Stratégie d’architecture API
Nous revenons sur le sujet API, deux ans après notre « Quick Reference Card » sur les stratégies d'architecture API dont l’objectif est de synthétiser les points structurants qu’il convient de résoudre, lors de la mise en œuvre d'une API en tant que produit. Les thèmes abordés constituent les sujets récurrents que nous avons rencontré chez nos clients, lors de la mise en oeuvre de leur API, les trois dernières années.

Si vous avez plus de temps, le présent article reprend – point par point – les éléments de la « carte de référence », en étayant et justifiant les propositions. Le menu vous permet de faire du pick and choose entre les différentes sections : les paragraphes sont auto-portants et comportent des redites.
Bonne lecture!
DISCLAIMER : Nos préconisations s'appuient sur un « état de l'art API » inspiré par les Géants du Web en terme de culture, pratiques et architecture. Cet article constitue un recueil de bonnes pratiques issues de notre expérience, qui peuvent bien entendu être discutées et qui ne peuvent en aucun cas être appliquées à la lettre sans être contextualisées. Nous proposons une vision et traitons des problématiques d’architecture et organisationnelles pour lesquelles il n’existe pas une solution unique. Nous vous invitons à participer à la réflexion et à challenger ces choix sur notre blog ou lors du meetup Paris API auquel nous participons régulièrement. Cet article porte sur les « API as a Product », c'est à dire sur l'API d'une entreprise exposée « en tant que produit » sur l'internet et qui repose sur un modèle d'affaire. Une API technique par exemple qui serait réalisée pour être dédiée à une application front (qui est le produit) n'entre pas dans le périmètre de cette étude.
Introduction
Pourquoi bâtir une API ?
La « transformation digitale » est devenue un voyage épique dont on discerne difficilement les contours. Elle se traduit souvent par la mise en oeuvre de nombreux chantiers d'une gageure fantaisiste, dont certains n'ont pas de réel rapport avec le numérique. Nous pensons néanmoins que deux problématiques fondamentales doivent être résolues pour adresser cette nouvelle ère numérique :
ATAWAD
Ces dernières années, une multitude de terminaux digitaux sont apparus. Nos utilisateurs sont mobiles. Nous souhaitons adopter une démarche customer-centric en leur offrant une expérience omnicanal et cross-devices. La capacité à bâtir des applications front rapidement sur cette myriade de terminaux (dont la mode vestimentaire est changeante) est devenue une nécessité. L’API, en capitalisant sur une couche de services, exposée sur l'internet, apporte une réponse concrète à cette problématique.

Ouverture du SI
L’ouverture du système d’information est un enjeu majeur pour développer de nouveaux modèles d’affaires et accélérer l'innovation. Nous pensons que ce point constitue le moteur de l'économie numérique. La démarche Open API est une manière d’y répondre.

En répondant à ces deux enjeux, nous pensons que l’API est le vecteur qui offre la capacité à industrialiser sa présence dans le digital.
Définitions
API
L’acronyme API désigne une interface normalisée par laquelle un logiciel offre des services à un autre logiciel.
Aujourd'hui, les entreprises souhaitent proposer un accès à leur système d'information via une API. Dans ce contexte, le terme API désigne en fait une Web API, c’est à dire la couche d’exposition d’un système sur l'internet, via le protocole HTTP.
Le développement d’une API porte donc essentiellement sur la logique d’exposition des ressources et le système de persistance sous-jacent. L’interface utilisateur et la logique métier peuvent ainsi être développées par des tiers, probablement plus experts dans les technologies d’interface et les problématiques ergonomiques, ou dans les métiers spécifiques.
Le système expose donc une API, c’est à dire un ensemble de ressources. Les applications finales reposent sur la composition de plusieurs ressources provenant éventuellement de systèmes disjoints : nous parlons de mashup (ou application composite). C’est par exemple le cas avec HousingMaps.com : le site permet de visualiser les petites annonces issues de l’API CraigsList.org au travers de l’API Google Maps.
Le pattern rejoint ainsi les principes majeurs des architectures orientées service (SOA) : le découplage et la possibilité de composition. Les architectures des Géants du Web, presque exclusivement basées sur le style REST, ont été longtemps opposées aux architectures SOA d’entreprises, majoritairement basées sur SOAP. Au début des années 2000, la communauté IT a subi une véritable scission suite aux polémiques opposant ces deux styles d’architectures. Or les APIs REST sont une forme de SOA, dont l’objectif est d'utiliser HTTP comme protocole applicatif. L’enjeu est d'homogénéiser et de faciliter les interactions entre SI, pour ne pas avoir à façonner un protocole « maison » qui a l'inconvénient de « réinventer la roue » à chaque fois. Nous appelons ce style d’architecture pas piqué des hannetons : les architectures orientées Web (WOA).

SOAP se traduit par un standard lourd qui applique les principes RPC visant à unifier le modèle de programmation distribué et local par l’intermédiaire d’un proxy (stub cachant l'appel distant). A contrario, la WOA s’appuie explicitement sur le Web pour tirer partie de sa nature distribuée, de ses forces (universalité, ouverture, etc.) et faiblesses (latence, coupure réseau, etc.).
La volonté d’exposer une couche de services date des années 2000. Quelle « révolution » apporte l’API ? Pour y répondre, nous proposons notre définition de l’API lorsqu'elle est réalisée en tant que produit marketing : L’API est l’industrialisation du processus de consommation des ressources (REST) de l’entreprise.
La première « révolution » est REST. L’API est une implémentation de la SOA qui « embrasse » les standards du Web :
- une modélisation orientée ressource (et non opération),
- qui tire partie des forces du standard HTTP et des architectures Web déjà en place et maîtrisées depuis les années 90,
- et qui permet une consommation par tout type de terminal numérique et navigateur internet.
La seconde « révolution » réside dans l’industrialisation du processus de consommation des « services » de l’entreprise. Nous étions d’ores et déjà capables d’échanger des données avec des partenaires, souvent via la définition d’un contrat, une sécurisation chronophage et non industrialisée de type VPN (ou WS-Security pour les plus téméraires) et le lancement d’un projet entre les deux parties qui pouvait s’étaler sur plusieurs mois. Aujourd’hui, avec l’explosion du nombre de terminaux (devices) et de consommateurs, cette stratégie point-à-point ne tient plus. Le marketing ne souhaite plus lanterner pour « combattre » la flotte armée du digital. Les fournisseurs ciblent désormais une consommation des ressources en quelques minutes par un développeur, qu’il soit interne ou externe à l’entreprise. Pour permettre cela, l’API inclut un « outillage » (cf portail développeur) et démocratise l’accès au SI via une interface intelligible. Une stratégie API repose donc sur deux points :
- la mise en oeuvre d'une API REST,
- la mise en oeuvre d'un outillage qui permet son industrialisation (API Management).
Plusieurs entreprises s’inscrivent aujourd'hui dans cette démarche API initiée par les Géants du Web.
Open API
Le principe Open API consiste à bâtir un « écosystème ouvert » via l’exposition de services utilisables par des tiers, sans avoir d’idée préconçue sur l’usage qui en sera fait.
Cette stratégie d'écosystèmes ouverts permet de :
- créer des revenus directs en les facturant. Exemple : Google Maps devient payant au delà de 25000 transactions par jour,
- étendre une communauté et donc recruter des utilisateurs. Exemple : grâce aux applications dérivées de sa plateforme, Twitter a atteint 140 millions d’utilisateurs actifs (et 500 millions d’inscrits),
- faire émerger de nouveaux usages pour sa plateforme et donc faire évoluer son modèle de revenu. Exemple : en 2009, Apple a constaté que les développeurs d’applications souhaitaient vendre non seulement des applications, mais aussi des contenus pour leurs applications. Le modèle de l’AppStore a donc évolué pour intégrer cette possibilité,
- parfois, externaliser leur R&D, puis racheter les startups les plus talentueuses. C’est ce qu’a fait Salesforce avec Financialforce.com.
API First
Le pattern API First est un dérivé du pattern Open API : il suggère de commencer par bâtir une API, puis de la consommer y compris en interne pour construire les applications destinées aux utilisateurs finaux.
L’idée est de se mettre au même niveau que les utilisateurs de l’écosystème, donc de s’appliquer à soi même les principes d’architecture que nous proposons à nos clients, selon le pattern « Eat Your Own Dog’s Food » (EYODF).
Design d’API
Les enjeux
Lorsque nous souhaitons concevoir une API, nous sommes rapidement confrontés à la problématique du « design d’API ». Ce point constitue un enjeu majeur, dans la mesure où une API mal conçue sera vraisemblablement peu ou pas utilisée par les clients : les développeurs d’applications.
Selon nous, une API bien conçue :
- respecte les standards HTTP,
- s’inspire des bonnes pratiques des Géants du Web, les développeurs d'applications étant habitués à les consommer,
- est simple d’usage (KISS),
- offre une bonne affordance (c-a-d la capacité d’un objet à suggérer sa propre utilisation),
- est agnostique des consommateurs.
Nous avons publié nos convictions sur le design d’API RESTful. Si le sujet vous intéresse, n’hésitez pas à consulter notre article « Designer une API REST ».

Les douleurs généralement constatées
Nos expériences nous ont montré que la démarche de design n'est jamais une chose aisée. Les « douleurs » que nous avons généralement constaté sont les suivantes :
la première difficulté pour les équipes est de « migrer » vers un état d'esprit ressource,
on entend souvent la phrase : « mon métier est complexe ». Mais nous sommes jusqu'ici toujours parvenu à designer une API REST avec nos clients,
la montée en compétence sur REST et HTTP (notamment pour les profils non techniques : marketing, métier, MOA, business analystes, etc.),
la capacité à faire des choix pour les problématiques de design ou HTTP ne donne pas de solution clé en main (il n'existe alors pas de réponse universelle et a réponse est souvent culturelle : cf notre refcard),
la démarche de design entre de nombreux acteurs est souvent passionnée fait régulièrement l'objet de réunions fleuves et de débats prolixes: « je pense qu'il faut mettre un 's' ». Si bien qu'il nous arrive d'être mandaté pour statuer et accélérer le processus de design,
enfin la démarche de construction réalisée « à l'aveugle », dans une optique de réutilisation, est un véritable travail d'équilibriste : on oscille entre les premiers besoins identifiés (pour un MVP par exemple) et les besoins génériques que l'on anticipe : il est facile de re-basculer dans une démarche point à point ou d'exposer une API complexe comme ça a été souvent le cas en SOAP. La pression exercée par les contraintes projet de la première application consommatrice (application mobile, échange partenaire, etc.) demeure. Les API REST n'apportent aucune solution pour ces aspects de gouvernance.
Puristes vs pragmatiques
Lorsque l'on design une API, deux approches s’opposent : celle des « puristes », qui militent pour défendre les principes RESTful sans concession, et celle des « pragmatiques » qui privilégient une approche plus pratique, pour que leur API soit fonctionnelle entre les mains d’utilisateurs réels. Le modèle de maturité REST de Richardson illustre les quatre niveaux possibles. En pratique, nous avons constaté que la majorité de nos clients ciblaient le niveau 2 (pragmatiques). Quelques-uns de nos clients partent sur le niveau 3 (puristes) en intégrant la mise en oeuvre de HATEOAS.
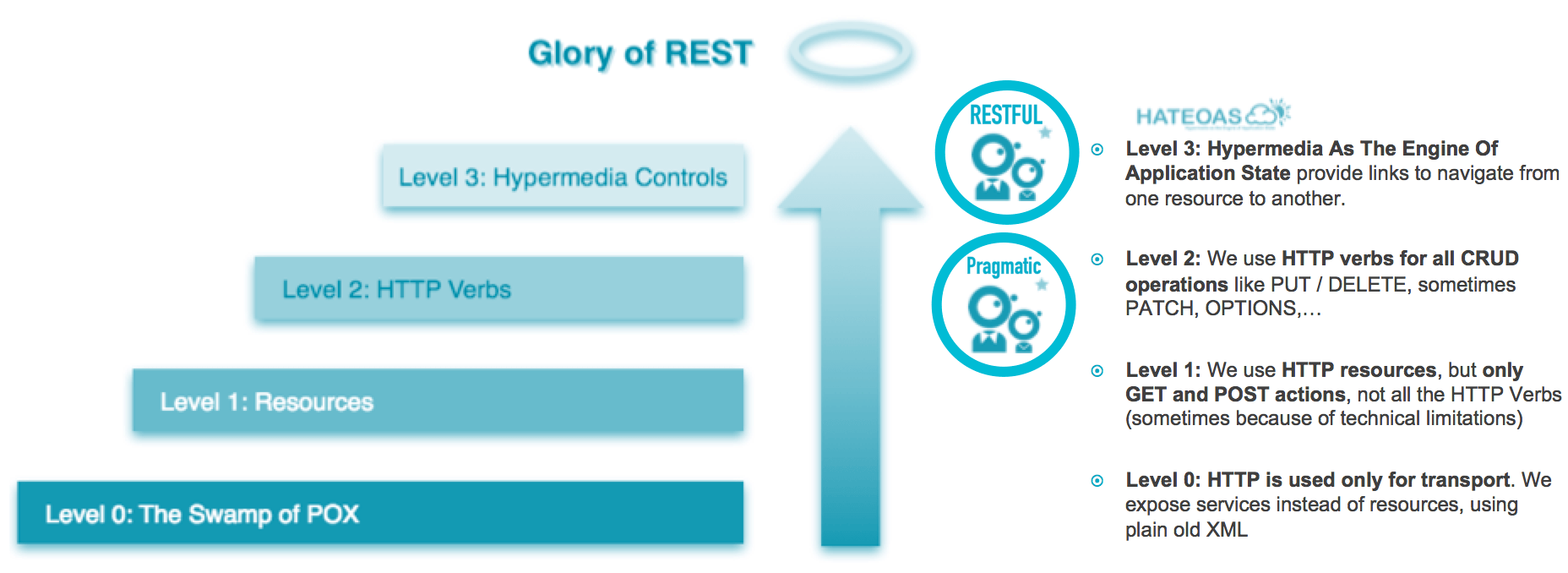
Niveaux d’ouverture d’une API
En marge du modèle de maturité REST de Richardson, nous distinguons trois niveaux d’ouverture d’une API :
- Niveau 1 « Private API » : l’API est destinée à être consommée par les applications développées au sein de l’entreprise.
- Niveau 2 « Partners API » : l’API est destinée à être consommée par les applications développées au sein de l’entreprise ou par des partenaires.
- Niveau 3 « Open API » : l’API est destinée à être consommée par tout type de développeurs.

La différence entre chaque niveau réside principalement dans la qualité du processus d’industrialisation de consommation des services qu’il convient de mettre en œuvre :
- au niveau 1, un développeur d’application est contraint de consommer l’API et peut - en cas de difficultés - directement contacter l’équipe API : « Angelina, je ne comprends pas comment fonctionne ce endpoint ! »
- au niveau 3, le succès d’une API, qui peut être consommée par des milliers d’utilisateurs sur la toile, dépend de la facilité du processus d'enrôlement et des qualités intrinsèques de l’API et de sa documentation
Nous recommandons de cibler le niveau 3, même si votre API n’est pas destinée à être ouverte à court terme. Le fait de cibler des développeurs extérieurs modifie la manière de concevoir des « services » :
proposer des ressources sans connaître tous les cas d’usages : c’est une démarche « à l’aveugle* »,
en ciblant les niveaux 1 ou 2, le risque est de retomber dans une démarche point à point en ciblant des cas d'usages spécifiques,
vulgariser au maximum l'API, en partageant un vocabulaire intelligible,
industrialiser le processus de consommation des ressources grâce à un portail développeur.
*Notons qu'en pratique, pour designer une API, nous nous appuyons systématiquement sur les besoins exprimés par un consommateur (une application front, un partenaire, etc.) dans le cadre d'un MVP. Nous tentons ensuite de d'adapter l'API pour anticiper sur les besoins ultérieurs, sans en connaitre le contexte. Ce principe de construction n'est jamais évidant : il s'agit de rester KISS, de time-boxer la « démarche funambule » de conception et de jongler entre les besoins exprimés et une anticipation des besoins globaux.
SOAP vs REST
La polémique
Dès l’apparition de la SOA, l’approche SOAP/WS-* a été controversée. La promesse de l'interopérabilité du protocole tenait à la bonne volonté des contributeurs (W3C, OASIS, les éditeurs de serveurs d'applications). Cette promesse ne s'est jamais réalisé suite à leurs divergences et à la difficulté d'aligner l'ensemble de ces acteurs. Si bien qu’en parallèle le style d’architecture REST s’est développé, basé sur un standard existant, porté par les Géants du Web. L’objectif était de proposer une version plus simple de la SOA, embrassant les caractéristiques et les technologies fondamentales du Web (ses forces et ses contraintes) plutôt que de chercher à les abstraire, à les combattre.
Les critiques d'une insolence claironnante ont été virulentes à l’égard de SOAP, avec un pic constaté en 2007.
Nick Gall [VP Gartner Group]
« WS-* style Web Services are "Web" in name only… The W3C should extricate itself from further direct work on SOAP, WSDL, or any other WS-* specifications » 2007 - https://www.w3.org/2007/01/wos-papers/gall
David Orchard [Web Services standards – BEA]
« Given the complexity of just SOAP and WSDL, how many developers will really be able to move to the full stack?... The promise of WSDL 2.0 has not materialized and is unlikely to do so » 2007 - https://www.w3.org/2007/01/wos-papers/bea
Steve Loughran [Apache Axis commiter]
« The only place SOAP survives is in the enterprise because if you can control both ends of the conversation, you can use the same toolkit and eliminate interop » 2007 - http://www.1060.org/blogxter/entry?publicid=6A6BBC2438A838170B0FD803AE83283F
La simplicité de REST
Afin d'illustrer la différence entre les approches REST et SOAP, l'exemple suivant montre comment réaliser une addition.

REST
La requête
GET https://api.{fakecompany}.com/sum?a=40&b=2
La réponse
42
La documentation
La ressource « somme » est la somme de deux paramètres entiers
a et b, représentée par une chaîne de caractères.
SOAP
La requête
<?xml version="1.0" encoding="UTF-8" ?>
<soapenv:Envelope xmlns:soapenv="http://schemas.xmlsoap.org/soap/envelope/"
xmlns:xsd="http://www.w3.org/2001/XMLSchema"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance">
<soapenv:Body>
<ns0:additionner
xmlns:ns0="http://axis.test.com"
soapenv:encodingStyle="http://schemas.xmlsoap.org/soap/encoding/">
<valeur1 xsi:type="xsd:int">40</valeur1>
<valeur2 xsi:type="xsd:int">2</valeur2>
</ns0:additionner>
</soapenv:Body>
</soapenv:Envelope>
La réponse
<soapenv:Envelope xmlns:soapenv="http://schemas.xmlsoap.org/soap/envelope/"
xmlns:xsd="http://www.w3.org/2001/XMLSchema"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance">
<soapenv:Body>
<ns1:additionnerResponse
xmlns:ns1="http://axis.test.com"
soapenv:encodingStyle="http://schemas.xmlsoap.org/soap/encoding/">
<additionnerReturn href="#id0" />
</ns1:additionnerResponse>
<multiRef xmlns:soapenc="http://schemas.xmlsoap.org/soap/encoding/"
id="id0" soapenc:root="0"
soapenv:encodingStyle="http://schemas.xmlsoap.org/soap/encoding/"
xsi:type="xsd:long">42</multiRef>
</soapenv:Body>
</soapenv:Envelope>
La documentation (WSDL)
<?xml version="1.0" encoding="UTF-8"?>
<wsdl:definitions targetNamespace="http://axis.test.com"
xmlns:apachesoap="http://xml.apache.org/xml-soap"
xmlns:impl="http://axis.test.com"
xmlns:intf="http://axis.test.com"
xmlns:soapenc="http://schemas.xmlsoap.org/soap/encoding/"
xmlns:wsdl="http://schemas.xmlsoap.org/wsdl/"
xmlns:wsdlsoap="http://schemas.xmlsoap.org/wsdl/soap/"
xmlns:xsd="http://www.w3.org/2001/XMLSchema">
<!--WSDL created by Apache Axis version: 1.3
Built on Oct 05, 2005 (05:23:37 EDT)-->
<wsdl:message name="additionnerRequest">
<wsdl:part name="valeur1" type="xsd:int"/>
<wsdl:part name="valeur2" type="xsd:int"/>
</wsdl:message>
<wsdl:message name="additionnerResponse">
<wsdl:part name="additionnerReturn" type="xsd:long"/>
</wsdl:message>
<wsdl:portType name="Calculer">
<wsdl:operation name="additionner" parameterOrder="valeur1 valeur2">
<wsdl:input message="impl:additionnerRequest" name="additionnerRequest"/>
<wsdl:output message="impl:additionnerResponse" name="additionnerResponse"/>
</wsdl:operation>
</wsdl:portType>
<wsdl:binding name="CalculerSoapBinding" type="impl:Calculer">
<wsdlsoap:binding style="rpc" transport="http://schemas.xmlsoap.org/soap/http"/>
<wsdl:operation name="additionner">
<wsdlsoap:operation soapAction=""/>
<wsdl:input name="additionnerRequest">
<wsdlsoap:body encodingStyle="http://schemas.xmlsoap.org/soap/encoding/"
namespace="http://axis.test.com" use="encoded"/>
</wsdl:input>
<wsdl:output name="additionnerResponse">
<wsdlsoap:body encodingStyle="http://schemas.xmlsoap.org/soap/encoding/"
namespace="http://axis.test.com" use="encoded"/>
</wsdl:output>
</wsdl:operation>
</wsdl:binding>
<wsdl:service name="CalculerService">
<wsdl:port binding="impl:CalculerSoapBinding" name="Calculer">
<wsdlsoap:address location="http://localhost:8080/TestWS/services/Calculer"/>
</wsdl:port>
</wsdl:service>
</wsdl:definitions>
« If you can't explain it to a six year old, you don't understand it yourself ». Albert Einstein
Cette exemple illustre que REST peut être bigrement simple et intelligible : lorsque l'on « ouvre le tuyau », on comprend ce qui transite sur le réseau. Le développeur d'application qui consomme l'API n'a pas besoin d'un toolkit évolué pour abstraire la technicité de l'échange.
Styles d'architecture
Mais en fait, qu’est-ce qui dissocie ces deux approches ? Et bien « SOAP vs REST », c’est en fait une une question de Style d’architecture. 
Les styles d’architecture SOAP et REST s’opposent fondamentalement sur trois niveaux, illustrés par le tableau ci-dessous :
| SOAP/RPC | REST |
|---|---|
| Modélisation par opération | Modélisation par ressources |
| --- | --- |
| Cherche à unifier le modèle de programmation distribué et local par l’intermédiaire d’un proxy | Modèle de programmation distribué explicite, et basé sur le WWW |
| --- | --- |
| Repose sur un toolkit pour être interprété | Mise sur une bonne expérience développeurs tous niveaux |
| --- | --- |
| Consommé que par des serveurs | Consommé par tout type de device, y compris les serveurs |
| --- | --- |
La tendance REST
Aujourd’hui si les principes substantiels de la SOA ne sont pas remis en cause, on considère que REST l’a emporté sur SOAP. 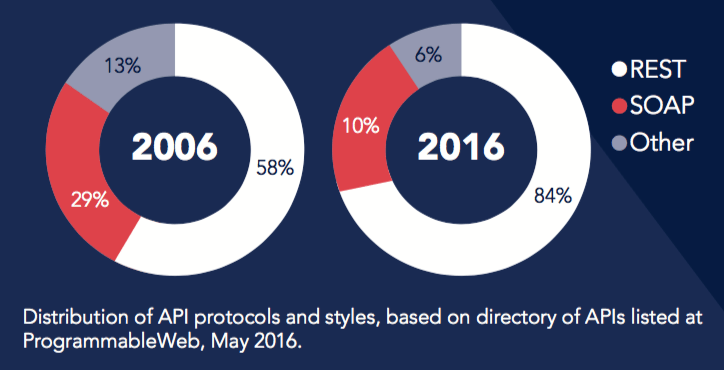
| API | REST | SOAP | Comments |
|---|---|---|---|
| Amazon S3 | X | X | "SOAP support over HTTP is deprecated, but it is still available over HTTPS. New Amazon S3 features will not be supported for SOAP. We recommend that you use either the REST API or the AWS SDKs." |
| --- | --- | --- | --- |
| Amazon EC2 | X | - | |
| --- | --- | --- | --- |
| X | - | ||
| --- | --- | --- | --- |
| Google cloud, maps, apps, plus, youtube, etc. | X | - | |
| --- | --- | --- | --- |
| X | - | ||
| --- | --- | --- | --- |
| Paypal | X | X | |
| --- | --- | --- | --- |
| X | - | ||
| --- | --- | --- | --- |
| X | - | ||
| --- | --- | --- | --- |
| X | - | ||
| --- | --- | --- | --- |
| TripAdvisor | X | - | |
| --- | --- | --- | --- |
| Expedia Affiliate Network | X | X | "EAN has discontinued support for SOAP. See our SOAP to REST migration guide for details on changes required for affected integrations." |
| --- | --- | --- | --- |
SOAP est-il mort ?
SOAP n’est pas mort, non ! : « SOAP is Not Dead - It's Undead, a Zombie in the Enterprise ». 
Vous l’aurez compris, nous préconisons vigoureusement que votre stratégie API soit basée sur REST et la WOA. Cela ne remet pas nécessairement en cause votre implémentation SOAP existante qui peut parfaitement répondre à un certain nombre d'usages . Mais pour réaliser de nouveaux « services », compte tenu des nouveaux enjeux (explosion du nombre de terminaux émergents et l’ouverture du SI), la question de la mise en œuvre d’une API doit être posée.
QUID de ma couche de Web Services existante ?
De nombreuses entreprises ont misé sur les architectures SOA dès les années 2000. Ce fut notamment l’âge d’or des WebServices SOAP encore très utilisés aujourd’hui. Mais lorsqu’un besoin d’API émerge, une question se pose : pouvons-nous bâtir nos APIs sur la couche SOA existante ?
Nous avons observé chez plusieurs de nos clients qu’un chantier API construit sur une couche SOAP se transforme fréquemment en chantier d’urbanisation des services existants. Il apparaît que ces services n’ont pas été conçus dans une optique de réutilisation, pourtant fondamentale, et ne répondent pas aux besoins de simplicité, de documentation et de self-service.
Dans ce cas là, la création d’APIs cristallise des difficultés jusque là ignorées.
Dans les cas extrêmes, un « travestissement » est réalisé via l’achat d’une solution d’API Management, en apportant des améliorations ponctuelles (monitoring, accounting…). Les services sont alors « maquillés » de SOAP XML en JSON et restent fondamentalement inchangés. Les APIs réalisées sont dès lors bien loin des standards RESTful, de l’exemple des Géants du Web, et ne répondent toujours pas aux enjeux.
Nous pensons qu’il est souvent préférable de dissocier la gateway SOAP existante de l’API à concevoir, en ciblant les nouveaux enjeux :
- Design d’une API RESTful.
- DX (Developer eXperience).
- API cross-device et omni-canal.
- Industrialisation de l’enrôlement via un portail développeur et optimisation du TTFAC*.
*Le TTFAC (Time To First API Call) désigne le temps nécessaire à un développeur pour réaliser un 1er appel d’API, après avoir consulté la documentation sur le developer portal. C’est un bon moyen pour mesurer la qualité du design et du portail développeur
Les deux stratégies sont illustrées sur l'illustration suivante :

Bien entendu, notre préconisation de cibler une « API REST à l'état de l'art » doit être pondérée. Dans certains cas, si l'on cible une API de niveau 0 ou 1 sur le modèle de maturité Richardson, une stratégie de transcodage des services SOAP existants peut s'avérer pertinente. Dans d'autre cas, si l'explosion du nombre de consommateurs « digitaux » n'est pas une certitude, et si l'ouverture des données n'est pas un enjeu, il peut être préférable de capitaliser sur les web services SOAP existants et l'ESB qui est peut être en place, plutôt que de vouloir surfer à tout prix sur la vague API.
Les trois dernières années, pour nos clients désireux de bâtir une API et qui possédaient un existant SOAP, nous avons constaté sur le terrain les trois scénarios suivants :
- Publier une API telle quelle avec les services SOAP existants : aucun client n'est finalement parti sur cette piste : 0%.
- Mise en oeuvre d'une façade API (REST over SOAP)
- via un outil ESB ou la brique de transcodage d'une solution d'API management : 10%,
- via une façade développée en spécifique : 70%.
- Exposition depuis les applications référentielles : 20%
Enjeux d’architecture
Plusieurs enjeux d'architecture interviennent dans le cadre de la mise en œuvre d’une API et sont abordés dans cette section. 
Stateless
Stateless signifie que votre API ne doit conserver aucun contexte entre deux appels successifs. Chaque appel est autoportant et son effet ne dépend que de l’état des ressources au moment de l’appel.
On ne parle donc pas d’absence d’état, mais au contraire de deux états bien distincts qu’il est recommandé de séparer :
- Le client est responsable de l’état de l’application (navigation, session utilisateur authentifiée, enrichissement de l’expérience utilisateur).
- Le serveur est responsable de l’état de ses ressources (persistance, cohérence, transitions entre états).
Le principaux bénéfices de cette séparation sont :
- simplifier l’implémentation du serveur (on m’envoie X, je réponds Y, rien d’autre à gérer, je suis user agnostic),
- rendre les requêtes cachable (on m’envoie X, je répondrai toujours Y => mettons cela en cache),
- gagner en résilience et scalabilité :
- plus de “session utilisateur” consommatrice de mémoire coté serveur,
- plus de “sticky session” au niveau du loadbalancer,
- pas de problématique de réplication de session entre noeuds applicatifs, impactant la complexité, la robustesse et la performance globale de l’architecture.
La mise en place d’architectures REST est enfin l’occasion de revenir dans le droit chemin du WEB : un client qui interagit de manière transparente avec un serveur via un protocole sans état.
Microservices
Un microservice possède trois caractéristiques fondamentales :
- Un microservice est roi de son domaine : il maîtrise son périmètre fonctionnel et est autonome vis-à-vis des autres services.
- Un microservice possède une interface explicite de communication. Elle abstrait totalement ses états internes, ne donne pas un accès direct à ses données.
- Un microservice peut être déployé indépendamment des autres composants du SI.
Nous savons que pour la mise en place d'une API REST est fortement liée avec l'organisation des équipes. L’architecture microservices répond bien aux nouveaux enjeux d'architectures « modernes » : scalables, résilientes et découplées.
L'un des atouts majeurs de cette architecture est de répondre aux enjeux de cloisonnement et de scaling technique et organisationnelle :
- Scaling technique : en découpant un « monolithe » en sous unités d’exécution, il est possible de scaler de manière fine le système en fonction des usages. Les technologies mises en oeuvre peuvent alors être totalement hétérogènes, et en adéquation avec les besoins d'un système technique spécifique. L'enjeux porte sur sur les aspects de résilience, de haute disponibilité et d'élasticité du système.
- Scaling organisationnel : au-delà d’une certaine taille (pizza teams), le poids de la communication et de la synchronisation étouffe un projet. Le séparer en microservices permet de découper également les équipes et donc de retrouver une efficacité accrue. Les développeurs doivent aujourd'hui choisir leur stack technique : le choix des outils et technologies n'est plus un sujet.

La mise en oeuvre d'une API via ce pattern consiste alors à bâtir différents resources providers autonomes, généralement sous la responsabilité d'équipes disjointes. Les cycles de vie, architectures et technologies peuvent alors être hétérogènes et adaptés aux besoins de chaque composant. Ce pattern est un des composants clés de la WOA, qui embrasse l’architecture du WWW : répartie, découplée où l’interopérabilité est garantie par le vecteur HTTP, y compris au sein du Système d’information. Le Système d'information peut alors être vu (en grossissant le trait) comme wikipedia : chaque appel de ressource donne une représentation et un ensemble de liens HATEOAS vers d'autres ressources, qui peuvent être servies indépendamment par d'autres systèmes techniques du SI.
Dans l'exemple suivant, un appel à /v1/customers/007 retourne les informations du client 007, ainsi que des liens vers d'autres ressources. Le panier peut être exposé par un autre système technique, sur d'autres technologies et sous la responsabilité d'une autre équipe (voir ce schéma) :
GET /v1/customers/007
{
"id": "007",
"firstname": "James",
"name": "Bond",
"_links": {
"self": {
"href": "/v1/customers/007"
},
"cart": {
"href": "/v1/customers/007/carts"
}
}
}
Limitations D'après nos expériences, la mise en oeuvre de ce type d'architectures décentralisées n'est jamais triviale et doit satisfaire aux pré-requis suivants :
maturité DEVOPS,
maturité sur les équipes short-cycle de type SQUAD,
et la présence de développeurs experts et passionnés au sein de ces équipes (technical leaders).
Low Latency & Asynchronisme
En lecture La lecture représente généralement la majorité de vos actions, et celles-ci doivent être performantes afin de construire une expérience utilisateur de qualité :
Mettre en place des caches (serveur ou client)
Introduire un CDN
Scaler les serveurs (horizontalement ou verticalement)
Introduire de nouvelles technologies si celles existantes sont à leur limite
Revoir l’implémentation
En écriture Les critères de performance vus précédemment s’appliquent toujours. En revanche de nouvelles techniques vont pouvoir être mises en place, pour éviter notamment les transactions longues :
- Fire and forget dans le cas où le client n’est intéressé que par la prise en compte de sa demande et non par son résultat.. L’API répond instantanément, la demande est prise en compte et le traitement est géré en interne de manière asynchrone.
- « Gestion de ticket » si le client est intéressé par le résultat d’une mise à jour. La ressource est instantanément créée ou mise à jour, en revanche un champ status permet de détecter l’issue du traitement (e.g. pending => completed).
- Callback et eventing : si le client est intéressé par le résultat de son action, alors une stratégie de callback peut être envisagée : cela permet au client d’être prévenu dès que possible que la demande a été bien traitée. Plusieurs approches sont possibles : HTTP 2.0 Server push, Websocket, HTML5 Server Sent Events, email, SMS, etc.
Non transactionnel
C’est un défaut que l’on oppose souvent aux architectures REST, qui est de ne pas fournir de fonctionnalités transactionnelles.
Concrètement prenons une ressource /accounts qui représenterait un compte en banque. Si, en tant que client, je souhaite faire un virement entre deux comptes, le fait de réaliser deux requêtes PATCH successives sur /accounts/{1} et /accounts/{2} sera hors contexte transactionnel. Si une exception se produit entre les deux actions, alors votre argent est potentiellement perdu dans le cyberespace…
Fondamentalement quel est le problème ?
- HTTP est un protocole requête/réponse,
- architecture stateless, vue précédemment : Donc pas de session utilisateur coté serveur, donc pas de contexte transactionnel coté serveur.
SOAP a tenté de fournir une spécification WS-Transactions / WS-Coordination pour permettre d’implémenter de la transaction distribuée (commit à 2 phases) sur le protocole HTTP. Seul les gros serveurs d’applications se sont aventurés dans ces territoires (websphere, weblogic, jboss) éminemment complexes à faire marcher et les retours d’expérience sont sans appel.
Dans le cadre d'une API REST, pour résoudre cette problématique, il existe deux solutions :
- utiliser une compensation fonctionnelle. Coté client, appeler une action de rollback (par exemple un appel à DELETE /accounts/{1} si PATCH /accounts/{2} échoue). Ou bien annuler la transaction coté serveur via un batch par exemple, et avertir l'utilisateur du comportement exceptionnel de manière asynchrone, tout rétablissant la cohérence du/des système(s)
- modéliser cette suite d’actions interdépendantes par une ressource unique (un message) qui fera alors l’objet d’un seul appel. Si on reprend l’exemple précédent, alors il devient évident que ce que l’on cherche à faire est d’enregistrer une transaction bancaire. La ressource POST /transaction, avec un corps de requête adapté sera alors plus évident. La garantie de l’atomicité et éventuellement de la réversibilité de l’action relève de l’implémentation de l’API et non de son utilisation correcte par les clients.
Notons enfin que si des propositions de mises en oeuvre sont formalisées (TCC), le principe des transactions par commit à deux phases est un réflexe souvent culturel qui a été challengé maintes fois. Notamment grâce à « l’illustration du fonctionnement de Starbucks qui n'utilise pas le commit à deux phases » mais un mécanisme de compensations fonctionnelles dans les très rares cas d'échecs : au final ça fonctionne.
Infrastructure
En général, la mise en oeuvre d’une API n'entraîne pas de modifications substantielles de l’infrastructure existante. En effet, l'infrastructure Web - déjà en place dans l’entreprise depuis les années 90 pour servir du contenu HTML - est intégralement ré-utilisée pour publier les « services » de l’entreprise, et donc induit des coûts maitrisés ! Les pratiques usuelles du Web comme les systèmes de cache, les CDN, TLS, etc. restent pertinentes pour la mise en oeuvre d’APIs.
Ouverture du SI : mise en oeuvre d'une brique d'API Management
Notons qu’un chantier API entraîne, de manière quasi systématique, la mise en oeuvre d’une nouvelle brique : l'API Management. Ce nouveau composant joue le rôle d'un gardien (circonspect et vaguement rosse) qui gère l'accès au SI depuis le WWW. Il arrive fréquemment que des composants sécuritaires d'infrastructure (WAF, WAM) déjà présents dans les entreprises posent quelques problèmes lors de la mise en oeuvre d’API, en restreignant l’accès à certains verbes HTTP :
OPTIONS /vx/resources
PUT /vx/resources
PATCH /vx/resources
DELETE /vx/resources
Cette fonctionnalité est incompatible avec la mise en oeuvre de REST et doit alors être désactivée. Dans les cas complexes, les firmware doivent être upgradés, ou pire encore, les composants trop anciens remplacés.
Performance
Mécanismes de gestion du cache La gestion des évictions des ressources cachées pour les méthodes safe (GET, OPTIONS) peut être cependant plus complexe, dans la mesure ou les données métiers « volatiles » doivent être invalidées du cache, soit de manière ordonnancée, soit suite à l'utilisation d'un verbe HTTP non-safe (POST, PUT, PATCH, DELETE).
Geodistribution La mise en oeuvre d'une solution d'API Management pose souvent la question du SaaS vs OnPremise. Les implémentations SaaS offrent en générale le meilleur time to market (notamment pour un POC ou un MVP) et permettent - via des mécanismes de caches distribués - une optimisation des temps de réponse. La faible latence de l’API constitue un enjeu fondamental : très souvent, les applications hébergées sur les terminaux numériques des utilisateurs réalisent plusieurs appels REST pour une même « page » ou même action utilisateur. Les solutions SaaS offrent une infrastructure au plus près de l’utilisateur final, qu’il soit à Paris ou à Krung Thep.
Architecture Big Picture : de la SOA en SOAP à la WOA
La SOA (Service Oriented Architecture) est apparue pour faciliter les échanges entre systèmes, « responsabiliser » les référentiels. Mais son implémentation principale (SOAP) a connu plusieurs travers. La WOA (Web Oriented Architecture) est une forme de SOA, basée sur des microservices REST, ainsi que les standards éprouvés du World Wide Web, et vise à corriger les problèmes des implémentations passées. La SOA a probablement échoué à cause des faiblesses de son implémentation (SOAP). D’autres raisons sont probablement à l’origine de la débâcle :
- la SOA n’a pas appuyé sur les enjeux d’ouverture et l’industrialisation de la consommation des services (le focus était point à point avec une volonté de répondre aux enjeux d'interopérabilité technique qui a pris le pas sur les enjeux d'urbanisation),
- la SOA n’a pas offert la capacité à adresser les terminaux émergents en capitalisant sur le WWW,
- et enfin, les éditeurs hégémoniques se sont empressés de vendre des implémentations illusoires « clé en main » de la SOA, via des EAI puis ESB (ritournelle qui est en train d’être rejouée à l’identique pour la WOA et l’API via des solutions d’API Management sur étagère).
Le schéma suivant illustre l’évolution de l’architecture applicative, sans grande révolution.
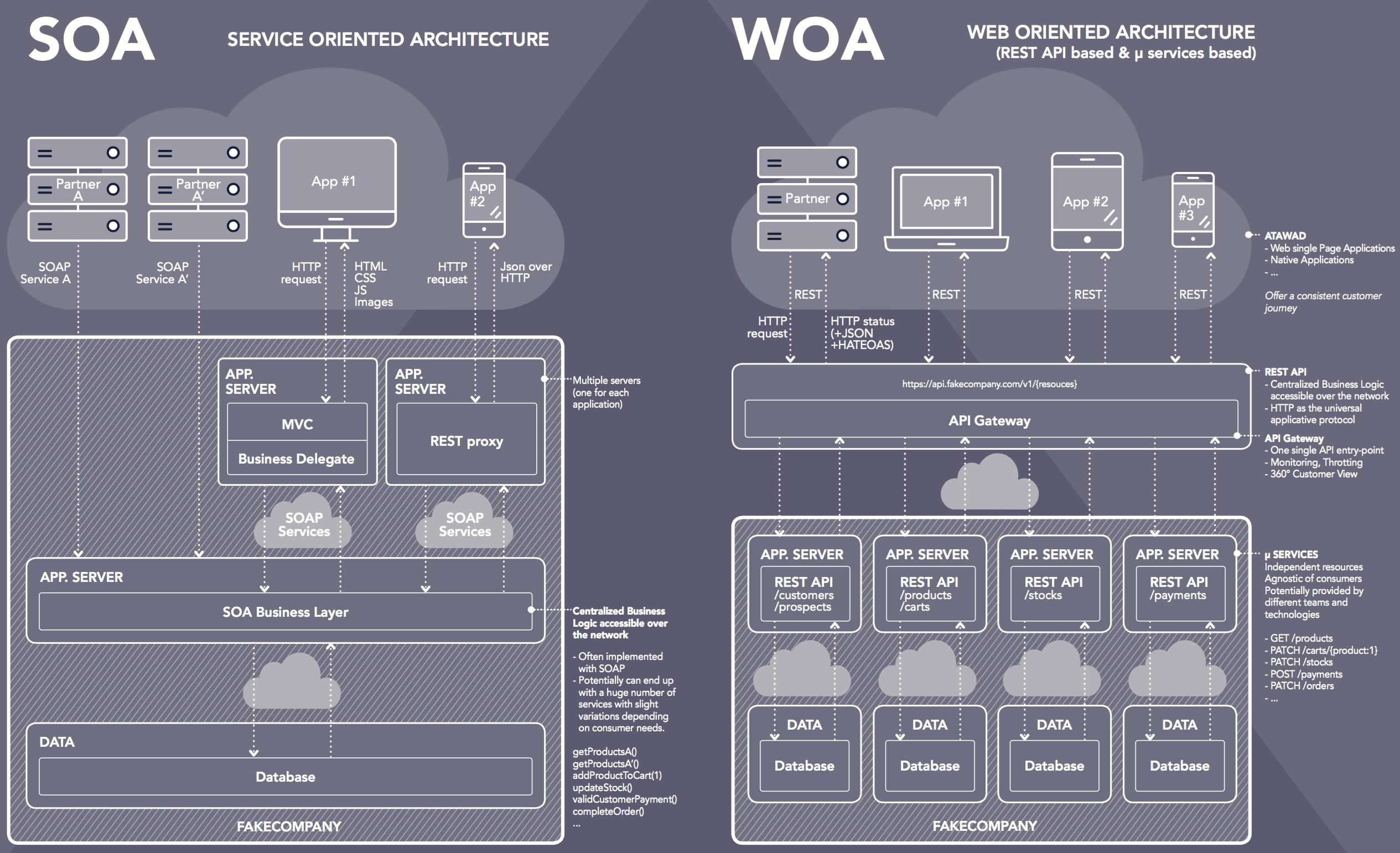
Nous gagnons potentiellement un étage : les terminaux peuvent consommer directement notre API sans avoir à monter un serveur intermédiaire pour sécuriser et « proxifier » les appels. Cependant, en pratique, nous constatons que le pattern BFF (Backend For Front) est souvent utilisé pour bâtir une API dédiée au front afin de répondre à des problématiques organisationnelles (découplage du front et de l’API), de performance (API « dédiée » aux écrans de l'application mobile) ou sécuritaires (la sécurisation de l'API depuis un serveur est beaucoup plus simple). Nous pensons que ce pattern doit être utilisé si une des trois problématiques est rencontrée.
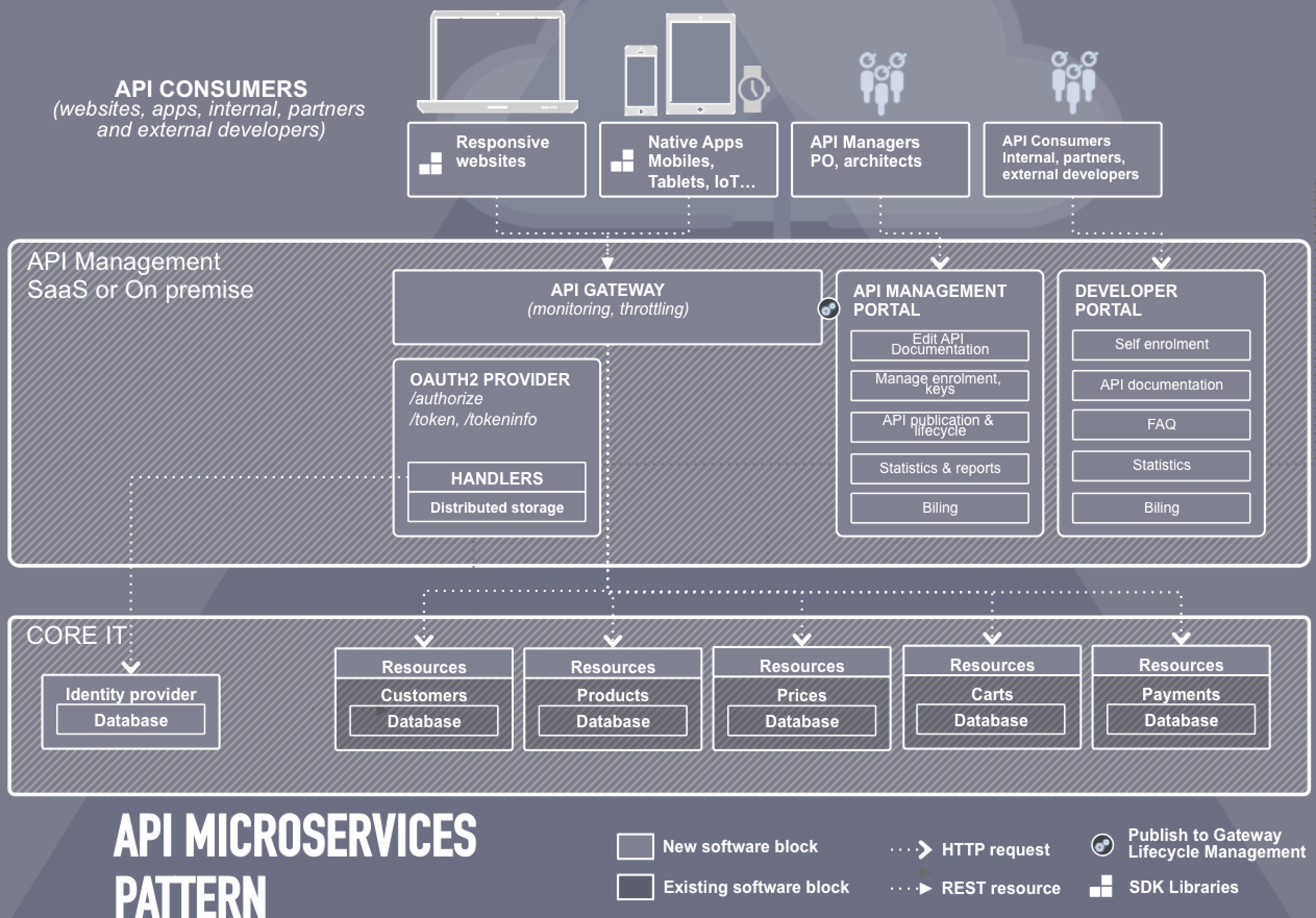
La Gateway est le composant qui sert de point d'entrée unique à l’API et prend en charge les fonctionnalités communes à toutes les API et ressources de l'entreprise : collecte de métriques, gestion centralisée de la sécurité et du monitoring, le portail dévelopeur et la console de management…. La Gateway route vers d'autres composants : les resources providers idéalement découpés en microservices indépendants. Sur le schéma, par exemple :
- une application est responsable de publier les ressources liées au client : /customers
- une application est responsable de publier les ressources liées au catalogue produit : /products et au panier : /carts
- etc.
Voir les sections Microservices et API : les impacts organisationnels.
Le tableau suivant énumère les différences fondamentales entre ces architectures. 
Les patterns d’intégration API
Pour exposer une API, il existe deux principaux patterns d’intégration : Façade et Façade-free (vers une architecture microservices).
Façade API
Le pattern « Façade » est utilisé pour fournir une interface simplifiée (API) en surcouche afin de masquer la complexité d’un système existant. Ce pattern peut être implémenté de deux manières : via la fonctionnalité de transcodage d'une solution d'API Management (Buy) ou via des développements spécifiques (Build).
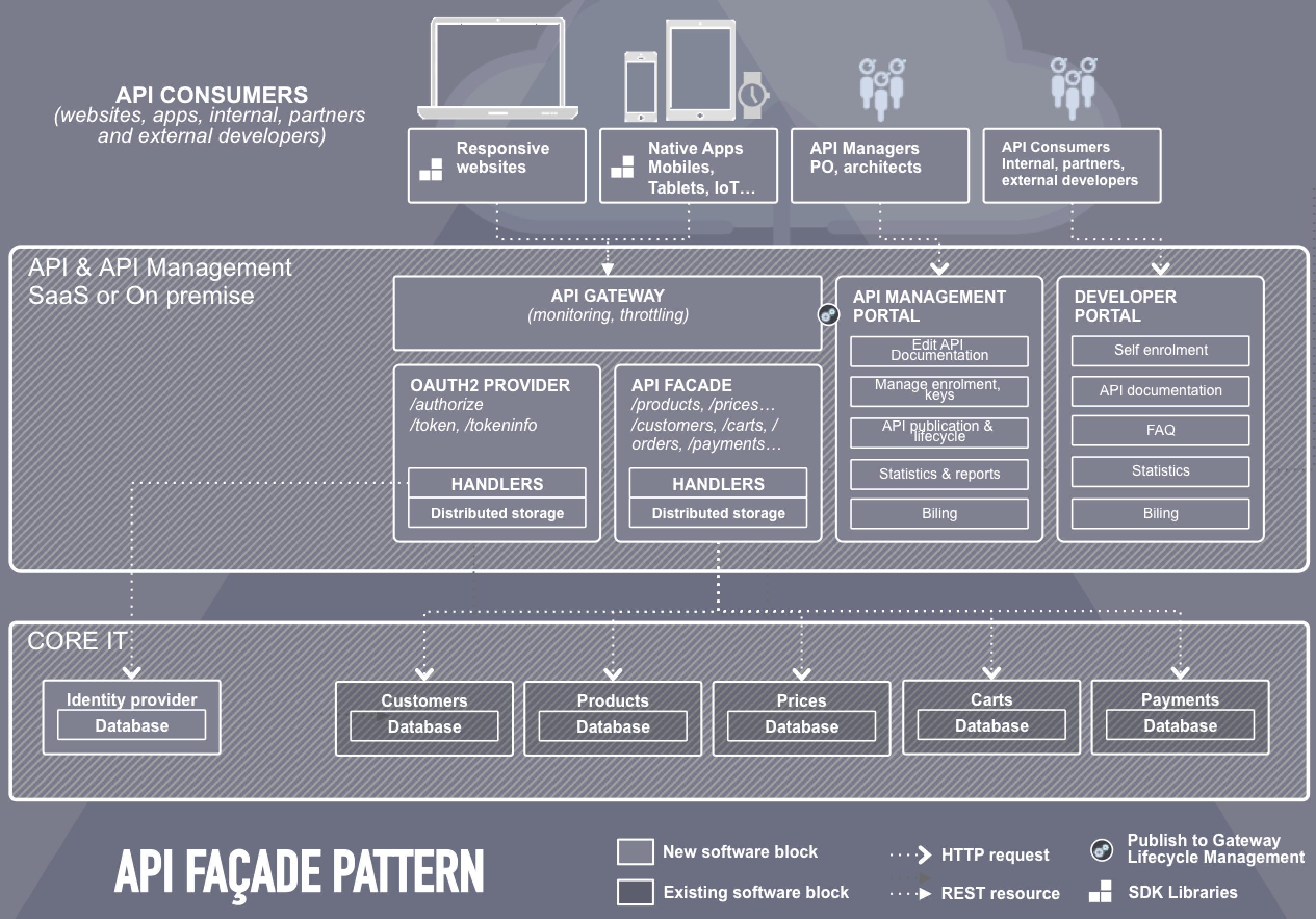
Pattern Façade-free (vers une architecture microservices)
Le pattern "Façade-free" consiste à faire évoluer ses applications référentielles pour publier directement des APIs REST au niveau du CORE IT. En revoyant les applications existantes avec le prisme ressources REST, on emprunte une trajectoire compatible avec l'approche microservices détaillée ici. (Dans le schéma suivant, le pattern est appelé microservices pattern). En y allant progressivement, vous tendrez vers une architecture microservices.
Comparatif
Les illustrations montrent que les « composants cœur » doivent être mis en place dans les deux cas :
- Gateway.
- Portail développeur.
- Portail d’API Management.
- Sécurisation.
Le tableau suivant illustre les avantages et inconvénients des différentes approches :
| PATTERN FAÇADE VIA UN OUTIL | PATTERN FAÇADE EN SPECIFIQUE | PATTERN FAÇADE-FREE |
|---|---|---|
| Utilisation de la fonctionnalité de transcodage d'une solution d'API Management (similaire à un ESB) pour exposer « à la hache » une API REST basée sur les services existants. | Developper une façade en spécifique qui expose une API REST basée sur les services existants. | Ce pattern consiste à exposer progressivement ses référentiels existants pour exposer a API RESTful, directement à partir des systèmes CORE IT |
| --- | --- | --- |
| + Bon time to market (pertinent pour un MVP) | + Bon time to market (pertinent pour un MVP). + Pas de dépendance vis à vis d'un éditeur. + Permet de prendre en compte une partie importante de la complexité de votre logique métier. | + Pas de dépendance vis à vis d'un éditeur. + Permet de prendre en compte toute la complexité de votre logique métier. + Pas d'overhead sur le temps de réponse. |
| --- | --- | --- |
| - Difficile d'obtenir une API résultante de qualité (dépend énormément des services sous-jacents existants) - Dependant de la solution d'API Management et de l'éditeur. - Ne permet pas forcément de prendre en compte la complexité de votre logique métier. - Overhead sur le temps de réponse. - La façade et vos services existants deviennent fortement couplés. | - Overhead sur le temps de réponse. - La façade et vos services existants deviennent fortement couplés. | - Probablement pas time to market car il faut impacter l'existant. |
| --- | --- | --- |
Quel pattern dois-je utiliser ?
Dans la plupart des cas, le pattern « Façade API » peut être considéré comme un anti-pattern qui a largement été invoqué pour implémenter la SOA via des ESB (cf cet article). Nous pensons que ce pattern est très pertinent pour offrir un bon time-to-market, mais qu’il doit être considéré comme une solution « transitoire » et non comme une cible d’architecture.

Les limitations de ce pattern sont :
- L’API résultante est limitée par les services exposés par vos backends sous-jacents : « A great API on bad services is lipstick on a pig ! ». Par exemple, il est quasiment impossible de modifier un mécanisme de pagination existant avec une façade.
- L’équipe API Façade peut constituer un goulot d’étranglement lorsque l’API grossit.
- L’équipe API Façade pourra difficilement maîtriser la complexité de la logique métier de l’ensemble de votre CORE IT.
- La Façade induit un couplage fort avec les applications référentielles : pour la mise en oeuvre d’une évolution substantielle, le backend évolue et la Façade est impactée.
- Avec le temps il est probable que la Façade devienne un monolithe difficile à maintenir (monolithe incluant des règles de gestions, de l'orchestration qui porte sur l'ensemble des backends et in fine un potentiel « plat de spaghettis » au sein d'une même brique).
- Overhead sur les temps de réponse de l’API.
Nous avons déterminé ces limitations après les avoir vécu chez un de nos clients. Ce dernier avait bâtit une infrastructure façade pour répondre aux problématiques d'exposition Web (forte sollicitation et enjeux HA) de son système existant. L'équipe et l'infrastructure mises en oeuvre ont alors révélé leur limites sur quelques années. Notre client a par la suite choisi comme stratégie d'architecture d'adresser ces problématiques au plus profond du SI, au niveau des composants référentiels. La stratégie retenue est de décommissionner progressivement la façade de manière opportuniste, en effectuant un refactoring des systèmes techniques sous-jacent s : c'est le « CORE Renaissance ».
Bien entendu si l'on accepte les limitations du pattern « Façade API », ce dernier peut être tout à fait pertinent. En effet, la mise en oeuvre d'une façade dispose d'un atout considérable : elle centralise les impacts avec les systèmes existants. La mise en oeuvre de l'API sera donc probablement plus rapide, et les coût associés probablement maitrisés. En outre, nombre d'architectes pérorent que la mise en oeuvre d'une façade API est un moyen de découpler le SI avec le monde « extérieur » du WWW.
Notons que les deux patterns peuvent être conjugués : approche facade-free lorsque c'est possible, et mise en oeuvre d'une façade API lorsque l'on a pas la main sur les resources-providers (cas d'un progiciel qui exposerait des services legacy par exemple).
Sécurisation
Rendre vos API disponibles du l'internet ne signifie pas qu'elles sont en accès libre, de manière non sécurisée. Il existe des protocoles Web standardisés pour gérer l’authentification et l’habilitation des applications appelantes et des utilisateurs connectées à ces applications. La pierre angulaire étant le protocole OAuth2, qui est un framework d’autorisation et qui peut être étendu pour prendre en charge l'authentification via le protocole OpenID Connect. Ces protocoles simples sont bien éloignés des solutions complexes généralement utilisées par les entreprises (WS-Security, SAML2…).

L’objectif étant de permettre aux développeurs de consommer facilement l’API, ces protocoles n’incluent pas de mécanismes de signature ou de chiffrement applicatif* des messages (ils reposent uniquement sur la couche de transport TLS qui garantie l’intégrité et la confidentialité des échanges) et permettent une consommation de l’API par tout type de device : non seulement des serveurs, mais aussi des navigateurs, des applications natives…
*Notons que JWT est fréquemment utilisé conjointement à une implémentation OAuth2. Il s'agit d'une RFC séparée ajoutant une couche de chiffrement qui complexifie les appels OAuth2 mais apporte une optimisation fondamentale permettant de récupérer les informations liées à l'utilisateur connecté et aux habilitations, sans effectuer de nombreux apples serveurs. Son utilisation est normalisée via la spécification OpenID Connect.
Enfin, le mécanisme de sécurité à implémenter dépend du type de ressources. Il existe en effet deux types de ressources :
- Les ressources publiques : dont les données ne dépendent pas d’un utilisateur final.
- L’application appelante est habilitée via une API_KEY.
- Les ressources privées : dont les données dépendent d’un utilisateur final.
- L’application appelante est habilitée via un access_token OAuth2 qui permet d’identifier l’utilisateur connecté.
API : les impacts organisationnels
La mise en œuvre d’une API impacte les équipes et l’organisation. La loi de Conway indique : « Any organization that designs a system [...] will inevitably produce a design whose structure is a copy of the organization's communication structure »
Nous en déduisons le corollaire suivant : il faut organiser ses équipes à l’image du système que nous souhaitons bâtir. L’API devrait être vu comme un produit à part entière et donc construite par une équipe dédiée.
La mise en œuvre d’une API nécessite la création d’une équipe API qui se charge - a minima - de mettre en place certaines « fonctionnalités cœur » qui doivent être centralisées :
- Le portail développeur.
- Le portail d’API Management.
- La gateway et la sécurisation de l'API via OAuth2 ou OpenID.
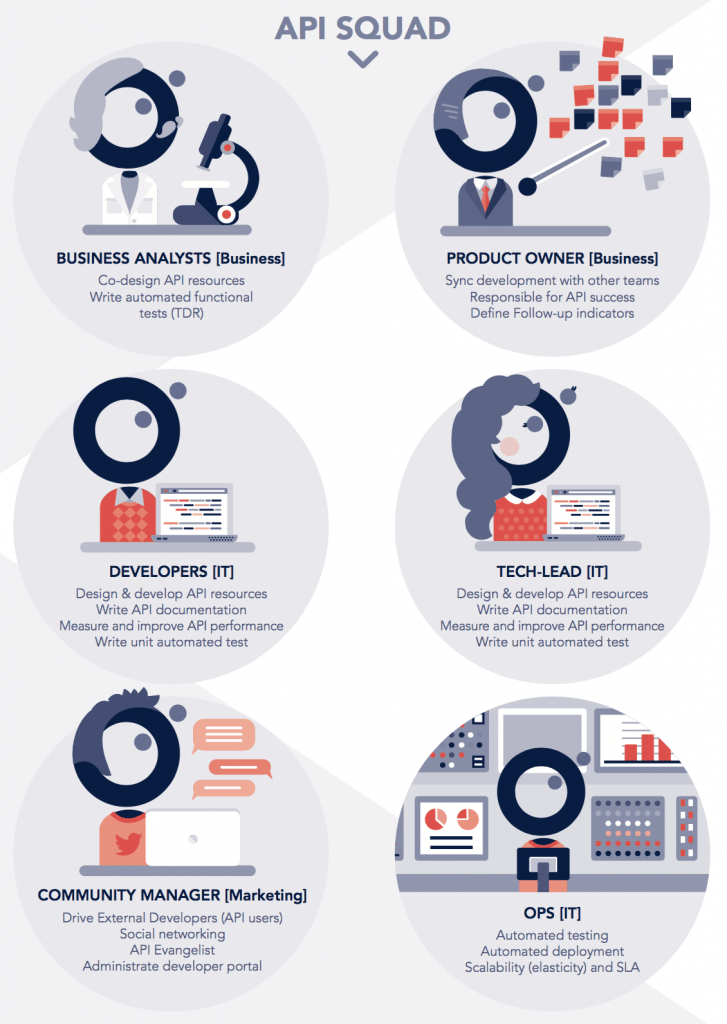
Nous organisons souvent cette équipe en squad dans le cadre d'une réalisation agile, c'est à dire une équipe responsable, autonome, pluridisciplinaire avec un focus produit. Cette organisation nous a toujours permis d'obtenir le meilleur time to market et est adaptée à la réalisation de produits stratégiques comme l'API. Les rôles sont représentés sur l'illustration suivante :
Notons que cette équipe API peut également être organisée de manière plus « traditionnelle » : MOA/MOE, cycle en V, etc.
Cette squad API doit inclure tous les membres responsables du produit API :
- un Product Owner (si possible Marketing/Métier),
- un Tech-Lead, des Développeurs et des OPS,
- et lorsque cela commence à faire sens, un Community Manager ou API Evangelist.
La squad API peut éventuellement prendre en charge le développement des premières ressources sur le pattern API Façade, afin de valider le MVP API en offrant un bon Time To Market (en évitant de devoir coordonner plusieurs équipes référentielles CORE-IT).
Cette première phase correspond au « stage one » de l'illustration suivante. 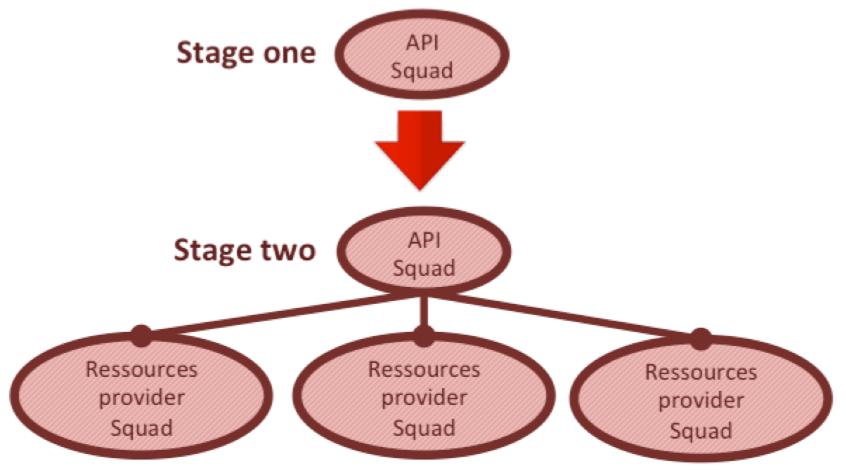
Si le MVP API est validé, l’entreprise peut accélérer pour entrer dans une seconde phase qui consiste à « démultiplier » l’API au sein de la DSI (« stage two » de l'illustration précédente). De nouvelles squads resources provider sont progressivement créées et prennent en charge une application référentielles, pour produire les ressources dont elles sont responsables. Ces équipes sont alors des feature teams. La façade API est progressivement décommissionnée. Le basculement sur une architecture WOA (REST microservices) est amorcé.
A noter qu’avec la WOA et REST, le Web « infiltre » la DSI en profondeur : les compétences doivent être adaptées pour accompagner votre stratégie API.
API Management
Le besoin d’industrialisation
Le besoin d’industrialisation induit que vos APIs soient managées. Chaque application appelante possède un identifiant (la clé d’application ou l'identifiant client). Cet identifiant permet de mesurer la consommation des ressources pour chaque application, ainsi que de limiter le nombre d’appels (par heure, par jour, …). Il est également possible de facturer les appels au delà d’un certain quota : c’est par exemple le cas de l’API Google Maps qui devient payante au delà de 25 000 appels/jour. Il est alors possible d'apprécier en temps réel qui consomme vos ressources et et de révoquer si besoin la clé d’un consommateur.
Le besoin d’industrialisation induit que vos APIs soient accessibles en self-service, c’est à dire que la souscription peut se faire depuis le site Web de l’API (le Portail développeur) sans aucune relation commerciale avec le fournisseur.
Dans le cadre d’une démarche Open API, l’enjeu fondamental est d’industrialiser le processus de consommation des ressources jusqu’à son paroxysme. La qualité de ce processus se mesure simplement, avec le TTFAC (Time To First API Call), c’est à dire le temps nécessaire à un développeur tiers pour réaliser un premier appel de ressource, suite à son enregistrement sur le Portail développeur.
Dans le monde de l’API, la DX (Developer eXperience) est un point à ne pas négliger. Elle dépend des qualités intrinsèques du Portail développeur et de l’API :
- facilité du processus d'enrôlement,
- qualité de la documentation de l’API, et des interfaces Try-It qui permettent de réaliser des appels sur une API « bac à sable »,
- qualité de l’API en terme de design (simplicité, affordance,…),
- qualité du support (F.A.Q, Forum d'entraide. etc.).
C’est en récoltant des feedback utilisateurs que l’on peut améliorer continuellement son API.
Pour aider à l’industrialisation de la consommation des ressources de l’entreprise et accélérer la mise en oeuvre d’API, de nouvelles solutions ont émergé à foison : les solutions d’API Management. Ce marché en plein essor et encore en voie de consolidation, vient récemment de voir apparaître des acteurs comme RedHat, Google, etc.
Cartographie fonctionnelle
Ces progiciels d'API Management offrent souvent les fonctionnalités énumérées sur l'illustration suivante :
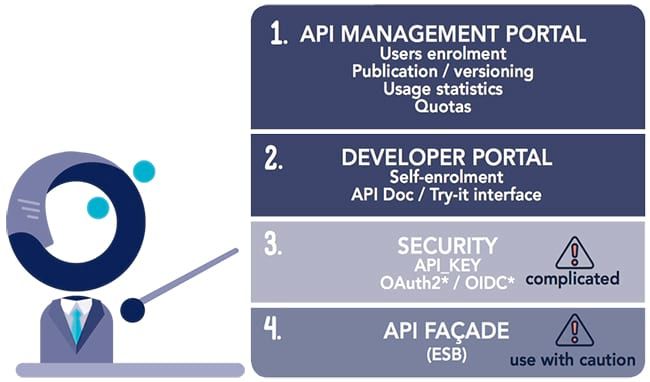
Globalement, nous avons pu constater que les solutions d’API Management couvraient correctement les deux premières fonctionnalités :
- Portail d’API Management :
- enrôlement des utilisateurs ou validation de leur enrôlement,
- publication d'APIs et gestion de leur versioning,
- la supervision des statistiques d'usage de l'API par consommateur et par application,
- du reporting techniques (user agent, IP, temps de réponse, etc.) ou métier (produit le plus sollicité, etc.) sur la consommation de l'API et des ressources,
- la possibilité de positionner des quotas d'utilisation de l'API (throttling) par consommateur et par application
- de monétiser la consommation de l'API, etc.
- Portail développeur :
- à minima documentation de l'API (swagger, etc.),
- avec des exemples cURL dans la documentation de l’API, qui peuvent être utilisés en copier-coller, pour lever toute ambiguïté concernant les modalités d’appel,
- une interface try-it qui implique la mise en oeuvre d'un d'un environnement sandbox (bouchonné ou bien un véritable environnement avec des données anonymisées),
- un mécanisme d'auto-enrôlement ou d'enrôlement soumis à habilitation, pour délivrer une clé d'API (API_KEY) ou un couple (client_id/secret) pour OAuth2 ou OIDC,
- la possibilité de suivre sa consommation par application,
- les informations liées à la monétisation de l'API,
- idéalement, le portail est hébergé sur l'internet à l'URI : https://developers.{fakecompany}.com
La sécurisation des ressources via les protocoles OAuth2 ou OpenID Connect est souvent pas ou mal implémentée.
- En pratique, les protocoles OAuth2 et OIDC sont sensiblement couplés avec des composants très spécifiques à l'entreprise (référentiels utilisateurs, mire de login SSO, etc.). La mise en oeuvre consiste souvent à développer en spécifique ces protocoles dans le progiciel, en héritant de son « environnement » (langage, runtime, infrastructure, etc. ) et sans bénéficier des usines logicielles en place (tests unitaires automatisés).
- Nous vous préconisons de réaliser à minima des POCs pour valider l’intégralité des flows OAuth2 nécessaires à votre contexte (Implicit, Code grant, Resource owner et Client credential) dans votre environnement.
Nous pensons que la fonctionnalité de transcodage (façade API) - qui est hélas le cheval de bataille de certains éditeurs - doit être utilisée en connaissance de cause et avec précautions ! En effet, cette brique peut s'avérer être un véritable cheval de Troie : nous avons constaté chez nos clients qu'une fois que les services étaient construits via ce progiciel transverse, et consommés par des applications, il n'était alors pas aisé de s'en séparer.

Nous pensons qu'il est fondamental de dissocier l'API (asset stratégique de l'entreprise) de son management (fonctionnalité annexe moins stratégique qui devrait être le coeur de métier des solutions d'API Management). Voir la section API : Build vs Buy.
Utilisateurs et rôles
Le schéma suivant illustre les utilisateurs et les rôles autour de l'API et de son management : 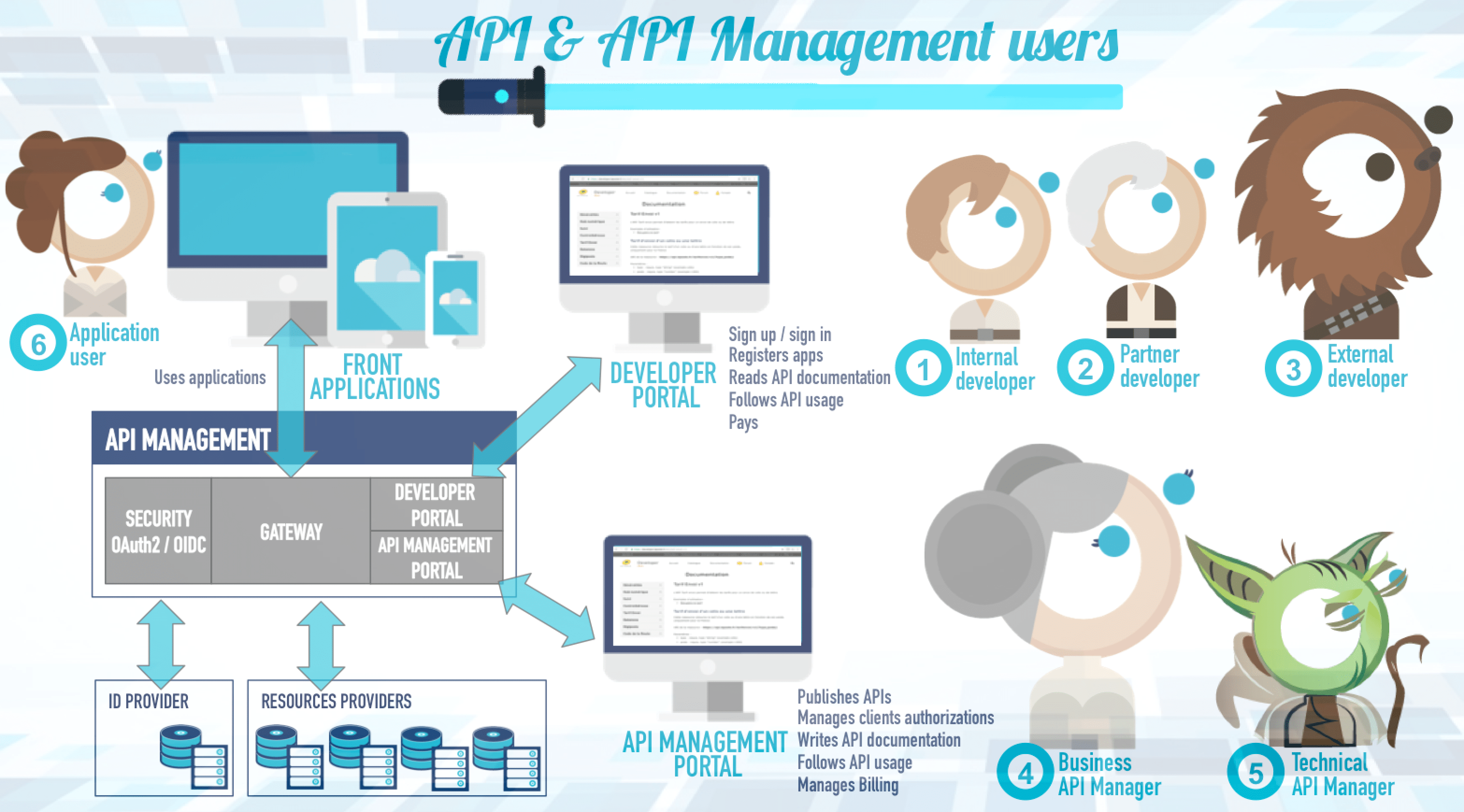
Panorama des solutions
DISCLAIMER : Nous signons des partenariats éditeurs lorsque nous sommes convaincus de leur pertinence. Afin de préserver notre indépendance, indispensable à notre posture de conseil, nous n'effectuons aucun partenariat commercial. Quelques solutions d'API Management sont présentées sur le schéma suivant. On distingue deux galaxies :
- à gauche des solutions plutôt intégrées et point & click,
- à droite les solutions plutôt open-source et developer friendly.
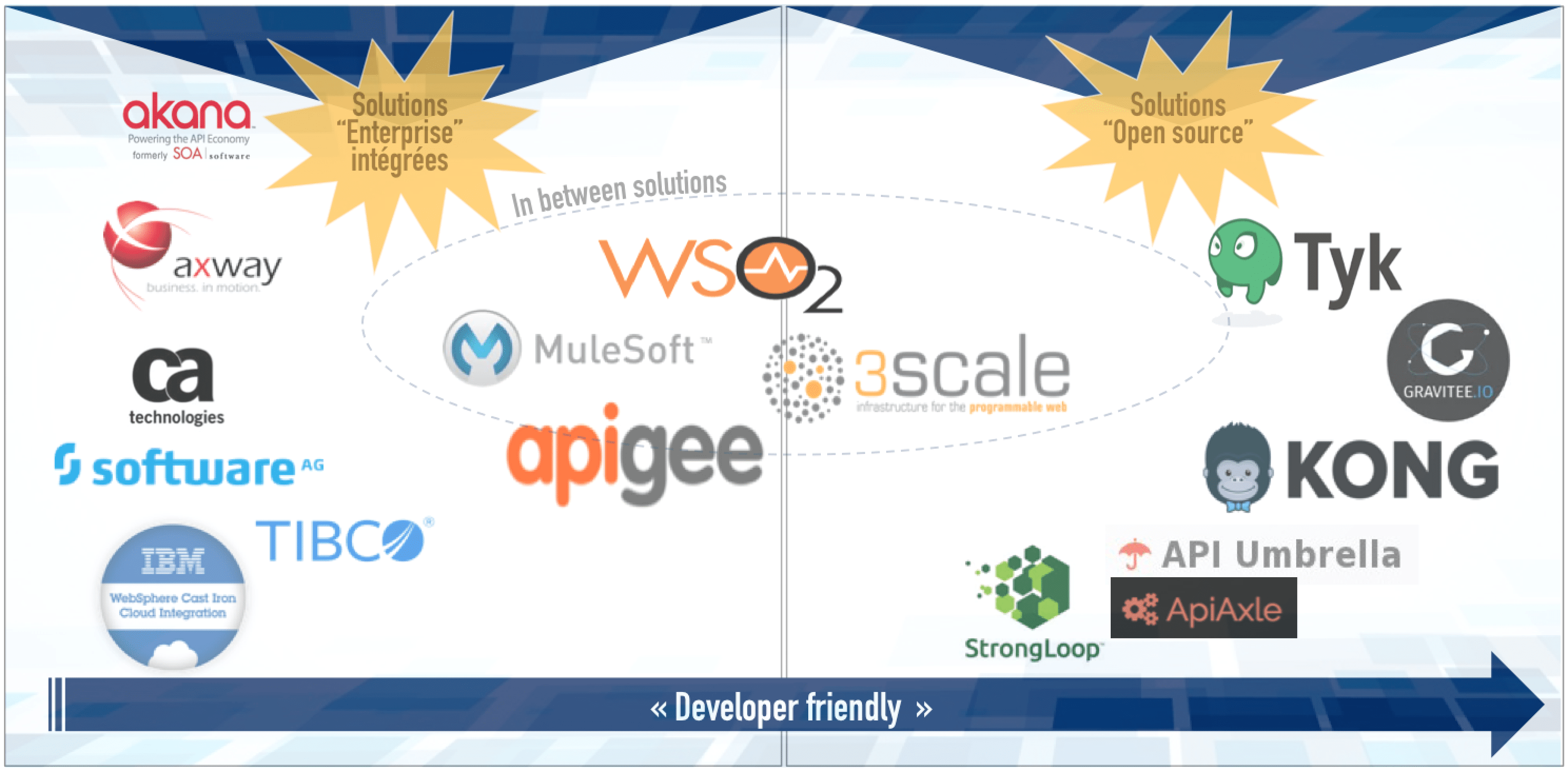
Le choix d'une solution dépasse le cadre de cet article, si l'achat d'une solution est privilégié (Voir la section API : Build vs Buy). Néanmoins, voici quelques critères à prendre en considération :
- les références de portail dévelopeur (et d'APIs) accessibles sur l'internet,
- les fonctionnalités souhaitées par rapport aux fonctionnalités offertes par la solutions. Notamment, ai-je besoin de fonctionnalités de transcodage de type ESB ?,
- communauté (nombre de réponses sur Google en cas de problème) et le support de l'éditeur
- le mode de déploiement (SaaS, On-Premise, IaaS)
- les capacités de customisation,
- le mode d'intégration (Gateway vs Plugins),
- le coût (parfois astronomique) de la licence,
- la capacité des équipes de production à opérer les technologies tirées par la solution,
- la capacité du produit à être piloté par une API (notamment pour pourvoir être intégré dans une usine logicielle).
Nous préconisons vigoureusement de réaliser un POC sur quelques produits et de prendre en compte le retour des équipes ayant participé à la mise en oeuvre. 
API : Build vs Buy
La réflexion Build vs Buy appliquée à l’API est illustrée sur la pyramide suivante :
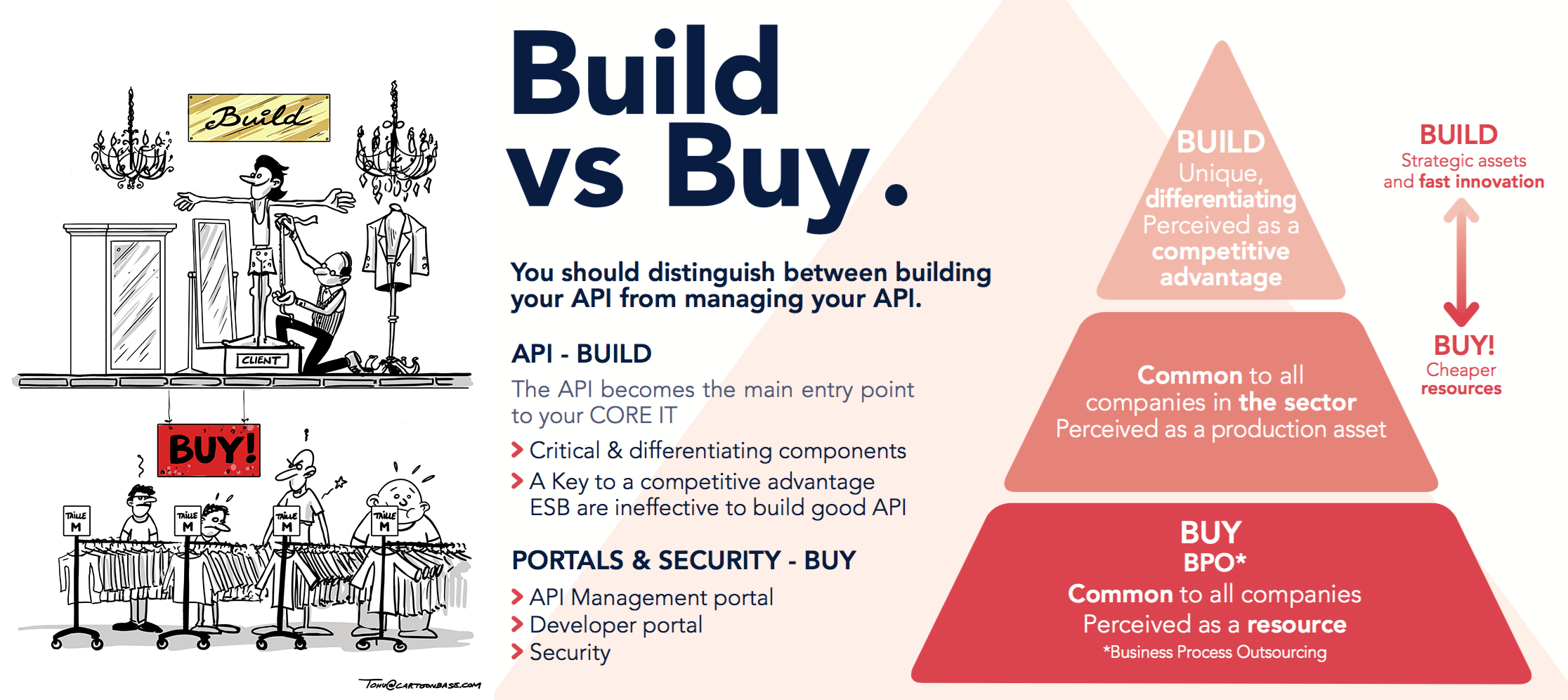
Notre conviction est qu’il est souvent préférable de développer l’API en spécifique (qu’il s'agisse d’une Façade non) . L’API qui devient le point d’accès unique au SI, est un composant stratégique différenciant. Le portail développeur, le portail d’API Management et la sécurité sont moins différenciants et peuvent être pris en charge par des solutions sur étagère.
Bien entendu, cela doit être pondéré en fonction de la stratégie de l'entreprise sur son orientation Build vs Buy : utiliser un outil pour construire, à la hussarde, une API via un outil peut s'avérer pertinent dans certains contextes. Plus de détails sur ce sujet peuvent être trouvés dans notre articles Les Patterns des Géants du Web - Build vs Buy.
Pièges à éviter, traquenards et embardées loupées
L’API Management n’est pas un outil miracle
La stratégie API d’une entreprise se résume hélas parfois à l’achat d’une solution d’API Management. Le risque : l’API ne sort pas après plusieurs mois (années?), puisque les véritables impacts et enjeux, jusqu’alors ignorés, n’ont pas été adressés.
En effet, la mise en oeuvre d’une API draine des problématiques complexes qui portent sur trois niveaux :
- fonctionnel (granularité, design des ressource RESTful, les compensations fonctionnelles, etc.).
- technique et Architecture (stateless, asynchronisme, µservices, etc.),
- et organisationnel (urbanisation, feature team vs component team, adaptation des compétences, etc.).
API Façade via un ESB
La fonctionnalité « Facade point & click » offerte par bon nombre de solutions d'API Management est en tous points identique à un ESB :
- Le pattern « API Facade » connait certaines limitations
- Une « API Facade » réalisée via un progiciel de type ESB (qui in fine permet d’effectuer des transformations limités, par exemple des renommages, etc.) ressemblera fortement aux services exposés par les back-end sous-jacents et laissera transpirer leurs défauts et contraintes
- Risque d’une forte adhérence avec un progiciel sur un sujet stratégique (voir section suivante API : Build vs Buy)

Et chez moi ?
Et dans ma DSI, dois-je lancer une stratégie API ?
Nous pensons que l’API est le vecteur qui offre la capacité à industrialiser sa présence dans le digital. Les promesses sont :
- Une réponse pour adresser les terminaux numériques émergents :
- l’expérience client cross-device,
- l’omnicanalité,
- la vision client à 360 degrés,
- l’industrialisation de la consommation des ressources de l’entreprise.
- L’ouverture des données :
- l'opportunité de faire émerger de nouveaux business models,
- la possibilité « d’outsourcer » l’innovation.
La WOA et l'API doivent être envisagés si vous souhaitez :
- permettre à quiconque (partenaire, développeur externe, etc.) de pouvoir consommer rapidement les ressources de votre SI :
- par exemple une banque consomme les ressources d’une société d’assurance,
- par exemple, un prestataire qui réalise votre application Apple Watch consomme les ressources de votre SI.
- adresser l'ensemble des terminaux digitaux émergents et offrir une expérience utilisateur cohérente à vos utilisateurs,
- avoir une vision sur la consommation de vos ressources et pouvoir les manager.
En corollaire, les questions à se poser :
- Est-ce que j’offre un bon TTFAC (5 minutes) pour qu’un partenaire puisse s’interfacer à mon SI ?
- Suis-je capable de bâtir des applications sur les terminaux émergents avec un bon time to market ?
- Ai-je une vision 360° technique et fonctionnelle sur les applications internes et externes qui consomment les ressources de mon SI?
- Quel gisement de gains pourrait apporter l’ouverture de mes données ?
Exceptions !
Dans certains cas, l'utilisation d'une API peut ne pas être adaptée :
- L’informatique temps-réel (type avion, automobile, machine outil) : dans ce cas, la composition de services peut poser des problèmes de performance.
- Tout ce qui nécessite un workflow complexe.
- Vous ne souhaitez pas adresser les terminaux émergents et vous échangez avec vos partenaires uniquement sur la base de protocoles propriétaires ou SOAP, sans qu'aucune douleur ne soit identifiée.
Glossaire
Applications référentielles : dans cet article nous utilisons ce terme pour désigner les applications (règles de gestion et base de données) qui sont responsables d'un périmètre fonctionnel (comme les clients, ou les produits, ou les contrats, etc.). Dans ce contexte, les données ne sont pas uniquement des données de « référence » comme un catalogue produit par exemple.
WOA : Dans cet article, nous utilisons cet acronyme pour : WOA = SOA + WWW + REST + Microservices. Voir aussi la définition section WOA dans la définition SOA Wikipedia. Voir la définition Gartner.
Resource provider : Système technique qui expose les ressources d'une API sur un ensemble fonctionnel cohérent, dans le cadre d'une architecture microservices.
