QCon London 2011: un peu de process, beaucoup d'architecture et de la performance pour passer à l'échelle
Il y a une semaine, avait lieu la 5° édition de QCon, un événement incontournable pour l'architecture de SI, pour sentir les tendances de l'industrie, pour détecter quelques nouveautés. 6 tracks parallèles, un total de 90 sessions. Impossible de participer à tout mais voici ce que nous en avons envie de retenir :
Des sujets d’actualité...voire innovants
Agile, c’est maintenant au tour de l’entreprise
Cela passe par l’organisation des équipes et la keynote d'ouverture par Craig Larman nous le rappelle. Cela confirme également la tendance du marché vers ces pratiques de développement logiciel ou produit (puisque C. Larman a notamment parlé de retours d’expérience chez Xerox) : il ne s'agit plus de convaincre que c’est une manière efficace de “faire du logiciel” mais de voir comment améliorer ces processus et passer à l'échelle. Alors “Features teams are better than component team” Craig Larman dans le texte et il s’agit de privilégier un découpage du produit en domaine qui ont chacun leur organisation scrum, leur PO, leur équipe pluridisciplinaire. En somme une organisation vue du client et pas vue de l’architecture (Loi de Conway). Dès lors, il est néanmoins important de formaliser des “Communities of Practices” : des rencontres d’experts (donc des personnes qui partagent des sujets et des problématiques communs) cross-team et finalement transverses à l’organisation, des lieux et temps de rencontre formalisés pour échanger, partager, progresser, cultiver le sentiment d’appartenance (vous n’avez qu’à regarder toutes les rencontres/échanges que mettent en place les plus grands cuisiniers français...). Enfin, il faut rappeler que le sprint règle et rythme la vie du produit, pas de l’équipe et on tentera de colocaliser les équipes par domaine.
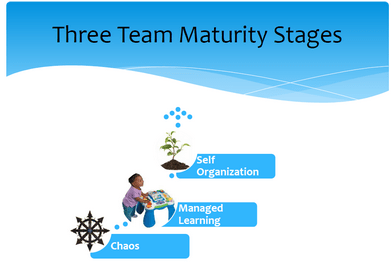
Cela passe également par l’organisation au sein de l’équipe. Roy Osherove l’a vécu et l’affirme "Most team leaders use the wrong kind of leadership for the current team stage”. Il définit ainsi différents niveaux de maturité d’une équipe et rappelle que trop souvent est faite l’hypothèse qu’une équipe agile est auto-organisée et doit seulement être coachée alors que souvent, il s’agit de faire grandir son équipe et adapter son management au niveau de progression de l’équipe.
Cela passera également par la “prod” et c’est dans cette mouvance que s’inscrit le mouvement devops. On notera l’agréable session de Jez Humble qui prolonge des choses que nous avions évoqué lors d’USI 2009. Il y a un enjeu fort à fiabiliser les mises en production et les “remediation patterns” y participent (Cf. plus bas). A noter que Jez Humble sera présent (ainsi que John Allspaw) à USI 2011
Pour aller plus loin, Dan North et Chrid Read (DRW Trading) étaient là pour nous parler de “Agile Operations”, issue de la culture devops (rapprochement entre les pratiques/outils des études et production) et de “Lean Operations” (dirigé par la théorie des contraintes dont l’auteur principal est Eliyahu M. Goldratt) avec pour objectif de réduire les gaspillages. Trois exemples concrets : superviser en une ligne de shell avec ping et mailx (ça rappelle le Taco Bell Programming), automatiser la configuration système à l'aide de Puppet/Chef pour éviter les process complexes et interminables entre la commande et la livraison d'environnements configurées ou encore améliorer la stabilité du système par du test-driven infrastructure (ex: pre-commit hook SVN pour valider la conf réseau avant même de commiter, utiliser sentinel pour tester en continu l'état du réseau, etc.).
Distributed Data Storage & nosql : un sujet d’actualité dans les industries de la Finance et du Web.
Distributed Data Grid et solutions NoSQL ont suivi des chemins différents mais adressent des sujets similaires. D’un côté, on est passé par la mémoire (shared memory), de l’autre par la parallélisation (shared nothing). D’un côté, le besoin d’optimiser la latence (une obsession dans le domaine financier), de l’autre, le besoin d’absorber des débits de requêtes de plus en plus importants, The End of an Architectural Era.
Alors certes, les Distributed Data Grid ont trouvé leur place dans le monde de la banque et NoSQL dans le monde du web. NetFlix nous a raconté sa stratégie et sa mise en oeuvre de migration vers AWS plutôt que de recontruire un nouveau Data Center. Les difficultés qu’ils ont rencontrés avec SimpleDB semblent corroborer ce qui est écrit dans ce papier. Bref, ce n’était pas de la publicité pour SimpleDB; bien au contraire et, à tort ou à raison, cela semble justifier leur choix de migrer vers Cassandra (et d’inverstir dans des nouveaux développements notamment au niveau des stratégies de réplication). Facebook nous a fait une présentation des travaux qu’ils réalisaient avec HBase. The Guardian, célèbre journal anglais, a mis en oeuvre MongoDB.
Des acteurs qui s’accordent sur le fait qu’il y a des manques tout de même : des APIs clientes encore trop simplistes (pas de timeout...), des limitations autour de l’upgrade du cluster sans interruption de services.... Reste que d’autres comme Twitter restent sur MySQL et semblent satisfaits . Nick Kallen démontre comment Twitter réalise le stockage des tweets, l’affichage de la timeline et la gestion du graph social dans MySQL (avec notamment l’utilisation de FlockDB ou Gizzard) en fonction des contraintes de performance. Pour info, on y retrouve quelques ordres de grandeurs qui permettent de positionner les contraintes auxquelles est soumise l’architecture : à titre d’exemple, 1100 tweets sont écrits par seconde. En revanche, la timeline sert 2,1millions de lectures par seconde (la timeline est pré-calculée et stockée dans memcached), et le graphe social doit gérer 20k modification / sec.
A noter que ce domaine est encore en pleine évolution. La preuve avec cette initiative intéressante de cela dépend des cas d’usage. Jusque là, “rien de génial” mais l’innovation dans ODC c’est que ce choix réplication vs. partitionnement, bien que définit par configuration en fonction de l’utilisation qui est faite de la donnée (type de requête...), n’impacte que le stockage de la donnée et absolument pas la modélisation qui peut rester relationnelle... Ainsi ODC, basée sur Cohérence, permet par configuration d’assurer ces deux modes de fonctionnement et du même coup de gérer des jointures, des indexations...
En somme, un domaine d’innovation si on le compare à celui des RDBMS mais qui trouve sa place, son terrain de jeu.
Big Memory : Azul, Terracotta...la limite de la JVM à 3 ou 4Go n’est plus acceptable
Une tendance intéressante qui part du constat que les évolutions d’infrastructure nous amènent à des serveurs pouvant proposer sans problème 50 Go de RAM voir plus. Or nos JVMs (enfin les Garbage Collector) ont bien du mal à dépasser les 3 ou 4 Go ce qui conduit inexorablement à une multitude de process en parallèle... avec ce que cela peut impliquer en terme de supervision. Azul propose sa JVM Zing qui inclue un GC sans pause. Il n'y a donc plus à avoir peur des minutes où le GC tournerait pour faire le ménage dand la heap d'une JVM de 100GB. La seule (grosse) limite actuelle de cette JVM est qu'il faut un noyau Linux patché ou exécuter son application dans une VM (au sens OS, pas une JVM). Dans ce dernier cas, la JVM est remplacée par une JVM proxy qui renvoie tout vers la JVM Zing présente dans une autre VM (Zing Virtual Appliance) avec un noyau patché. Terracotta propose des extensions à Ehcache; Big Memory, qui vise à contourner la JVM et à utiliser directement la RAM disponible pour stocker de l’information. BigMemory doit bien entendu être couplé à Terracotta Server qui va ainsi rajouter la couche “scalabilité” et persistence.
Les langages fonctionnels et plus particulièrement la programmation orientée acteur continuent leur "bonhomme de chemin"...
A commencer par Erlang; un langage fonctionnel pensé pour construire des applications concurrentes, distribuées et résilientes. Pour cela, il permet la création de processus légers (appelés acteurs) en taille mémoire nécessaire, en temps de création mais aussi en temps d'ordonnancement. Il est ainsi facilement envisageable d'avoir une application avec plusieurs centaines de millier de ces processus. Ces processus sont gérés (créés et schedulés) directement par la VM Erlang évitant ainsi les allers-retours entre le noyau de l'OS et l'espace utilisateur. La philosophie de la programmation par acteurs est "share nothing", contrairement à la programmation par threads. Chaque acteur communique alors avec les autres en envoyant des messages asynchrones et traite les messages reçus les uns à la suite des autres. Ces acteurs travaillent donc tous en parallèle sur plusieurs coeurs d'un même CPU et sur plusieurs CPU distribuées sur plusieurs machines. Enfin et concernant la résilience, en cas de “crash” d’un des processus, les processus préalablement liés sont notifiés et prennent la décision adéquate. Ainsi des patterns tel que "Supervisor & Worker" permettent de configurer une stratégie de redémarrage des workers (combien de redémarrage successif du même worker avant d'abandonner, relancer seulement le worker qui a planté ou l'ensemble des workers supervisés, …). En plus de cela, un certain nombre d'autres mécanismes tel que le déploiement à chaud d'une nouvelle version d'une application, l'activation de cette nouvelle version, le rollback à une version précédente, … apportent aux applications développées en Erlang une disponibilité maximale.
Ce type de programmation n’est pas sans inspirer le développement de nouveaux produits basés sur l’asynchonisme et des approches orientées évènements (type SEDA). Ces approches - à la Node.js , ou encore Tornado visent à dépasser le “C10k Problem” en découplant requête et réponse (qui sera traité dans une callback) et ainsi assurer une meilleure concurrence.
L'objectif de ces outils est ainsi de pouvoir supporter un très grand nombre de connexions simultanées (grand nombre de requêtes à la seconde ou grand nombre de connexions longues (ex: long polling, websocket, …)) et chacun y va de sa solution :
- Node.js propose des API IO asynchrones. En effet Node.js n'exécute le code que sur un seul thread qui traite toutes les requêtes en parallèle et switch de requête dès qu'il exécute un appel IO via une API asynchrone. Ainsi le traitement du résultat de cet appel sera traité dans un handler. Cette approche est dite event-driven programming
- Erlang et Haskell (qui utilisent aussi des green-threads légers en mémoire, cpu et context switching) présentent un modèle hybride complètement transparent pour le code. Le code est écrit avec des API IO synchrones (plus simple) mais la VM utilise quand cela est possible des appels IO asynchrones (
epoll()par exemple) ou utilise le threading classique niveau OS lorsqu'un appel bloquant est obligatoire (accès fichier par exemple). A noter l’initiative de Basho, éditeur de Riak, qui a développé Web Machine ; un condensé d’HTTP.
Au delà de la performance, un des challenge de ce type d’outil (contrairement à la programmation orientée acteur où le mindset, le paradigme est différent) concerne le développement : comment offrir des APIs qui fonctionnent en asynchrone même si le comportement est synchrone et qui n’impactent pas le code, sa lisibilité? quid de l’outillage, du debug etc...
La résilience qui, avec l’efficience des systèmes est certainement un des prochains challenges (enfin...)
A****lors la résilience a été au niveau langage avec des plateformes type Erlang qui ont fait leur preuve. La plateforme OTP (Open Telecom Platform) d'Erlang permet de construire une hierarchie de supervision de sous-systèmes à base d'acteurs (en s'appuyant sur le pattern "Supervisor & worker" précédemment décrit) capable de supporter le crash d'un sous-système et de se réamorcer. Ce guide présente plus en détail comment Erlang gère la résilience.
Au niveau des tests où l’on se rend compte que les tests de résilience arrivent très tôt dans le processus de développement, avant même les tests de performance qui nécessitent la mise en place d’infrastructure représentative (voire de réaliser des “parallel runs”)
Mais également au niveau delivery et déploiement avec Jez Humble : les “remediation patterns”. On y trouve des patterns comme :
- “feature toggle” qui vise à décorréler le déploiement du code du déploiement d’une fonctionnalité,
- le “Canary Releasing” qui vise à déployer une partie de la population sur la nouvelle version de l’application (une solution pour l’A/B testing, les tests de performance...); avec un sujet sur la base de données qui peut être adressé soit en reconciliant les deux bases, soit en stockant des évènements (cf. Event Sourcing) et en rejouant les évènements, soit en assurant la compatibilité ascendante du schéma (certainement la meilleure solution mais celle qui demande le plus de discipline, car le plus important sera de nettoyer le schéma à terme). Ce papier de Google traite malheureusement pas assez en détail de ces sujets.
- ou encore l’incremental delivery
Des domaines qui continuent de s’améliorer (et où l’on considère bien souvent que plus rien ne se passe)
La qualité logicielle et la réarchitecturation des systèmes
Rien de nouveau mais ça va mieux en le disant :
“All architecture is design but not all design is architecture. Architecture represents the significant design decisions that shape a system, where significant is measured by cost of change.” Grady Booch
Concernant la qualité logicielle, un des sujets est certes de choisir les indicateurs mais surtout de choisir la représentation de ces derniers (et quelques part choisir les façons de communiquer qui seront les plus adaptées). Cela n’est pas sans rappeler le mouvement Data Visualization si cher à notre Joseph national (spécial dédicace :o) ). On utilisera alors à façon treemap facilitant la visualisation de la taille du code, la complexité cyclomatique ou encore des ratios nombre de LOC sur nombre de LOC de tests. A noter qu’il est possible de représenter le code sous forme de ville en 3D avec CodeCity.
Les plateformes telles que Java & .Net continuent de s’améliorer
Alors il y a du classique avec Spring 3.1, Servlet 3.1 ou encore Mono Cecil; une librairie .Net Open Source cross-platform (de .NET à WindowsPhone 7) permettant d’étendre les fonctionnalités de réflexion classiques de la plateforme .NET (par exemple sur les champs masqués derrière une propriété), mais également de manipulation de bytecode. Cela permet de coder simplement des fonctionnalités de type AOP par exemple.
Et du moins classique... Java est adopté dans des environnements sensibles à la performance comme la finance. StreamBase, un CEP haute fréquence implémenté en Java avec , il faut bien l’avouer, quelques optimisations ou spécificités, notamment sur la gestion du garbage collection ou la génération du bytecode avec Janino (un compilateur à la volée et en mémoire).... Cameron Purdy, ancien CEO de Tangosol et vice président de Oracle Fusion Middleware a également confirmé cette tendance en présentant plusieurs axes de travail (la sortie de ces travaux n’étant même pas encore confirmée) permettant à Java d'être plus performant (notamment sur la latence, cruciale dans le domaine financier). En bref, pour le moment de la pure R&D, qui sortirait peut-être dans une version 9 de Java, avec notamment
- une API pour du bus de message basse latence directement sur RDP/Infiniband ou TCP/IP, JMS étant “trop lourd” dans ce cas. Java chercherai donc à jouer sur le même terrain que ØMQ.
- un accès direct et distant à la RAM RDMA sans passer par le noyau (oui, oui vous avez bien compris)****, pour là encore gagner en latence. Le prix à payer est que ces innovations utilisent très fortement les optimisations (et donc les particularités) de l’OS et du matériel... Les premières implémentations de ces API sont visiblement prévues sur les appliances Exalogic. Issues de la synergie que lui offre désormais un fondeur pour des puces dédiées (Sun), un OS et un hyperviseur maison (Oracle Unbreakable Linux) et une JVM, ces appliances sont les Rolls-Royce d'Oracle sur lesquelles l'éditeur mise beaucoup dans le monde de la finance. Et pour être franc, tout cela sent le “Java propriétaire”...
HTML5 comme plateforme
Mark S. Miller de Google a ainsi présenté les concepts qui sous-tendent la sécurité pour le cross-scripting de ECMAScript (JavaScript) 5. L'objectif est clairement de sortir d'une logique page web et de construire des objets JavaScript qui interagissent entre eux à travers Internet... Un objectif qui n’est pas sans rappeler la notion de “mashup” mais qui surtout nécessitent de repenser la Same Origin Policy. 
Même Adobe se positionne sur HTML5 voyant là un standard permettant de cibler le plus grand nombre de plateformes. Cela commence par l’enrichissement de sa gamme de produit; DreamWeaver avec entre autre les nouvelles balises de Sections HTML5, Illustrator capable d’exporter les images en SVG ou Canvas via un plugin. L’apparition de nouveaux outils comme Wallaby confirme cette stratégie permettant aux éditeurs Flash de convertir leurs animations en HTML5 (ciblé bannières publicitaires pour compatibilité iPhone, iPad, etc.), mais aussi de futurs outils à surveiller comme le projet appelé “EDGE prototype” dont l’objectif est de fournir un outil dédié à la construction d’animations orientées timeline, entièrement HTML5 et Javascript, en partenariat avec JQuery. Flash reste dans cette vision la plateforme pour les fonctionnalités innovantes : Peer to Peer, collaboration ou encore 3D (Molehill par exemple).
L’intégration reste un sujet d’actualité (et c’est pas près de s’arrêter avec le Cloud...)
Les frameworks légers type Camel, Spring Integration sont massivement utilisés notamment dans des contextes financiers à très fortes contraintes. John Davies nous a fait une magnifique explication de leur plateforme d’échange qui gère du multi-format, multi-version, du routage et de la conversion FIX, FpML, SWIFT à un niveau de performance impressionnant : 100 000 req/sec avec une latence < 10 ms. Il est clair que la notion Canonical Model a été bien challengé au profit d’un pattern qu’il appelle Integration Object. L’idée est en somme de gérer le routage et la mapping directement en Java (notamment via Jaxen, Saxonica...) et la persistence dans un cache type Coherence ou Gigaspace. En somme de l’ESB ultra léger sur un Data Grid.
Côté exposition de service, l’actualité est largement et encore tournée vers REST. Les maîtres mots étaient contrat minimaliste, souple, plutôt clé/valeur. Le principe REST de navigabilité des ressources trouve une utilisation dans la définition de workflow à travers l’implémentation du système Hypermedia (ici et ici)
Voilà ce que nous avions envie de retenir. Après comme dit l’autre :
“Prediction is very difficult difficult, especially about the future.” Niels Bohr