Protocol Buffers: Benchmark et utilisation sur mobile
Aller de plus en plus vite sur smartphone est devenu essentiel. Au delà du moyen de communication, le format de données utilisé joue un rôle sur la vitesse. Le JSON est aujourd’hui standard pour les API. Mais ce format de donnée est-il adapté au mobile? La manipulation d’un JSON en Android, par exemple, n’est pas simple.
D’autres formats de données émergent depuis quelques années comme Thrift, Avro, Message Pack ou encore Protocol Buffers.
Protocol Buffers, c’est la possibilité d’avoir un format binaire qui soit facilement adaptable et manipulable. C’est aussi une structure de base extrêmement simple à écrire et comprendre, qui permet de générer du code source facilement pour plusieurs langages.
Protocol Buffers (protobuf) a déjà fait parler de lui sur ce blog, en 2012. La version utilisée était alors 2.4.1, et la norme d’écriture, proto2.
Évolution
Le développement de protobuf a débuté en 2001, la dernière version stable date d’octobre 2014. Mais c’est la version bêta-3 3.0.0 qui sera utilisée tout le long de cet article (Edit (01/08/2016): la version 3 est enfin sortie!). Avec cette version bêta, la norme proto3 fait son apparition. Le but de cette nouvelle norme est de simplifier un peu plus les fichiers de déclaration de structure protobuf.
| message Hello {<br> message Bye {<br> required string name = 1;<br> optional int32 count = 2 [default = 1];<br> }<br><br> repeated Bye bye = 1;<br> optional bool check = 2;<br>} | message Hello { <br> repeated Bye bye = 1;<br> bool check = 2;<br>}<br><br>message Bye {<br> string name = 1;<br> int32 count = 2;<br>} |
| Norme proto2 | Norme proto3 |
Parmi les changements visibles entre proto2 et proto3, on note la disparition des attributs “optional” et “required”. L’attribut “required” était déjà déconseillé par Google : il empêche la suppression ultérieure du champ concerné des futures versions de l’objet. En effet, supprimer, modifier ou ajouter un champ “required” cause des bugs de lecture d’une donnée protobuf.
Outre les attributs, les valeurs par défaut ne peuvent plus être modifiées. Le premier argument en faveur de ces évolutions reste la simplification des objets. Le deuxième est l’extension de protobuf à d’autres langages, qui eux, n’acceptent pas forcément les valeurs par défaut. Ce choix permet donc d’uniformiser la génération dans les langages présents et futurs.
Malgré tout, la norme proto2 est toujours acceptée par le générateur de Protocol Buffers.
Dans sa version 2.6.1, Protocol Buffers peut se décliner sur quatre langages : C++, Java, Go et Python. Actuellement, la version 3.0.0-beta-3 propose neuf déclinaisons. C# et Objectif-C ont été ajoutés en bêta. JavaScript, Ruby et Javanano sont actuellement en alpha.
Protocol Buffers est sous licence BSD. Tout le monde a alors la possibilité de participer à son évolution. Cela permet donc une expansion rapide. On peut désormais trouver une multitude de générateurs protobuf pour beaucoup de langages différents. Cette liste répertorie une partie des implémentations existantes.
Benchmarks
Pour visualiser les performances de Protocol Buffers, un client (Nexus 5, Android 6.0.1) fait appel à un serveur (Go) pour lui transmettre du contenu texte. L’appel se fait en local, via HTTP/2.
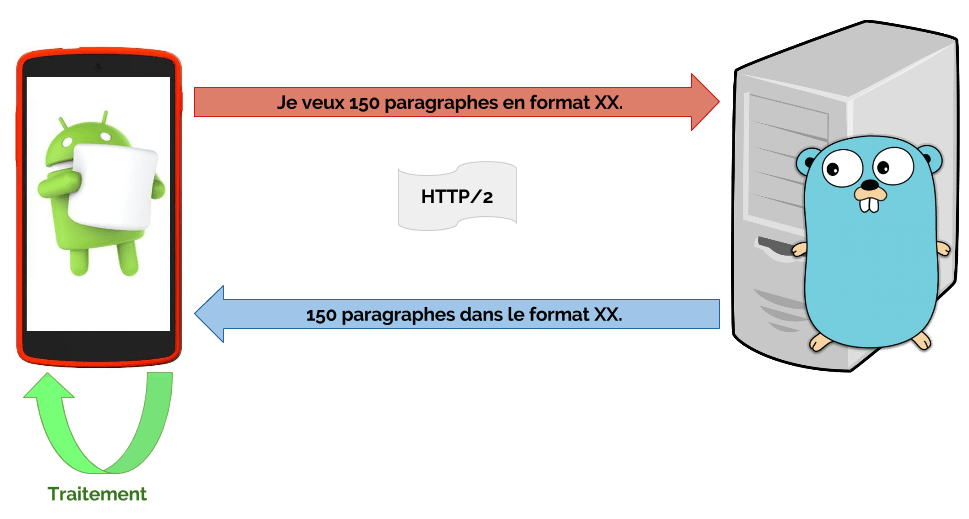
Environnement de Tests
Afin de comparer les résultats, d’autres formats de données sont introduits : XML, JSON et MessagePack. Pour le format JSON, trois librairies sont testées : Jackson, Jackson Jr et Moshi. Du côté de protobuf, il y a deux librairies utilisées : l’implémentation officielle de Google (bêta-3.0.0) et Wire de Square (2.2.0).
Temps de Traitement
Ce temps de traitement correspond au temps entre la fin de réception des paquets et l’envoi des objets finaux à l’affichage.
Le client demande donc au serveur 10 fichiers d’un nombre variable de paragraphes (entre 50 et 500). Ces paragraphes sont choisis aléatoirement afin que les données reçues soient différentes d’une demande à une autre. Chaque demande est renouvelée 50 fois afin d’avoir une moyenne pour chaque nombre de paragraphes. Ainsi, le temps d’initialisation de l’objet “parser” (que ce soit pour le JSON, MessagePack ou Protobuf) qui intervient au premier tour, est dilué. Ce choix est fait pour s’approcher de la réalité: l’objet “parser” est initialisé au premier passage et est réutilisé tout au long de l’usage de l’application.
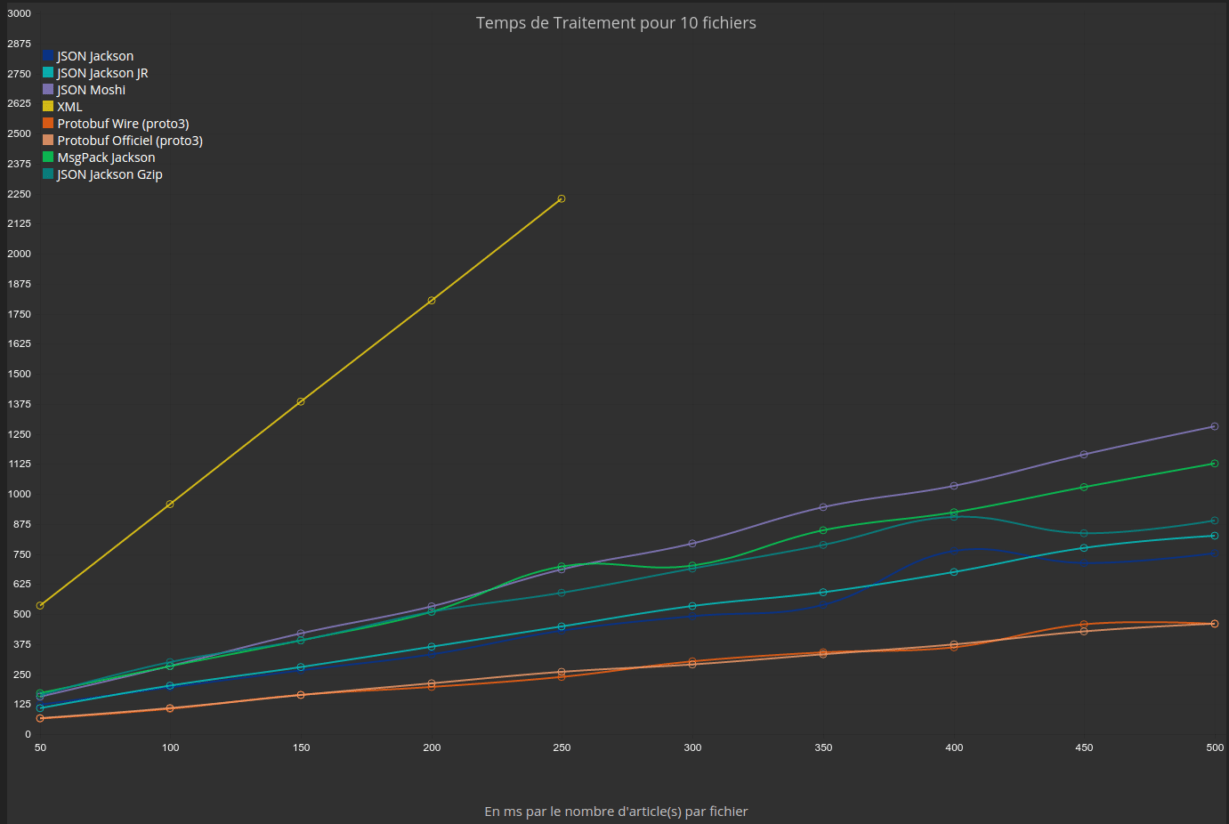
Résultats Benchmark: temps en ms par le nombre de paragraphes par fichier
Première constatation déjà connue : XML est totalement hors course. Pour plus de lisibilité, on retire XML du second schéma.
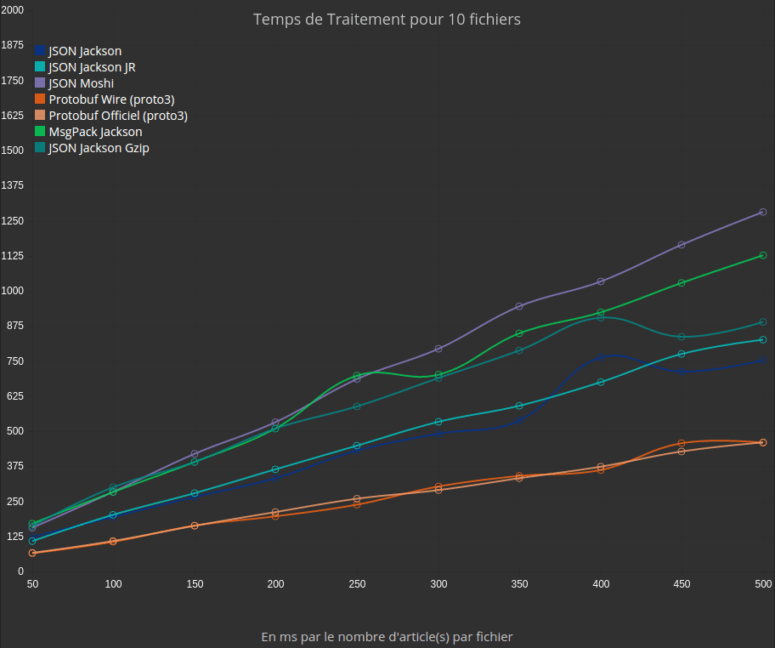
Résulats Benchmark sans XML: temps en ms par le nombre de paragraphes par fichier
Pour les autres formats, on peut constater un temps de traitement plus faible pour Protocol Buffers. Pour le JSON Gzippé, le coût du traitement est multiplié par 1,2 par rapport au JSON. Le facteur entre JSON (avec Jackson, soit le plus bas) et Protocol Buffers est de presque 2. La conclusion est donc qu’en temps de traitement sur des données textes, Protocol Buffers est nettement à son avantage.
Mémoire
Mémoire totale allouée pour l'appel et le traitement d'un fichier de 10 000 paragraphes
Concernant le coût mémoire, on s’aperçoit assez facilement que Protocol Buffers consomme presque aussi peu que Jackson pour le JSON.
Poids
Au niveau de la compression de la donnée initiale, on peut constater que le binaire protobuf est plus léger que celui de MessagePack ou encore du JSON Gzippé.
Côté Android
Malgré ces résultats encourageants, la mise en place d’une nouvelle solution peut paraître périlleuse. Pour Protocol Buffers, l’utilisation reste relativement simple. Prenons Android comme exemple. On a le choix entre l’Implémentation Officielle de Google (IOG) et la version de Square, Wire. Au-delà de l’efficacité, la comparaison de plusieurs autres points est nécessaire.
Génération du code :
Deux façons de générer votre code : en ligne de commande ou en pré-build.
En ligne de commande :
Pour IOG, le paquet de la dernière version est disponible et contient un exécutable.
protoc --java_out=. *.proto
Pour Wire, un jar est aussi disponible.
java -jar wire-compiler-2.2.0-jar-with-dependencies.jar --java_out=. --path_proto=. *.proto
En pré-build :
Du côté d’IOG, ce n’est pas possible. Du moins pour la norme proto3. Un plugin Gradle existe mais nécessite gradle 2.12 mais ne comprend que proto2.
Wire est plus efficace sur ce point. Square dispose officiellement d’une version Gradle du plugin Wire, mais le dépôt n’est plus à jour depuis environ un an. De plus, il n’y a aucune information d’utilisation et impossible de le trouver sur les dépôts officiels tel que jcenter ou mavenCentral. Un des forks résout ces problèmes : le plugin Wire Gradle par Jiechic.
La mise en place est ensuite très simple :
Dans build.gradle du projet :
classpath ‘com.jiechic.librairy.wire:wire-gradle-plugin:1.0.0’
Dans build.gradle de l’app:
apply plugin: 'com.squareup.wire' dependencies { compile 'com.squareup.wire:wire-runtime:2.2.0' }
Il suffit ensuite de placer les fichiers proto dans src/main/proto. A la compilation, les objets seront générés dans build/generated/source/proto.
Objets Générés :
Square gagne sans contestation. Les fichiers générés par IOG sont illisibles et rebutants. Ceux de Square sont bien plus simples à comprendre. De plus, les objets générés sont aussi plus simples à l’utilisation.
Encode/Decode :
Dans mon cas, seule la partie ‘decode’ de chaque version a été utilisée. Les syntaxes sont simples. Par exemple, la structure est la suivante :
syntax = “proto3”; package hello; option java_package = “com.sdu.testprotoreceive”;
message Hello { string name = 1; }
IOG version:
HelloOuterClass.Hello hello = HelloOuterClass.Hello.parseFrom(byteArray);
Wire version:
Hello hello = hello.ADAPTER.decode(byteArray);
Les objets générés par Wire étant plus simples, ils sont aussi plus naturels à utiliser.
Autres langages
Le serveur utilisé pour les tests présentés plus haut est en Go. La génération des objets Go depuis les fichiers proto3 se fait ainsi :
protoc --go_out=. *.proto
La commande est générique d’un langage à un autre, ce qui rend l’usage très simple. Pour interpréter le fichier généré, la librairie n’est pas sur le même dépôt que celui des autres langages :
go get -u github.com/golang/protobuf/protoc-gen-go go get -u github.com/golang/protobuf/proto
Example d’utilisation:
func sendProto(w http.ResponseWriter, r *http.Request) { hello := new(hello.Hello) hello.Name = “Marie” hello.Number = 32 w.Header().Set("Content-Type", "application/x-protobuf") helloCompress, err := proto.Marshal(hello) if err != nil { log.Fatal("Compress Problem (Marshal error)") } w.Write(helloCompress) }
Le dernier langage testé est le C#. Encore une fois, c’est la simplicité qui prime.
public static void Main (string[] args) { WebRequest wrGETURL = WebRequest.Create( "http://xx.xx.xx.xx:8000/"); Stream streamHello = wrGETURL.GetResponse().GetResponseStream(); Hello hello = Hello.Parser.ParseFrom(ReadFully(streamHello)); Console.WriteLine (hello.Name+" "+hello.Number+" "+hello.Bool); }
Ici, la fonction ReadFully permet seulement de transformer le Stream en tableau de bytes.
Mise en Oeuvre
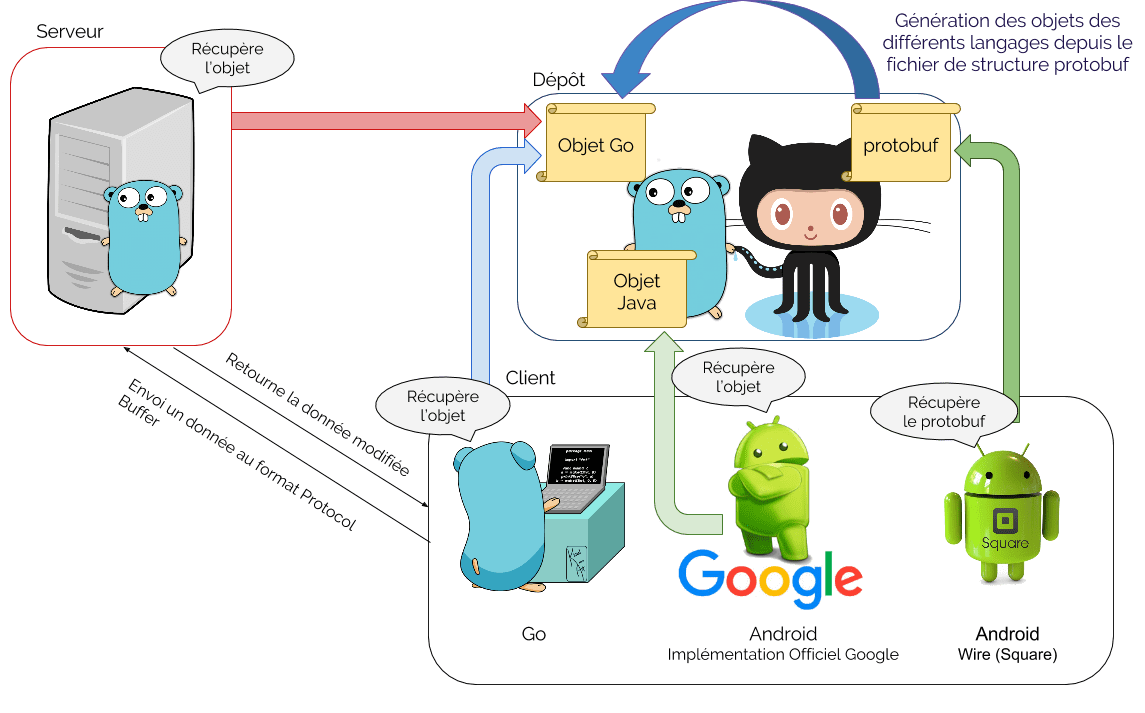
Schéma de la mise en oeuvre disponible: le dépôt, le client Go, le serveur Go, les clients Android
Un jeu de test fourni sur Github vous permet de voir une mise en oeuvre plus concrète. Un dépôt Go contient le fichier protobuf et possède une application pour générer les objets dans les langages souhaités. Un serveur Go va chercher dans ce dépôt son objet, un client Go fait de même. Le client Android sous Wire trouve le fichier protobuf et génère ses objets en pré-build. Le client Android sous IOG récupère le fichier jar créé par le dépôt Go.
Conclusion
La génération des objets pour Java, Golang et C# s’est faite en trois lignes de code grâce à un fichier très simple à écrire.
L’utilisation de ces objets est très semblable d’un langage à un autre et ressemble assez aux fonctions pour décoder du JSON.
Pour un contenu texte, sur un client Android, Protobuf possède plusieurs avantages comme la simplicité (“build”) ou le gain en temps de traitement (“run”). Son utilisation à la place du JSON peut même être conseillé dans le cas d’un nouveau projet.
Il faut néanmoins prendre en compte que certains outils sont peu ou pas mis à jour (comme le plugin gradle par Square).
La V3 tente de simplifier l’utilisation et d’agrandir le champs des utilisateurs, avec toujours plus de nouveaux langages. L’appréhension du binaire, l’utilisation de nouveaux formats et le JSON déjà en place depuis longtemps freinent le changement. C’est, je pense, les raisons qui laisse Protocol Buffers peu utilisé.