Stratégies de placement de conteneurs Docker (partie 1)
Les gestionnaires de cluster Docker sont des briques stratégiques lorsqu’il s’agit de déployer des conteneurs à l’échelle, jusqu’en production.
Nous travaillons à analyser techniquement ces solutions suivant plusieurs critères : résilience, scalabilité, sécurité, performance… C’est plus précisément sur les stratégies de placement des conteneurs que va porter notre attention dans cette série de deux articles.
L’enjeu d’un placement pertinent est primordial car il peut contribuer à offrir une bonne disponibilité des services, des performances, le respect des qualités de service, le tout en optimisant l’utilisation des ressources sous-jacentes. Il est donc nécessaire de pouvoir annoter les conteneurs pour aider le scheduler à prendre les meilleures décisions de placement possibles.
Au menu : l’affinité conteneur-nœud et l’anti-affinité entre conteneurs dans 4 solutions opensource : Fleet, Nomad, Swarm et Kubernetes. Nous passerons en revue les opérations de base pour optimiser le placement de nos conteneurs sur chacun de ces produits.
L’affinité des conteneurs sur les nœuds
Commençons donc par étudier la capacité à opérer une affinité entre les conteneurs et les nœuds.
Le but de cette affinité peut être de deux ordres :
- Certains nœuds ont un positionnement réseau particulier qui les rend éligibles à porter des conteneurs particuliers (reverse-proxies en DMZ, applications en zone front, persistance en zone back…)
- Certains nœuds ont des caractéristiques techniques (disques low-cost ou ssd, présence dans une zone, région spécifique…)
Démarche
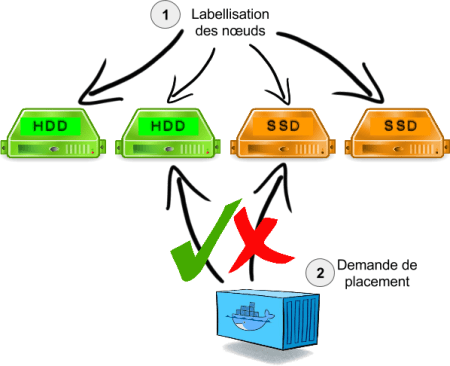
Avant de mettre en œuvre cette affinité, il est préalablement nécessaire de labelliser les nœuds à l’aide de métadonnées libres. Voyons comment faire cela sur nos quatre candidats, qui pour les besoins de la démonstration, sont installés sur des CoreOS.
Notre exercice va consister à placer des conteneurs sur des nœuds suivant le type de disques présents sur la machine. Nous allons par conséquent labelliser les nœuds avec une métadonnée disktype qui vaudra hdd ou ssd en fonction des nœuds.
Fleet

Fleet est l'orchestrateur livré en standard avec la distribution Linux CoreOS. Il se présente comme un orchestrateur générique de services distribués (sous forme de conteneurs Docker, rkt ou tout autre processus). Il s'appuie sur un cluster de nœuds etcd pour distribuer sa configuration de façon résiliente.
Labellisation des nœuds
Fleet accepte de recevoir des métadonnées au travers d’une variable d’environnement :
# /etc/systemd/system/fleet.service.d/10-env.conf
[Service]
Environment="FLEET_METADATA=coreos=true,disktype=ssd"
Une fois le redémarrage de Fleet effectué, les nœuds sont visibles avec leurs tags associés
$ fleetctl list-machines MACHINE IP METADATA 4e58f54e... 10.0.3.73 coreos=true,disktype=ssd 5a73bd14... 10.0.3.61 coreos=true,disktype=hdd 6ad001f1... 10.0.3.62 coreos=true,disktype=hdd 7192a51d... 10.0.3.72 coreos=true,disktype=ssd d26ecc11... 10.0.3.71 coreos=true,disktype=ssd ef774ea0... 10.0.3.63 coreos=true,disktype=hdd
Lancement de conteneurs
La définition d'un job Fleet peut alors utiliser cette nouvelle métadonnée disktype comme contrainte. Pour rappel, la description d’un job Fleet est au format des units systemd auquel est ajoutée une section spécifique [X-Fleet].
# my-nginx@.service
[Unit]
Description=My NGinx server
After=docker.service
Requires=docker.service
[Service]
TimeoutStartSec=0
ExecStartPre=-/usr/bin/docker kill my-nginx
ExecStartPre=-/usr/bin/docker rm my-nginx
ExecStartPre=/usr/bin/docker pull nginx
ExecStart=/usr/bin/docker run --rm --name my-nginx -p 80 nginx
ExecStop=/usr/bin/docker stop my-nginx
[X-Fleet]
MachineMetadata=disktype=hdd
Il est alors possible de lancer plusieurs instances de l'unit avec la commande :
$ for i in {1..4}; do fleetctl start my-nginx@$i.service; done Unit my-nginx@1.service inactive Unit my-nginx@1.service launched on 4e58f54e.../10.0.3.63 Unit my-nginx@2.service inactive Unit my-nginx@2.service launched on d26ecc11.../10.0.3.61 Unit my-nginx@3.service inactive Unit my-nginx@3.service launched on 4e58f54e.../10.0.3.63 Unit my-nginx@4.service inactive Unit my-nginx@4.service launched on 7192a51d.../10.0.3.62
Les traces du lancement des units semblent montrer que le scheduler a fait le travail. A posteriori, il est toujours possible de vérifier le placement des conteneurs créés :
$ fleetctl list-units UNIT MACHINE ACTIVE SUB my-nginx@1.service 4e58f54e.../10.0.3.63 active running my-nginx@2.service d26ecc11.../10.0.3.61 active running my-nginx@3.service 4e58f54e.../10.0.3.63 active running my-nginx@4.service 7192a51d.../10.0.3.62 active running
Nomad

Labellisation des nœuds
La configuration du client (ou nœud ou agent) permet d’ajouter une section meta avec des propriétés libres :
log_level = "INFO"
data_dir = "/var/lib/nomad"
bind_addr = "0.0.0.0"
advertise {
rpc = "10.0.3.84:4647"
}
client {
enabled = true
servers = [ "10.0.3.81:4647", "10.0.3.82:4647", "10.0.3.83:4647" ]
node_id = "coreos-nomad-client1"
options {
driver.whitelist = "docker"
}
meta {
disktype = "hdd"
}
}
Les metadata des nœuds ne sont pas visibles au travers de la commande nomad node-status, mais un simple curl sur l’API Nomad permet tout de même de vérifier notre labellisation :
$ curl -sfq http://127.1:4646/v1/node/coreos-nomad-client1 | jq .Meta { "disktype": "hdd" }
Lancement de conteneurs
Lors de la soumission d'un job, il est possible de préciser notre contrainte de placement au travers du bloc constraint :
job "my-service" {
datacenters = ["dc1"]
group "webs" {
count = 3
constraint {
attribute = "$meta.disktype"
value = "hdd"
}
task "frontend" {
driver = "docker"
config {
image = "nginx"
port_map { http = 80 }
}
service {
port = "http"
tags = [ "http" ]
check {
name = "alive"
type = "http"
path = "/"
protocol = "http"
interval = "10s"
timeout = "2s"
}
}
resources {
cpu = 500
memory = 128
network {
mbits = 10
port "http" { }
}
}
}
}
}
La soumission du job dans Nomad nous montre que le placement a lancé les conteneurs sur le seul nœud qui répond à la contrainte :
$ nomad run job.hcl ==> Monitoring evaluation "010099c5-b186-b951-b89e-67ba08eb4ccb" Evaluation triggered by job "my-service" Allocation "56258a1d-a861-9f40-23bc-5984936a2aa3" created: node "coreos-nomad-client1", group "webs" Allocation "86222b27-69d7-4ea2-aee9-c14a8aa484e4" created: node "coreos-nomad-client1", group "webs" Allocation "eb585d75-61d2-9ec5-18c7-b3be83b76a71" created: node "coreos-nomad-client1", group "webs" Evaluation status changed: "pending" -> "complete" ==> Evaluation "010099c5-b186-b951-b89e-67ba08eb4ccb" finished with status "complete"
La confirmation nous est donnée par la commande de détail du job en cours :
$ nomad status my-service ID = my-service Name = my-service Type = service Priority = 50 Datacenters = dc1 Status =
==> Evaluations ID Priority TriggeredBy Status 010099c5-b186-b951-b89e-67ba08eb4ccb 50 job-register complete
==> Allocations ID EvalID NodeID TaskGroup Desired Status 56258a1d-a861-9f40-23bc-5984936a2aa3 010099c5-b186-b951-b89e-67ba08eb4ccb coreos-nomad-client1 webs run running 86222b27-69d7-4ea2-aee9-c14a8aa484e4 010099c5-b186-b951-b89e-67ba08eb4ccb coreos-nomad-client1 webs run running eb585d75-61d2-9ec5-18c7-b3be83b76a71 010099c5-b186-b951-b89e-67ba08eb4ccb coreos-nomad-client1 webs run running
Swarm

Docker Swarm est l'orchestrateur de Docker Inc. Il a la particularité d'exposer une API compatible avec celle de Docker Engine, permettant une réutilisation native des clients Docker, comme Docker Compose.
Labellisation des nœuds
La labellisation du nœud s’effectue en ajoutant l’option --label sur la ligne de commande du démon Docker :
# /etc/systemd/system/docker.service.d/10-env.conf
[Service]
Environment="DOCKER_OPTS=-H=0.0.0.0:2376 -H unix:///var/run/docker.sock --cluster-advertise eth0:2376 --cluster-store etcd://10.0.3.30:2379 --label disktype=hdd"
Une fois les démons redémarrés, il est possible de vérifier que les swarm masters ont intégrés la présence de ce label sur les nœuds :
$ docker info Containers: 0 Running: 0 Paused: 0 Stopped: 0 Images: 0 Role: replica Primary: 10.0.3.33:2375 Strategy: spread Filters: health, port, dependency, affinity, constraint Nodes: 3 coreos-swarm-node1: 10.0.3.34:2376 └ Status: Healthy └ Containers: 0 └ Reserved CPUs: 0 / 1 └ Reserved Memory: 0 B / 1.023 GiB └ Labels: disktype=hdd, executiondriver=native-0.2, kernelversion=4.4.1-coreos, operatingsystem=CoreOS 955.0.0, storagedriver=overlay └ Error: (none) └ UpdatedAt: 2016-02-16T21:57:05Z coreos-swarm-node2: 10.0.3.35:2376 └ Status: Healthy └ Containers: 0 └ Reserved CPUs: 0 / 1 └ Reserved Memory: 0 B / 1.023 GiB └ Labels: disktype=ssd,executiondriver=native-0.2, kernelversion=4.4.1-coreos, operatingsystem=CoreOS 955.0.0, storagedriver=overlay └ Error: (none) └ UpdatedAt: 2016-02-16T21:56:51Z coreos-swarm-node3: 10.0.3.36:2376 └ Status: Healthy └ Containers: 0 └ Reserved CPUs: 0 / 1 └ Reserved Memory: 0 B / 1.023 GiB └ Labels: disktype=hdd,executiondriver=native-0.2, kernelversion=4.4.1-coreos, operatingsystem=CoreOS 955.0.0, storagedriver=overlay └ Error: (none) └ UpdatedAt: 2016-02-16T21:56:46Z Plugins: Volume: Network: Kernel Version: 4.4.1-coreos Operating System: linux Architecture: amd64 CPUs: 3 Total Memory: 3.068 GiB Name: coreos-swarm-master1 Experimental: true
Lancement de conteneurs
La syntaxe de contraintes d’affinité ou anti-affinité de Swarm est décrite dans la documentation comme des filtres. Elle est injectée dans Swarm sous forme de pseudo variables d’environnement associées aux conteneurs :
$ docker run -d -P -e constraint:disktype==hdd --name nginx1 nginx 0083a290e6cd82259a13f53932cbda59a4f420880111380f2980e1917c712b3f $ docker run -d -P -e constraint:disktype==hdd --name nginx2 nginx fba57999d5d9a70da6e7b03f06d62232742bea2420e4b970b38c40d1eb4c4587 $ docker run -d -P -e constraint:disktype==hdd --name nginx3 nginx f0cd897bbe09b7467e5b9e85592e3c0942a8656925bc1b3643d1157a3c51570a
Vérifions que le scheduleur a honoré la contrainte :
$ docker ps --format='{{ .ID }} {{ .Image }} {{ .Names }}' f0cd897bbe09 nginx coreos-swarm-node3/nginx3 fba57999d5d9 nginx coreos-swarm-node3/nginx2 0083a290e6cd nginx coreos-swarm-node1/nginx1
Nous sommes bien en présence de conteneurs qui ne tournent que sur les nœuds répondant à la contrainte.
Kubernetes

Kubernetes est l'orchestrateur de conteneurs écrit par Google. Il est le fruit d'années d'expérience du Géant du Web dans l'utilisation à très grande échelle de conteneurs Linux. Il est capable de lancer des conteneurs Docker ou rkt.
Labellisation des nœuds
La labellisation des nœuds peut être effectuée dans Kubernetes à n’importe quel moment via la ligne de commande :
$ kubectl label no/10.0.3.71 disktype=ssd $ kubectl label no/10.0.3.72 disktype=hdd $ kubectl label no/10.0.3.73 disktype=hdd
La vérification est possible simplement en listant les nœuds du cluster.
$ kubectl get nodes NAME LABELS STATUS AGE 10.0.3.71 disktype=ssd,kubernetes.io/hostname=10.0.3.71 Ready 3h 10.0.3.72 disktype=hdd,kubernetes.io/hostname=10.0.3.72 Ready 3h 10.0.3.73 disktype=hdd,kubernetes.io/hostname=10.0.3.73 Ready 3h $ kubectl get nodes -l disktype=hdd NAME LABELS STATUS AGE 10.0.3.72 disktype=hdd,kubernetes.io/hostname=10.0.3.72 Ready 3h 10.0.3.73 disktype=hdd,kubernetes.io/hostname=10.0.3.73 Ready 3h
Lancement de conteneurs
La définition d'un pod ou d'un ReplicationController avec des contraintes de placement s’effectue au travers de l’attribut NodeSelector :
apiVersion: v1
kind: ReplicationController
metadata:
labels:
run: my-nginx
name: my-nginx
namespace: default
spec:
replicas: 2
selector:
run: my-nginx
template:
metadata:
labels:
run: my-nginx
spec:
containers:
- image: nginx
name: my-nginx
ports:
- containerPort: 80
protocol: TCP
nodeSelector:
disktype: hdd
Pour créer le ReplicationController :
$ kubectl create -f rc.yaml
Pour vérifier le placement de pods créés :
$ kubectl get podes -o wide NAME READY STATUS RESTARTS AGE NODE my-nginx-8td6t 1/1 Running 1 2h 10.0.3.72 my-nginx-cx34v 1/1 Running 1 2h 10.0.3.73
Conclusion
Les quatre produits testés montrent une capacité tout à fait correcte à gérer des affinités avec les nœuds :
| Fleet | Nomad | Swarm | Kubernetes | |
|---|---|---|---|---|
| Version testée | 0.11.5 | 0.2.3 | 1.1.1 | 1.1.7 |
| Affinité aux nœuds | oui | oui | oui | oui |
| Labellisation des nœuds à chaud | non | non | non | oui |
| mot-clé dans la description des jobs | MachineMetaData | contraint | constraint | nodeSelector |
Remarques
En cas d’impossibilité de satisfaire les contraintes, le comportement des schedulers se traduira différemment en fonction des moteurs : Nomad et Kubernetes acceptent la création, en espérant pouvoir la satisfaire plus tard, Swarm échoue directement, Fleet bloque la commande jusqu’à ce que la contrainte soit satisfaite.
Nous avons poussé l'exercice jusqu'à tester le comportement des clusters en cas de déplacement des labels des nœuds. À l’exception de Fleet, la relabellisation des nœuds ne déclenche pas le déplacement des pods existants, mais interviendra lors des prochaines demandes de scheduling. L’administrateur est donc amené à manuellement re-soumettre les jobs ou détruire les conteneurs mal placés en cas de changement de la labels.
Pour aller plus loin
Pour aller plus loin sur les contraintes d’affinité sur les nœuds ou si vos besoins s’avèrent plus compliqués que cet exemple, n'hésitez pas à aller creuser dans les documentations ou le code source des projets.
Nous verrons dans un prochain article dans quelle mesure les moteurs de cluster permettent également des règles d’anti-affinité entre conteneurs.