Stratégie de placement de conteneurs Docker (partie 2)
Second volet de notre étude sur les orchestrateurs de nœuds Docker, après l’étude des placements des conteneurs sur les nœuds, abordons désormais les possibilités d’anti-affinité offertes par nos chers candidats Fleet, Nomad, Swarm et Kubernetes.
Profitons également de l'occasion pour nous offrir une petite mise à jour des versions de nos belligérants. Le changement majeur est du côté de Docker Inc. puisque désormais Swarm est directement embarqué dans le moteur de conteneurs depuis la version 1.12.
Problématique
Le cas d'utilisation pourrait se résumer ainsi : comment éviter de mettre tous nos œufs dans un même panier ?
Quitte à lancer plusieurs conteneurs d'un même rôle, autant s'assurer qu'ils ne sont pas tous lancés sur la même machine (physique ou virtuelle) et qu'une panne de cette dernière n'arrêtera pas l'intégralité du service.
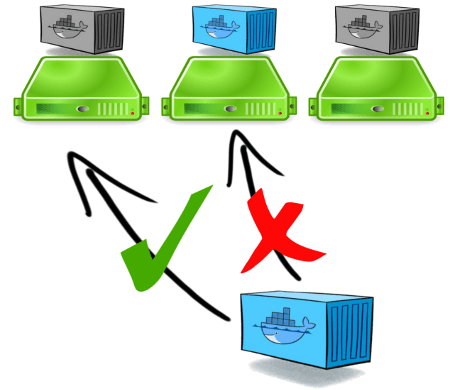
Autrement dit, si je sais que deux conteneurs se secourent mutuellement (les conteneurs bleus dans cette illustration), je dois indiquer à l'orchestrateur qu’ils doivent être placés sur des machines distinctes.
Il existe deux stratégies pour assurer une bonne répartition des conteneurs :
- Stratégie dite « un (et un seul) conteneur sur chaque nœud ». Cette stratégie détermine le nombre de conteneurs à partir du nombre de nœuds éligibles. Particulièrement pertinente pour faire tourner des conteneurs techniques sur tous les nœuds (centralisation des logs, monitoring par exemple), elle a l'avantage de s'adapter automatiquement à l'ajout ou au retrait d'un nœud dans le cluster. Elle maximise les chances de disponibilité d'un conteneur, quitte à en avoir un peu trop. Un cas d'usage très classique concerne la mise en place de conteneurs de routage des flux entrant dans le cluster (type reverse-proxy) sur toutes les machines en DMZ.
- Stratégie dite « n conteneurs, un par noeud ». Cette option permet de fixer un nombre arbitraire de conteneurs et de laisser au moteur de clustering le soin de prendre la meilleure décision pour les placer. Cette stratégie peut être plus économe en ressources (je peux ne faire tourner que deux conteneurs si je cherche uniquement une certaine haute disponibilité, sans nécessairement une grosse puissance de traitement). En revanche, elle impose de bien choisir des nœuds différents. Dans ce modèle, deux sous-cas de figure peuvent se gérer :
- Anti-affinité stricte : si je demande à créer 3 instances et qu'il n'y a que deux nœuds éligibles, le moteur de placement ne crée que deux instances et manifeste son mécontentement
- Anti-affinité souple : si je demande à créer 3 instances et qu'il n'y a que deux nœuds éligibles, le moteur de placement crée tout de même 3 instances quitte à sacrifier une des contraintes demandées en plaçant deux conteneurs sur le même nœud
Fleet

Fleet n'a pas une connaissance fine des topologies de conteneurs (ou plus largement de services) et a donc choisi deux approches simples.
Stratégie « Un (et un seul) sur chaque nœud »
Cette approche est possible en utilisant l'option Global=true. Elle peut être combinée avec un autre filtre comme MachineMetadata pour ne s'appliquer qu'à un certain groupe de nœuds.
# nginx.service
[Unit]
Description=My NGinx server
After=docker.service
Requires=docker.service
[Service]
TimeoutStartSec=0
ExecStartPre=-/usr/bin/docker kill my-nginx
ExecStartPre=-/usr/bin/docker rm my-nginx
ExecStartPre=/usr/bin/docker pull nginx
ExecStart=/usr/bin/docker run --rm --name my-nginx -P nginx
ExecStop=/usr/bin/docker stop my-nginx
[X-Fleet]
MachineMetadata=zone=dmz
Global=true
Stratégie « N copies, un par nœud »
L'autre stratégie repose sur la création d'un service (au sens systemd) multi-instanciable (nommé monservice@.service). Cette stratégie adopte une anti-affinité souple, voire très souple car rien de garantit que vos conteneurs vont être proprement ventilés sur les nœuds éligibles. Il est possible de préciser le mot-clé Conflicts qui peut contenir des wildcards pour s’assurer qu’un seul conteneur d’un type donné est présent par nœud et passer alors dans une stratégie d'anti-affinité stricte. La nomenclature des services devient alors primordiale car c’est le seul garde-fou aux mauvais placements.
# nginx@.service
[Unit]
Description=My NGinx server
After=docker.service
Requires=docker.service
[Service]
TimeoutStartSec=0
ExecStartPre=-/usr/bin/docker kill my-nginx-%i
ExecStartPre=-/usr/bin/docker rm my-nginx-%i
ExecStartPre=/usr/bin/docker pull nginx
ExecStart=/usr/bin/docker run --rm --name my-nginx-%i -P nginx
ExecStop=/usr/bin/docker stop my-nginx-%i
[X-Fleet]
MachineMetadata=zone=dmz
Conflicts=nginx@*
Il est alors possible de démarrer plusieurs instances du service :
$ fleetctl start nginx@1 Unit nginx@1.service inactive Unit nginx@1.service launched on 67f376d6.../10.0.3.84 $ fleetctl start nginx@2 Unit nginx@2.service inactive Unit nginx@2.service launched on 67f99925.../10.0.3.85 $ fleetctl start nginx@3 Unit nginx@3.service inactive Unit nginx@3.service launched on 9801a072.../10.0.3.86 $ fleetctl list-units
UNIT MACHINE ACTIVE SUB nginx@1.service 67f376d6.../10.0.3.84 active running nginx@2.service 67f99925.../10.0.3.85 active running nginx@3.service 9801a072.../10.0.3.86 active running
S'il n'y a plus de nœud éligible pour votre nouvelle instance de service, la commande de démarrage va simplement bloquer et ne pas rendre la main tant qu'elle ne trouve pas de place. C'est à vous de comprendre que le placement échoue et qu'il faut interrompre la demande de placement avec un bon vieux ^C.
$ fleetctl start nginx@4 Unit nginx@4.service inactive [... Rien ne se passe ...] ^C $
Le service a tout de même été soumis. Pour éviter que la soumission ne soit bloquante, il suffit d'ajouter l'option -no-block à la commande :
$ fleetctl start -no-block nginx@5 Unit nginx@5.service inactive Triggered unit nginx@5.service start $
Nous pouvons alors voir que deux instances du service sont en attente et non placées sur des nœuds :
$ fleetctl list-unit-files UNIT HASH DSTATE STATE TARGET nginx@1.service 37babe6 launched launched 67f376d6.../10.0.3.84 nginx@2.service 37babe6 launched launched 67f99925.../10.0.3.85 nginx@3.service 37babe6 launched launched 9801a072.../10.0.3.86 nginx@4.service 37babe6 launched inactive - nginx@5.service 37babe6 launched inactive -
Dès qu'un nouveau nœud sera éligible, il se vera automatiquement attribué un des deux jobs en attente.
Nomad

Stratégie « Un (et un seul) sur chaque nœud »
Nomad propose plusieurs schedulers. Si l'on utilise le scheduler system, on se retrouve dans la situation de Fleet avec son mode Global=true. Il est également possible de préciser une contrainte de sélection des nœuds pour faire démarrer le service sur toutes les machines répondant aux critères, et ce en s'adaptant dynamiquement à l'arrivée ou au départ desdits nœuds.
job "my-service" {
datacenters = ["dc1"]
type = "system"
group "webs" {
constraint {
attribute = "$meta.disktype"
value = "hdd"
}
task "frontend" {
driver = "docker"
...
service {
...
}
resources {
...
}
}
}
Stratégie « N copies, un par nœud »
Nomad implémente la stratégie « Un par nœud », mais avec la capacité à préciser le nombre de copies de la tâche à créer (group.count). À nouveau cette stratégie s'ajoute à la capacité à sélectionner les nœuds éligibles au placement. Le scheduler de type service est alors utilisé. C'est celui par défaut pour des services standard, le troisième étant celui dédié à l'exécution des batches.
Comme pour Fleet, il est possible de demander une anti-affinité (trop) souple ou stricte en précisant l'option distinct_hosts = true comme dans l'exemple ci-dessous :
job "my-service" {
datacenters = ["dc1"]
type = "service"
group "webs" {
count = 3
constraint {
attribute = "$meta.disktype"
value = "hdd"
distinct_hosts = true
}
task "frontend" {
driver = "docker"
...
service {
...
}
resources {
...
}
}
}
Ici, pas de négociation, Nomad préfère ne pas démarrer le nombre demandé de conteneurs plutôt que de les colocaliser.
Pour mettre en évidence ce comportement, commençons par instancier 3 copies d'un conteneur nginx qui vont naturellement trouver leur place sur 3 nœuds :
$ nomad run job.hcl ==> Monitoring evaluation "8ac4685d" Evaluation triggered by job "my-service" Allocation "092298a2" created: node "b647364b", group "webs" Allocation "36c6396a" created: node "5703390a", group "webs" Allocation "74d51965" created: node "f3358cf7", group "webs" Evaluation status changed: "pending" -> "complete" ==> Evaluation "8ac4685d" finished with status "complete"
Constatons en détail l'état du service après quelques secondes le temps que les conteneurs démarrent :
$ nomad status my-service ID = my-service Name = my-service Type = service Priority = 50 Datacenters = dc1 Status = running Periodic = false
Summary Task Group Queued Starting Running Failed Complete Lost webs 0 0 3 0 0 0
Allocations ID Eval ID Node ID Task Group Desired Status Created At 092298a2 8ac4685d b647364b webs run running 10/03/16 09:19:18 UTC 36c6396a 8ac4685d 5703390a webs run running 10/03/16 09:19:18 UTC 74d51965 8ac4685d f3358cf7 webs run running 10/03/16 09:19:18 UTC
À présent rendons la tâche un peu plus difficile en drainant (vider et rendre inutilisable) un des 3 nœuds :
$ nomad node-status ID DC Name Class Drain Status 5703390a dc1 coreos-nomad-client1 <none> false ready f3358cf7 dc1 coreos-nomad-client3 <none> true ready b647364b dc1 coreos-nomad-client2 <none> false ready $ nomad node-drain -enable -yes f3358cf7 $ nomad node-status ID DC Name Class Drain Status 5703390a dc1 coreos-nomad-client1 <none> false ready f3358cf7 dc1 coreos-nomad-client3 <none> true ready b647364b dc1 coreos-nomad-client2 <none> false ready
Dès lors, seuls les nœuds coreos-nomad-client1 et coreos-nomad-client2 sont utilisables. L'état du service bascule dans un état non conforme :
$ nomad status my-service ID = my-service Name = my-service Type = service Priority = 50 Datacenters = dc1 Status = running Periodic = false
Summary Task Group Queued Starting Running Failed Complete Lost webs 1 0 2 0 1 0
Placement Failure Task Group "webs": * Constraint "distinct_hosts" filtered 2 nodes
Allocations ID Eval ID Node ID Task Group Desired Status Created At 092298a2 8ac4685d b647364b webs run running 10/03/16 09:19:18 UTC 36c6396a 8ac4685d 5703390a webs run running 10/03/16 09:19:18 UTC 74d51965 8ac4685d f3358cf7 webs stop complete 10/03/16 09:19:18 UTC
Dès que l'on ré-active le 3ème nœud, et que l'on re-soumet le job, tout rentre dans l'ordre :
$ nomad node-drain -disable -yes f3358cf7 $ nomad status my-service ID = my-service Name = my-service Type = service Priority = 50 Datacenters = dc1 Status = running Periodic = false
Summary Task Group Queued Starting Running Failed Complete Lost webs 0 0 3 0 1 0
Placement Failure Task Group "webs": * Constraint "distinct_hosts" filtered 2 nodes
Allocations ID Eval ID Node ID Task Group Desired Status Created At 353ec700 d2583c52 f3358cf7 webs run running 10/03/16 09:25:02 UTC 092298a2 8ac4685d b647364b webs run running 10/03/16 09:19:18 UTC 36c6396a 8ac4685d 5703390a webs run running 10/03/16 09:19:18 UTC 74d51965 8ac4685d f3358cf7 webs stop complete 10/03/16 09:19:18 UTC
Enfin pas tout à fait, la commande nomad status continue à remonter l'erreur de type Placement Failure alors que les trois instances ont correctement démarré. Sans doute un petit bug de jeunesse.
Swarm mode de Docker

L'histoire de Docker Swarm est pavée d'embûches suite à certains changements dans l'architecture du couple Docker-Engine/Docker-Swarm. La gestion des contraintes de placement semble avoir été largement remaniée, prenez donc garde en consultant la litérature ! Nous sommes bien en face de deux outils au comportement très différent :
- Le mode Swarm nativement intégré à Docker-engine version 1.12 ou supérieure (c'est cette version que nous étudions ici)
- Swarm en version standalone couplé avec un Docker-engine version 1.11 ou inférieure, que nous appellerons l'ancienne version de Swarm

Avec cette mouture de Swarm, la description des objets à déployer dans le cluster se fait au travers de la commande docker service.
Pour montrer les capacités de Swarm, nous allons préalablement labelliser nos nœuds. Dans l'exemple ici, nous avons 3 nœuds master et 3 nœuds standard :
$ docker node update --label-add type=master coreos-swarm-master1 $ docker node update --label-add type=master coreos-swarm-master2 $ docker node update --label-add type=master coreos-swarm-master3 $ docker node update --label-add type=worker coreos-swarm-node1 $ docker node update --label-add type=worker coreos-swarm-node2 $ docker node update --label-add type=worker coreos-swarm-node3
Stratégie « Un (et un seul) sur chaque nœud »
Swarm dispose désormais d'une capacité à lancer des conteneurs sur chaque nœud avec le mode dit global :
$ docker service create --name nginx-global --mode global --constraint 'node.labels.type == worker' nginx
Une fois l'instanciation du service, nous pouvons regarder le déploiement des conteneurs
$ docker service ps nginx-global ID NAME IMAGE NODE DESIRED STATE CURRENT STATE ERROR 1eir3xq978197ip0sum8i08ed nginx-global nginx coreos-swarm-node3 Running Running 7 seconds ago cwwz4cdfs2to5wrvsd4wcooiq \_ nginx-global nginx coreos-swarm-node2 Running Running 7 seconds ago 2nrs40zdgif0y1os3oylcgg5z \_ nginx-global nginx coreos-swarm-node1 Running Running 7 seconds ago 2hpvcwucmpsfvfcdirdgeqf3j \_ nginx-global nginx coreos-swarm-master3 Running Allocated 9 seconds ago dstk7i1ppvp6b35fw10ksjggk \_ nginx-global nginx coreos-swarm-master2 Running Allocated 9 seconds ago 3s739zw3wq60mvhgxnym859ta \_ nginx-global nginx coreos-swarm-master1 Running Allocated 9 seconds ago
Curieusement, l'affectation d'une contrainte pour ne placer les conteneurs que sur les nœuds de type worker annonce les conteneurs non éligibles (sur les masters) dans un état Allocated.
Stratégie « N copies, un par nœud »
Swarm propose dans son mode standard une politique de placement classique (dite replicated) dont la syntaxe est la suivante :
$ docker service create --name nginx-repl --replicas 4 --constraint 'node.labels.type == worker' nginx 2s6dsd5f8q9bhczed3l077c94 $
Ici, nous avons donc fixé le nombre de copies du conteneur, ce que l'on peut vérifier par la commande :
$ docker service ls ID NAME REPLICAS IMAGE COMMAND 1eir3xq97819 nginx-global global nginx 2s6dsd5f8q9b nginx-repl 4/4 nginx
Pour retrouver la localisation des nœuds, la commande docker ps nginx-repl nous renseigne :
$ docker service ps nginx-repl ID NAME IMAGE NODE DESIRED STATE CURRENT STATE ERROR 950enddkroq13us254hypegaz nginx-repl.1 nginx coreos-swarm-node3 Running Running 13 seconds ago
0df7a7jx76q7irsh2dvtrs9jp nginx-repl.2 nginx coreos-swarm-node1 Running Running 13 seconds ago
06cp4moaqo76d62g70cktd9o6 nginx-repl.3 nginx coreos-swarm-node1 Running Running 13 seconds ago
cdl3dqz3nht6vlmb4feugj5ir nginx-repl.4 nginx coreos-swarm-node2 Running Running 13 seconds ago
On constate que la politique de placement correspond à une politique d'anti-affinité souple, puisque l'on a demander à placer 4 conteneurs sur 3 nœuds éligibles. Dans le cas présent coreos-swarm-node1 porte deux conteneurs.
Dans l'ancienne version de Swarm, il était possible d'ajouter des contraintes d'anti-affinité spécifiques (par exemple affinity:container!=~redis*) permettant d'obtenir une politique stricte, mais cela ne semble plus disponible avec le mode Swarm.
Kubernetes

Stratégie « Un (et un seul) sur chaque nœud »
Les objets Kubernetes DaemonSets sont une implémentation de cette stratégie. La définition ressemble à celle d’un ReplicationController ou ReplicaSet, mais sans préciser le nombre de copies du pod. L’utilisation d’un NodeSelector s’applique toujours. Au final, tous les nœuds éligibles porteront une et une seule instance du pod décrit.
Stratégie « N copies, un par nœud »
Kubernetes implémente nativement n copies d'un conteneur (ou pod) au travers de plusieurs objets : les ReplicationControllers ou dernièrement les ReplicaSets encapsulés dans des Deployments. Dans tous les cas, on spécifie le nombre de copies (ou réplicats) que l'on souhaite et le scheduler de Kubernetes fait le travail d'allocation des pods sur les nœuds. La politique de placement par défaut repose sur des choix classiques (trouver là où il y a de la place sur des nœuds éligibles, puis répartir les pods correspondant à un même service sur plusieurs nœuds). À nouveau un NodeSelector permet de filtrer les nœuds éligibles au placement.
Lorsque l'on souhaite implémenter des stratégies d'affinité plus poussées et dépendantes d'une topologie spécifique (Rack, salle, DC, zone, région...), Kubernetes dispose d'une approche très puissante de personnalisation mais aussi un peu laborieuse à appréhender. La documentation décrivant le mieux cette mécanique se trouve sur le site d'OpenShift. Prévoyez un peu de temps pour assimiler ces informations.
Nous allons ici nous focaliser sur le cas d'utilisation le plus simple.
Kubernetes considère que si une stratégie d'anti-affinité doit s'appliquer, c'est en général pour assurer la disponibilité d'un service. il s'agit donc de garantir que les pods qui sont exposés par ce service ne sont pas tous colocalisés.
Pour illustrer cette capacité du scheduler, nous allons modéliser une règle d’anti-affinité pour éviter que tous les pods d'un même service ne soient sur la même baie de serveurs. Beaucoup d’autres cas d’utilisation sont possibles tant pour de l’affinité (dc, zone, région cloud) que pour de l’anti-affinité (hyperviseur, machine, baie). La configuration intervient à l’échelle de tout le cluster. Elle va donc s’appliquer sur tous les services sans distinction, que cela leur soit utile ou non.
Commençons par labelliser les nœuds pour notre test :
$ kubectl label no/10.0.3.71 rack=rack-01 $ kubectl label no/10.0.3.72 rack=rack-01 $ kubectl label no/10.0.3.73 rack=rack-02 $ ubectl get no --show-labels NAME STATUS AGE LABELS 10.0.3.71 Ready 9m beta.kubernetes.io/arch=amd64,beta.kubernetes.io/os=linux,kubernetes.io/hostname=10.0.3.71,rack=rack-01 10.0.3.72 Ready 9m beta.kubernetes.io/arch=amd64,beta.kubernetes.io/os=linux,kubernetes.io/hostname=10.0.3.72,rack=rack-01 10.0.3.73 Ready 9m beta.kubernetes.io/arch=amd64,beta.kubernetes.io/os=linux,kubernetes.io/hostname=10.0.3.73,rack=rack-02
Il est par la suite nécessaire de reconfigurer le scheduler Kubernetes en lui spécifiant la politique par défaut, à laquelle nous avons ajouté notre contrainte d’anti-affinité par rack (nommée RackSpread dans cet exemple) :
{
"kind" : "Policy",
"version" : "v1",
"predicates" : [
{"name" : "PodFitsPorts"},
{"name" : "PodFitsResources"},
{"name" : "NoDiskConflict"},
{"name" : "MatchNodeSelector"},
{"name" : "HostName"}
],
"priorities" : [
{"name" : "LeastRequestedPriority", "weight" : 1},
{"name" : "BalancedResourceAllocation", "weight" : 1},
{"name" : "ServiceSpreadingPriority", "weight" : 1},
{"name" : "RackSpread", "weight" : 5, "argument" : {"serviceAntiAffinity" : {"label" : "rack"}}}
]
}
Un redémarrage du scheduler Kubernetes avec l’option --policy-config file=/etc/kubernetes/policy.json s'impose alors.
Lançons ensuite un Deployment (initialement vide), exposons-le derrière un service avant de le faire scaler à 2 pods.
$ kubectl run nginx --image=nginx --replicas=0 deployment "nginx" created $ kubectl expose deployment/nginx --port=80 service "nginx" exposed $ kubectl scale deployment/nginx --replicas=2 deployment "nginx" scaled $ kubectl get po -o wide NAME READY STATUS RESTARTS AGE IP NODE nginx-701339712-ebp4b 1/1 Running 0 1m 172.16.87.4 10.0.3.71 nginx-701339712-i1qls 1/1 Running 0 1m 172.16.28.3 10.0.3.73
Le scheduler a donc choisi de distribuer les pods sur les deux racks conformément à notre souhait. Si l'on augmente le nombre de copies de ce pods, on constate que la contrainte d'anti-affinité est souple.
$ kubectl scale deployment/nginx --replicas=4 deployment "nginx" scaled $ kubectl get po -o wide NAME READY STATUS RESTARTS AGE IP NODE nginx-701339712-9yw4h 1/1 Running 0 1m 172.16.28.4 10.0.3.73 nginx-701339712-df521 1/1 Running 0 1m 172.16.74.2 10.0.3.72 nginx-701339712-ebp4b 1/1 Running 0 3m 172.16.87.4 10.0.3.71 nginx-701339712-i1qls 1/1 Running 0 3m 172.16.28.3 10.0.3.73
Notez également qu'il est possible de prioriser nos contraintes personnalisées en les pondérant. Dans notre exemple, le poids est de 5, ce qui donne à notre règle d'anti-affinité au rack la priorité par rapport aux autres priorités définies.
Conclusion
Résumons la situation concernant nos belligérants dans leur version actuelle :
| Fleet | Nomad | Swarm | Kubernetes | |
|---|---|---|---|---|
| Version testée | 0.11.8 | 0.4.1 | 1.12.1 (Docker mode Swarm) | 1.4.1 |
| filtrage des nœuds éligibles suivant leur classe (ssd, dmz...) | oui | oui | oui | oui |
| Stratégie de placement « un (et un seul) sur chaque nœud » | oui Global=True | oui type=”system” | oui --mode global | oui DaemonSets |
| Stratégie «N copies, un par nœud» | partielle* | oui | oui | oui |
| Type d'anti-affinité | souple ou stricte | souple ou stricte | souple | souple avec priorité |
| Moteur de règles personnalisable | non | non | non | oui : modélisation possible de régions, zones, racks, … |
*Contraintes basées sur le nommage des services uniquement
Nos 4 schedulers proposent une implémentation plutôt efficace et saine pour placer les conteneurs. L'arrivée de Swarm en natif dans Docker 1.12 comble une partie du retard sur Kubernetes, mais ce dernier reste largement le plus configurable. En cadeau bonus, de nouvelles fonctions sont actuellement en alpha dans la version 1.4.
Pour des besoins simples où il n'est pas nécessaire de modéliser des topologies complexes, l'utilisation de Fleet ou Nomad peut largement faire l'affaire. Le couplage de Nomad avec d'autres produits de chez HashiCorp comme Consul et Vault notamment en font un candidat très sérieux qu'il faudra suivre.
Pour approfondir, il serait intéressant de se pencher sur le comportement de nos moteurs dans des cas où des déplacements de conteneurs (rebalance) pourraient s'imposer (ajout d'un nœud ou changement de labels d'un nœud existant).
Il serait également intéressant d'étudier les algorithmes qui s'appliquent lors d'un scale-down dans le choix du ou des conteneurs à supprimer.