Un schema registry pour passer à l'échelle
Faire évoluer les contrats d’interfaces peut être un casse-tête, surtout quand leur nombre se multiplie. Comment faire face à une augmentation des clients ?
Dans ce billet seront abordées des solutions comme : un schéma registry minimaliste et la mise en place du zéro downtime deployment. Leurs implémentations et leurs utilisations seront détaillées.
Cet article constitue un retour d'expérience sur la construction d’un Datawarehouse (DWH) et son alimentation en données. Il traite de l’augmentation du nombre d’utilisateurs du DWH et des solutions techniques mises en œuvre pour répondre à ce changement d’échelle.
Construction d'une plateforme de données
Dans le cadre d’un programme de refonte de SI, une multitude d’applications sont développées pour venir remplacer celles existantes. Afin de regrouper les données provenant de l’ensemble de ces nouvelles applications, une équipe met en place une plateforme de données. Il s’agit d’un ensemble d’outils et de services qui répondent collectivement aux besoins de : stockage, préparation, livraison, gouvernance et sécurité des données. Au cœur de cette plateforme se trouve un DWH.
L’objectif du DWH est d’agréger, d’historiser et d’offrir des services pour accéder aux données récoltées. Ces dernières sont utilisées par des directions métiers (BI) et des particuliers (open data).
La mise en place de la plateforme débute par l’alimentation en données du DWH. Quelques fournisseurs se sont connectés sur la plateforme pour y déposer leurs données. 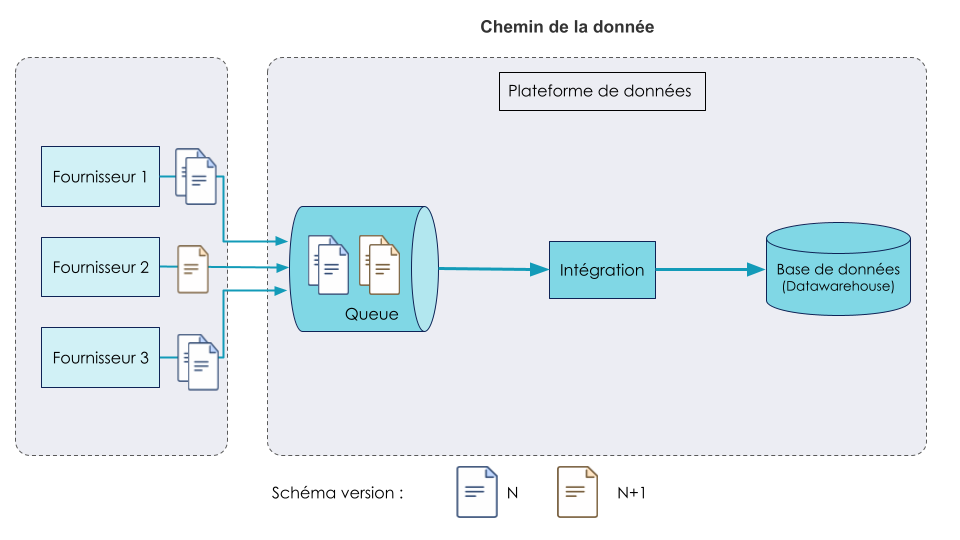
Un changement d’échelle difficile : une intégration inadaptée à un grand nombre d’utilisateurs
Suite au succès de l’intégration des premiers fournisseurs/flux de données, d’autres émettent le souhait de venir déposer leurs données sur la plateforme de données. Afin de permettre ces nouvelles arrivées, un bilan est apparu nécessaire. Trois constats sont dressés .
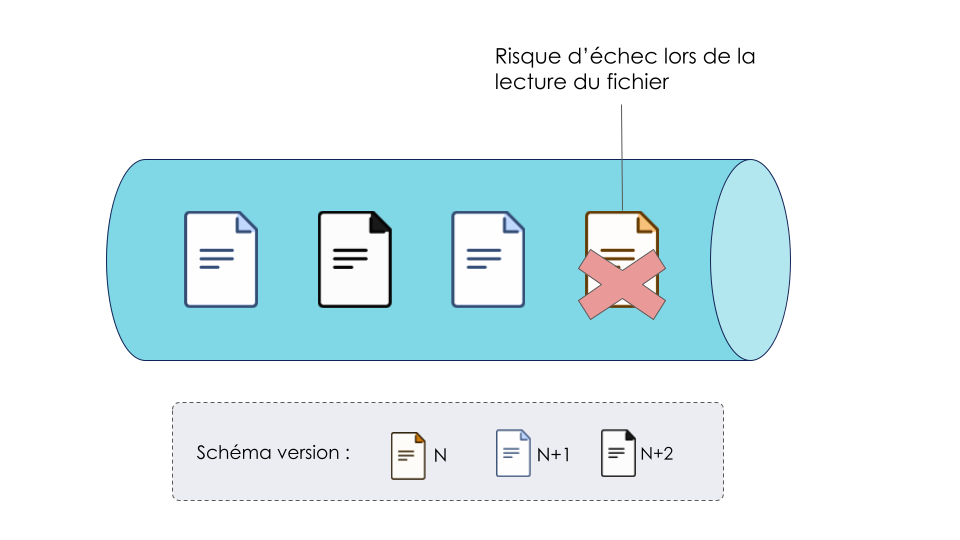
Une régression sur la lecture de fichiers dans la queue
Un des premiers fournisseurs du DWH a, au bout d’un certain temps, mis à jour le schéma de ses JSON. Cet évènement a entraîné une régression dans la lecture des fichiers car le composant Intégration n’était plus en mesure de lire ces nouveaux schémas. Cette régression a été découverte grâce à une alerte automatique envoyée lors de l’échec d’un batch. Le rollback a été long parce qu’il a nécessité de nombreux échanges entre équipes. Le fournisseur de données a dû déployer une ancienne version de son application pour revenir au schéma JSON supporté par Intégration.
Une synchronisation obligatoire entre les fournisseurs et le composant Intégration lors des mises en production
Le schéma des JSON mis à disposition dans la queue, doit être le même que le schéma des JSON attendu par le composant Intégration. Cette obligation de synchronisation est contraignante et provoque une perte de souplesse et d’autonomie pour les équipes lors des mises en production. Ce problème fait écho au premier constat.
L’absence de références communes sur les schémas attendus
Aujourd’hui, il n’y a aucun endroit qui référence les schémas existants. Leurs définitions n’ont pas été centralisées,ni mises à disposition des équipes productrices et consommatrices des données. Cela rouvre régulièrement des échanges sur ce qui a déjà été acté.
Suite à ces constats, il apparaît essentiel de résoudre ces différents problèmes pour être en mesure d’accueillir plus d’utilisateurs sur le DWH et garantir une bonne intégration des données.
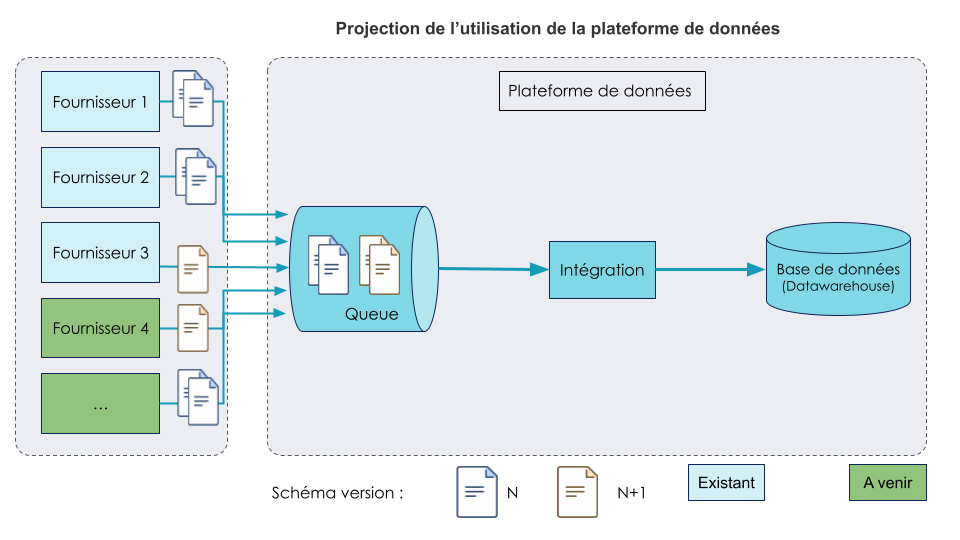
Les besoins et contraintes pour un changement d’échelle sans douleur
Les problèmes rencontrés lors de l’état des lieux mettent en évidence des besoins :
- Déléguer la responsabilité du contrôle de format aux fournisseurs
- Permettre l'évolution des schémas sans contrainte de synchronisation
- Centraliser et publier les contrats d’interface à des fins documentaires
- Schéma des fichiers échangés
- Métadonnées : description, fraîcheur des données, filiation, …
Cependant, il existe également des contraintes :
- Éviter aux équipes de retravailler les flux existants
- Permettre aux nouveaux arrivants de s’inscrire dans le nouveau modèle de validation à la frontière
- Minimiser l’impact des solutions et de leurs mises en oeuvre sur l’ensemble des parties prenantes
Ces exigences sont essentielles pour éviter une augmentation importante de la charge de travail et un ralentissement du développement du programme.
Les réponses apportées pour la montée en charge
Les besoins mis en évidence peuvent être abordés avec une multitude de solutions. Ici sont détaillées uniquement les réponses mises en place par l’équipe data.
Déléguer la responsabilité du contrôle de format aux fournisseurs
Afin d’éviter des régressions et de longs échanges entre l’équipe data et les fournisseurs, en cas d’erreur sur le schéma des fichiers déposés dans la queue, il a été décidé d'implémenter un schéma registry inspiré de celui de Kafka. Il a été décidé de créer le schéma registry plutôt que d'utiliser un produit clef en main pour ne pas avoir besoin de débourser plus d'argent que le coût de la mise en place et de la maintenance.
Schema registry fait maison
Le schéma registry se traduit ici par la mise à disposition, via une API, des schémas des json acceptés par le composant Intégration. Ces derniers sont générés à la volée à partir des pojos (plain old Java object) dans le code d’intégration. Les schémas sont donc toujours à jour sur tous les environnements. Les objets Java sont la source de vérité pour le maintien des contrats d’interface.
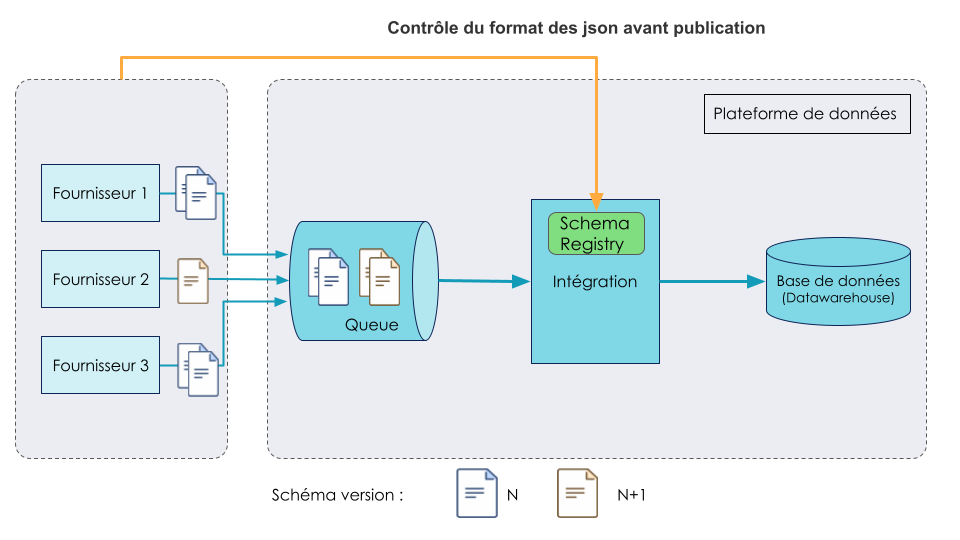
Une nouvelle étape permet aux fournisseurs de venir contrôler le fichier qu’ils s’apprêtent à envoyer.
Un exemple d’implémentation est disponible sur GitLab.
En contrepartie, cette solution demande des ouvertures de flux supplémentaires pour que les fournisseurs puissent venir requêter l’API d’intégration. De plus, elle nécessite de mettre en place une haute disponibilité pour le composant Intégration qui ne peut plus se permettre des interruptions de service. Son API doit être disponible à tout moment.
Le schéma registry de Kafka se distingue de la solution mise en place.
Les différences majeures avec le schéma registry de Kafka
La différence majeure avec le schéma registry de Kafka est d’abord la possibilité d’utiliser plusieurs formats, notamment Avro, ainsi qu’une large gamme d’outils facilitant les développements. Il est par exemple possible, avec Avro, de ne pas passer les headers dans les fichiers transférés. Ils sont reconstruits à l’aide du schéma registry. Cela permet des transferts de fichiers plus légers.
Au vu de la taille des fichiers (quelques Mo) et du besoin de fraîcheur des données, ces avantages ne sont pas un besoin pour l’équipe data. Il n’est pas envisageable d’utiliser le format Avro, car sa mise en place est coûteuse. Il est donc important de minimiser l'impact sur l’ensemble des parties prenantes.
Le schéma registry de kafka est également plus souple, en effet les fournisseurs peuvent pousser leur propre schéma dedans. Pour reproduire ce comportement, le composant d’intégration devrait s’adapter en fonction des schémas donnés par les fournisseurs. Pour ce faire, il faudrait générer des pojos à partir des schémas.
Ici encore cette fonctionnalité n’est pas un besoin. Elle serait coûteuse en temps pour la mettre en place.
Pour éviter de devoir synchroniser les mises en production des fournisseurs et du composant d’intégration, des contraintes sur l’ évolution des schémas sont nécessaires.
Evolution des schémas sans contrainte de synchronisation
Une des réponses possibles pour ce besoin est de garantir la compatibilité entre les versions de schéma N et N+1. Les principes peuvent être retrouvés dans l’article Zero Downtime Deployment. Dans le cas de compatibilité de schéma json, il s’agit du type de compatibilité backward. Si le producteur veut proposer son schéma, aucun moyen simple n’a été trouvé pour pouvoir l'accepter. C’est donc toujours le consommateur qui sera à l’initiative des évolutions de schéma. Mettre en place la backward compatibility demande quelques ajustements. Il faut, lors d’un changement de version (N+1 -> N+2), que le composant intégration s’assure qu’il ne recevra plus de json avec un schéma en version N. Un des moyens est de monitorer la queue. Pour aider le monitoring, il peut être de bon ton de garantir que l’ordre de lecture des fichiers correspond à leur ordre d’arrivée (FIFO).
Si les mises en production sont moins risquées avec la rétrocompatibilité des schémas, il reste à centraliser et publier les contrats d'interfaces attendues.
Publication des contrats d’interfaces à des fins documentaires
Pour partager un point de vérité, facilement entre les équipes, un moyen est de mettre à disposition de la documentation sur le contrat d'interface, au format markdown, sur un gestionnaire de version (ici : Gitlab). Comme pour le schéma registry, les objets Java sont la source de vérité des contrats d’interface. Il suffit d’ajouter une étape dans la CI pour générer le nouveau fichier .md lorsque l’on déploie sur un environnement et le déposer sur le gestionnaire de version. Voici un exemple de documentation :
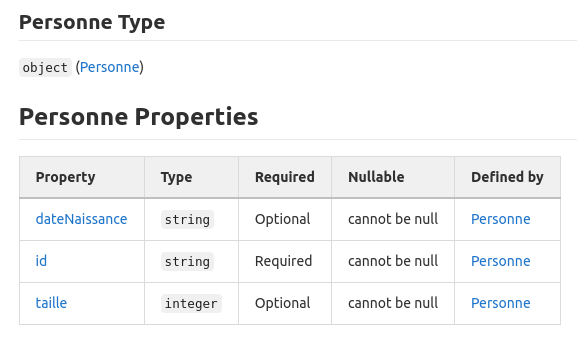
Dans la documentation peuvent figurer :
- Le schéma json des données
- Une description des données
- La fraîcheur des données (fréquence de mise à jour)
- La filiation des données
- La définition des champs
Ces solutions permettent de répondre aux besoins identifiés pour un changement d’échelle. Cependant elles ne résolvent pas tout.
Limite des solutions mises en place
Les fichiers de la queue ne sont pas supprimés après avoir été consommés. Ils ont une période de rétention. L’objectif est de pouvoir faire une reprise de données sans demander aux fournisseurs de publier une seconde fois leurs données. Cela vaut dans le cas où la reprise ne concerne pas un historique de données trop profond et/ou les données envoyées ne sont pas corrompues. Cependant, si le schéma d’un flux change plus de deux fois, cette reprise nécessitera des actions manuelles, sera partielle et/ou demandera un code très résilient pour être effectuée.
Conclusion
La mise en application des différents éléments de résolution n’est pas toujours nécessaire. Ils ont été mis en place dans le contexte de cette mission, néanmoins, dans un contexte avec moins de flux et de fournisseurs, il semble possible de s’en passer. Dans ce cas, n’est-il pas urgent de ne rien faire ?