360 de la qualité : du build à la mise en production - Ex d'un programme stratégique
Vision, enjeux et cadre initial
En production depuis bientôt un an et demi, ce programme vise à unifier le système d’information pour moderniser la gestion des alertes et des interventions en sécurité et secours. En remplaçant des solutions hétérogènes, il améliore la coordination entre acteurs grâce à une centralisation des applicatifs et une interopérabilité renforcée. L’enjeu en cible : gérer 18 millions d’appels par an, 200 000 agents et près de 5 millions d’interventions sur le terrain.
Ce dispositif intègre des fonctionnalités avancées, telles que :
- La gestion des alertes via la téléphonie et
- La géolocalisation précise des appelants en situation d’urgence.
- La gestion opérationnelle, des applications de compte-rendu de sortie, de planification,
- Ainsi que d'autres outils essentiels pour les équipes sur le terrain.
Nos enjeux sur ce programme:
Comment assurer un delivery performant sur un programme aussi complexe ?
Comment garantir que les déploiements restent un non-sujet, même à grande échelle ? Et comment s’assurer que l’évolution du programme ne dépende jamais de ressources clés, tout en maintenant une continuité optimale ?
En explorant les choix stratégiques et les méthodes mises en place, vous découvrirez comment ces questions trouvent leurs réponses au cœur de notre approche.
Context technique
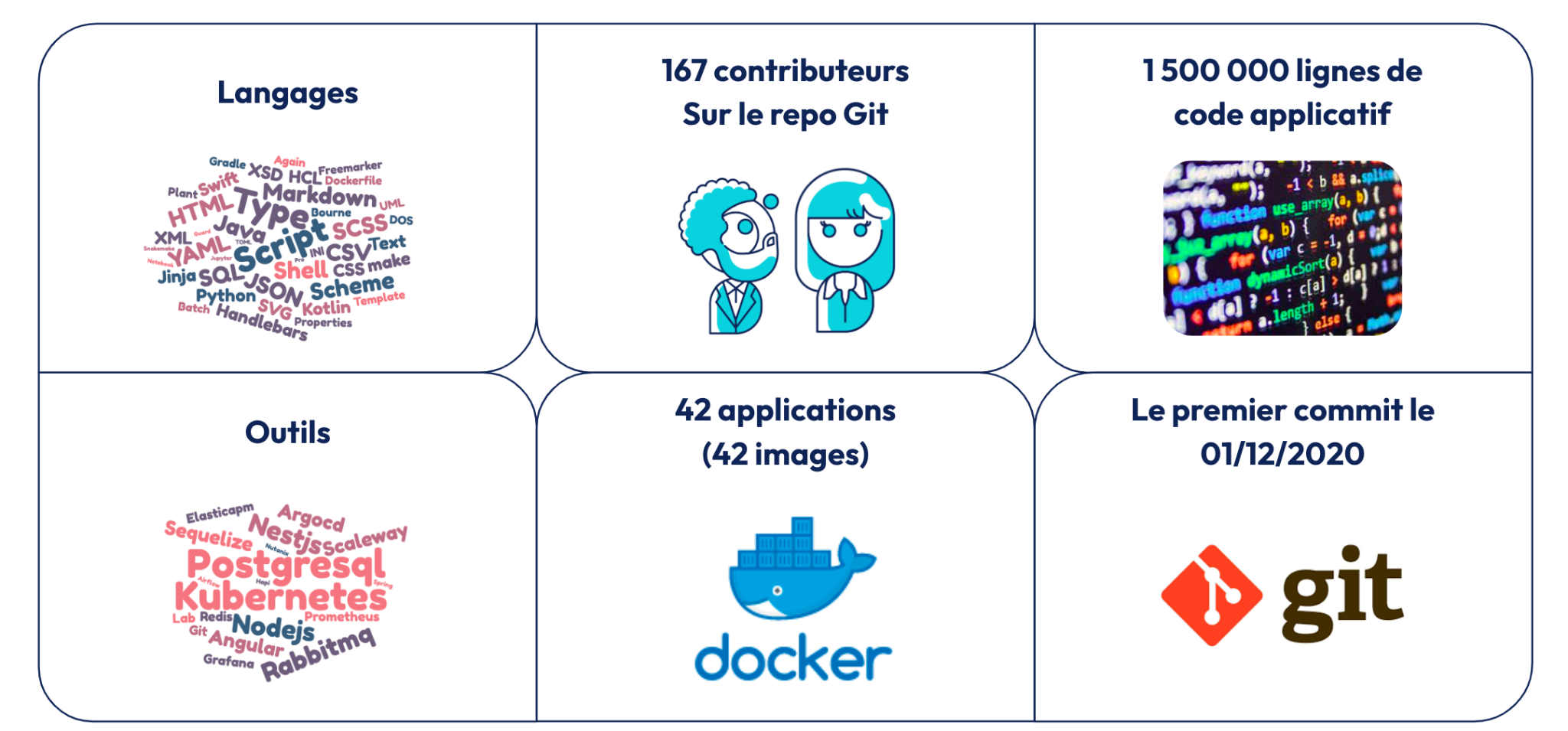
Quelques chiffres:
Environ 167 personnes ont contribué à ce delivery sur une période de cinq ans, aboutissant à la production de 1 500 000 lignes de code dans le principal mono-repo. Ce chiffre n’inclut pas le tooling ni le code d’infrastructure.
Un système conçu pour l’avenir : sécurité, résilience et interopérabilité
Le développement de cette plateforme stratégique a relevé plusieurs défis pour garantir un service fiable, sécurisé et interopérable. Son architecture repose sur un petit nombre d' objectifs et de principes clés :
- Cybersécurité : segmentation stricte avec trois zones de sécurité, surveillance continue des images Docker, détection des comportements anormaux et audits annuels pour anticiper les cyberattaques.
- Résilience : architecture permettant la continuité de service avec des mécanismes comme la réplication des données en temps réel, le découplage des applications et l’orchestration via Kubernetes pour un redéploiement rapide.
- Interopérabilité : intégration fluide avec les systèmes clients, partenaires privés et administrations (Hub Inter-force), ainsi que l’interfaçage avec les hôpitaux pour une gestion efficace des données.
Choix technologiques :
- Cloud souverain avec SCALEWAY et OVH pour garantir l’indépendance des données.
- Communication optimisée via Orange et Xivo pour des échanges sécurisés.
- Auditabilité renforcée pour une transparence totale.
- Messaging pour la communication événementielle inter-applicative, garantissant une coordination fluide et un couplage faible entre les applications.
Ces mesures assurent la performance, la souveraineté et l’adaptabilité de la plateforme.
Les grandes phases du delivery : de la conception à la mise en Production
Le programme s’est déroulé en quatre grandes phases :
1. Phase de Build (4 ans) : Une phase de développement trop longue sans MEP
2. Phase de définition du périmètre, un seul focus : la Première Mise en Production (6 mois)
3. Phase de Stabilisation (6 mois) : Un Travail Technique en Profondeur
4. Phase de Mise en Production (depuis janvier 2024) : Un Équilibre Progressif
Chacune marquée par des défis spécifiques et une évolution du ratio entre l’apport de valeur et les correctifs apportés détaillée ci-dessous.
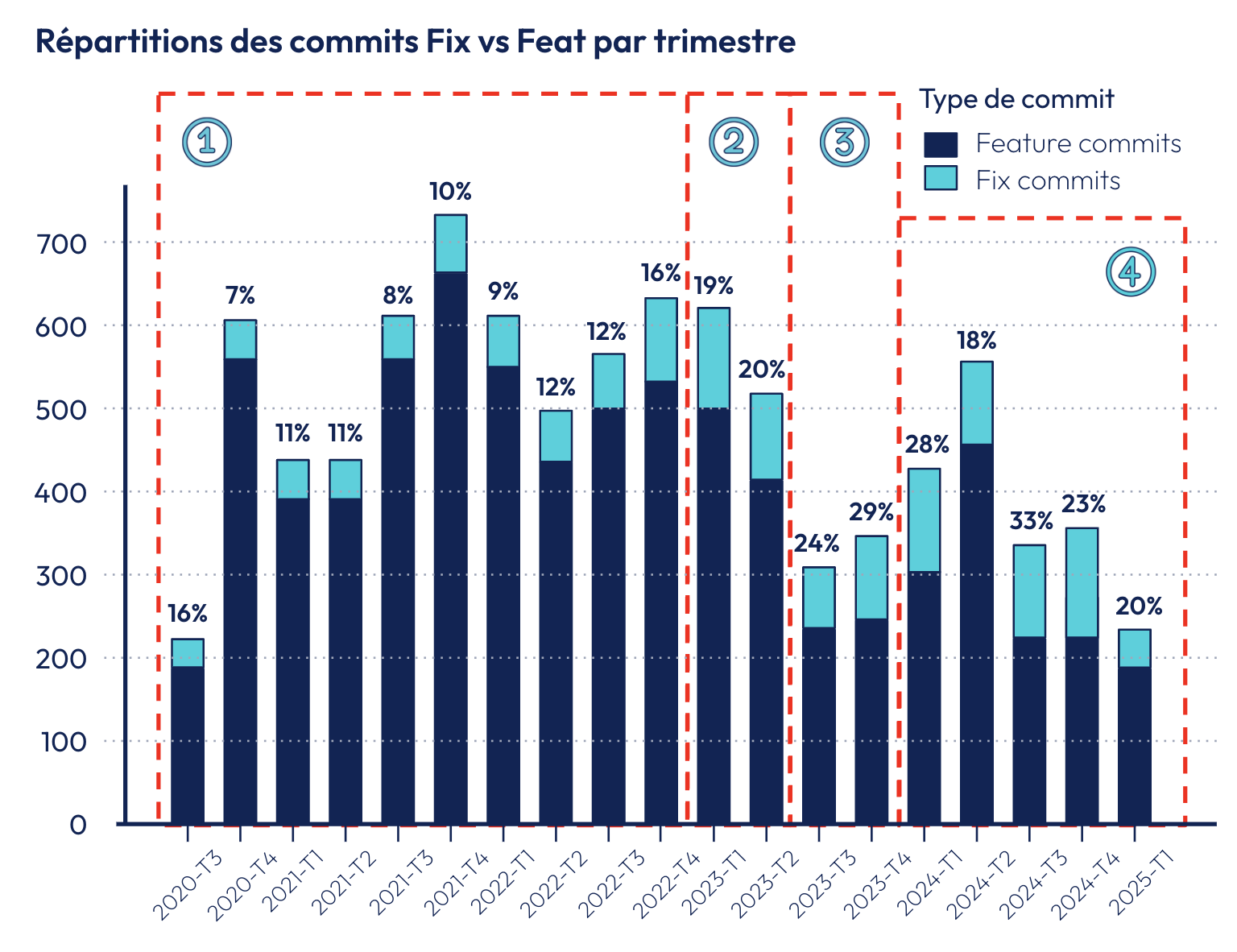
1. Phase de build (4 ans) : Une phase de développement trop longue sans MEP
Cette première phase, souvent considérée comme le péché originel du programme, s’est étalée sur quatre ans. L’une des principales difficultés résidait dans l’absence d’un périmètre minimum clairement défini pour une mise en production anticipée. Cette situation a généré de nombreuses incertitudes quant à la future mise en service.
Malgré ces défis, l’apport de valeur est resté relativement stable, autour de 90%, avec 10% de corrections de bugs. Il est important de noter que ce chiffre reflète les bugs corrigés et non ceux qui ont été identifiés mais non traités immédiatement.
Sur le plan technique, cette phase a permis de poser les bases d’un delivery industrialisé, grâce à une approche DevSecOps rigoureuse. Chaque merge request déclenchait automatiquement le déploiement complet de la plateforme sur un environnement dédié au développeur, garantissant un cycle de feedback rapide et une qualité de livraison continue.
Cette stratégie d’industrialisation s’est traduite concrètement par la mise en place d’un pipeline de déploiement structuré, s’appuyant sur plusieurs environnements techniques dédiés et des cycles de livraison réguliers.
- 6 environnements : 3 QUALIF, 2 REC, 1 DEV
- Déploiements réguliers : une versionver’’sion toutes les deux semaines sur les environnements de pré-production
- Patchs à la demande
Grâce à cette approche, les déploiements n’ont jamais constitué un point de friction dans le programme.
2. Phase de définition du périmètre, un seul focus : la Première Mise en Production (6 mois)
Cette seconde phase a marqué un tournant dans le programme. Nous avons défini le MVP avec pour objectif une première MEP à 6 mois.
Il ne s’agissait plus seulement d’ajouter de nouvelles fonctionnalités, mais de garantir la cohérence fonctionnelle,et aussi de traiter des bugs qui, jusqu’ici, n’étaient pas considérés comme critiques. À l’approche de la mise en production, nous avons appliqué un durcissement des critères d'évaluation des anomalies ce qui a entraîné une augmentation significative du taux de correctifs.
Ainsi, l’apport de valeur est descendu à 80%, tandis que le volume de corrections a augmenté. Cette phase a permis de consolider le produit en identifiant et en corrigeant les éléments indispensables à son bon fonctionnement opérationnel.
3. Phase de Stabilisation (6 mois) : Un travail technique en profondeur
L’objectif principal de cette période était d’améliorer la résilience et la performance de la plateforme en la confrontant aux conditions réelles d’utilisation. Cependant, au-delà de ces aspects techniques, les véritables drivers de cette phase de stabilisation ont été :
- La mise en place et l’épreuve des processus de livraison de correctifs : Il s’agissait d’être capable de réagir rapidement en cas de problème, car après quatre ans de build, il était inévitable que des bugs apparaissent en production, malgré tous les tests réalisés en amont.
- L’optimisation des mécanismes de détection et d’identification des anomalies en production : L’enjeu était de réduire le temps de diagnostic pour éviter tout impact prolongé sur les utilisateurs et assurer une correction rapide et efficace.
Pour atteindre ces objectifs, plusieurs actions techniques majeures ont été mises en place :
- Création d’outils de monitoring avancés, notamment des dashboards et des puits de logs, pour améliorer la supervision en temps réel et permettre une analyse rapide des incidents.
- Optimisation et fiabilisation du code, avec des opérations de refactoring visant à renforcer la maintenabilité et l’efficacité globale de la plateforme.
Cette phase a nécessité un réajustement des priorités, entraînant une baisse temporaire du ratio d’apport de valeur, avec une moyenne de 75% d’évolutions fonctionnelles et 25% de correctifs. Toutefois, elle a permis d’assurer une préparation optimale pour les futures mises en production, garantissant une capacité à livrer rapidement et efficacement des correctifs en cas de besoin.
Nb: Les évolutions fonctionnelles ont principalement concerné l’expérience utilisateur (UX), avec l’ajout de filtres, de nouvelles données affichées et d’autres optimisations d’interface.
4. phase de mise en production (depuis janvier 2024) : Un équilibre progressif
Depuis son déploiement, la plateforme a connu une période d’ajustement progressive. Lors des six premiers mois, l’apport de valeur a légèrement chuté à 70%, le temps d’optimiser l’environnement de production et de traiter les retours initiaux des utilisateurs. Par la suite, il est remonté à 80%, traduisant une meilleure stabilité et une capacité à intégrer de nouvelles améliorations plus efficacement.
Un apport de valeur constant tout au long du programme
Malgré les différentes phases et les défis rencontrés, une constante se dégage :
L’apport de valeur est resté élevé et soutenu tout au long du programme.
Si certaines périodes ont nécessité une plus grande attention sur la stabilisation et la correction, l’évolution globale montre une trajectoire maîtrisée et une adaptation efficace aux exigences du terrain.
Ce découpage met en évidence la maturité progressive du programme et l’importance d’une approche structurée, combinant innovation, rigueur technique et anticipation des besoins opérationnels.
Les avantages de la qualité du code sur le long terme.
Un apport de valeur constant malgré l’évolution du système
Les choix d’architecture et l’effort consacré à la qualité ont porté leurs fruits lors de la mise en production, notamment lorsqu’un de nos clients majeurs a exprimé le besoin d’ajouter de nouvelles applications et fonctionnalités impactant l’ensemble du système.
Dès l’ouverture en production, le développement des nouvelles fonctionnalités et des nouvelles applications a pu démarrer en parallèle de la mise en service de la plateforme, en s’appuyant sur une architecture flexible et une approche Feature Flipping.
Grâce à cette organisation et à la robustesse de l’architecture, nous avons pu assurer simultanément la mise en production et le développement d’un module impactant l’ensemble des applications, tout en maintenant un apport de valeur constant.
Ces éléments confirment la pertinence des choix technologiques effectués dès le départ et démontrent la capacité du système à évoluer sans rupture, garantissant ainsi sa pérennité et son efficacité.
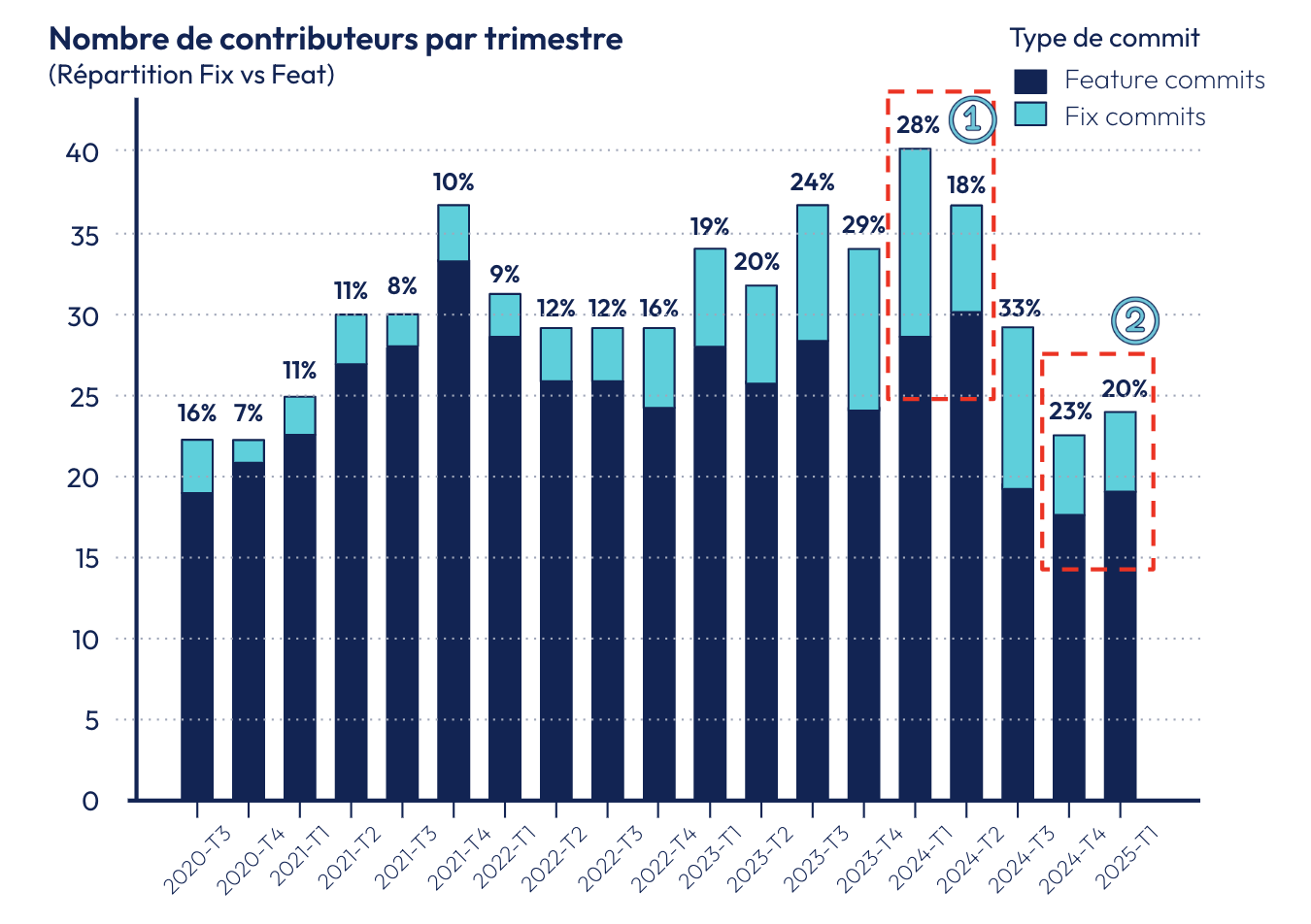
Optimisation des effectifs et maintien de la production
Afin d’assurer une évolution continue tout en maîtrisant les coûts, l’équipe programme a été redimensionnée, passant de 40 à 23 personnes. Ce destaffing progressif a permis de garantir à la fois :
- La maintenance et l’exploitation de la plateforme en production,
- La poursuite du développement de nouvelles fonctionnalités critiques.
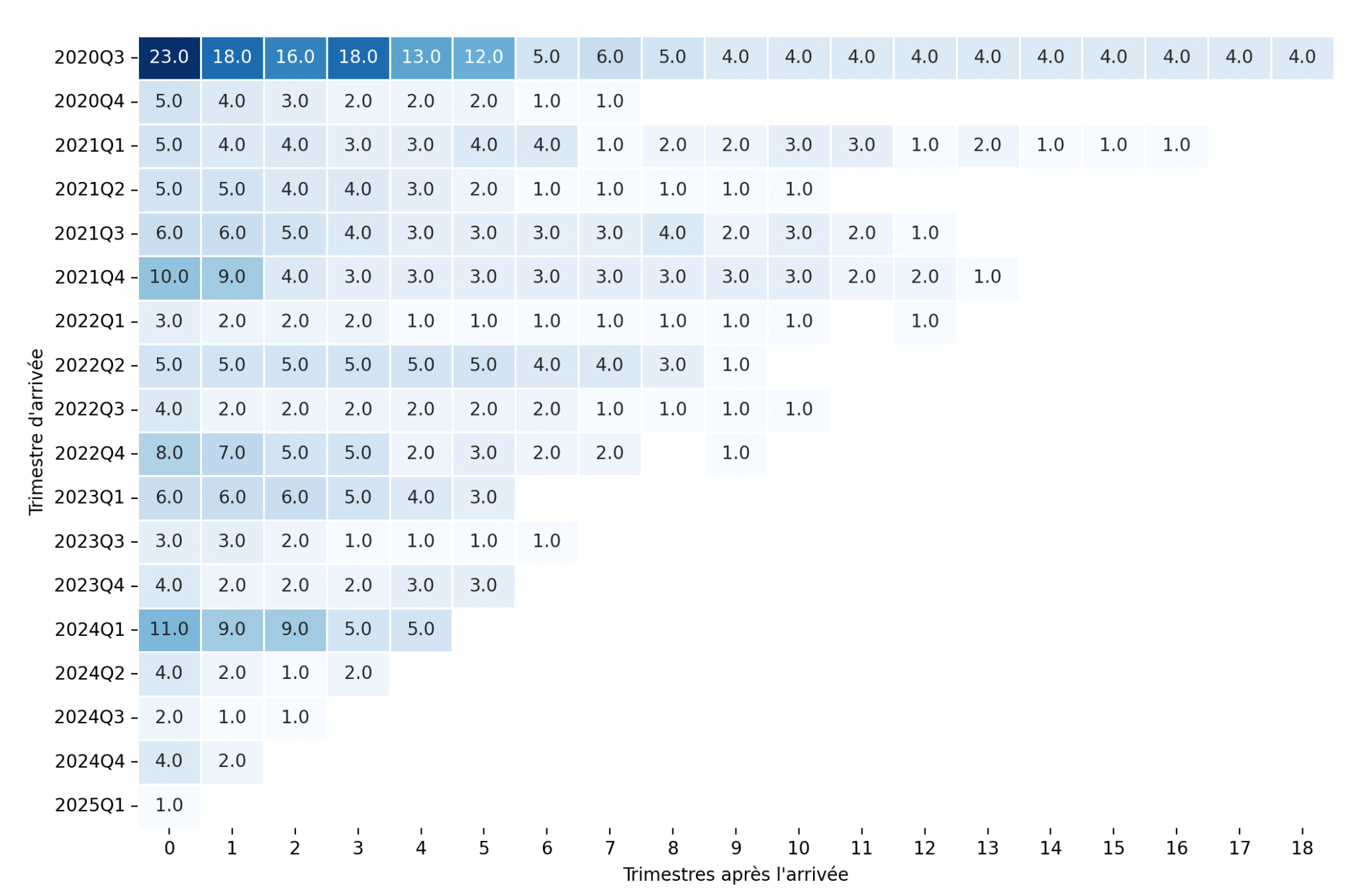
La réversibilité adressée dès le début
L’analyse des cohortes met en évidence la dynamique des effectifs tout au long du programme. La première colonne illustre le nombre de nouveaux développeurs intégrés au début de chaque période, tandis que les colonnes suivantes indiquent le nombre de développeurs restant sur la période suivante (N+1).
Cette rotation des effectifs, propre aux ESN et à l’expertise ponctuelle du programme, met en évidence deux éléments clés, en plus des fondamentaux comme le DDD, TDD et les pratiques craft :
- L’indépendance du programme vis-à-vis des personnes critiques : Aucune dépendance excessive à un individu ou à un groupe restreint n’a été constatée.
- La fluidité du processus d’onboarding : L’intégration rapide des nouvelles recrues a permis de maintenir la continuité du programme sans perte significative d’efficacité.
Depuis le début du programme, seuls quatre collaborateurs sont encore présents, et l’ancienneté médiane des développeurs est d’un an et demi. Ces chiffres attestent de la réversibilité du programme, qui a été éprouvée tout au long de sa réalisation, garantissant ainsi sa capacité à évoluer indépendamment des fluctuations des effectifs.
La qualité du code reste la pierre angulaire de la réversibilité, mais elle a été renforcée par plusieurs leviers :
- Des rituels de Tech Lead, favorisant l’alignement des conventions et la cohérence technique du programme.
- L’utilisation d’un mono-repo, qui facilite la visibilité sur le code des autres équipes et encourage le mimétisme des bonnes pratiques d’une application à l’autre.
Organisation :
Plusieurs formes d’organisation ont été testées pour finalement converger vers une organisation créée selon plusieurs principes:
- Alliance stratégique et opérationnelle : Associer une vision pérenne du domaine à une approche tactique au niveau des équipes.
- Engagement sur le cycle de vie : Appliquer le principe We build it, we run it en garantissant un support de niveau 3 par les équipes de BUILD.
- Efficience et optimisation : Réduire le nombre de strate de management pour permettre un impact direct des utilisateurs et de nos clients, avec implication sur la priorisation du delivery et aussi réduire les coûts marginaux et limiter l’encadrement superflu.
- Synergie BUILD/RUN : Renforcer le lien entre les phases de déploiement et les équipes opérationnelles grâce à un partage quotidien des problématiques.
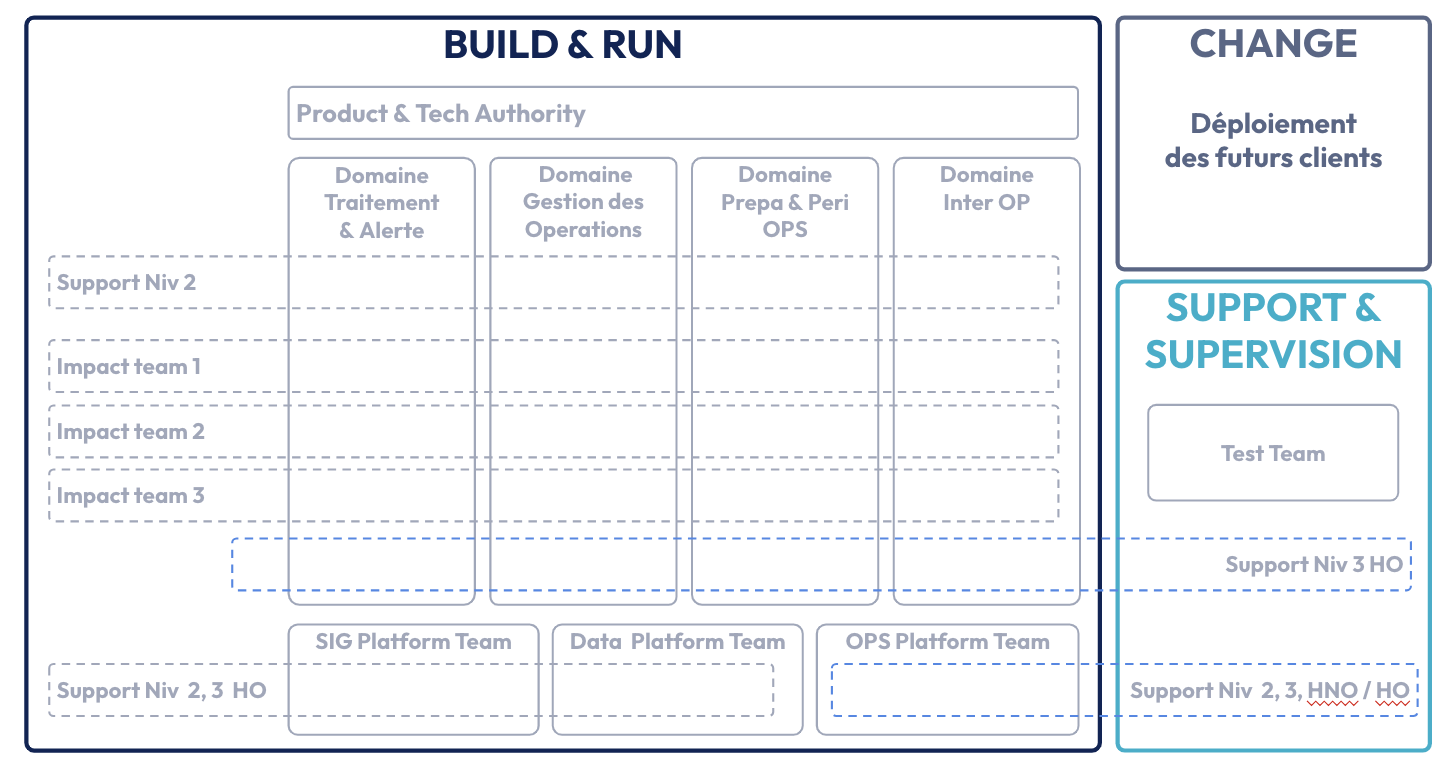
Cette organisation permet de piloter une équipe d’environ 40 personnes, tout en assurant la maintenance en condition opérationnelle des domaines métier et en menant des programme transverses à moindre coût.
Elle repose sur un maximum de trois Impact teams, chacune ayant une durée limitée à six mois.
Sa principale force réside dans la synergie entre les équipes OCTO et celles du client, fédérées autour d’un objectif commun.