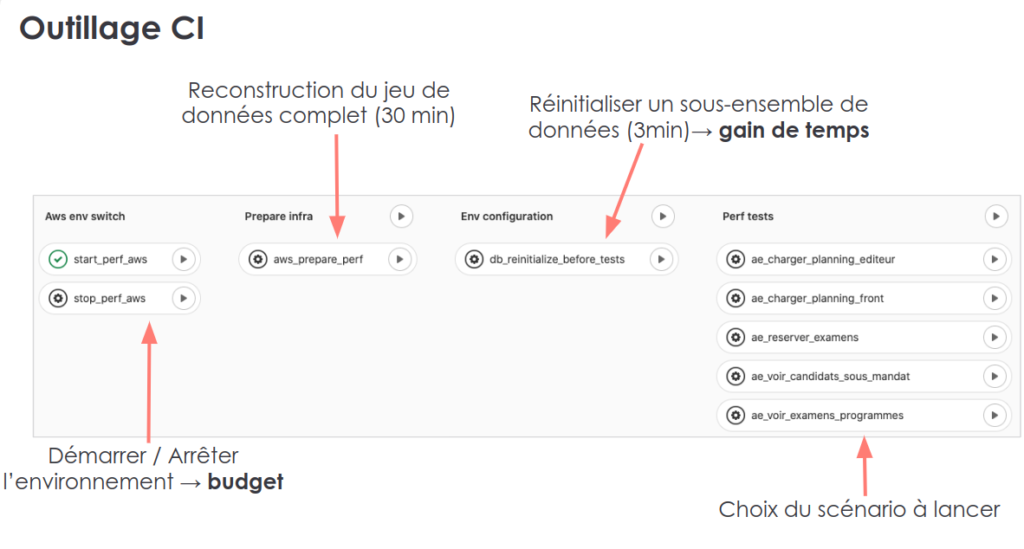
Outillage CI mis en place pour gérer les tirs de performance
Angle mort #5 : Quelle méthode pour ne pas se noyer ?
Avant de se lancer, il est recommandé de définir des cibles, telles que le temps de réponse et le nombre maximal d’appels concurrents sans erreur. Si les cibles ne sont pas atteintes, il convient alors d’identifier le ou les goulots d’étranglement, comme par exemple la base de données. Si vous n’avez pas de services limitant, alors vous n’avez pas de problème de performances !
Jennifer insiste sur l’importance d’expérimenter étape par étape, pour être certain de comprendre ce qui se passe. Autrement, vous risquez par exemple d’ajouter des machines ou des index “pour rien”.
Il est également important d’identifier au plus tôt les impacts des évolutions applicatives sur les scénarios de performance, pour éviter que l’ajout d’une nouvelle règle métier ne crée une régression sur un scénario donné.
Par ailleurs, des évolutions impactantes sur des fonctionnalités très utilisées peuvent mériter des tests de performance, complémentaires aux tests fonctionnels. Cette vérification en amont évite de découvrir des régressions directement en production.
Bonus : Quelques tips pour la route
Niveau base de données :
La base de données est souvent un composant critique pour les performances. Les index sont un quickwin qu’il est facile de mettre en place. Le feedback est rapide et les gains apportés peuvent être très importants.
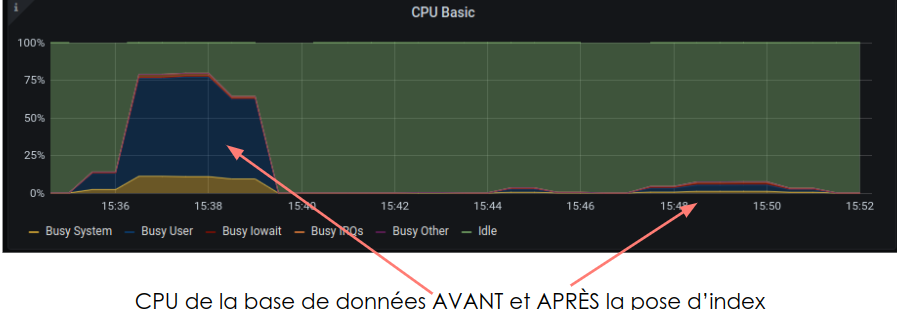
Certains outils permettent d’identifier rapidement les requêtes les plus gourmandes en base et les plus exécutés. Ils permettent d’orienter les travaux vers les points les plus sensibles.
Niveau applicatif :
Au niveau applicatif, un conseil qui peut sembler évident, mais qui ne l’est pas toujours, est de regarder si les requêtes générées par l’ORM sont correctes et s’il n’y a pas de N+1 (requêtes à base de données exécutées en boucle par l’ORM).
Un autre axe d’amélioration API est de mettre en place du cache (applicatif ou au niveau HTTP) et des mécanismes de debounce: mécanisme permettant de s’assurer qu’un appel est effectué une seule fois par utilisateur pour limiter le nombre d’appels et économiser les ressources.
Niveau fonctionnel :
Les solutions techniques ne permettent pas toujours de résoudre les problèmes de performance.
Une remise en cause de l’UI/UX peut réduire le nombre de clics nécessaires pour réaliser une action (en plus de satisfaire les utilisateurs).
Il peut être pertinent de challenger le métier dès la conception, pour limiter l’impact de règles métiers complexes en les simplifiant.
Exceptionnellement, les critères d'acceptation des features peuvent être revues à la baisse, si l’état de la production le permettait.
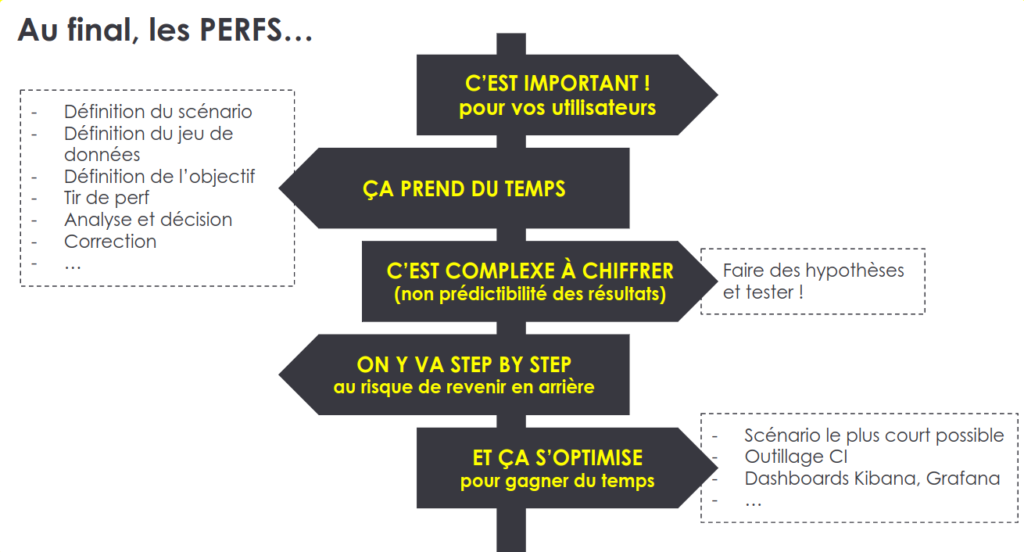
Take away
Suite aux nombreux apprentissages des chantiers menés sur les performances, Jennifer a listé les points suivants à retenir lorsqu'on mène un chantier de perf:
- La performance, est importante pour les utilisateurs et pour le produit
- Cela prend du temps pour reproduire les comportements utilisateurs et pour corriger les problèmes
- La non-prédictibilité des résultats rend le chiffrage complexe
- Il est important de mener les chantiers étape par étape, quitte à revenir en arrière
- Il est possible d’optimiser les chantiers en s’outillant, en cherchant à réduire la boucle de feedback et en identifiant les priorités