Un filet de sécurité pour se lancer dans la refonte d'un module Puppet
Le but de cet article est d'étudier la façon dont on peut se construire un filet de sécurité quasi automatiquement avant de se lancer dans la réécriture d'un obscur module Puppet.
Le vieux module AKA la bête à 7 têtes
Ce module, vous le connaissez, vous l'avez peut-être même écrit quand vous débutiez avec Puppet.
Il n'a aucun tests, il est écrit à la va-vite, aucun commentaire, une paire d'appels à des scripts externes pas plus documentés et puppet-lint en viendrait même à se demander si c'est bien du Puppet ...
Bref il faut le revoir.
Ce module, ça pourrait être lui. Mais ça pourrait aussi être son cousin avec 10 lignes de Puppet et 1500 lignes de shell.
Normalement en voyant ça, on prend peur, on veut le jeter, repartir de zéro, écrire des commentaires, faire du TDD (enfin du TDI ici), faire du serverspec, du beaker ou du test kitchen...
Oui mais, ce module il fonctionne et a donc déjà de la valeur !
Ah mais je dois donc le garder?
Pas vraiment mais on ne va pas le jeter tout de suite ! On va lister les modifications qu'il effectue et générer un filet de sécurité. On va s'en servir pour la seule chose où il est bon : faire le travail qu'on lui demande.
L'idée c'est d'avoir un beau module Puppet sans appel shell qui n'exploite que le resource abstraction layer (RAL) : on ne cherche pas à faire un module qui fonctionne (ce serait trop facile si ça pouvait se générer tout seul).
On cherche à faire un module qu'on exécutera en dryrun (noop) qui nous permettra d'auditer les ressources non conformes à ce que faisait le module précédent.
Le principe
On part d'une machine vierge, on fait une image de celle-ci (ce n'est pas un snapshot au sens VirtualBox mais une représentation de l'OS vu par Puppet à cet instant).
On applique l'ancien module, on refait une image.
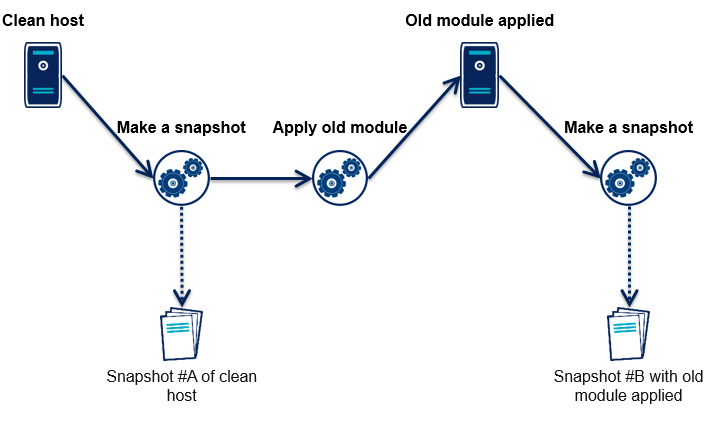
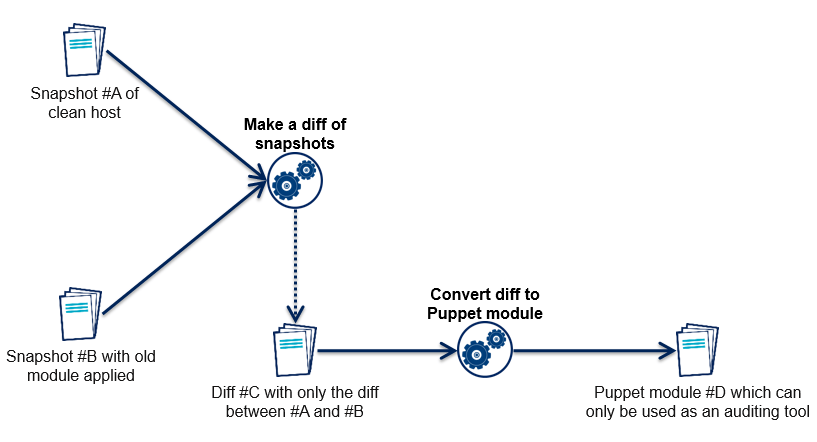
A partir de ces deux images, on extrait les différences. Puis on convertit ce diff en module Puppet basique qui nous servira d'outil d'audit.
On écrit notre nouveau module, on l'applique sur un système vierge. On applique le module d'audit et on vérifie qu'il ne signale rien, sinon c'est que l'a raté quelque-chose lors de notre refactoring.
Si le module d'origine était paramétrable ou fonctionnait sur différentes distributions, il faudra répéter l'opération pour chaque cas.
Ok, je vois l'idée, mais comment on fait ce module automatiquement? Parce que si je dois écrire 2 modules c'est un peu lourd ...
Je propose d'utiliser 2 outils complémentaires et un peu de shell pour ça :
- Blueprint
- Puppet Resource (commande de base de Puppet)
Blueprint est un outil qui permet de faire du reverse engineering sur un système linux en prenant des snapshots.
Dit comme ça, ça semble magique. En pratique c'est un peu plus compliqué que ça et cela produit du bruit. L'outil est capable de sortir ses infos en format Chef, Puppet et script shell. Il est également capable de fournir un diff entre 2 snapshots.
Sa plus-value par rapport à un simple un diff récursif sur la racine du filesystem, c'est qu'il connait une bonne partie des fichiers à ignorer. C'est cette partie qui va nous aider à produire un diff sans avoir à se soucier d'en exclure les fichiers temporaires, etc.
Jouons avec Blueprint
Si vous voulez suivre ce qui est décrit ici, vous pouvez le faire avec vagrant et ce dépôt (vagrant up puis vagrant ssh).
Installation (inclus dans le Vagrantfile) :
apt-get install python-pip -y
pip install blueprint
Blueprint a également besoin de git et d'un nom/email fictif vu que l'on ne se servira pas de git directement (inclus dans le Vagrantfile) :
apt-get install git -y
git config --global user.email "nil"
git config --global user.name "nil"
Une fois installé, on va pouvoir créer notre premier snapshot :
blueprint create cleanvm
Pour voir le contenu de ce snapshot :
blueprint show cleanvm | less
On constate que l'intelligence liée aux fichiers à ignorer est limitée vu la taille du snapshot pour une machine quasi vide. D'où l’intérêt de travailler avec des diffs et non avec un snapshot isolé directement.
On va maintenant passer notre vieux module et refaire un snapshot puis un diff :
mkdir /tmp/modules
cd /tmp/modules
git clone https://github.com/alex-raoul/my_ugly_module.git myuglymodule
puppet apply -e 'include myuglymodule' --modulepath=/tmp/modules
blueprint create afteruglymodule
blueprint show afteruglymodule | less
blueprint diff afteruglymodule cleanvm diffuglymodule
Là, si on commence à regarder le diff, on commence à voir des choses intéressantes !
blueprint show diffuglymodule | less
On voit que l'installation de screen change des choses dans /etc/init.d/.depend.boot et /etc/shells. Mais on voit aussi un fichier /etc/myapp/conf apparaître et plusieurs paquets.
Sauf qu'avec super module, un utilisateur est ajouté et celui-ci n’apparaît pas dans le diff. Blueprint ne le détecte pas et ne le fera probablement jamais. Pareil pour le service puppet arrêté.
On va quand même essayer de générer le module Puppet et voir ce qu'il contient :
blueprint show diffuglymodule --puppet
cat diffuglymodule/manifests/init.pp
Ce n'est pas trop mal mais ça ne va pas être pratique à utiliser sans nettoyage :
- le apt-get update en mode refresh pollue les logs,
- le contenu des fichiers nous importe peu, le hash md5 suffirait pour de l'audit,
- le service puppet à ajouter à la main,
- l'utilisateur à ajouter à la main.
Bref, il manque des morceaux.
Puppet resource vient à l'aide
La commande puppet resource permet d'extraire du système la façon dont Puppet le voit, exemple sur la commande :
puppet resource user
Par contre, pas de diff automatique, pas d'intelligence pour filtrer les utilisateurs de base, etc.
On va donc faire notre propre diff.
Retour en arrière, on repart de notre VM vide et on fait notre snapshot custom (après avoir installé blueprint et Puppet) dans un script :
chmod +x snapshot.sh
./snapshot.sh cleanvm
On repasse notre module puppet puis on refait un snapshot :
puppet apply -e 'include myuglymodule' --modulepath=/tmp/modules
./snapshot.sh afteruglymodule
Un second script entre dans la danse, celui qui va faire notre diff : Il modifie chaque fichier de ressource en mettant une ressource par ligne. C'est ce qui permet de faire un tri (sort) sur le fichier puis de faire un diff.
Concernant les fichiers édités, on va réutiliser les données de blueprint pour nourrir puppet resource. En effet, puppet resource file ne liste pas tous les fichiers du fs comme il le fait sur les autres types de ressources, il faut lui donner le chemin de chaque fichier, par exemple :
puppet resource file /etc/motd
Parmi les informations remontées, les ctime et mtime nous seront inutiles : il faut penser à les filtrer au risque de ne jamais être conforme à l'audit car les dates ne correspondront pas.
De plus, type est un attribut redondant avec ensure et qui risque d'être plus gênant qu'utile.
Pour réutiliser les données de blueprint, on va utiliser la commande show files qui liste les fichiers présents dans le snapshot.
blueprint-show-files myDiff | while read file ; do puppet resource file $file 2>/dev/null ; done | grep -v type | grep -v ctime | grep -v mtime > file_diff
J'ai constaté que blueprint diff ne réagissait pas de la même façon qu'un blueprint create avec un diff de snapshot en argument : blueprint diff ne prend pas /etc/myapp/conf dans notre exemple.
chmod +x diff.sh
./diff.sh cleanvm afteruglymodule diffuglymodule
Et voilà, notre manifest est situé dans diffuglymodule/diff.pp, il n'y a plus qu'à l'exécuter en dryrun et on a notre filet de sécurité.
En résumé
- On instancie une VM vide
- On installe Blueprint et Puppet
- On déploie nos 2 scripts
- On exécute le script de snapshot
- On passe notre vieux module puppet
- On repasse le script de snapshot
- On execute le script de diff
- On profite de notre diff.pp generé automatiquement pour faire de l'audit avec Puppet.
Finalement, on peut comparer ce qu'on a fait à la construction d'un filet de securité autour de code legacy.
Limites
Ce qui a été généré ne peut pas être suffisant pour considérer qu'on est bordé à 100% : ce n'est pas dynamique, ça ne gère pas l'ordre d'application des ressources, ça n'interagit pas avec les éventuels services au niveau réseau (enregistrement auprès d'un loadbalancer...), etc.
Mais ça fait déjà une bonne partie du job et cela permet d'aborder ce refactoring un peu plus sereinement !