Retour d'expérience mobile Le Monde #partie 2
Dans la première partie de cet article, je présentais la partie organisationnelle des projets mobiles du Monde, et notamment comment avec une super équipe et un peu d'attention aux utilisateurs, on est parvenu à voir notre application dans le top des applications Françaises sur le store.
Dans cette seconde partie, je m'attache à décrire notre organisation au sein de l'équipe Android (gestion des sources, revues de code, releases, ...), ainsi que des aspects plus techniques (architecture, outillage, ...).
Cycle de développement
La chose essentielle lorsqu'on parle de développement, c'est le partage des sources. Je ne vais pas revenir sur l'intérêt d'avoir un gestionnaire de source mais sur l'utilisation qu'on en a fait et l'organisation associée.
Au Monde, nous utilisons github (dépôts privés). Basé sur git, maintenant très répandu, github a l'avantage d'être hors du SI et donc de pouvoir travailler hors des locaux si besoin. Bien entendu, github apporte de nombreuses fonctionnalités dont quelques unes nous ont été bien utiles.
Sur notre mode de travail, les points importants sont les suivants :
- Nous utilisons le flux de branches décrit dans le schéma suivant et détaillé ici :
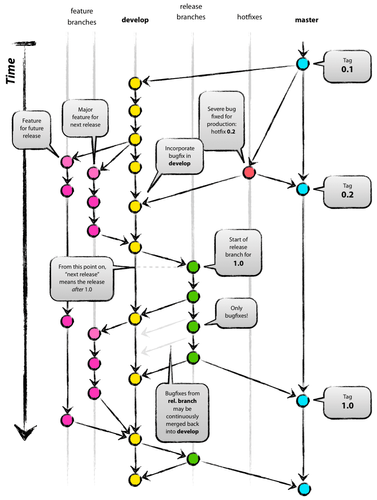
- Une branche de développement (« develop ») qui contient le code source le plus récent. Aucun développement ou presque n'est fait sur cette branche, seulement quelques corrections mineures.
- Des branches par fonctionnalités (« feature branches »). Une nouvelle branche est créée pour chaque nouvelle fonctionnalité à développer. Elle est mergée sur develop une fois validée.
- Une branche de « release » lorsqu’on décide de figer une version et de faire la recette.
- Une branche « master » qui constitue notre version de production, issue de la release corrigée suite à la recette.
- Des branches de patch/fix, utilisées pour corriger la release ou la master (sans oublier de les merger sur develop bien sûr).
- Associé aux feature branchs, nous utilisons une fonctionnalité bien connue de github : les pull requests. Lorsqu’un développeur termine le développement d'une fonctionnalité, il créé une pull request (diff entre la branche de développement et la branche de la fonctionnalité).
- Un autre développeur peut alors récupérer la branche en question, faire une revue de code, et finalement accepter ou refuser la requête. Si c’est ok, la branche est automatiquement mergé sur la dev. Au Monde, les revues de code sont systématiques. D’une part cela permet d’éviter certaines étourderies et d’améliorer la qualité du code, mais cela permet aussi de connaître une plus grande partie de l’application, et parfois d’apprendre tout simplement.
Remarque : Il y a les défenseurs du trunk based development et ceux qui sont plutôt feature branch. Je vous invite à faire la recherche google "feature branch vs trunk based development" pour vous rendre compte du combat acharné :
- Le premier limite les risques de merge compliqués puisqu'il n'y a pas de merge de branches à faire (ou presque pas, il y a tout de même une branche de release). Par contre, cela implique de bien maitriser ses fonctionnalités et de pouvoir faire du feature flipping pour désactiver une fonction qui n'aurait pu être finie avant la livraison. Il implique également d'avoir un serveur d'intégration continue pour valider en continue que le code commité est stable. C'est ce que je préconisais avant de connaître git... Et c'est ce que la plupart des géants du web ^[<a href="http://paulhammant.com/2013/05/06/googles-scaled-trunk-based-development/" title="google trunk" target="_blank">1</a>][<a href="http://paulhammant.com/2013/03/04/facebook-tbd/" title="facebook trunk" target="_blank">2</a>]^ font.
- Le second, sur lequel nous sommes partis au Monde, est très pratique pour les revues de code. Une fonctionnalité non terminée (non mergée) n'est pas embarquée dans l'application et il n'y a donc pas de feature flipping à mettre en oeuvre. Par contre, le risque est d'avoir des merges compliqués lorsque la feature est terminée. Pour palier à ça, nous faisions régulièrement des rebase de develop pour être à jour. Il nous est arrivé d'avoir quelques branches qui perdurent dans le temps et effectivement dans ce cas, c'est assez compliqué. Il faut donc veiller à la granularité des fonctionnalités pour limiter ce risque.
Cycle de release et de déploiement
Sur ces points, nous avons eu deux phases assez différentes :
- La première, lorsque nous sommes rentrés en période de run suite à la première release en juin. Sur cette phase, nous avions un rythme d'une release toutes les 3/4 semaines et un process à peu près rodé : on fige les développements sur la branche de release, on met à disposition une version pour les PO et ils testent pendant quelques jours, voire une semaine (logiquement, ils ont déjà testé en continu avec le déploiement continu les stories marquées comme done sur notre kanban). Une fois validé, on merge sur master et on tag la version sur git. Sur Android, nous avons largement exploité le déploiement progressif que permet le Play Store afin de s'assurer qu'aucun crash ne survient. Généralement, nous déployions à 20% pendant deux jours, puis 50% pendant deux jours puis finalement 100%. Il nous est arrivé de ne rien voir sur le déploiement à 20% et d'avoir des remontées foudroyantes (notes et commentaires) à 50%. Cela nous a permit de rapidement déployer un patch et d'éviter le massacre qui aurait lieu pour un déploiement à 100%.
- Puis est arrivée une phase un peu plus laxiste et compliquée. C'est essentiellement dû à deux "grosses fonctionnalités" qui devraient arriver prochainement (courant mai). Durant cette phase, nous avons développé les deux grosses fonctionnalités sur le trunk (avec des micro feature branches pour faciliter les revues de code). Conséquence : toutes les releases provenaient de patchs de la branche master (corrections ou petites fonctionnalités). Le feature flipping aurait pu nous aider à faire autrement mais les fonctionnalités sont trop impactantes (et je n'en dirai pas plus) pour pouvoir le mettre en oeuvre.
Qualité
Tests
Au delà des revues de code, nous nous efforçons de couvrir le maximum de code (métier, utilitaires) par des tests unitaires ou d'intégration. Si c'était moins vrai au début du projet Actu En Continue, ça l'est de plus en plus (notamment sur la Matinale que nous avons démarré en janvier et parue le 11 mai), et c'en est presque devenu un jeu, "celui qui aura la plus grosse... couverture".
Sur l'application Actu En Continu, dont l'architecture initiale n'était pas très structurée, la couverture globale est de 30% de 38000 loc (~720 tests). Sur l'application La Matinale, très orienté MVP, la couverture est pratiquement de 60% de 10500 loc (480 tests). Je reviendrai sur MVP un peu plus loin...
Techniquement, on utilise des frameworks assez standards sur Android, à savoir JUnit et Robolectric. Ces deux outils ont l'avantage de s'exécuter sur une JVM et d'être ainsi beaucoup plus rapides à s'exécuter.
Easymock, bien connu sur java, nous permet de mocker et rendre nos tests plus unitaires et indépendants.
Plus récemment, nous avons décidé de mettre en place des tests d'interface avec espresso 2 pour valider certains parcours nominaux (ouvrir une rubrique, parcourir les articles, en ouvrir un, ...). Le principal intérêt d'espresso par rapport à Robotium ou Selendroid est la synchronisation avec le thread UI. Sur Robotium, il est nécessaire de faire des wait pour attendre que l'interface soit à jour avant de continuer les tests. Parfois (souvent ?), même après avoir attendu, l'interface n'est pas à jour et les tests échouent. C'est quelque peu irritant de ne pas pouvoir faire confiance à ses tests... De son côté, espresso continue l'execution des tests lorsque le thread UI est disponible. De même il gère nativement les AsyncTask. Par contre si vous avez des traitements longs et que vous n'utilisez pas les AsyncTask, vous devrez définir des Idling Resources, typiquement pour attendre le retour d'un web service. Pour l'instant, nous n'avons posé que quelques tests de ce type mais ça reste un objectif à court/moyen terme.
Intégration continue et indicateurs
Là encore, deux outils bien connus nous ont été fort utiles. Jenkins d'une part, comme moteur de notre intégration continue, construisant et testant notre application à chaque commit. SonarQube d'autre part, nous fournissant un rapport complet de la qualité du code (problèmes potentiels, couverture des tests, ...).
Dernièrement (mars), nous avons également mis en place des builds Travis qui valident nos pull request avant de les merger. Avec l’intégration à github, on obtient quelque chose de très visuel et d'assez pratique. Ca facilite le travail par feature branch dont je parlais plus haut, en constituant en quelque sorte un unbreakable merge (cf. unbreakable build dont je parlais sur ce blog en 2008...).
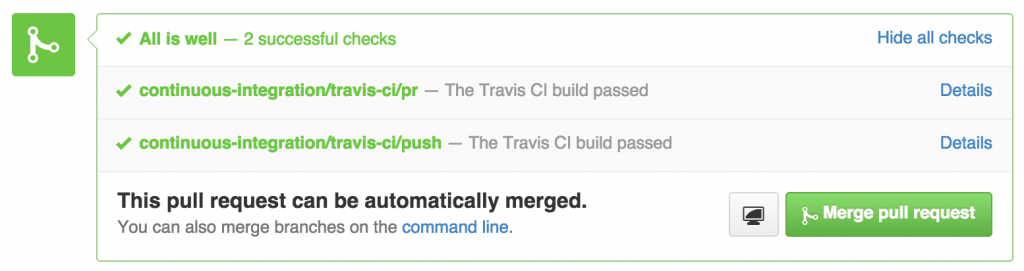
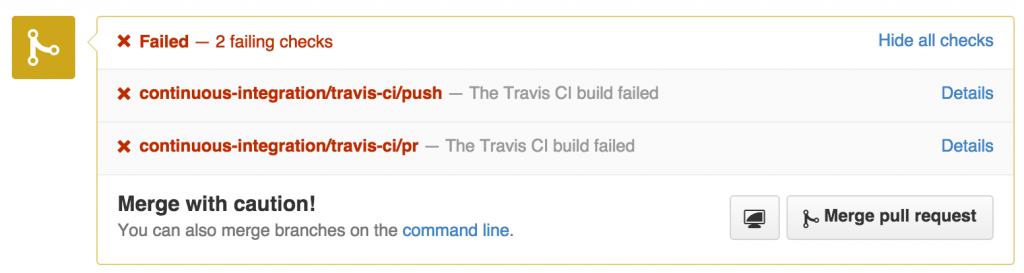
À ces outils de plus en plus standards (et je dirai même indispensables), s'ajoute un autre qui nous permet d'aller plus loin et de faire de la livraison continue (continuous delivery). Il s'agit de HockeyApp (équivalent à Appaloosa). Il nous permet de mettre à disposition la fameuse dogfood dont je parlais plus haut. À chaque build Jenkins réussi, la version la plus récente de l'application est poussée à tous les utilisateurs ayant accepté de jouer au cobaye.
Nous aurions pu aller plus loin en faisant de la mise en production en continue, avec le plugin Jenkins Google Play Android Publisher sur le build de notre branche master (production). Nous ne l'avons pas fait pour la simple et bonne raison que nous souhaitons faire une dernière passe de tests manuels et notamment un test de montée de version avant le déploiement.
Architecture et outillage
MVP
Sur l'application Actu En Continu, nous n'avions pas d'architecture applicative à proprement parler. Nous utilisions des "managers" qui contiennent l'essentiel du code métier et des frameworks pour nous aider à découpler notre code (dagger et otto notamment; j'y reviendrai), mais il subsiste beaucoup de code dans nos Fragments, ce qui rend difficile les tests unitaires.
Sur l'application La Matinale, nous avons décidé dès le départ d'utiliser le pattern MVP (Model View Presenter). Ce pattern a l'avantage de manipuler la vue au travers d'une interface, rendant plus facile les tests unitaires puisqu'il devient possible de mocker cette vue et d'être agnostique du SDK Android, du Context, ...
Couplé à ce pattern, nous utilisons Dagger pour l'injection des dépendances. Je vous épargne l'explication du concept, prenons un exemple simple :
La fameuse interface pour notre vue :
public interface ArticleView {
void displayArticle(final Article article);
void displayError();
}
Et le fragment (ca pourrait aussi être une activité) qui implémente cette interface :
public class ArticleFragment implements ArticleView {
@Inject
ArticlePresenter mArticlePresenter;
@Override
public void onAttach(final Activity activity) {
super.onAttach(activity);
final ArticlesModule articlesModule = new ArticlesModule();
articlesModule.setArticleView(this);
// https://gist.github.com/doridori/602f00e37fdeeac7756d
DaggerHelper.injectWithScopedModules(this, Arrays.<DaggerModule>asList(articlesModule));
}
@Override
public void displayArticle(final Article article) {
// fill article webview and others fields
}
@Override
public void displayError() {
// display an error message / toast / whatever
}
}
Notre presenter :
public interface ArticlePresenter {
void load(final long articleId);
}
Et son implémentation :
public class ArticlePresenterImpl implements ArticlePresenter {
private ArticleView mArticleView;
private ItemsManager mItemsManager;
public ArticlePresenterImpl(final ArticleView articleView, final ItemsManager itemsManager) {
mArticleView = articleView;
mItemsManager = itemsManager;
}
@Override
public void load(final long articleId) {
// load data from cache, database or anywhere
Article article = mItemsManager.loardArticle(articleId);
if (article == null) {
mArticleView.displayError();
} else {
mArticleView.displayArticle(article);
}
}
}
Et le boilerplate code dagger pour que la magie opère :
@Module(
injects = {
ArticleFragment.class
},
addsTo = AndroidModule.class,
complete = false
)
public class ArticlesModule implements DaggerModule {
private ArticleView mArticleView;
public void setArticleView(final ArticleView articleView) {
mArticleView = articleView;
}
@Provides
public ArticlePresenter provideArticlePresenter(final ItemsManager itemsManager) {
return new ArticlePresenterImpl(mArticleView, itemsManager);
}
}
Dagger
Si nous avons évolué sur notre manière d'architecturer l'application, nous avons également évolué sur notre usage de Dagger. En effet, sur l'Actu En Continu, nous avions un unique module, contenant tous nos Provides, toutes les classes injectées, bref le mega module. On peut donc injecter tout, partout, tout le temps... Si c'est plus simple à l'usage, c'est par contre très consommateur de mémoire puisque toutes les classes fournies par ce module sont instantiées.
Sur l'application La Matinale, nous sommes partis sur des modules plus fins (comme dans l'exemple ci-dessus), avec des scopes limités. Par exemple un module pour un pan fonctionnel précis, voire pour un écran. Cela permet au GC de faire le ménage lorsqu'on quitte ce pan fonctionnel ou cet écran et réduire un peu l'empreinte mémoire.
Par ailleurs, toujours dans notre objectif de tester plus, Dagger met à disposition une option pour surcharger un objet providé (overrides = true, malheureusement, cette option n'existe plus dans Dagger 2). Si on reprend notre exemple ci-dessus on peut par exemple surcharger la classe ItemsManager pour tester unitairement le presenter :
public class ArticlePresenterTest {
@Before public void setUp() {
DaggerHelper.initWithTestModules(new TestModule());
}
@Module(
addsTo = AndroidModule.class,
overrides = true
)
static class TestModule {
@Provides @Singleton ItemsManager provideItemsManager() {
return new ItemsManagerMock(); // use easymock, mockito, ... or your own mock
}
}
}
Otto
Pour compléter notre boîte à outils, nous utilisons également Otto, fonctionnant sur le principe du publish & subscribe, et qui permet d'envoyer des événements sur un bus. Cela nous évite les nombreux listeners passés un peu partout et permet donc de découpler le code encore un peu plus.
Un bémol tout de même car si cela semble magique, ça peut être source d'arrachage de cheveux. Quelques cas d'usage dont il faut se méfier :
- Un subscribe est fait dans un fragment se trouvant dans un ViewPager. Les 3 fragments "visibles" à l'écran vont donc être notifiés. Ce n'est probablement pas ce qui est voulu... Dans ce cas, pensez à vérifier la valeur de
getUserVisibleHint(). - Si une activité A lance une activité B. A souscrit à un événement qui va être déclenché dans B (ou plus profondément dans un fragment de B par exemple). Si l'activité A est tuée par le système, elle ne recevra jamais l'événement... Un
startActivityForResult()est peut-être plus approprié dans ce cas. - ...
Les autres frameworks
Outre Dagger et Otto qui sont très pratique pour découpler le code au maximum, nous avons utilisé d'autres frameworks pour nous faciliter la vie :
- volley, pour la couche d'appel des web services (avec les fonctions d'asynchronisme et de cache http).
- butterknife, qui nous simplifie la récupération des vues (
@InjectView) et leur manipulation (@OnClick). - picasso (et oui, encore square...), qui comme son nom ne l'indique pas, permet de télécharger des images puis de les afficher.
- ... et d'autres plus communs : apache commons, jackson pour la (de)serialisation json, joda time, les play services évidemment, ... À noter que nous n'avons pas utilisé guava, un peu lourd pour Android.
Conclusion
En un an (février 2014 - février 2015), nous sommes passé de 1.2 millions à plus d'1.7 millions d'utilisateurs actifs (environ 250 000 visiteurs uniques et plus de 2 000 000 de pages vues par jour).
Sur la même période, la note a progressé de pratiquement 0.5 point, passant de 3.6 à 4.06 étoiles, pas si simple quand il s’agit de la moyenne de plusieurs dizaines de milliers de notes.
Bien entendu, s'appeler Le Monde aide beaucoup à générer du trafic, et cela permet aussi d'avoir une aide précieuse de la part de Google (préconisations, invitations à des événements, support...). Mais avoir une application de qualité permet de le conserver, d'augmenter sa visibilité et la satisfaction utilisateurs, et pourquoi pas, de faire partie de la sélection Google des meilleures applis de l'année. 