Quoi de neuf dans Hadoop 2.0 ?
Introduction
Cloudera a sorti une nouvelle version de sa distribution, la CDH4 qui intègre Hadoop 2.0.0.
Cette version apporte de grosses nouveautés, la plus emblématique étant YARN (Yet Another Resource Negociator) que l'on nomme parfois MRv2 (Map Reduce 2) bien ces deux dénominations ne soit pas synonymes comme nous allons le voir par la suite.
Les bases sont là mais il est à noter que certains éléments présentés ci dessous sont encore en cours d'implémentation dans Hadoop 2.
Malgré tout, il nous semble intéressant de nous pencher sur quelques une des évolutions.
Une évolution architecturale majeure
Cette nouvelle version d'Hadoop apporte donc une évolution architecturale majeure : YARN.
YARN est une évolution de l'architecture d'Hadoop permettant de décharger le JobTracker qui avait tendance à cumuler trop de rôles et devenait donc complexe à maintenir et à faire scaler.
Cette remise à plat des rôles à permis aussi de découpler Hadoop de Map Reduce et, ce faisant, de permettre à des frameworks alternatifs d'être portés directement sur Hadoop et HDFS et non au dessus de Map Reduce.
Cela va donc permettre à Hadoop, outre une meilleure scalabilité, de s'enrichir de nouveaux frameworks couvrant des besoins peu ou pas couverts avec Map Reduce.
Si cela vous intéresse, une liste des frameworks portés ou en cours de portage est disponible sur le site du projet.
On y retrouve notamment deux projets Apache :
- Giraph pour le Graph Processing qui est utile pour les calculs de classification de résultats de recherche, de news, de pubs, ...
- Hama pour le calcul scientifique distribué.
Le JobTracker a disparu de l'architecture
Ou plus précisément, ses rôles ont été répartis différemment.
L'architecture est maintenant organisée autour d'un ResourceManager dont le périmètre d'action est global au cluster et à des ApplicationMaster locaux dont le périmètre est celui d'un job ou d'un groupe de jobs.
En terme de responsabilités, on peut donc dire que : JobTracker = ResourceManager + ApplicationMaster. La différence, de part le découplage, se trouve dans la multiplicité. En effet, Un ResourceManager gère n ApplicationMaster, lesquels gèrent chacun n jobs.
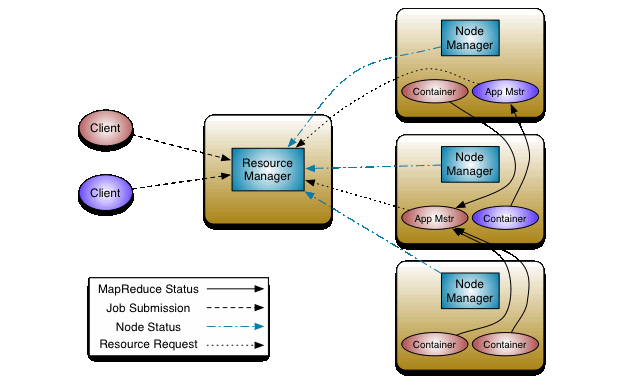
Le ResourceManager
Le ResourceManager est le remplaçant du JobTracker du point de vue du client qui soumet des jobs (ou plutôt des applications en Hadoop 2) à un cluster Hadoop.
Il n'a maintenant plus que deux tâches bien distinctes à accomplir :
- Scheduler
- ApplicationsManager
Le Scheduler
Le Scheduler est responsable de l'allocation des ressources des applications tournant sur le cluster.
Il s'agit uniquement d'ordonnancement et d'allocation de ressources.
Les resources allouées aux applications par le Scheduler pour leur permettre de s'exécuter sont appelées des Containers.
Un Container désigne un regroupement de mémoire, de cpu, d'espace disque, de bande passante réseau, ...
Ces informations sont remontées du cluster par les NodeManager, qui sont des agents tournant sur chaque noeud et tenant le Scheduler au fait de l'évolution des resources disponibles. Ce dernier peut ainsi prendre ses décisions d'allocation des Containers en prenant en compte des demandes de ressources cpu, disque, réseau, mémoire, ...
L'ApplicationsManager
Il accepte les soumissions d'applications.
Une application n'étant pas gérée par le ResourceManager, la partie A_pplicationsManager_ ne s'occupe que de négocier le premier Container que le Scheduler allouera sur un noeud du cluster. La particularité de ce premier Container est qu'il contient l'ApplicationMaster.
L'ApplicationMaster est le composant spécifique à chaque application qui est en charge des jobs qui y sont associés.
- Lancer et au besoin relancer des jobs
- Négocier les Containers nécessaires auprès du Scheduler
- Superviser l'état et la progression des jobs.
Un ApplicationMaster gère donc un ou plusieurs jobs tournant sur un framework donné. Dans le cas de base, c'est donc un ApplicationMaster MRv2 qui lancer un job MapReduce. De ce point de vue, il rempli un rôle de TaskTracker.
L'ApplicationsManager est l'autorité qui gère les ApplicationMaster du cluster. A ce titre, c'est donc via l'ApplicationsManager que l'on peut
- Superviser l'état des ApplicationMaster
- Relancer des ApplicationMaster
De gros changements dans les API
Les évolutions architecturales présentés ci dessus ont induit des modifications dans les APIs d'Hadoop.
Cependant, une couche de rétrocompatibilité avec Hadoop 0.20.2 est maintenue afin de permettre une migration en douceur.
La seule contrainte étant de recompiler ses jobs avec la nouvelle version d'Hadoop.
Le SPOF du Namenode a disparu
L'ancienne architecture d'Hadoop imposait l'utilisation d'un namenode, composant central contenant les métadonnées du cluster HDFS. Ce namenode était un SPOF.
En effet, dans un cluster HDFS, les données sont répliquées sur plusieurs noeuds. Mais les métadonnées elles, sont stockées dans le namenode. si le namenode tombe, on perd les données.
Des mécanismes de type secondary et backup namenode ont été mis en place mais le temps de down est trop important pour un gros cluster. Ce souci est assez bien expliqué dans cet article de Facebook Engineering.
Dans Hadoop 2, on peut mettre deux namenodes en mode actif/attente.
Cela signifie que le namenode actif est celui qui est utilisé par le cluster tandis que celui en attente se contente d'écouter ce qui se passe. Cela est différent d'un maître/esclave dans la mesure où chaque datanode envoi maintenant ses informations aux deux namenodes. L'actif et celui en attente. La bascule peut donc se faire à chaud et donc plus rapidement lorsque le noeud actif tombe. La conséquence de ce mode de fonctionnement est que le SLA est meilleur puisque le temps moyen avant redémarrage est diminué.
Un point d'attention majeur toutefois est qu'il faut que les deux namenodes partagent un répertoire. Cela peut être via NFS ou d'autres méthodes mais c'est nécessaire pour faire fonctionner le mode actif/attente. Il faut donc être vigilant afin de ne pas remplacer un SPOF par un autre.
La fédération HDFS
Dans un cluster HDFS, un namenode correspond à un espace de nommage (namespace). Jusqu'à présent, on ne pouvait utiliser qu'un namenode par cluster. La fédération HDFS permet de supporter plusieurs namenodes et donc plusieurs namespace sur un même cluster.
Un cas d'usage de la fédération HDFS serait d'isoler les directions métier sur un socle commun de stockage. On évite ainsi qu'un job lancé par une direction métier ne touche, ne déplace voire supprime (collision de noms, faute de frappe dans le job, ...) un fichier, un répertoire important pour une autre direction.
En terme d'infrastructure et de dev, la fédération HDFS est intéressante car elle permet, sur un même cluster HDFS déjà en place avec ses procédures d'exploitation, de maintenance, ... de fournir un espace de production, un espace de recette et un espace de développement parfaitement isolés. Il devient donc possible par exemple de développer des algorithmes de d'analyse nécessitant de gros volumes de données en entrée sur un seul et même cluster HDFS commun.
Conclusion
Les changements architecturaux d'Hadoop 2.0.0 sont, à minima, intéressants à deux titres :
- Du point de vue ops, haute disponibilité et la capacité de mutualiser l'infrastructure HDFS;
- Du point de vue dev et métier, le découplage par rapport à Map Reduce va permettre de faire émerger d'autres framework. Hadoop n'est donc plus un moteur MapReduce, mais bien un moteur générique pour du calcul distribué.