Utiliser Hadoop pour le calcul de la Value At Risk Partie 5
Dans le premier article de cette série, j'ai introduit pourquoi le framework Hadoop peut être utile pour calculer la VAR et analyser les données intermédiaires. Dans les second, troisième et quatrième articles j'ai donné deux implémentations concrètes du calcul de la VAR avec Hadoop ainsi que des détails d'optimisation. Un autre intérêt d'utiliser Hadoop pour le calcul de la Value At Risk est la possibilité d'analyser les valeurs intermédiaires au sein d'Hadoop avec Hive. C'est l'objet de ce (petit) article au sein de cette série.
Utiliser Hive pour de l'analyse décisionnelle
L'objectif majeur de cette implémentation avec Hadoop était de conserver les paramètres et les prix des calls de façon à les analyser par la suite. Pour cela, j'ai utilisé Hive, un framework conçu au dessus de Hadoop. Je vous recommande de lire cet article de façon à avoir un aperçu complet du fonctionnement de Hive. En bref, Hive est un framework qui traduit des expressions SQL en jobs Map/Reduce et les exécute sur un cluster Hadoop. Deux principaux avantages ont motivé cette solution :
- Hadoop peut traiter des terabytes de données. C'est une voie pour dépasser les limitations des architectures BI traditionnelles pour certains cas d'utilisation
- Définir des tables Hive au dessus de fichiers dans HDFS (Hadoop Distributed File System) nécessite simplement de créer des métadonnées. Comme Hadoop a créé lui-même les paramètres des tirages et le prix des calls dans HDFS il n'y a pas besoin de déplacer ces données pour l'analyse décisionnelle ce qui peut amener des gains de temps importants
Hive est un framework encore jeune et il a certaines limitations. La sortie du Map/Reduce doit être des fichiers texte mais peuvent heureusement être compressés. En conséquence, la configuration doit être modifiée légèrement
jobConf.setOutputFormat(org.apache.hadoop.mapred.TextOutputFormat.class);
jobConf.setBoolean("mapred.output.compress", true);
jobConf.set("mapred.output.compression.type", CompressionType.BLOCK.toString());
jobConf.setClass("mapred.output.compression.codec", GzipCodec.class, CompressionCodec.class);
Après avoir installé Hive (je vous renverrai vers cet article), la table peut ensuite être définie via la ligne de commande Hive en lui donnant le chemin des fichiers de sortie dans HDFS :
CREATE TABLE call_prices (key STRING, price DOUBLE, k DOUBLE, r DOUBLE, s0 DOUBLE, sigma DOUBLE, t INT) ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t';
CREATE EXTERNAL TABLE cp like call_prices LOCATION '/user/user/output';
Hive se contente alors de créer quelques métadonnées. Je peux désormais requêter mes valeurs. Je vais vous donner un exemple simpliste permettant seulement de voir la différence entre les prix évaluer par la méthode de Monte-Carlo et l'approximation linéaire à travers la valeur sous-jacente (c'est une ligne dont la pente est égale au delta et passe par le point correspondant au prix actuel du sous-jacent et du prix du call correspondant). En combinant différents outils Unix je peux produire le graphique suivant.
hive -e 'INSERT OVERWRITE LOCAL DIRECTORY "HiveOutput" select cp.s0, cp.price from cp order by cp.price;'
cat HiveOutput/attempt_201010081410_0003_r_000000_0 | tr '\001' '\t' > HiveOutput/output.txt
gnuplot -e 'set terminal png size 764,764; set output "call.png"; set xlabel "Stock price (underlying)"; set ylabel "Call price (option)"; plot "HiveOutput/output.txt" using 1:2, 0.56*(x-120)+12.35632307; exit;'
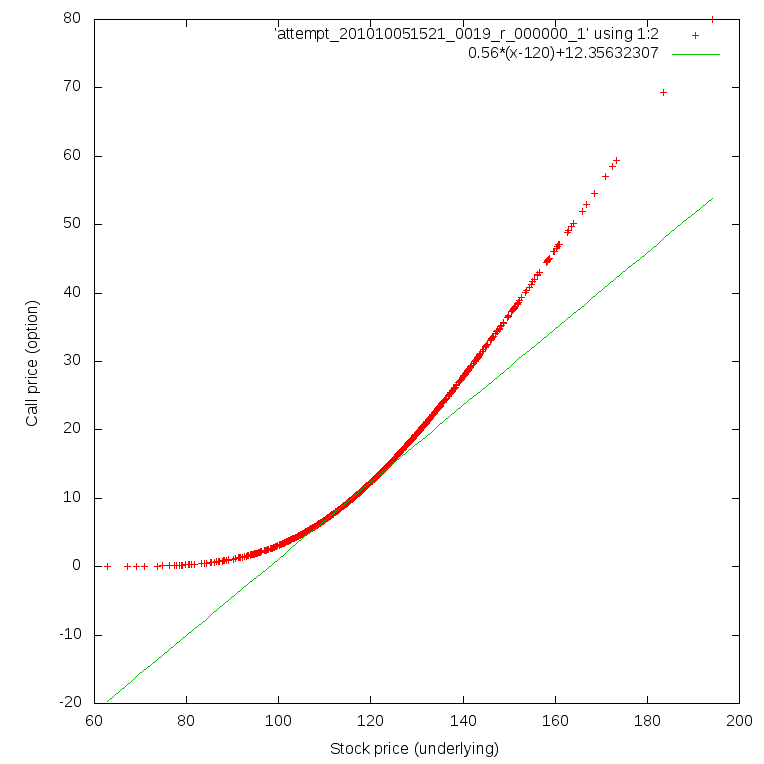
Cela conclut l'implémentation détaillé du calcul de la VAR avec le framework Hadoop. Nous avons calculé la VAR et nous sommes capables d'analyser les résultats intermédiaires avec le framework Hive au dessus d'Hadoop. Dans le sixième et dernier article, je vais vous donner quelques chiffres de performances pour voir dans quelle mesure Hadoop peut concurrencer GridGain et je conclurai sur l'ensemble du sujet.