Sérialisation : Thrift et Protocol Buffers, principes et aperçu
La sérialisation est une des bases de la transmission de données entre systèmes. Certains langages proposent d'ailleurs une méthode de sérialisation en standard, qui leur est souvent propre.
L'interopérabilité entre systèmes hétérogènes nécessite que le format de sérialisation soit compréhensible par différents langages et plates-formes. De nombreux standards utilisent le mécanisme d'IDL (Interface Description Language) pour répondre à ce besoin : ASN.1, CORBA ou encore SOAP.
Depuis quelques années, de nouveaux frameworks basés sur un IDL ont vu le jour pour l'interopérabilité de technologies hétérogènes dans une optique d'économie de bande passante. Parmi eux, on trouve Thrift et Protocol Buffers. Ce premier article présente les deux frameworks sous l'angle de la sérialisation des messages et détaille leur utilisation en Java.
Historique et objectifs
Thrift et Protocol Buffers (abrégé en protobuf) ont en commun d'avoir été développés par des acteurs majeurs du Web. Thrift a été initialement développé par Facebook, et est désormais en incubation chez Apache suite à son passage en open source. Protocol Buffers a commencé comme framework interne chez Google, où son utilisation est majoritaire. L'ouverture de son code source s'est faite après une remise à plat nommée Proto2.
Afin de s'affranchir des barrières de langages, ces deux frameworks reposent sur des mécanismes classiques :
- un IDL pour décrire les structures de données,
- une génération statique du code de sérialisation dans divers langages de programmation,
- un protocole de sérialisation, c'est-à-dire une méthode de représentation des messages.
On peut par exemple générer du code permettant l'échange de messages entre Java et C++ :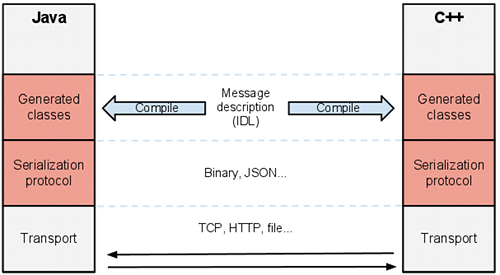
Cet article se focalise en priorité sur le protocole de sérialisation, qu'il convient de distinguer du protocole de transport. Ce dernier correspond au support véhiculant le message sérialisé suivant le protocole de sérialisation.
Pourquoi de nouveaux protocoles de sérialisation ?
Protobuf se limite au protocole de sérialisation, et est donc similaire à la CDR de CORBA ou à ASN.1 associé à un encodeur : il s'agit uniquement de représenter un message sous forme sérialisée. Thrift y ajoute des implémentations de RPC en mode client/serveur sur plusieurs protocoles de transport (HTTP, Socket, File...). Leurs fonctionnalités sont limitées par rapport à ce que propose CORBA par exemple : Thrift ne propose pas de gestion des transactions, de reprise sur erreur ou de fonctionnalités d'annuaire.
Les principes de Thrift et Protocol Buffers ne sont donc pas nouveaux. Ces deux frameworks ont néanmoins deux avantages majeurs pour les contextes de haute disponibilité et forte scalabilité, tels ceux de Google ou Facebook :
- Compatibilité ascendante/descendante : permet de faire évoluer l'interface sans nécessiter de redéploiement immédiat de toutes les applications concernées
- Taille de message et temps de sérialisation/désérialisation optimisés : permettent de minimiser les besoins de bande passante et de temps de traitement. Le champ d'utilisation peut de plus être étendu à la persistance de données.
L'argument de compacité du message est uniquement valable si on emploie le protocole de sérialisation binaire de Protobuf et le protocole compact de Thrift, car ils permettent une optimisation de la taille du message à l'octet près. Par exemple, les deux sérialisent une chaîne de caractères en la faisant précéder par sa longueur, à l'instar de CDR. Mais ils codent cette longueur avec un varint, qui est plus compact que l'entier sur 32 bits employé par CDR.
IDL et interfaces
Thrift et Protobuf se ressemblent énormément en pratique. L'IDL du premier s'appelle Thrift IDL, celui du second se nomme simplement protocol buffer language. Les deux frameworks supportent la plupart des types de données courants, le détail est disponible ici pour Thrift et là pour Protobuf.
L'exemple considéré est l'objet Node dont une version en Java est la suivante :
package com.octo.example.serialization.model;
public class Node implements Serializable {
private Integer mNumber;
private boolean mEven;
private Double mRate;
private RoomType mType;
private String mDescription;
[...]
}
Il contient quelques membres de types différents, dont une énumération ; les accesseurs ont été omis par concision.
Voici le descripteur équivalent en Thrift IDL : tree.thrift
namespace java com.octo.example.serialization.model.thrift
enum RoomType {
SINGLE =0,
DOUBLE =1,
SUITE =2
}
struct Node {
1: optional i32 number,
2: optional bool even,
3: optional double rate,
4: optional RoomType type = RoomType.SINGLE,
5: optional string description
}
La première ligne permet de spécifier le package Java auquel appartiendra le code généré par le compilateur Thrift. L'énumération RoomType associe une constante numérique à chaque valeur possible. Puis notre objet Node lui-même est défini. En Thrift IDL, chaque champ est défini par
- un identifiant unique
- suivi de l'indication s'il est optionnel ou non (optional/mandatory),
- puis son type,
- son nom
- et une valeur par défaut précédée du signe = si nécessaire.
Le message est donc sérialisé sous forme clef-valeur, avec l'identifiant unique comme clef. La valeur contient le type puis la valeur elle-même. Voici à fins d'illustration ce que donne la struct Node sérialisée avec le protocole de sérialisation TJSONProtocol de Thrift :
{
"1":{
"i32":0
},
"2":{
"tf":1
},
"3":{
"dbl":0.0
},
"4":{
"i32":0
},
"5":{
"str":"Lorem ipsum dolor sit amet, cons"
}
}
Voici le pendant en Protocol Buffers language : tree.proto
package serialization;
option java_package = "com.octo.example.serialization.model";
option java_outer_classname = "TreeProto";
enum RoomType {
SINGLE =0;
DOUBLE =1;
SUITE =2;
}
message Node {
optional int32 number =1;
optional bool even =2;
optional double rate =3;
optional RoomType type =4 [default = SINGLE];
optional string description = 5;
}
La première ligne correspond au package protobuf, ce qui permet d'éviter les conflits lors d'imports de fichiers .proto externes par exemple. Les deux lignes suivantes sont des options propres à la génération de code Java ; il s'agit du nom de package et du nom de la classe générée par protoc. La déclaration d'un champ se fait de manière similaire à celle de Thrift :
- l'indication si le champs est optionnel (optional) ou non (required),
- puis son type,
- son nom,
- son identifiant unique précédé du signe =
- suivi d'une valeur par défaut si nécessaire.
La sérialisation suit le même principe que celle de Thrift : le message est sérialisé en clef-valeur avec l'identifiant unique comme clef. Le détail de l'encodage binaire est fourni ici.
Versioning et évolution de l'interface
La compatibilité ascendante/descendante des messages nécessite de respecter certaines règles afin d'être garantie. Ces dernières sont similaires pour les deux frameworks. La pierre angulaire de la compatibilité est l'identifiant unique associé aux champs. La principale règle de désérialisation est que tout champ d'identifiant inconnu est ignoré. Il reste néanmoins conservé dans le message car il peut être utile à d'autres versions de l'interface.
Les règles à respecter lors de l'évolution des interface sont les suivantes
- les identifiants de champs doivent être invariants
- tout champ ajouté dans une nouvelle version doit être optionnel, sous peine de ne plus pouvoir lire les messages issus d'anciennes versions
- les valeurs par défaut ne doivent en général pas être modifiées. En effet, elles ne sont pas transmises dans le message sérialisé, mais assignées par le code de désérialisation
- tout champ obligatoire doit être présent dans toutes les versions de l'interface, passées ou futures.
A ces règles protobuf ajoute
- des compatiblités entre types, par exemple entre uint32 et bool,
- un mécanisme d'extension afin de réserver des plages d'identifiants pour une utilisation future, pour de l'héritage par exemple.
Génération du code
L'étape suivante consiste à générer le code correspondant aux objets et interfaces définies ci-dessus. Le compilateur Thrift est utilisé de la manière suivante :
thrift -v --gen java -o . tree.thrift
Le code généré est placé dans un sous-répertoire gen-java, avec autant de fichiers-classes que de structs et énumérations :
gen-java └── com └── octo └── example └── serialization └── model └── thrift ├── Node.java └── RoomType.java
Pour Protobuf, le principe reste le même, même si la ligne de commande change un peu :
protoc -I=project/root/ --java-out=. tree.proto
Dans ce cas un unique fichier est généré, contenant l'ensemble des messages sous forme de classes internes
java └── com └── octo └── example └── serialization └── model └── TreeProto.java
Cas particulier : déclaration avancée et récursion
Le but initial de l'exemple était de sérialiser un arbre constitué de nœuds. Or **Thrift ne supporte pas la white paper de Thrift :
Due to inherent complexities and potential for circular dependencies, we explicitly disallow forward declaration. Two Thrift structs cannot each contain an instance of the other.
Par exemple, le compilateur Thrift bloque sur deux erreurs lors du parsing de la struct suivante :
namespace java com.octo.example.serialization.model.thrift
struct InvalidNode {
1: optional i32 number,
2: optional bool even,
3: optional double rate,
4: optional RoomType type = RoomType.SINGLE,
5: optional string description,
6: list<InvalidNode> children
}
enum RoomType {
SINGLE =0,
DOUBLE =1,
SUITE =2
}
La première est à la ligne 6 : Type "RoomType" has not been defined, et la seconde à la ligne 8 : Type "Node" has not been defined.
Protobuf n'a pas cette limitation et compile donc sans erreur un .proto équivalent. La classe chargée de la sérialisation, CodedInputStream propose une sécurité sur le niveau de récursion. La limite par défaut est de 64, et peut être modifiée via la méthode setRecursionLimit.
Conversion modèle applicatif - objets sérialisables
Si l'applicatif utilise déjà un modèle d'objets existants, des méthodes de conversion entre ce modèle et les objets sérialisables doivent être développées. Ni Thrift ni protobuf ne proposent de moyen d'automatiser ou de générer ce code de conversion. Afin d'éviter ce surcoût, il est préférable de manipuler directement les objets sérialisables générés à l'étape précédente quand cela est possible.
Dans l'exemple, l'objet de départ Node est un simple POJO, la conversion a donc été codée manuellement dans des classes dédiées à la sérialisation. Les objets générés par Thrift exposent des accesseurs pour chacun des champs :
package com.octo.example.serialization.serializers.tree;
public class ThriftTreeSerializer {
[...]
public com.octo.example.serialization.model.thrift.Node convertToSerializable(Node pNode) {
com.octo.example.serialization.model.thrift.Node vNode = new com.octo.example.serialization.model.thrift.Node();
vNode.setNumber(pNode.getNumber());
vNode.setRate(pNode.getRate());
vNode.setType(RoomType.valueOf(pNode.getType().toString()));
vNode.setDescription(pNode.getDescription());
vNode.setEven(pNode.isEven());
for (Node vChild : pNode.getChildren()) {
vNode.addToChildren(convertToNode1(vChild));
}
return vNode;
}
}
Protobuf utilise des messages immuables et le pattern builder :
package com.octo.example.serialization.serializers.tree;
public class ProtoBufTreeSerializer {
[...]
public com.octo.example.serialization.model.LimitedTreeProto.Node convertToSerializable(Node pNode) {
com.octo.example.serialization.model.LimitedTreeProto.Node.Builder vBuilder = com.octo.example.serialization.model.LimitedTreeProto.Node.newBuilder()
.setNumber(pNode.getNumber())
.setRate(pNode.getRate())
.setType(LimitedTreeProto.RoomType.valueOf(pNode.getType().toString()))
.setDescription(pNode.getDescription())
.setEven(pNode.isEven());
for (Node vNode : pNode.getChildren()) {
vBuilder.addChildren(convertToNode1(vNode));
}
return vBuilder.build();
}
}
Une autre méthode consiste à faire implémenter l'interface Externalizable aux objets du modèle applicatif. Cela permet d'utiliser l'un des deux frameworks tout en maintenant la compatibilité avec les API de sérialisation Java standards. Cependant, l'utilisation du protocole de sérialisation de Java augmente la taille du message, notamment à cause la présence des noms de classes complets. Sur un court message, le surcoût est rédhibitoire. À titre d'exemple, le même Node pèse 49 octets s'il est sérialisé par protobuf directement, et 118 octets si on utilise protobuf via Externalizable.writeExternal.
Sérialisation en pratique
Thrift propose plusieurs protocoles de sérialisation à choisir parmi les implémentations de TProtocol fournies, dont deux binaires :
TBinaryProtocol: code chaque champ est sous la forme longeur puis valeur binaire,TCompactProtocol: produit un message plus compact grâce à des optimisations, dont l'utilisation systématique de varints.
Ce dernier est préférable et globalement équivalent à celui de protobuf. Voici un exemple de classe de sérialisation avec Thrift
package com.octo.example.serialization.serializers.tree;
import com.octo.example.serialization.model.thrift.Node;
[...]
public class ThriftTreeSerializer {
public byte[] serialize(Node Object) throws Exception {
TSerializer serializer = new TSerializer(new TCompactProtocol.Factory());
return serializer.serialize(Object);
}
public Node deserialize(byte[] pMessage) throws Exception {
TDeserializer deserializer = new TDeserializer(new TCompactProtocol.Factory());
Node vRoot = new Node();
deserializer.deserialize(vRoot, pMessage);
return vRoot;
}
[...]
}
Protobuf lui ne propose nativement qu'un protocole binaire. Des extensions permettent le support d'autres protocoles de sérialisation, par exemple protobuf-java-format qui sérialise en JSON, XML ou HTML. La classe de sérialisation équivalente en protobuf :
package com.octo.example.serialization.serializers.tree;
import com.octo.example.serialization.model.LimitedTreeProto.Node;
[...]
public class ProtoBufTreeSerializer {
public byte[] serialize(Node object) throws Exception {
return object.toByteArray();
}
public Node deserialize(byte[] message) throws Exception {
CodedInputStream vStream = CodedInputStream.newInstance(message);
return Node.parseFrom(vStream);
}
[...]
}
Conclusion
Thrift et Protocol Buffers sont deux frameworks qui n'innovent pas sur le principe. Les deux frameworks sont relativement similaires et répondent surtout aux besoins des sociétés qui les ont créées, Facebook et Google. Elles ont revisité les mécanismes classiques d'interopérabilité via un IDL, en mettant l'accent sur les performances et la compatibilité ascendante et descendante, deux caractéristiques cruciales dans leur contexte. Ces frameworks proposent principalement de la sérialisation, avec en sus une implémentation RPC simple pour Thrift.
Du fait de la génération statique de code et de la nécessité potentielle de développer des méthodes de conversion, leur utilisation peut s'avérer coûteuse à mettre en œuvre. Comme beaucoup d'outils spécialisés, il vaut donc mieux avoir un besoin avéré de leurs avantages et bien évaluer leurs limitations avant d'envisager leur utilisation.
D'autres frameworks de sérialisation utilisent des principes différents de ceux de Thrift et Protocol Buffers. Apache Avro notamment, qui repose sur la présence systématique de l'interface dans le format sérialisé. Cela lui permet de rendre la génération de code optionnelle et de se passer d'identifiants uniques de champs.
Thrift et Protocol Buffers obtiennent des performances équivalentes dans un benchmark regroupant plusieurs sérialiseurs Java. Ce benchmark se limite toutefois à l'utilisation d'un unique message. Dans un prochain article, les deux frameworks seront comparés en termes de compacité de la sérialisation avec une structure de message variable.
Références
Les versions utilisées pour cet article sont la 0.8.0 pour Thrift et la 2.4.1 pour Protocol Buffers. Les liens suivants sont en anglais.
- Documentation officielle de Protocol Buffers : complète et didactique.
- Thrift : the missing guide, plus clair et détaillé que le très léger Wiki officiel de Thrift.
- Thrift white paper
- Java serializers benchmark : comparaison souvent remise à jour des performances d'un grand nombre de couples sérialiseurs/protocoles.
- Thrift vs Protocol Buffers : comparaison des deux projets d'un point de vue global (documentation, qualité de code, fonctionnalités, performances...)
**