Quel avenir pour la Data Science? Réalités et stratégie des entreprises
Les géants du web sont à l'origine de Big Data et demeurent une source d'inspiration inépuisable faisant rêver le Data Scientist au fond de chacun de nous.
Dernier exploit en date, l'algo de Google et Stanford capable de générer une légende à partir d'une image quelconque :

Bluffant.
Aussi passionnants qu'ils soient, ces progrès paraissent bien éloignés des préoccupations des entreprises qui nous entourent, et à raison. Les enjeux du marché Français dans les secteurs de la Banque ou de l'Industrie ne partagent que peu d'atomes crochus avec Google : battre l' état de l'art de la vision artificielle de 2% ne bouleverse ni notre compréhension de Big Data, ni la définition de ce que sera demain une "Data Driven Company".
Alors, quel avenir pour la Data Science? Difficile de répondre.
Quelle seront ses évolutions dans nos entreprises maintenant et pour les prochaines années? Voilà la question à laquelle nous allons nous intéresser.
Démocratisation
La véritable révolution pour l'analyse de données réside dans la facilitation de l'accès aux outils, méthodes et connaissances associés.
Nous disposons de nouveaux logiciels, gratuits, puissants, intéractifs et complets. Pour exemple Python s'affirme actuellement comme environnement d'avant-garde, avec des frameworks tels qu'Anaconda permettant de développer des rapports d'analyses mêlant code, texte, visualisations et modèles de machine learning.

Ensuite vient l'accès à la connaissance. Sujet traditionnellement ancré dans une culture académique et littéraire, la Data Science s'ouvre et se place au même niveau que le développement logiciel avec :
- Des cours en ligne, dont le fameux coursera d'Andew Ng.
- Des ouvrages de plus en plus orientés vers la pratique, comme "Doing Data Science" chez O'Reilly.
- Des outils qui encapsulent la complexité mathématique. Pour entraîner un modèle de machine learning aujourd'hui, une ligne de code suffit.
- Des formations dédiées en pleine émergence (on pensera par exemple au mastère Big Data dispensé à Télécom ParisTech)
Ces changements se cristallisent en une appropriation du sujet par les digital natives, la génération Y, les bidouilleurs ou encore les data enthusiasts. De plus en plus de personnes intéressées par la donnée et capable d'en tirer de la valeur, avec un état d'esprit proche de certains codeurs : "Si ça marche c'est bon". Bien loin sont les lamentations concernant les hypothèses d'échantillonnage... On en revient au fameux diagramme de Venn définissant le Data Scientist comme le composite de trois compétences complémentaires :
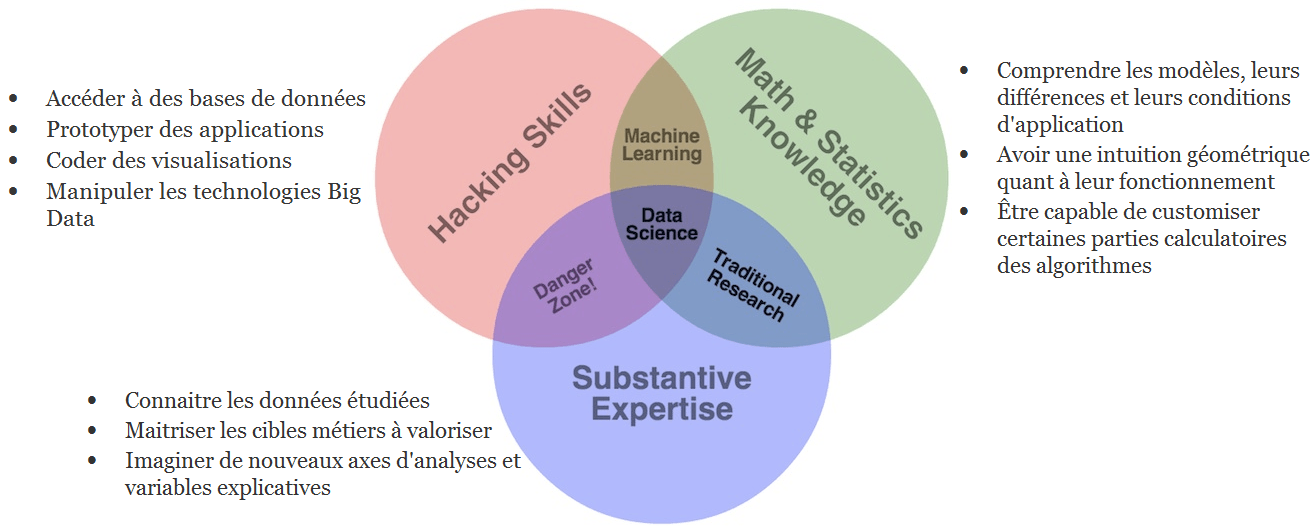
Ce profil hybride vise la productivité, la polyvalence, l'agilité et la débrouillardise.
L'incarnation ultime de cette culture en transition: Kaggle, des compétitions de Data Science en ligne. Sur le site, on navigue hasardeusement aux bords d'une frontière séparant état de l'art scientifique et jeu multijoueur en ligne...
Ubiquité
Quelle influence cette démocratisation va avoir sur le quotidien de nos entreprises?
Pour de nombreux secteurs, l'analyse prédictive n'est pas un sujet neuf. Les exemples ne manquent pas, que ce soit les Quants dans la finance, ou l'analyse de consommation électrique chez les acteurs de l'énergie. En revanche, on pourrait remarquer que l'utilisation de la data se cantonne souvent au core business. Pour des problématiques limitrophes ou génériques telles que le web analytics on constate soit une profondeur d'analyse très faible, soit une externalisation des outils et des compétences. Demain ces domaines seront impactés par une ré-internalisation des profils et profiteront de la même force de frappe prédictive que certaines applications du core business.
Soyons clairs : l'utilisation du machine learning va se renforcer et se généraliser, partout, tout le temps et pour tout. Le recrutement passera par de la veille automatisée sur Twitter ou LinkedIn sur la base de la théorie des graphes. La trésorerie sera gérée par déclenchements d'emprunts au regard d'algorithmes d'anticipation. Le knowledge management va être disrupté par les moteurs de recherches et l'application du natural language processing aux patrimoines documentaires...
Ce changement est inévitable, comme l'explique très bien Yann Lecun, directeur de la recherche en IA à Facebook :
"The amount of data generated by our digital world is growing exponentially with high rate (at the same rate our hard-drives and communication networks are increasing their capacity). But the amount of human brain power in the world is not increasing nearly as fast.
This means that now or in the near future most of the knowledge in the world will be extracted by machine and reside in machines. It's inevitable. En entire industry is building itself around this, and a new academic discipline is emerging."
Sans parler des réseaux sociaux ou des communications gargantuesques générées demain par l'internet des objets, nous vivons aujourd'hui une époque où la donnée est terriblement sous utilisée! Cette démocratisation doit impacter les différents niveaux dans l'entreprise d'un point de vue métier mais également d'un point de vue des ressources humaines. Quelque soient nos responsabilités ou nos profils, nous devons développer une appétence et une confiance forte envers la donnée. Secrétaire, chef de projet, DSI, développeur, chargé de communication, directeur du marketing, personne ne doit être épargné dans le développement de cette culture.

Des solutions s'expriment au travers des formations à l'utilisation d'outils d'accès à la donnée, des rituels du type stand-up appliqués à la data et une ouverture totale de la donnée en interne. Aujourd'hui les équipes métiers ne dépendent que trop de la présence de Data Scientists, vrais porteurs de l'innovation. Il est essentiel que chacun prenne conscience des possibilités liées au Big Data. Le propre du machine learning est d'apprendre aux programmes à résoudre des problèmes qu'on imaginait indépassables : pour une fois qu'on propose la liste au père noël à nos métiers, profitons en.
Scalabilité
Cette vision n'est valable qu'à une condition : la scalabilité.
2025, vous êtes Data driven (bravo!) et votre entreprise abrite un écosystème foisonnant de modèles, datavizs, et autres crunchings de données en tout genre. Le coût fixe d'entretien de cet écosystème va automatiquement être très élevé. Il faudra ré-entraîner les modèles et vérifier leur validité régulièrement, développer inévitablement une approche API en interne qui ouvrira les modèles en tant que services, faire de plus en plus attention aux questions de gouvernance de la Donnée. Sans évoquer les difficultés technologiques liées à ces architectures qualifiables de "Data Lake" , comprenant des outils variés (streaming, batch, search, machine learning...), multitenantes, réunissant 100% de la donnée du SI...
Dans ces conditions, le coût marginal de développement de la millionième analyse doit être négligeable. Bonne nouvelle, c'est la trajectoire actuelle de la Data Science.
D'abord, les modèles nous demandent de moins en moins d'efforts à entraîner et se vérifient toujours plus efficaces. C'est la raison d'être du Big Data, plus de volume engendre des modèles plus robustes et plus précis, et ce sans exiger un travail de corps sur la donnée. De nouveaux programmes sont capables d'imputer les valeurs manquantes dans la donnée, générer des variables et d'optimiser automatiquement les paramètres des modèles (Grid Search). Les nouvelles capacités de calcul nous permettent de prendre en compte des milliers de variables sans distinction, d’entraîner des dizaines de modèles pour les combiner (méthodes ensemblistes) et ainsi profiter d'une grande précision de prédiction sans pour autant tomber dans le sur-apprentissage. Les nouvelles avancées dans le Deep Learning montrent également la faculté des modèles à extraire des signaux très faibles dans des masses d'informations importantes, et ce sans connaissance métier.
Enfin, les nouvelles architectures sont en train de nous offrir cette scalabilité en érigeant la parallélisation des calculs au rang de standard. Le passage à l'échelle devient transparent et élastique grâce aux architectures distribuées convergeant actuellement autour d'Hadoop. L'investissement dans le matériel se révèle de plus en plus itératif, YARN et HDFS nous autorisant à rajouter du calcul et du stockage de manière très modulaire : un serveur de moins, un disque de plus, bien dégagé derrières les oreilles svp. De plus les technologies Big Data font abstraction des couches physiques en terme de développement. Des outils comme Spark MlLib proposent des algorithmes de machine learning distribuables sur des centaines de noeuds, aussi simple à utiliser qu'en local sur son poste. L'apprentissage machine évolue clairement vers plus de facilité et de rapidité : loin est le temps des optimisations C++ custom sur les descentes de gradients.
Entretenir et enrichir un écosystème de milliers de modèles n'est désormais plus un défi technique sans solution.
Conclusion
Démocratisation, ubiquité et scalabilité deviendront éventuellement le quotidien des activités de Data Science de nos entreprises. On peut imaginer ces caractéristiques s'arrangeant en une pyramide des besoins, la scalabilité étant le Saint-Graal. Ces étapes seront embrassées progressivement en fonction de la maturité des acteurs sur le sujet Big Data, de leur appétence envers la Data en tant qu'asset, et tout simplement en termes de capacité d'investissement. Pour finir, il faut rappeler qu'une telle approche nécessite au préalable une excellence opérationnelle sur des sujets clés tels que DevOps, les architectures orientées API, l'agilité dans les développement, le continuous delivery...
Un Égyptien sage bâtit sa pyramide sur des fondations solides.