Votre premier projet Hadoop
Avec les approches BigData, et plus précisément grâce à une plateforme Hadoop, vous allez enfin avoir la possibilité d'extraire l'information de ces dizaines de téra-octets que vous stockez dans votre infocentre. Et mieux : commencer à vous intéresser à des données moins structurées, qu'elles soient internes (des weblogs par exemple), ou externes (réseaux sociaux, partenaires), pour en apprendre encore plus sur votre business.
Les technologies comme Hadoop sont un vrai changement de paradigme par rapport à ce que nous avons traditionnellement dans nos SI. Un projet Hadoop s'inscrit clairement dans une démarche d'innovation : il y a une courbe d'apprentissage, et cela nécessite une conduite projet spécifique. Du cadrage à l'organisation projet, en passant par le tuning : c'est ce que nous allons voir dans cet article.
Au fait : Vous êtes sûr d'avoir besoin d'Hadoop ?
Hadoop a 3 grandes caractéristiques :
- il garantit la disponibilité et la durabilité des données, par réplication. C'est une approche logicielle à contre-courant des solutions matérielles traditionnelles (RAID, SAN, …)
- il garantit une scalabilité linéaire des capacités de stockage et de traitement par simple ajout de machine. Stockage et traitement sont distribués et co-localisés
- il apporte une capacité à traiter des données peu ou pas structurées
Ni plus, ni moins. Ce n'est pas un remplacement à une technologie SGBDR, ni une solution dont la performance pure par processeur et par unité de temps dépasse d'autres technologies. There is no magic.
Ce n'est pas non plus, à l'heure actuelle, une solution pour bâtir un reporting qui répond en temps-réèl, ou en temps court, à vos requêtes sur de gros volumes. Ce point pourrait évoluer prochainement, avec Impala, mais le projet n'est pas encore suffisamment mâture pour un POC dans une DSI.
Hadoop n'est pas adapté aux "small big-data". Il est clairement contre-productif d'essayer d'utiliser Hadoop si vous avez moins de 20To de données à traiter, ou d'installer un cluster de moins de 5 datanodes.
Votre besoin Hadoop est qualifié ? Vous n'avez pas survendu la technologie à votre management ou à vos clients internes ? Alors, c'est parti.
![]()
Le cadrage
Votre projet doit impérativement commencer par un cadrage, et ce avant même de commander le matériel.
En effet, même si on parle de commodity hardware, la configuration standard d'un datanode par exemple n'est pas habituelle : 4 CPU multicore, 64 GB RAM, plusieurs disques en JBOD, multiple attachement réseau. De même, la configuration des racks et le dimensionnement des switchs doivent être préparés soigneusement.
Les fournisseurs hardware habituels commencent à se doter d'offres "Hadoop ready" et proposent ce genre de configurations. Ca n'empêche pas de les challenger un peu.
Durant ce cadrage, il vous faudra définir les sources de données à collecter et à explorer, et commencer à raffiner les questions métiers auxquelles vous cherchez à répondre.
D'une part, vous obtiendrez des éléments structurants pour le dimensionnement. Votre traitement est-il I/O bound ? CPU bound ? Quels volumes de données vont être manipulés ? Vous vous ferez une idée des temps de traitements (même distribués, vos traitements sur 20To prendront beaucoup de temps), et vous aurez une première idée des éléments de configuration, ce qui est très utile étant donné leurs interdépendances. L'illustration ci-dessous montre ces dépendances entre dimensionnement, typologie d'utilisation du cluster, et quelques-uns des paramétrages du cluster (cf également l'article Comment dimensionner un cluster)
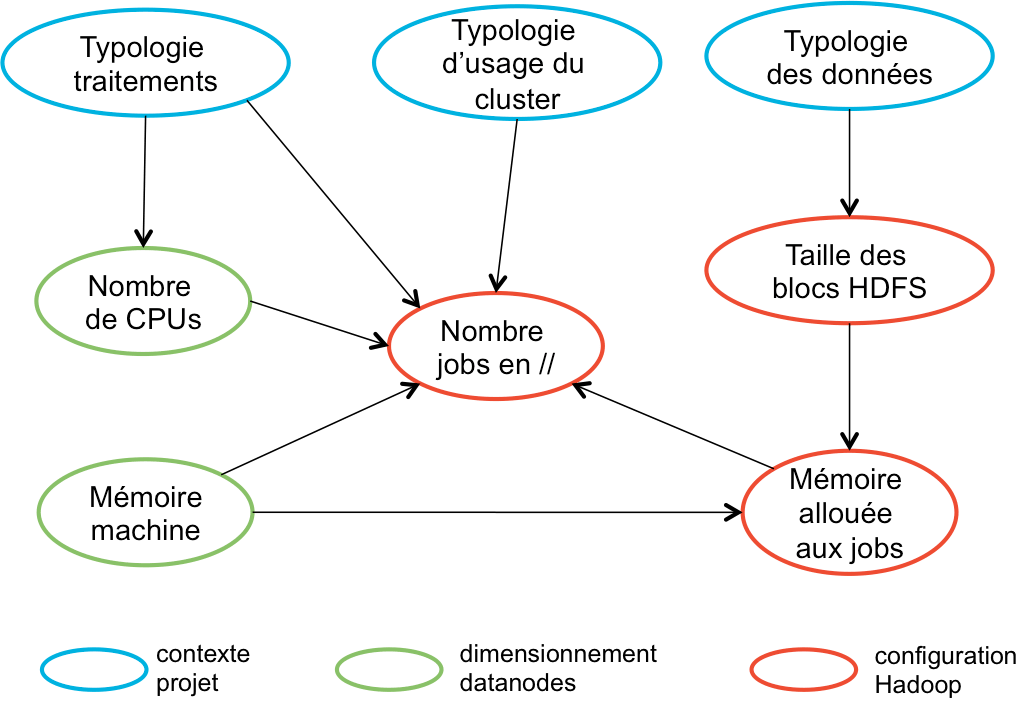
D'autre part, ces éléments issus du cadrage vous permettront de pré-selectionner les composants techniques à utiliser dans le très vaste écosystème Hadoop :
- integration au SI par Flume, Sqoop ... ou par un ETL habituel
- traitement et requêtage des données en Hive, PIG, hadoop-streaming
- analyses avancées : Mahout, Hama, Giraph...
- les algorithmes pressentis
- les moyens de supervision : ganglia ou autre
- les outils d'ordonnancement et de workflow
- utilisation de HBase
Réception du cluster
Une fois vos machines installées (ce qui nécessite des compétences spécifiques, j'y reviendrai), une phase à ne pas négliger est la recette de cette installation.
Les services Hadoop de base et tous les composants cités ci-dessus doivent être installés, configurés, lancés, être visibles dans les interfaces de management, accessibles des développeurs (avec les comptes associés), et unitairement testés ("hello world" sur chaque).
D'ailleurs, vous pouvez, pourquoi pas, envisager une approche 'Test Driven Infrastructure' pour cette recette.
Un benchmark du cluster pour constater son comportement en charge est également essentiel. La quantité de paramètres de configuration est telle qu'il faut vérifier que les jobs ne planteront pas à cause d'un sous-dimensionnement mémoire par exemple, ou que l'ensemble du cluster n'est pas sous-performant pour une raison X ou Y. Cf l'article Benchmarker son cluster
Qualité des données
Comme dans tout projet "data", la question de la qualité des données doit être adressée. En terme de contenu, plus ou moins valide, et en terme de format également, beaucoup moins structuré que ce qu'on a l'habitude de manipuler dans un projet data-warehouse avec ses tables et ses colonnes bien définies.
Les outils sur Hadoop sont pensés en ce sens, et sont très tolérants. Ainsi, Hive est construit sur le paradigme "schema-on-read" : les données sont stockées de façon brute, et c'est à la lecture qu'on va interpréter telle donnée comme une colonne d'une table. Hive est capable de gérer des données hétérogènes au sein d'une même table (ex : pas le même nombre de colonnes tout au long de vos données), et considère comme NULL tout ce qu'il ne peut interpréter.
Il n'empêche. Si une donnée fausse vos traitements, elle est juste noyée dans des dizaines de téra-octets... Et le job hadoop-streaming que vous développerez de façon ad-hoc pour aller la corriger prendra plusieurs heures à s'exécuter.
Ainsi les phases de nettoyage, de préparation des données, d'aggrégations préliminaires, peuvent représenter jusqu'à 80% du temps de votre projet ! Les phases d'analyses sophistiquées ne viennent qu'ensuite.
Tuning
Un cluster Hadoop est un environnement contraint en taille. Je vous entends d'ici : "Comment ça contraint ? Avec une quinzaine de machines à 64GB de RAM, 24 cores, et des dizaines de disques de 3To ?". Oui, contraint.
Exemple : votre dataset remplit le cluster à 50% ? Impossible d'en faire une copie, ou de stocker le résultat d'un job de pre-traitement des données qui produirait un volume équivalent. Vos traitements devront travailler sur la donnée brute, ou bien vous devrez prévoir cette transformation au fil de l'eau lors du chargement des données.
De même, votre objectif est d'utiliser votre capacité de traitement au max, donc tous vos CPUs (ou toutes les I/O). Les machines seront dans le rouge en permanence, et si elles ne le sont pas, vous augmenterez le nombre de tâches lancées en parallèle. Sauf si, ce faisant, vous explosez la mémoire disponible...
Bref, vous allez passer votre temps à jouer avec les limites des capacités de votre cluster. Ne négligez pas les phases de tuning dans votre projet, vous allez y passer beaucoup de temps, surtout pour les premières versions de vos traitements.
Prévoyez des itérations d'optimisation : adaptations des traitements, et tuning du cluster. Les jobs devront être refactorés et adaptés quand vous aurez mesuré comment ils se comportent. Le cluster pourra être tuné, mais à la marge, pour grapiller 10-20% de performance supplémentaire, et seulement si ce tuning n'est pas contre-productif pour un autre traitement. En un mot, c'est à votre traitement de s'adapter aux contraintes d'infra (et non l'inverse).
Le debugging des jobs est particulièrement fastidieux. Les outils d'assistance au debug sont encore relativement pauvres dans l'écosystème. Trouver les données incorrectes qui font crasher votre traitement dans les 20To du dataset est plutôt ... pénible. Inspecter les traces java des jobs Map/Reduce, pas tellement plus fun. Bref, là aussi, vous allez y passer du temps.
Organisation du projet
Je ne pense pas que vous trouverez sur ce blog d'autres recommandations que faire de l'Agile :-)
Je ne rentrerai pas dans la question de la méthode (Scrum, Kanban...), mais il y a des pratiques absolument incontournables, au risque de vraiment planter votre projet :
- colocalisation : un plateau projet qui rassemble toutes les compétences
- métier, pour affiner les questions biz et les analyses à faire sur les données
- architecte, pour définir les logiques des traitements (par exemple : si votre traitement nécessite un full-scan de 20 To, on va faire en sorte de ne le faire qu'une fois...)
- développeurs, bien sûr
- infra/ops : ils doivent être présents et disponibles pour la réception du cluster, l'analyse de la performance et le tuning des traitements, les adaptations de configuration
- travaillez en itératif, bien sûr. Vous ne pouvez pas savoir à l'avance si vos modèles d'analyse seront pertinents, ni si vos données seront suffisantes et de qualité. On est clairement dans le champ de l'innovation. On apprend en marchant...
- utilisez les rituels agiles habituels : stand-up meeting, bilans d'itération. Ayez des objectifs S.M.A.R.T
- outillez-vous :
- prévoyez des échantillons de petite taille de vos données, pour tester les développements avant de les passer sur de gros volumes.
- des machines virtuelles en mode pseudo-distribué disposant des mêmes versions des composants que le cluster cible seront très utiles aux développeurs.
- prévoyez des outils collaboratifs (wiki, partage de code source) accessibles de tous les intervenants, y compris les prestataires externes qui pourraient intervenir ponctuellement. Cela va sans dire, mais ça va mieux en le disant.
- je recommande très fortement un git (ou svn), avec 2 dépôts : un dédié à la gestion de conf (scripts, recettes chef/puppet, éléments de configuration) de façon à les versionner et à les rendre accessibles à tous. Et un deuxième dépôt avec le code source des traitements, et éventuellement des propositions de modification de conf du cluster (qui seront répliqués dans le premier dépôt par les ops)
- et de façon générale, je ne saurai que vous recommander de suivre les principes du Lean Software Developement
Compétences
Vous l'aurez compris en lisant cet article, ce type de projet nécessite de l'expertise "du sol au plafond".
- De l'expertise admin Hadoop : pour le choix du hardware, durant le setup et la configuration du cluster, puis lors des phases de tuning. Hadoop est une technologie complexe, avec de nombreux composants en interaction, et des choix de configuration pour chacun.

- De l'expertise developpeur Hadoop et map/reduce : même si vos développements seront réalisés dans des langages de haut niveau comme Hive ou PIG, il est primordial de comprendre ce qui se passe "dans la soute", au niveau des jobs Map/Reduce générés. Comme indiqué plus haut, on doit développer des traitements adaptés au paradigme distribué d'Hadoop et aux contraintes de l'infrastructure, et non pas pondre des requêtes compliquées, et attendre d'un admin qu'il tune le cluster en conséquence.
Prévoyez de la formation pour tous les développeurs et admins qui interviendront dans le projet. Que ça soit en formation chez un éditeur comme Cloudera ou HortonWorks, ou de l'auto-formation. Si vous optez pour cette 2° option :
- allouez suffisamment de temps
- les tutoriels sur internet sont insuffisants, lisez plutôt de bons bouquins (cf en fin d'article)
- il faut mettre les mains dans le cambouis et s'exercer à l'aide de machines virtuelles en mode pseudo-distribué
Si vous faites intervenir des consultants, organisez le transfert de compétence (par binômage par exemple).
Au-delà de ces expertises sur la technologie Hadoop en elle-même, votre projet BigData nécessite les compétences suivantes :
- datamining / machine learning : Hadoop remet au goût du jour la discipline du datamining. Mais maintenant, nous avons beaucoup (beaucoup) plus de données disponibles, avec beaucoup plus de dimensions, et parfois de l'information diluée et/ou bruitée. Traiter cette complexité, définir des modèles d'analyse, c'est le métier du Data Scientist, et ne s'improvise pas.
- métier : comprendre l'information que vous allez extraire, et en tirer de la valeur, nécessitera d'interagir fortement avec vos experts métiers.
Industrialisation
Une fois les premiers résultats obtenus, vous pourrez vous attaquer à l'industrialisation de la démarche :
- intégrer la plateforme au reste de vos outils de BI traditionnels
- faire cohabiter plusieurs projets d'analyse sur le même cluster
- traiter les questions d'authentification, habilitation, isolation et anonymisation des données, traçabilité des accès
- industrialiser les opérations (côté infra)
- ouvrir l'environnement à plus de développeurs et d'analystes, ce qui nécessitera de sélectionner ou de développer de l'outillage pour faciliter cela
Conclusion
En résumé, un projet Hadoop nécessite une organisation et un pilotage adaptés. Comme disent nos amis anglo-saxons : "There ain't no such thing as a free lunch".
C'est le prix à payer pour commencer à explorer ce formidable terrain de jeux qu'est le big-data, et la puissance de la technologie Hadoop !