Qu'est ce que Storm ?
Le domaine des big data est très prolifique, de nouveaux produits sortent régulièrement, certains meurent rapidement, d'autres, au contraire, connaissent un certain succès. Storm appartient à la seconde catégorie.
Peut-être que vous vous demandez ce qu'est Storm. Est ce un concurrent d'Hadoop ? Une solution pour faire du requêtage en temps réel ? Encore autre chose ?
Nous allons tenter, au travers de cet article, de vous aider à comprendre ce qu'est Storm et pourquoi il remporte un certain succès aujourd'hui.
Storm, une solution de CEP polyvalente
Storm est une solution OpenSource de Complex Event Processing (CEP) relativement jeune puisque sa première version stable date de Septembre 2011.
Si vous ne voyez pas ce qu'est le Complex Event Processing, je vous conseille de lire ou de relire nos articles Complex Event Processing, de quoi s'agit-t-il ainsi que l'introduction au Complex Event Processing (en Anglais).
Malgré son jeune âge, Storm connaît un grand succès, Yahoo l'ayant même porté sur Hadoop YARN avec son projet Storm-YARN.
Pourquoi un tel succès ? Voici quelques éléments de réponse.
Calculs en temps réel sur des big data
Storm a été développé par Nathan Marz pour Backtype, une startup rachetée par la suite par Twitter. Ainsi, les premières versions de Storm étaient internes et répondaient à un vrai besoin pour le business de Backtype.
En l'occurrence, le besoin d'effectuer des traitements et des calculs complexes en temps réel sur des flux de données que l'on peut qualifier de big data de part leur volume et leur haute fréquence (comme le flux Twitter).
Distribué et tolérant aux pannes
Qui dit traitement de big data dit beaucoup de serveurs pour tenir la charge. C'est pour cela que Storm a été conçu pour être distribué et tolérant aux pannes.
Ainsi, de la même manière qu'avec MapReduce sur Hadoop, il est possible de monter en charge en ajoutant des serveurs, dynamiquement.
Elégance et simplicité
Storm est majoritairement écrit en Clojure, un langage fonctionnel dérivé de LISP et fonctionnant sur la JVM qui, de par ses racines, est particulièrement expressif.
D'autre part, et c'est peut être là le plus important, Storm tend à rester le plus simple possible.
Simple à déployer, avec une bonne intégration de ses différentes briques et un minimum de configuration pour lancer un cluster (en quelques lignes de configuration seulement).
Simple à appréhender au niveau de son architecture car il applique la même philosophie qu'Unix avec les fichiers à savoir que tout repose sur quelques abstractions simples à appréhender et à manipuler que sont :
- les topologies
- les streams
- les spouts
- les bolts
- les drpc
La compréhension de ces 5 concepts permet de comprendre comment fonctionne Storm.
Le reste n'étant "que" des constructions reposant sur eux.
Les topologies et les streams
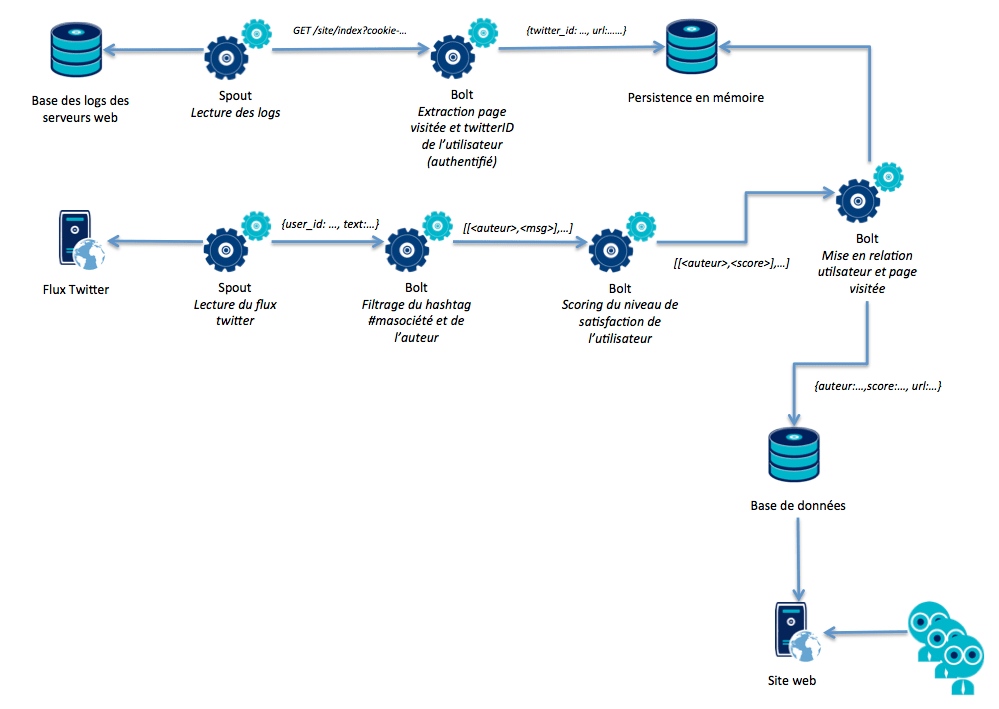
Nous l'avons dit, Storm permet d'effectuer une série de traitements et de calculs sur un flux de données.
Comme le montre le schéma ci dessus, une topologie est un enchaînement de traitements. Quant au Stream, il s'agit du flux de données que l'on passe d'un traitement à un autre. Dans notre exemple, le contenu des flèches bleues entre les bolts sont autant de streams.
Un stream est une liste de tuples. Charge donc au développeur de définir ce qu'il souhaite inclure dans les streams que génèrent chaque Bolt et chaque Spout.
Ici, nous voyons clairement qu'en fonction du bolt (et donc du traitement) effectué, le stream en entrée n'est pas le même qu'en sortie. Tantôt enrichi, tantôt simplifié.
Les spouts et les bolts
Ce sont les deux abstractions que le développeur doit implémenter.
Les Spouts
Les Spouts ont pour rôle de :
- Se connecter à une source de données
- mettre au format son contenu afin de l'envoyer dans la topologie sous forme de stream
Le Stream émis par un Spout sert donc de point de départ aux traitements effectués sur une topologie.
Dans notre schéma, les deux sources de données :
- Base des logs de serveurs web
- Flux Twitter
Ne sont pas de même nature, n'ont pas la même fréquence d'émission ni le même volume de données. Ce sont donc deux spouts qui s'y connectent, en lisent le contenu à une fréquence adaptée à chaque source de donnée et envoient chacun sur la topologie un stream contenant les informations utiles aux analyses que l'on souhaite effectuer.
La version du navigateur n'étant pas utile ici par exemple, elle n'est est donc pas envoyée dans le stream.
La fréquence de polling de la source de données par le spout est laissée à la discrétion du développeur. Cela permet de s'adapter aux contraintes de cette dernière, par exemple :
- La bande passante avec la source de données étant limitée, on ne veut pas saturer le réseau
- Des règles d'usage de type fair use sont en place sur la source de données, on ne veut donc pas effectuer trop de requêtes à la seconde dessus
D'autre part, Storm garanti que chaque tuple d'un stream émis sera transféré à un bolt au moins une fois.
Les Bolts
Un Bolt implémente un traitement, un calcul particulier.
Ce dernier peut être une somme, un appel à un script R pour faire des calculs prédictifs, une écriture dans une base de données, … La seule contrainte est de pouvoir le coder dans un langage supporté tel que Java, Clojure ou Python.
Dans notre schéma, nous avons par exemple le bolt "filtrage du hashtag" dont le rôle est d'extraire de chaque tuple de son stream d'entrée contenant le hashtag #masociété, le nom de l'auteur ainsi que son texte afin de produire un stream alimentant un autre bolt chargé de faire une analyse de sentiment sur le contenu du tweet.
Ainsi, chaque bolt est très spécialisé ce qui permet, comme nous en parlerons plus bas, d'identifier et de fixer plus facilement les goulots d'étranglement dans une topologie.
Dans l'idée, cela ressemble beaucoup à des outils de conception de flux. En revanche dans Storm, on passe par du code, et cela permet de pousser très loin les raffinements.
Les DRPC
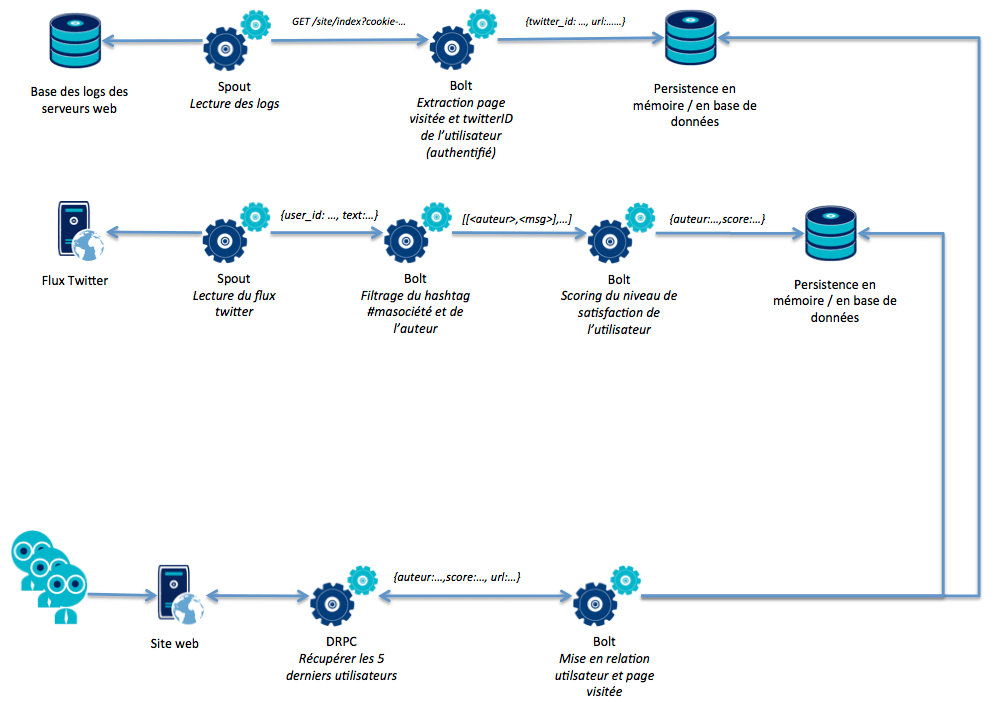
Storm permet d'exposer des DRPC (Distributed Remote Procedure Call) ou appel de fonction distribué.
Dans l'idée, le DRPC est un peu comme un spout dont la source de données serait les arguments de la fonction et qui retournerait une valeur comme une chaîne de caractères ou un json.
L'appel de fonction étant distribué, un ensemble de bolts est donc mobilisé pour effectuer le traitement le plus rapidement possible, et ce d'autant plus qu'un DRPC est un appel synchrone et donc bloquant pour l'appelant.
Quel cas d'usage pour un DRPC ?
Le DRPC est utile pour distribuer un calcul coûteux en temps et ainsi diminuer son temps de réponse.
Il peut aussi servir à effectuer certains agrégats ou rapprochements à la demande plutôt que de tout calculer en amont lors de la capture d'une source de données.
Ainsi, nous pouvons ré-écrire notre exemple de topologie en utilisant cette fois un DRPC.
Techniquement
Une stack logicielle simple
Pour fonctionner, Storm a besoin de :
- Zookeeper pour coordonner l'état du traitement d'un tuple à travers une topologie
- zeromq et jzmq pour les échanges stream entre bolts dans une topologie
- supervisord pour lancer les différents services de Storm
Le binaire storm, qui est en fait un script Python lançant des processus Java, sert de point d'entrée unique pour lancer ces services :
- nimbus : le démon auquel sont soumis les topologies de traitement
- supervisor : le démon installé sur chaque noeud du cluster et qui lance les bolts d'une topologie
- ui : le démon qui lance l'interface web de Storm. C'est elle qui permet de suivre l'état des topologies ainsi que leurs statistiques
- drpc : le démon qui lance un serveur DRPC qui permet de communiquer en direct avec une topologie
Le parallélisme dans Storm
Ce découpage illustré dans les deux schémas plus haut permet de jouer sur le parallélisme d'un cluster Storm au niveau du spout et du bolt.
Ainsi, si par exemple, le flux Twitter devient soudain si volumineux que notre bolt d'extraction se retrouve saturé, il est possible simplement de redimensionner ce bolt afin de lui allouer plus de ressources pour s'adapter à la montée en charge.
Cela dit, comment identifier que ce bolt d'extraction est saturé ?
Storm UI fournit des statistiques précises et en temps réel de débit en entrée, en sortie, de latence moyenne, du nombre de tuples traités ou dont le traitement a échoué et ceux, par spout et par bolt.
Ainsi, l'identification du goulot de notre bolt est possible simplement en regardant dans l'interface de Storm UI, l'état de notre bolt.
Les niveaux de garanties dans Storm
Storm garantie au moins un traitement de chaque tuple émis dans une topologie.
Dans ce cas, vos spouts et vos bolts émettent simplement des tuples sans prêter attention à leur devenir.
Comme ce niveau de garantie ne convient pas toujours, il est possible, au prix d'une perte de performances, d'avoir deux autres niveaux de garantie de traitements :
- weak consistency : une garantie de traitement de chaque tuple émis une seule fois
- strong consistency : une garantie de traitement ordonnée de chaque tuple émis une seule fois
Weak consistency
Un peu de la même manière que Cassandra permet de jouer sur le quorum par requête, Storm permet de jouer sur le niveau de garantie de traitement par Spout ou par topologie.
Le weak consistency consiste à ne plus simplement émettre des tuples mais d'utiliser de les marquer comme "ack" ou "fail" en fonction de la réussite ou non du traitement par bolt.
De cette manière le spout à l'origine du stream est notifié de quel tuple a pu et n'a pas pu être traité et peut alors prendre la décision de le réinjecter dans le stream ou de l'ignorer.
De plus, utiliser les ack/fail permet d'obtenir des statistiques de latence sur les traitements.
Strong consistency avec Trident
Imaginons maintenant que le besoin soit un cran plus haut, c'est à dire qu'en plus d'une garantie de traitement une seule fois, une garantie de traitement ordonné est nécessaire.
Pour répondre à ce besoin, Storm propose Trident, une surcouche construite au dessus des abstractions de base que sont les spouts et les bolts et qui permet d'effectuer des traitements ordonnés par mini batchs.
Qu'est ce qu'un mini batch ?
Il s'agit d'un ensemble de tuples identifiés par un même numéro de séquence.
Trident garantie que les mini batchs sont ordonnés, c'est à dire que le mini batch 1 sera traité avant le mini batch 2, et ainsi de suite.
Storm, la couche temps réel d'Hadoop ?
Un cas d'utilisation de Storm qui revient souvent est celui de la couche de traitement en temps réel à Hadoop.
C'est ce que l'on appelle une architecture Lambda.
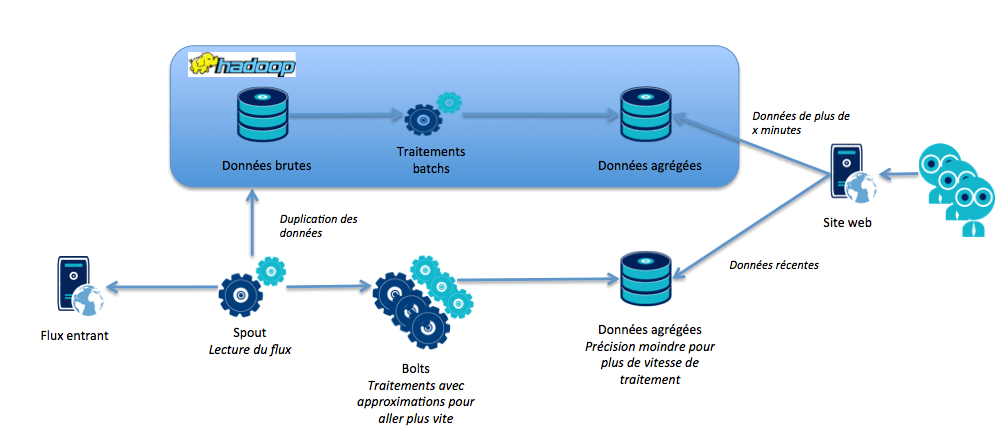
Cela part du constat suivant :
- Hadoop est bon pour faire des traitements batch mais mauvais lorsqu'il s'agit de temps réel
- Storm sait traiter en temps réel de gros flux de données mais n'a pas de solution de stockage de big data
Imaginons que l'on veuille suivre l'évolution de consommations des ventes sur des sites e-commerce à fort traffic en analysant les logs des serveurs web.
Hadoop est capable de fournir des agrégats sur plusieurs axes d'analyses et des ETL permettent aux métiers de concevoir ces analyses facilement. Cependant, il lui faudra malgré tout quelques minutes pour calculer ces derniers.
L'idée de l'architecture Lambda dans ce cas est d'utiliser Storm pour calculer au fil de l'eau une approximation des agrégats sur l'intervalle de temps nécessaire à Hadoop pour calculer les agrégats précis et pérennes.
Storm ne conserve donc jamais très longtemps les résultats de ses analyses, il pourrait même dans certains cas les persister en mémoire et en fournir les résultats via un DRPC.
Lorsque Hadoop a terminé ses calculs, les agrégats dans Storm sont remis à zéro, les résultats de Hadoop faisant foi.
Ainsi, il est possible de fournir en temps réel les courbes de tendances, lesquelles sont récupérées de Storm pour les x dernières minutes.
Conclusion
Bien qu'assez jeune, Storm est un produit très complet.
Bien que le déploiement d'un cluster Storm soit relativement rapide et aisé comparé à d'autres solutions big data, ce dernier n'est pas simple pour autant.
En tant que système distribué, le développement sur Storm reste un exercice qui requiert de bonnes connaissances sur les particularités de ce type de programmation. Sans cela, les performances peuvent rapidement s'écrouler.
Magré tout, Storm contribue à faire aujourd'hui ce qu'Hadoop a fait ces dernières années; baisser le coût d'accès aux technologies de calcul distribué, et en simplifier l'utilisation.
Cela va probablement permettre de faciliter un peu plus la migration d'un certain nombre d'architectures basées sur des batchs "trop gros pour échouer" vers des systèmes de traitements au fil de l'eau tolérants aux pannes, ce qui est une excellente chose.