3 jours à QCon London 2014
QCon London 2014 a rassemblé la semaine passée plusieurs centaines de participants et plus de 100 speakers pour 3 jours de conférences. Nous n'étions que 3 pour 5 tracks en parallèle, impossible de tout suivre, mais voici ce que nous avons retenu.
HTML5 et Mobile : l'heure des frameworks
Lors de sa keynote, "Does the browser has a future?", le premier jour, Tim Bray nous a dressé un avenir en demi-teinte. En 1997 déjà, Wired magazine titrait sur la mort du navigateur, et pourtant aujourd'hui, il est toujours là et plébiscité par les utilisateurs. Les navigateurs apportent de très bonnes choses (HTML, HTTP) mais aussi de très mauvaises (CSS, JavaScript et le modèle du DOM). Aujourd'hui le modèle DOM et JavaScript fonctionnent côté navigateur, car il y a peu de choses à contrôler. Mais le nombre de devices mobiles explose avec toujours plus de capteurs, et demain un avenir avec réalité augmentée. Par exemple avec le Project Tango, Google veut donner au mobile une sensibilité de capteur permettant de donner aux applications la même sensation d'espace et de mouvement que l'être humain. Étonnamment, les jeux mobiles multiplateformes sont aujourd'hui écrits en C++ et non en HTML5. Alors pas d'avenir pour le navigateur ? Il faut rester modeste, des technologies comme PHP ont permis de réaliser des outils fantastiques comme Wikipedia et Facebook. Je retiendrai que pour l'instant, de nombreux frameworks viennent contrebalancer les manques du navigateur.
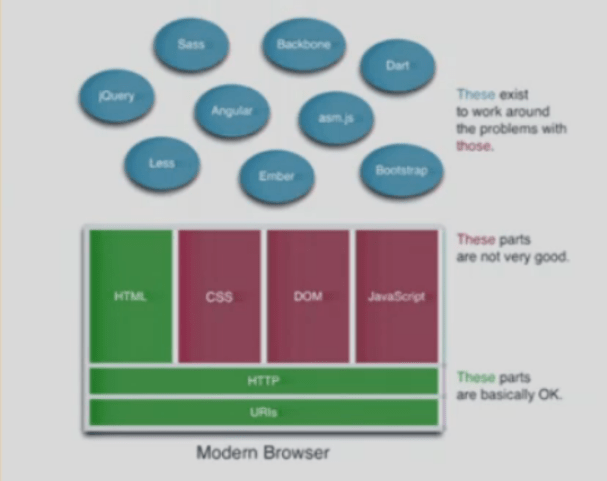
REST et Micro-services
Les architectures REST sont également bien implantées et ont fait l'objet de retours d'expérience. Brandon Byars de chez ThoughWorks nous a présenté une réécriture d'un système Télécom dans une architecture REST. Celle-ci est très efficace pour gérer la complexité en la divisant en nombreux contextes spécialisés et isolés. Mais l'intégration reste en REST comme avec d'autres architectures une source de complexité. La première des règles est de retarder autant que possible l’existence de versions incompatibles. De plus il est important de séparer les tests fonctionnels des tests d'intégration - qui doivent donc être des tests à part entière. Enfin, il faut fournir au développeur des environnements qu'il maîtrise et des bouchons pour l'ensemble du système afin qu'il puisse systématiquement tester sans avoir l'intégralité du système sur son poste. Dernière recommandation, la loi de Postel encourage à écrire des services tolérants aux écarts par rapport au contrat. Cela est tout à fait dans la philosophie de REST à condition de paramétrer certains frameworks qui fonctionnent avec une philosophie code first.
Devops et Agile
Parvenir à un système de déploiement continu qui permet de faire plusieurs dizaines de déploiements dans la même journée sans douleur est aujourd'hui un des objectifs majeurs de Devops. Différents acteurs y sont parvenus, avec différentes méthodes.
Tout d'abord, ce qui tourne sur le poste du développeur doit être exactement la même chose que ce qui va tourner en production. Groupon atteint cet objectif en découpant son application en une multitude de petites applications nodejs (une quinzaine de fichiers maximum) qui peuvent être lancées en isolation, et donc tourner en local dans leur intégralité. Etsy, de son côté, fournit à ses employés des VM packagées avec les recettes Chef qui vont bien pour que chacun puisse lancer une copie conforme de l'intégralité de l'application de production directement en local. Ainsi, pas de surprise, et plus d'excuse de "Chez moi ça marche, maintenant c'est le problème des Ops".
La seconde est présentée par Dave Farley qui a mis en oeuvre le continous delivery chez LMAX : une start-up qui fournit des services d'échanges à faible latence dans les services financiers. Sa méthode repose sur l'automatisation de quasiment tout pour éviter toute manipulation humaine, l'utilisation systématique du contrôle de source de façon à pouvoir reconstruire complètement un datacenter et l'accélération des cycles de livraison. "If it hurts, do it more often - bring the pain forward". Cette approche est nécessairement couplée à une approche de qualité avec une batterie de tests, automatisés pour la répétition et manuel pour utiliser la créativité des testeurs. Au final : 45 minutes seulement pour déployer en cas d'urgence. Aller vers le déploiement continu c'est mettre réellement en oeuvre l'un des principes de l'agile et cela fait changer de façon de travailler.
Tous ces acteurs ont aussi mis au point des outils internes qui leur permettent de simplifier leurs déploiements. Chez Etsy par exemple, chacun peut déployer en un clic grâce à un outil qui se charge de lancer les tests (en parallèle sur un pool d'environ 400 instances Jenkins tournant dans des containers Docker sur disque SSD), et de synchroniser la nouvelle application sur tous leurs serveurs. Un déploiement complet prend en moyenne 15 minutes chez eux.
L'obsession de la mesure se retrouvait aussi chez tous ces acteurs qui possèdent des pages entières de dashboard pour monitorer tout ce qu'il se passe, depuis la RAM, le CPU au nombre de login, logout, erreurs 404, etc. Ainsi, dès qu'une courbe semble sortir de l'ordinaire, on peut rapidement la lier au déploiement qui a dû la causer. Le point important sur lequel plusieurs speakers ont insisté était que ces dashboards doivent être accessibles par absolument tout le monde dans l'organisation. Dès que quelqu'un développe une feature, il doit avoir accès aux métriques qui y correspondent en production, car il sera le plus à même de comprendre les implications.
Tolérance aux pannes
Lorsqu'il s'agit de concevoir des systèmes tolérants, rien n'est jamais évident. Joe Armstrong, un des pères d'Erlang - un langage résilient par nature - nous démontre ainsi que la scalabilité d’un système est fortement corrélée à sa tolérance à la panne. Difficiles (voir parfois impossibles) à prédire, ces pannes peuvent venir de n'importe quel composant logiciel ou matériel et ce à n'importe quel moment. Le système dit résilient doit alors détecter, corriger et stopper la propagation de cette panne de manière automatique. Plusieurs choix s'offrent à nous : masquer la panne, réessayer ou « let it crash ». Joe nous met également en garde contre l'illusion du code défensif, faisant peut-être du sens dans des languages basés sur une stack (programmation séquentielle), mais pas forcément nécessaire sur des langages Acteur par exemple, ou les autres acteurs seront forcément notifier en cas de crash d'un des leurs.
Uwe Friedrichsen nous rappelle que la priorité majeure en production est de garantir la disponibilité de ses applications (sinon pas de business). Il nous présente ainsi quelques patterns simples et faciles à mettre en oeuvre pour concevoir des programmes tolérants aux pannes : « circuit breaker », « fail fast », « shed load » ou encore « deferrable work » (pour en apprendre d'autres, lisez Distributed systems: Principles and Paradigms de Andrew S. Tanenbaum). Il faut également investir dans la supervision, faire en sorte de pouvoir modifier à chaud ces gardes-fous ce qui permet de diminuer les temps de réaction en cas de problème sur un système (on peut aller jusqu'à automatiser du failover).
Pour gérer la résilience, mieux vaut réviser ses fondamentaux. Andy Piper nous montrait ainsi que tout algorithme de communication fiable, sur un réseau par définition non fiable, est une affaire de compromis. Michael T. Nygard a bien illustré ce propos à travers de nombreuses échappatoires possibles au théorème de CAP. Non que celui-ci soit faux, mais que rare sont les cas d'utilisations où la définition exacte de la cohérence et de la disponibilité du théorème sont nécessaires. Ainsi le système spanner en production chez Google ne respecte pas la cohérence de l'historique des modifications sur chaque noeud, mais fournit un timestamp par horloge GPS a chaque modification pour pouvoir les ordonner. La maîtrise intime des définitions est donc indispensable pour choisir la meilleure résilience possible pour un système.
Big Data & NoSQL
Comme chacun sait, NoSQL est un écosystème très vivant : tous les produits du marché, et notamment les solutions Open Source, introduisent à chaque release de nouvelles features, permettant d'optimiser l'existant et de résoudre de nouveaux problèmes.
* La version 2.0 de Cassandra a apporté son lot de nouveautés, et notamment le native protocol. Johnny Miller (Datastax) nous présente les nouveautés du Driver Java natif, et notamment la possibilité de définir des stratégies sur retry d'une requête, la reconnection ou encore le routage vers des coordinateurs possédant les données.
* Joel Jacobson (Basho) nous explique tous les bienfaits apportés par les CRDTs (Convergent/Communtative Replicated Data Types, basé sur des travaux de l'INRIA) introduits dans la version 2.0 de Riak (release courant mars) : Counters, Set, Map, Registers and Flags.
Plus généralement, de nombreux talks ont remis les points sur les i en ce qui concerne Big Data et ses enjeux :
* Mark Harwood (elasticsearch) nous rappelle que l'utilisation de données massives nécessite forcément une phase d'exploration pour en tirer le meilleur. Au travers de différents use case (analyse des crimes et délits à Londres, d'une BDD de films ou encore de l'analyse de fraude bancaire), Mark montre à quel point elasticsearch est pertinent pour explorer ces données, notamment grâce aux agrégations(introduits dans la v1.0) telle que significant_terms qui permet de mettre en évidence les termes les plus significatifs et non pas les plus fréquents comme on avait l'habitude de voir jusqu'à présent.
* Akmal B. Chaudhri (Hortonworks) présente comment Hadoop 2 répond toujours mieux aux 3V's (Variety, Volume et Velocity), notamment grâce à l'arrivée de YARN comme couche de partage et médiation des ressources du cluster. De nombreux frameworks, tels que Pig, Hive (Stinger) ou Tez, vont directement en bénéficier. Qui plus est, une gateway (Knox) fait son apparition pour isoler un cluster Hadoop et sécuriser les accès.
* Nathan Marz (Twitter) nous explique de manière élégante les architectures lambda, fondées sur l'immutabilité et où chaque requête peut être considérée comme une fonction sur la totalité des données (historique + temps réel). Ce type d'architecture sur deux couches : "batch" pour le stockage de l'historique et la construction de precomputed views; "speed" pour l'ingestion des données temps réelles et la construction d'incremental views. (son livre est en EAP).
Cloud next generation
Docker était la principale nouveauté technologique cette année dans le monde du cloud et Chris Swan en a fait une présentation sans surprise. Derek Collison a été plus visionnaire en considérant qu'aujourd'hui les systèmes de cloud computing manquent d'une vision intégrée pour le monitoring, la supervision. L'avenir verra probablement émerger l'équivalent de systèmes d'exploitation pour le cloud. Serait-ce l'avenir du cloud privé ? Netflix enfin a longuement détaillé les différents outils qu'ils mettent en oeuvre pour opérer l'intégralité de leur système sur Amazon Web Services : des outils de monitoring, de déploiement, utilisables par tous les développeurs. Cette session à mi-chemin entre la résilience, le cloud et devops montre bien leur philosophie radicalement différente de nos habitudes. Netflix préfère en effet réagir aux erreurs du système, déclencher des erreurs en production volontairement pour être mieux capable d'y réagir plutôt qu'investir en amont. À leur niveau de charge les erreurs sont quasi certaines. Ils déploient donc des outils comme chaos monkey pour débrancher volontairement des serveurs en production entre 9h. et 18h. Tout le monde est là pour corriger et apprendre ce qui rend plus fort pour réagir lorsqu'un problème survient en plein milieu de la nuit.
Java et programmation réactive
À deux semaines du lancement de Java 8 Simons Ritter est venu nous présenter comment les lambdas sont intégrés dans le framework. Une modification pas si minime du langage, un bon en avant dans le domaine fonctionnel et réactif. Sur ce point Node.JS était omniprésent dans les sessions technologiques mais j'aurais aimé plus de retour d'expérience. Aujourd'hui cependant Node.JS est une référence. Le nouveau moteur JavaScript Nashorn sur la JVM proposera une couche de compatiblité qui le rendra compatible avec 95% des applications Node.JS (manqueront les API natives de chrome V8). Oracle a voulu aller plus loin avec le projet Avatar qui fournit une véritable API JS au dessus de JEE et une API client. J'avoue resté sceptique hors du besoin d'intégration. D'autres solutions sont explorées, par exemple Vert.x avec son modèle à mi-chemin entre node.js et des acteurs. Beaucoup de technologies qui permettent donc de changer de paradigme. Car il y a clairement un enjeu autour de travailler sur des flux, de travailler en asynchrone depuis le driver. Martin Thompson, CTO chez LMAX en convenant également. Mais comment le faire concrètement? Un exemple de Rx pour concevoir un jeu vidéo en réactive c'est bien, mais assez éloigné de mes projets. Allard Buijze, créateur de Axon framework tenait le même discours, mais avec un exemple beaucoup plus appliqué à l'informatique de gestion. En effet, Axon fournit les mécanismes de base pour implémenter une architecture CQRS. Celle-ci permet à la fois de dépasser le découpage en couche pour tirer profit d'une architecture réactive tout en étant compatible avec les principes du Domain Driven Design pour gérer la complexité. 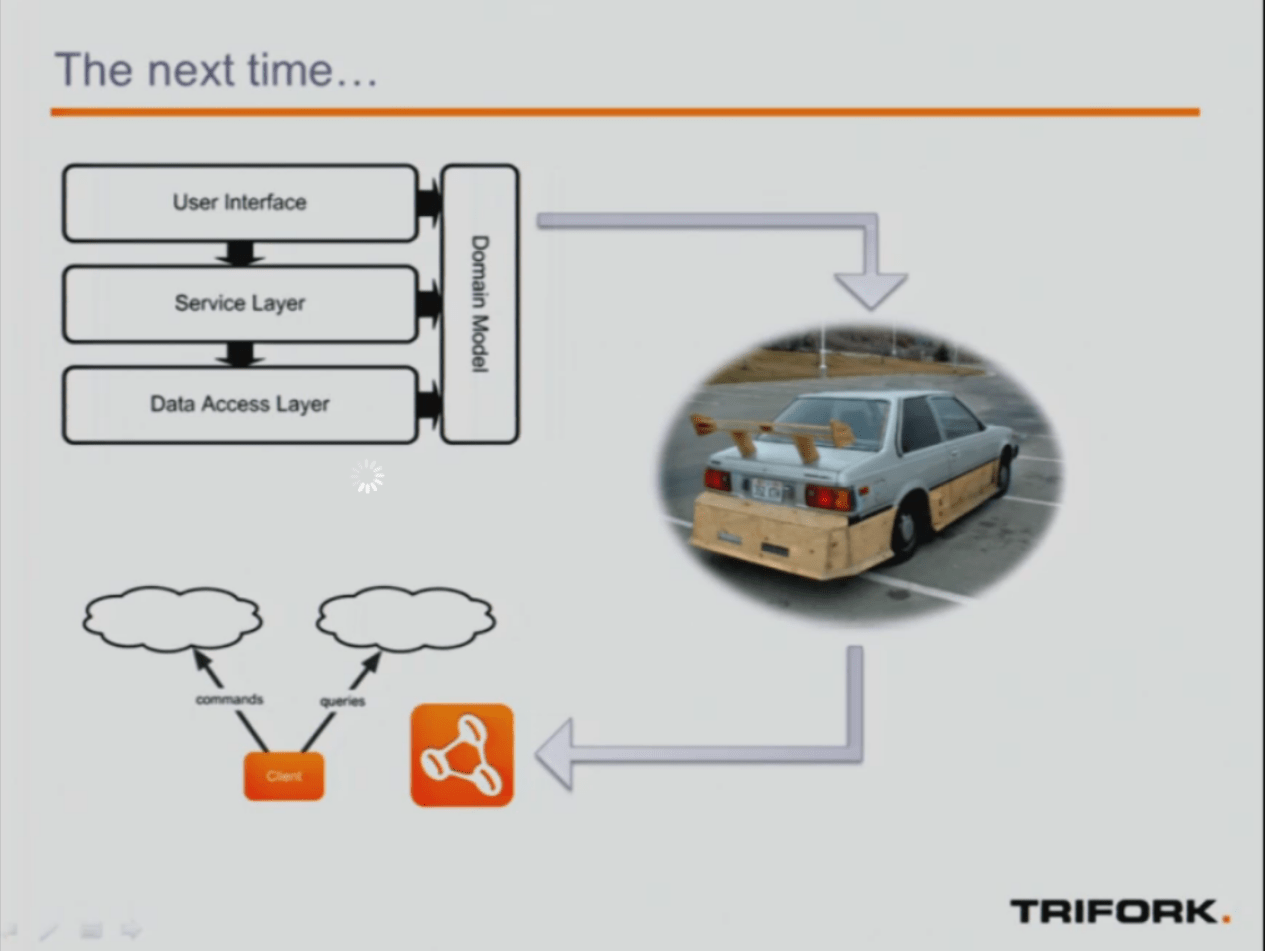
Retour aux fondamentaux
De nombreux algorithmes permettent de résoudre les problèmes induits par les gros ensembles de données. Adrian Colyer (Pivotal) nous explique ainsi en quoi les Bloom Filters sont indispensables lorsqu'il s'agit de savoir si un élément est présent ou non dans un dataset volumineux ou encore en quoi HyperLogLog permet d'estimer le nombre d'éléments uniques dans ces mêmes datasets. Pour les plus curieux, jetez un oeil à stream-lib.
Un dernier message : en informatique certains sujets sont très pointus et il faut ne jamais l'oublier. Les float avec les problèmes d'optimisations, les bibliothèques de chiffrement sans défaut, les libraries mathématiques où la startup OpenGamma expliquait qu'ils préféraient intégrer des librairies mathématiques reconnues en C plutôt que de les porter en Java au coeur de leur plateforme. Lorsqu'on veut faire fonctionner avec précision ces sujets, les anciennes recettes sont toujours les meilleures : des tests et le partage du savoir.
Que retenir? DevOps et Big Data sont définitivement rentrés en production avec de nombreux retours d'expérience. Le Reactive Programming était le sujet en vogue du moment, mais nous attendons encore les premiers retours d'expérience. HTML5 était finalement au milieu de ces deux mondes, en progressant doucement vers une certaine maturité.