Référencer une application web Single Page - AngularJS, NodeJS, PhantomJS et jsDOM
Le référencement c'est un peu le nerf de la guerre du web, et avec la venue de nouvelles pratiques de développement accompagnant l'explosion des frameworks JavaScript côté client (MVC, MVP, MVVM), de nouvelles problématiques apparaissent. Les développeurs sont de plus en plus amenés à construire les contenus depuis le navigateur, l'application côté serveur se limitant à une page 'template' globale (SPA), et le plus souvent des ressources REST/json sollicitées à la demande en Ajax pour préserver l'UX.
Ce type d'architecture logique rend impuissants les moteurs de recherche qui ne sont pas (encore) propulsés par un moteur JavaScript, comme illustrés ici :
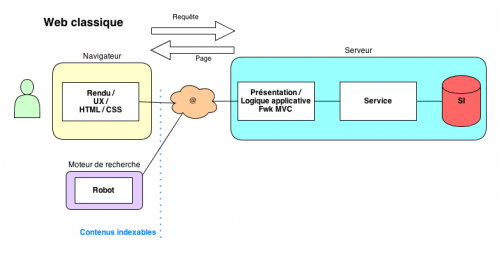
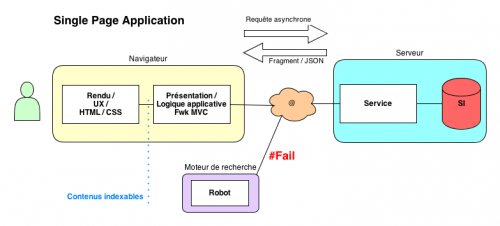
La simple indexation de fragments HTML ne pose pas véritablement de problème, il suffit de déclarer des hashbangs dans sitemap.xml et discriminer les requêtes de robots par _escaped_fragment_ (plutôt que user agent), comme suggéré dans le getting-started de Google sur ce sujet. La vraie difficulté réside donc dans les contenus eux-mêmes.
Puisqu'on sait discriminer les requêtes de robots, une solution rapide consiste à leur servir des pages statiques, ce qui revient à avoir un deuxième site à gérer (!).
Une autre approche consiste à faire générer ces snapshots de pages par les visiteurs eux-même, mais il faut alors embarquer le code qui va poster les snapshots sur le serveur, pas vraiment idéal...
Peut-on trouver une solution plus efficace et industrielle ?
Prenons un exemple d'application web codée en NodeJS propulsée par AngularJS qui sert une page globale index.html et les fragments de contenus a.html et b.html correspondant aux URIs /a et /b (sources du projet). Remarque : dans la terminologie AngularJS on parle de 'partial' pour faire référence à un fragment.
En browsant http://localhost:3000/a avec un navigateur on obtient :
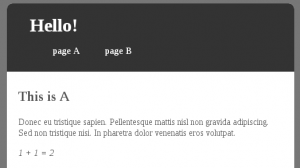
Le conteneur central est constitué d'un fragment HTML, en fait un partial chargé par le routeur Angular, et contient des données dynamiques évaluées via le binding Angular.
En se faisant passer pour un moteur de recherche on obtient logiquement une page avec un conteneur central vide : #fail
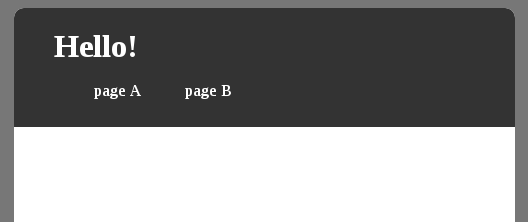
Plusieurs approches sont possibles pour obtenir un contenu :
1. Chargement des partials côté serveur :
En ajoutant un middleware bien placé dans l'application côté serveur, on peut dérouter les requêtes provenant de robots et inclure dynamiquement le partial correspondant à l'URI dans la vue (sources du projet).
var fs = require('fs')
, routes = require('../assets/js/routes') // Définition des routes Angular réutilisées par le serveur
, config = require('../config');
module.exports = function (req, res, next) {
var ua, template;
res.locals.viewContent = null;
ua = req.headers['user-agent'];
if (!ua.match(/bot/i)) { // Si ce n'est pas un robot on passe au middleware suivant (le routeur Express)
return next();
}
template = routes[req.path] || routes['']; // Chemin du template à charger en fonction de l'uri path
fs.readFile(config.baseDir + template, 'utf-8', function (err, data) {
if (err) {
console.error(err.stack);
res.send(500, 'Something broke!');
return;
}
res.locals.viewContent = data; // Injection du contenu du fichier dans la variable de template viewContent
next();
});
};
Ajouter une expression expressjs dans la vue template pour injecter le contenu du partial :
<section id="main"><%- viewContent %></section>
Le serveur étant codé aussi en JS, on peut facilement mutualiser le composant 'routes' :
(function () {
var routes;
routes = { // Map des routes Angular (uri -> chemin du partial)
'/a': '/assets/partials/a.html',
'/b': '/assets/partials/b.html',
'/': '/assets/partials/a.html',
'': '/assets/partials/notFound.html'
};
// Technique pour mutualiser un module JS côté client et côté serveur
if (typeof module !== 'undefined' && typeof module.exports !== 'undefined') {
module.exports = routes;
} else {
window.routes = routes;
}
})(); // Fonction auto-appelante, permet de définir un scope limité pour les variables
Résultat avec un robot :
Les contenus des partials sont bien récupérés, mais les données restent non valorisées. L'intérêt de ce type de solution est très limité, tout dépend de ce qu'on souhaite référencer. Dans certains cas ces données bindées peuvent être liées au contexte client donc inutile au référencement, mais la plupart du temps cette limitation est rédhibitoire.
2. Navigateur sans tête avec PhantomJS :
C'est l'approche la plus répandue, il s'agit d'utiliser PhantomJS comme navigateur headless pour interpréter le code client et obtenir les contenus valorisés. La difficulté concerne la récupération du contenu côté serveur, ici on triche en détournant l'API de log, voici donc le nouveau middleware avec phantomjs (sources du projet):
var phantom = require('phantom')
, ph;
phantom.create(function (phantomPh) {
ph = phantomPh;
});
module.exports = function (req, res, next) {
var ua;
res.locals.viewContent = null;
ua = req.headers['user-agent'];
if (!ua.match(/bot/i)) {
return next();
}
ph.createPage(function (page) {
page.set('onConsoleMessage', function (msg) { // Détection des événements console
var data;
try {
data = JSON.parse(msg);
} catch (err) {
}
if (data && data.mainContent) { // Récupération du contenu provenant de PhantomJS et injection dans le template
res.locals.viewContent = data.mainContent;
page.close();
next();
} else {
console.log('log from phantom :', msg); // Trace normale
}
});
page.open('http://localhost:3000' + req.path, function (status) {
page.evaluate(function () { // Evaluation de la page par PhantomJS, ici on est dans un contexte client
var mainElt, mainContent;
mainElt = document.getElementById('main');
mainContent = mainElt && mainElt.innerHTML; // On récupère le contenu qui nous intéresse
mainContent = mainContent || '';
console.log(JSON.stringify({ mainContent: mainContent })); // On envoie le contenu au serveur
});
});
});
};
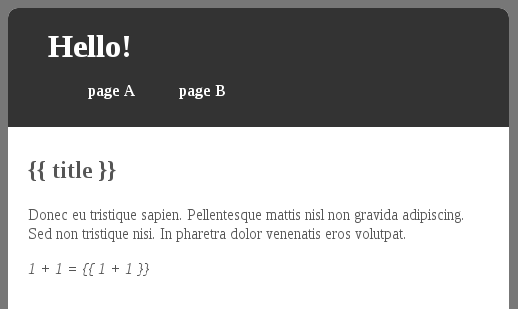
Résultat :
<section id="main">
<div class="ng-scope">
<h2 class="ng-binding">This is A</h2>
Donec eu tristique sapien. Pellentesque mattis nisl non gravida adipiscing. Sed non tristique nisi. In pharetra dolor venenatis eros volutpat. <em class="ng-binding"> 1 + 1 = 2 </em>
</div>
</section>
On obtient bien un contenu valorisé prêt à être référencé : objectif atteint La solution nécessite d'installer PhantomJS, et d'ouvrir un port supplémentaire (par défaut 12300). Chaque requête d'un robot déclenche sur le serveur une nouvelle requête vers le navigateur headless qui exécute tout le code client, en terme de scalabilité c'est moyen, mais cette limite ne concerne que les robots... PhantomJS est assez sensible, si le code JS lui pose problème le process sortira avec un code retour pas toujours très explicite, il faut donc une gestion d'erreur rigoureuse. Pour des raisons de commodités le serveur est codé en NodeJS, néanmoins le principe de mise en oeuvre est parfaitement transposable à n'importe quelle technologie serveur (Java par exemple).
3. Exécution de code client côté serveur avec jsDom :
Une autre approche consiste à utiliser une implémentation JavaScript de DOM qui joue un rôle similaire à celui de PhantomJS, mais sans nécessiter d'installation supplémentaire (binaire phantomjs) ni d'ouverture de port, tout se fait de manière programmatique. Version modifiée du middleware avec jsDom (sources du projet) :
var path = require('path')
, fs = require('fs')
, jsdom = require('jsdom')
, routes = require('../assets/js/routes')
, config = require('../config')
, template;
module.exports = function (req, res, next) {
var ua, template;
res.locals.viewContent = null;
ua = req.headers['user-agent'];
if (!ua.match(/bot/i)) {
return next();
}
template = routes[req.path] || routes['']; // On charge le contenu du partial
fs.readFile(config.baseDir + template, 'utf-8', function (err, data) {
if (err) {
console.error(err.stack);
res.send(500, 'Something broke!');
return;
}
res.locals.viewContent = data; // On stocke le contenu dans une variable de template
res.render('index', function (err, content) { // Lancement du rendu de la page index.html
var onLoad, jsDomConfig;
onLoad = function (errors, window) {
var document, angular, module, mainContent;
angular = window.angular; // Dans jsDOM tout est porté par l'objet window, pas de variable globale
document = window.document;
document.getElementById('main').removeAttribute('ng-view'); // On retire l'attribut pour inhiber le routeur Angular
window.scrollTo = function () { // API nécessaire à AngularJS mais manquante dans jsDOM
};
window.console = console;
module = angular.module('seospa', []);
module.config(['$locationProvider', function ($locationProvider) {
$locationProvider.html5Mode(true);
}]);
angular.bootstrap(document); // Là Angular va valoriser les contenus
mainContent = document.getElementById('main').innerHTML; // On récupère le fragment qui nous intéresse
res.locals.viewContent = mainContent; // Et on le réinjecte dans notre page
next();
};
jsDomConfig = {
html: content, // Contenu de la page
src: [ // Scripts à injecter
fs.readFileSync(path.join(config.assetsDir, 'lib', 'angular', 'angular.min.js'), 'utf-8'),
fs.readFileSync(path.join(config.assetsDir, 'js', 'controllers', 'HelloCtrl.js'), 'utf-8')
],
done: onLoad // Fonction à appeler une fois la page chargée
};
jsdom.env(jsDomConfig); // Lancement du chargement dans jsDOM
});
});
};
Là encore on obtient bien les contenus valorisés, objectif atteint. Chaque requête de robot déclenche sur le serveur le chargement dans jsDom de la page, on intercepte alors le chargement effectif pour exécuter un code JavaScript proche de notre application AngularJS originale, mais légèrement modifié pour inhiber le routeur. Le routeur AngularJS est inutile car la page est déjà raffinée, de plus toute tentative de chargement d'une route fera planter jsDom (chargement externe). Il reste à récupérer le contenu DOM qui nous intéresse (ici le sélecteur #main) et le réinjecter dans la vue côté serveur pour répondre au client. Avec jsDOM le surcoût en performance est négligeable, pas de connexion avec un tier, pas d'impact dans le code une fois le middleware en place. En revanche la solution est fortement liée à NodeJS; de plus le pseudo-navigateur se permet quelques interprétations qu'il va falloir hacker (absence de window.scrollTo par exemple).
Conclusion :
Référencer une application "Single Page" nécessite de combler l'absence de moteur JS dans les robots :
- soit en reproduisant les comportements du client sur le serveur : Les + : simplicité, efficace si on ne s'intéresse qu'aux simples contenus des partials sans les données dynamiques Les - : limité, peu réaliste si l'on veut tout supporter, lourd quand le langage serveur n'est pas JavaScript
- soit en utilisant un composant qui émule un navigateur : PhantomJS, ZombieJS, SlimerJS voire HtmlUnit Les + : véritable exécution du JS (webkit pour PhantomJS, gecko pour SlimerJS), solution agnostique en terme de techno serveur Les - : un composant en plus à maintenir
- soit en utilisant une implémentation DOM légère, avec NodeJS : jsDOM Les + : légèreté, efficacité, pas de connexion supplémentaire Les - : adhérence avec NodeJS, un navigateur en plus à gérer (hacks)
PhantomJS est souvent utilisé dans des usines logicielles via l'outil de build Grunt le plus souvent pour exécuter des tests, mais on peut facilement l'utiliser pour fabriquer une version statique du site dédiée aux robots si c'est l'objectif. Dans la mesure où la génération des pages peut se limiter aux contenus, sans mise en page ni éléments d'interaction, ce compromis peut être avantageux car simple et pas si coûteux.
Compte tenu de l’essor du langage JavaScript, il est fort à parier qu'à terme les robots seront équipés de moteurs JS, en attendant, comme souvent dans le web, il faut vivre avec des astuces...
[ Intégralité des sources disponible sur GitHub ]