ScyllaDB contre Cassandra : vers un nouveau mythe ?
Disclaimer : L'ensemble des tests décrits dans cet article ont été réalisés sur la version 0.10 de ScyllaDB. Nous invitons le lecteur à se reporter au site http://www.scylladb.com/ pour une vision à jour de ScyllaDB
Le 22 Septembre 2015, une communauté de développeurs annonce avoir mis au point une nouvelle base de données, et pas n’importe laquelle, la plus rapide au monde ! Répondant au doux nom de ScyllaDB, celle-ci s’inscrit dans la mouvance NoSQL dont les principales ambitions sont :
- Rendre les systèmes "scalables" en répartissant la charge de travail ou de stockage sur plusieurs machines.
- Rendre les systèmes tolérants aux pannes.
- Offrir des débits et des volumes élevés et des latences réduites
Dans ce milieu où les offres se sont multipliées ces dernières années, ScyllaDB présente une particularité intéressante : l’ensemble de ses structures et de son fonctionnement a été repris d'une autre base de données, Cassandra. Principale différence annoncée, ScyllaDB est écrit en C++ quand Cassandra est en Java.
L’avantage d’utiliser les mêmes structures est qu’il est possible d’interchanger les deux gestionnaires dans un cluster de façon totalement transparente pour l’utilisateur. Les développeurs Cassandra n’ont ainsi pas besoin de repenser leurs structures de données et peuvent les appliquer directement dans ScyllaDB. La barrière à l’entrée est donc réduite à son minimum pour les habitués de Cassandra.
Les premiers tests réalisés par l’équipe de ScyllaDB font état de débits de 10 à 20 fois plus élevés sur leur outil que sur Cassandra. Ils se présentent de ce fait comme un concurrent direct.
Tout ça juste en passant du Java au C++ ?
Pas uniquement. L’avantage d’avoir une application écrite en C++ est effectivement de réduire l’utilisation du processeur notamment en évitant au programme d’avoir à être chargé dans une JVM et d’être compilé à l’exécution. Dans Scylla, cette utilisation est également minimisée par une gestion du réseau s'offrant le luxe de se passer du noyau Linux. Aucun appel système n'est nécessaire pour effectuer une communication. Tout se passe dans l'espace utilisateur limitant ainsi le nombre de basculements entre celui-ci et l'espace noyau, coûteux en cycles processeurs et en copies de données.
D’autre part, avec le C++, il est possible d’avoir une gestion plus fine, mieux maîtrisée mais plus complexe de la mémoire. En effet, en Java c’est le garbage collector qui se charge de faire une passe régulièrement sur la mémoire allouée et qui libère l’espace inutilisé. Cette étape, extrêmement coûteuse en cycles processeur peut stopper l’application jusqu’à quelques secondes sur de grosses mémoires, le temps de “faire le ménage” (voir cet article pour plus de détails).
Bien que ces temps de garbage collection tendent à diminuer grâce à de nouveaux algorithmes plus efficaces, il est aujourd’hui recommandé de ne pas allouer plus de 8 Go de mémoire à la JVM lors de l’exécution de Cassandra, quand bien même votre machine aurait plus de 100 Go de mémoire (chose de plus en plus fréquente avec la diminution du coût de la mémoire vive). ScyllaDB se targue, lui, d’utiliser entièrement les ressources physiques de vos machines. En particulier, quand Cassandra s’appuie essentiellement sur le caching proposé par le système d’exploitation, un nouveau système de cache spécifique à Scylla a été mis en place pour stocker en mémoire de façon compressée les données récemment lues.
Nos essais
Suite à toutes ces affirmations alléchantes sur le papier, nous avons voulu en avoir le coeur net et vérifier par nous-mêmes, voir si l’expérience allait enfin se réconcilier avec son homologue de pensée. Les ambitions de Scylla peuvent en effet sembler trop belles pour être vraies : avoir une base de données 10 fois plus rapide sans avoir rien à changer au niveaux du matériel et du développement, comme le prétend la page d’accueil du site scylladb.com (voir image ci-dessous).
Image d’accueil du site scylladb.com : il serait possible d’arrêter Cassandra et de lancer Scylla sans problème, et de gagner un facteur 10 en débit
Pour cela, nous avons fait quelques essais sur Amazon Web Service en suivant les recommandations fournies par le site de ScyllaDB. Celui-ci propose une image (un AMI) à charger sur une machine Amazon, sur laquelle Scylla est déjà entièrement installé sur le système d’exploitation Fedora 22.
Premier test
Nous avons mis en place 3 groupes de machines :
- Un cluster Scylla composé de 3 noeuds
- Un cluster Cassandra composé de 3 noeuds
- 12 noeuds “tireurs” qui permettront de réaliser les tests en effectuant des requêtes auprès de chacun des 2 clusters précédents
Les noeuds Scylla et Cassandra sont les mêmes : m3.xlarge
Les noeuds tireurs sont tous les mêmes : c3.8xlarge
L’outil cassandra-stress permet de tester la charge supportée par un cluster Cassandra et est fourni avec l’image Scylla proposée. C’est donc avec lui que nous avons effectué nos requêtes sur les noeuds tireurs.
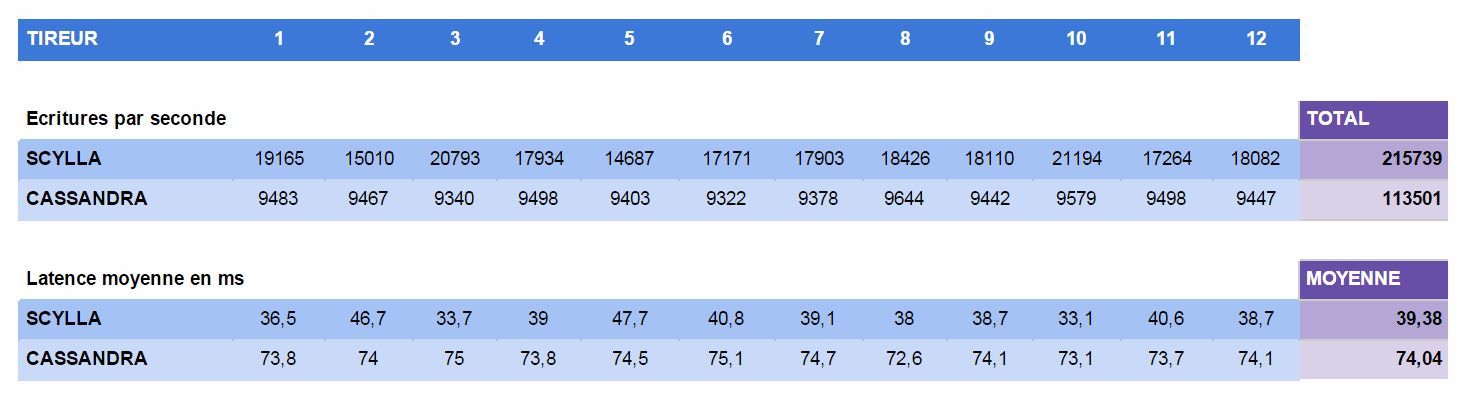
Nous avons obtenu les résultats suivants, détaillés dans le tableau :
- 215 000 écritures/seconde sur Scylla
- 113 000 écritures/seconde sur Cassandra
Plusieurs réserves néanmoins :
- Scylla tourne ici sur Fedora alors que Cassandra tourne sur Ubuntu
- Nous avons utilisé les AMI (AWS) pré-configurées sans les modifier
Nous sommes ensuite demandé si le débit mesuré chez Scylla n’avait pas été limité par le réseau, et par la charge à laquelle nous l’avions soumis.
Second test
Nous avons donc laissé reposer ces résultats puis réalisé de nouveaux tests. Cette fois-ci :
- Scylla et Cassandra tournent ici sur les mêmes machines, sous Fedora et le réseau est maintenant de 10Gbit.
- Nous avons augmenté le nombre de tireurs à 17
- Nous avons utilisé les configurations par défaut
Le but de ce nouveau test : pousser Scylla à bout afin de vérifier le débit maximum qu’il est capable d’absorber. Pour cela, nous utilisons maintenant 17 tireurs, connectés en 10 Gigabits afin de ne pas être limités par le réseau.
Et là, surprise, Scylla n’arrive pas à supporter le débit et renvoie systématiquement des timeouts aux tireurs, signe que la charge n’est pas absorbée. En réduisant le nombre de tireurs, on retrouve effectivement de bons débits en écriture sur Scylla sans timeouts. C’est donc bien la charge qui n’a pas été adaptée aux capacités de Scylla, alors que Cassandra, lui, ne présente pas ce problème : lorsqu’il est en surcharge, le débit des tireurs baisse automatiquement (car les requêtes sont synchrones), et ce sans timeout. Cela signifie que Cassandra remonte efficacement la pression au client. Dans le cas de Scylla, on s’expose à des pertes de tuples lorsqu'on le sollicite à un débit supérieur à sa limite.
A posteriori, en regardant de plus près les valeurs mesurées lors du premier test (cf. tableau ci-dessus), on constate également de plus grandes disparités de performances obtenues par les différents tireurs sur Scylla que sur Cassandra :
- En latence, nous avons un écart type relatif de 11 % sur Scylla, contre 1% sur Cassandra
- En débit, nous avons encore un écart type relatif de 11% sur Scylla et de 1% sur Cassandra
Dans notre cas, l'écart type nous permet de caractériser la stabilité des gestionnaires de données. En l'occurrence, Scylla apparaît ici significativement plus instable que Cassandra. Cela signifie qu'outre les incertitudes sur sa capacité à s'adapter à de fortes charges, il peut être délicat de prédire précisément les performances d'un cluster Scylla.
Il conviendrait bien évidemment d’investiguer davantage sur ces instabilités afin d’en établir les causes. Par ailleurs, les tests devraient être reproduits plusieurs fois et sur plusieurs machines correctement configurées pour avoir une valeur de benchmark. Néanmoins, ils permettent d’avoir un aperçu du potentiel de Scylla et de son état d’avancement.
Au-delà de ces constatations expérimentales, plusieurs remarques sont à effectuer sur Scylla (voir son statut) :
- Scylla utilise CQL 3.0 (contre une version 3.2 pour Cassandra 2.1 et même 3.3 pour Cassandra 2.2) comme langage de requêtes. La fonction ALTER n'est pas supportée, tout comme les compteurs qui n'ont pas encore été implémentés. De ce fait, l’outil cassandra-stress de Scylla a été légèrement adapté. La version Cassandra de cet outil ne fonctionne pas sur Scylla.
- Scylla utilise son propre système d'échange de données entre les noeuds, ce qui rend impossible l'utilisation d'un cluster contenant à la fois des machines Scylla et des machines Cassandra.
- Scylla ne supporte pas encore la communication sécurisée client-serveur et inter-noeuds via SSL.
Conclusion
Le bilan que l’on tire de ces expériences est qu’il est possible d’améliorer les performances de Cassandra à partir d’une gestion plus fine de la mémoire et en économisant quelques cycles processeurs. Ainsi, en état stationnaire, Scylla semble présenter un débit au moins 2 fois supérieur à celui de Cassandra (rappelons que l’équipe Scylla annonce un facteur 10). Le programme est cependant encore loin de l’état de maturité de Cassandra et plusieurs fonctionnalités essentielles manquent aujourd’hui à l’appel. Scylla n’en est toutefois qu’à sa version beta et une étude approfondie devra être menée lors de sa première sortie stable prévue en Janvier 2016, afin d’évaluer le sérieux de ce nouveau concurrent.
Scylla conservera-t-il cette avance en terme de latences une fois qu’il sera plus stable et qu'il aura implémenté toutes le fonctionnalités portées par Cassandra aujourd’hui ? Par ailleurs, Cassandra est aujourd'hui une technologie éprouvée, fonctionnant sur des clusters contenant jusqu'à plus de mille noeuds (voir cette présentation). Scylla parviendra-t-il à atteindre un tel niveau de maturité ?
Merci aux Octos pour l'apport de leur touche à cet article.