Utiliser Hadoop pour le calcul de la Value At Risk Partie 6
Dans le premier article de cette série, j'ai introduit pourquoi le framework Hadoop peut être utile pour calculer la VAR et analyser les données intermédiaires. Dans le second, troisième et quatrième article j'ai détaillé deux implémentations concrètes du calcul de la VAR avec Hadoop. Ensuite dans le cinquième article, j'ai étudié comment analyser les résultats intermédiaires avec Hive. Je vais enfin vous donner quelques chiffres de performances sur Hadoop et les comparer à ceux sur GridGain. Grâce à ces chiffres, je détaillerai certains points capitaux pour les performances lorsqu'on utilise ce type d'outils. Pour finir, je concluerai sur l'intérêt d'Hadoop pour réaliser ce type de calcul.
Quelques chiffres de performance
Disposant de cette implémentation, il est désormais possible de réaliser quelques mesures de performances. J'ai utilisé une machine virtuelle avec 2 GB de RAM et 4 coeurs sur mon laptop, un DELL Latitude E6510 avec un core i67 quad core et 4 GB de RAM. En effet, Hadoop est plus facile à installer sur Linux sachant que j'utilise Windows pour mon travail de tous les jours. Il n'est donc pas possible de comparer directement les chiffres de performances avec les anciennes mesures réalisées sur une machine physique. J'ai donc rejoué à l'intérieur de la machine virtuelle le tir avec GridGain dans lequel tous les résultats sont stockés sur le disque. J'ai réalisé les mesures avec 1 et 4 CPUs. Le graphique suivant montre clairement le gain comparant les temps de calcul entre GridGain et Hadoop. 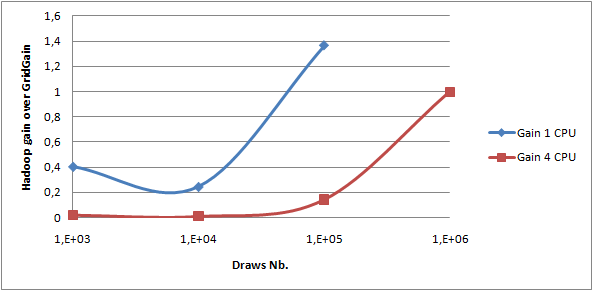
- Toutes les étapes intermédiaires dans Hadoop impliquent des écritures sur le disque alors qu'Hadoop transfère les données en RPC
- Pour ces tests j'ai utilisé uniquement mon portable donc toutes les écritures sont réalisées sur un seul disque. Aucune distribution des entrées/sorties n'est possible
Pour un gros volume de données, je n'ai pas pu réaliser de mesures de performances avec GridGain du fait de mon architecture 32 bits qui limite la taille de ma heap. Cependant, à partir de 100000 tirages nous pouvons remarquer qu'Hadoop est aussi rapide que GridGain. Ainsi, ma prochaine étape sera d'analyser les performances pour des volumes de données plus large en utilisant les deux implémentations que j'ai décrites et certaines optimisations.
Les données sont écrites sous forme texte ou binaire
La VAR est extraite par la fonction
main()ou par la phase de reduceCertains paramètres de configuration ont été optimisés comme ceci:
#core-site.xml io.file.buffer.size=131072 #hdfs-site.xml dfs.block.size=134217728 #mapred-site.xml mapred.child.java.opts=-Xmx384m io.sort.mb=250 io.sort.factor=100 mapred.inmem.merge.threshold=0.1 mapred.job.reduce.input.buffer=0.9En bref, cela permet d'avoir plus de place mémoire (
mapred.child.java.opts), de traiter des lots plus importants en mémoire avant d'écrire sur le disque (io.file.buffer.size,io.sort.mb,io.sort.factor,mapred.inmem.merge.threshold,mapred.job.reduce.input.buffer) et de lire/écrire des blocs plus importants sur HDFS (dfs.block.size).
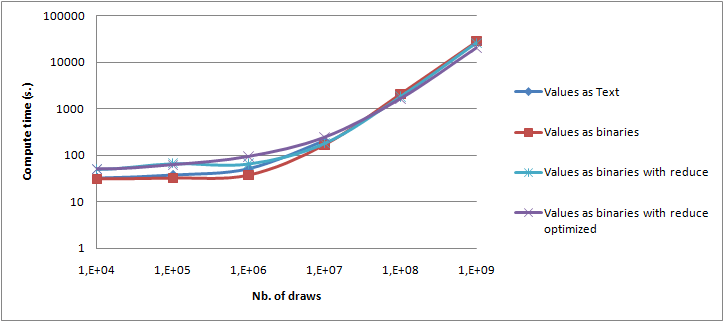
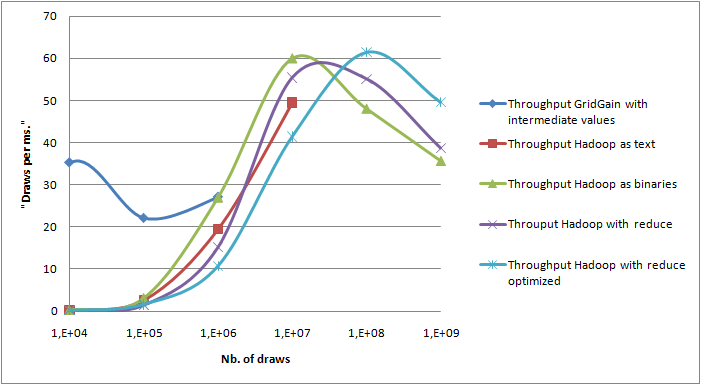
Enfin, un test réellement distribué a été réalisé. Les résultats étaient correct jusqu'à 10 millions de tirages mais la performance n'était pas au rendez-vous, au maximum 1,3 fois mieux qu'avec un seul PC. Les conditions de l'expérience n'étaient pas bonnes, en particulier une contrainte sur la taille disque sur l'autre PC a conduit à une très mauvaise répartition des blocs. Cependant, il n'en reste pas moins que la distribution pour le calcul de la VAR sur un scénario ne scale pas bien sur plusieurs PCs. Le nombre d'écritures est très important ce qui conduit à un grand nombre de transferts de blocs. Et l'implémentation avec une seule phase reduce nécessite de traiter toutes les données pour le reduce sur une seule machine. La distribution de scénarios indépendants devrait être beaucoup plus efficace car la phase de reduce peut être distribuée. En pratique je ne l'ai pas vérifié par un test de charge. Plusieurs autres optimisations ont été testées durant ces investigations mais avec peu ou pas de gains. L'optimisation la moins mauvaise était le comparateur binaire décrit dans le 4ème article. Elle a été testée avec 100000 scénarios de 1000 tirages ce qui est le cas le plus favorable - lire simplement la clé de scénario compare 99,9% des résultats. Le comparateur binaire permet un calcul 1,19 fois plus rapide dans ce cas particulier.
Conclusion
Hadoop est capable de réaliser des calculs de Value At Risk. Il ne peut pas concurrencer directement des outils comme GridGain car il a été conçu pour traiter de larges volumes de données sur le disque. Cependant, dans le cas du calcul de la VAR avec une analyse ultérieure de tous les résultats intermédiaires, il fournit dans ce cas un meilleur framework. Tout d'abord, son système de fichiers distribué et la distribution des travaux de façon colocalisée fournissent nativement une très bonne scalabilité (jusqu'à 1 milliard de tirages, 15,4 GB de données binaires compressées sur un simple portable). Ensuite, la capacité à faire de l'analyse des résultats directement sur les fichiers évite des transferts de gros volumes de données qui peuvent être coûteux. Du point de vue du développeur, Hadoop implémente le même pattern map/reudce que GridGain. Cependant, le code doit être conçu en tenant compte de la distribution réalisée par Hadoop pour être réellement efficace. Réaliser des calculs financiers sur Hadoop peut aujourd'hui encore être considéré comme un sujet de R&D car les outils sont très jeunes. Distribuer les tâches de calcul intensif est utilisé depuis environ 10 ans dans les banques d'investissement. Bénéficier de la distribution du stockage a permis aux grands acteurs internet de traiter d'immenses volumes de données. Cela a été rendu possible par les coûts de stockage et de traitements relativement raisonnables des fermes de serveurs permettant d'exécuter des outils comme Hadoop, ce qui n'était pas envisageable avec des grands systèmes monolithiques. Différentes initiatives autour du stockage et du traitement distribué - avec le mouvement NoSQL- montrent que des outils de plus en plus intégrés sont actuellement en développement. De telles architectures peuvent à la fois aider à répondre à des problèmes particuliers que les approches traditionnelles ne savent pas bien traiter ou autoriser de nouvelles analyses. Par exemple, des cas d'utilisation où le traitement de téraoctets de données n'étaient pas envisageables avec des architectures traditionnelles peuvent désormais appartenir au champ des possibles.