Premiers pas dans les infrastructures auto-scalables
On parle d'une infrastructure auto-scalable quand on est face à un système qui est capable d'adapter dynamiquement sa capacité ou les services qu'il fournit en fonctions d'événements extérieurs, et ce pour en garantir un rendement maximum.
Ce article se veut un point de départ pour les prochains travaux que nous allons mener, visant à recenser les principaux enjeux, acteurs, technologies et les problématiques inhérents à ces systèmes. Commençons par formuler quelques questions sans avoir nécessairement la prétention d'y apporter toutes les réponses. Citons simplement celles qui nous viennent spontanément, nous aurons tout loisir de les remettre en question.
Pourquoi faire des infrastructures auto-scalables ?
Pour adapter le coût à la demande
Rares sont les services qui ont besoin en permanence de la même puissance machine. Certaines professions demandent des puissances de calcul ou de stockage très importantes sur des périodes assez courtes (quelques jours à quelques semaines). Les sites d'information sont très dépendants de l'actualité et donc très fréquemment soumis à des pics de fréquentation très fortement supérieurs aux périodes creuses. Autant certains évènements sont prévisibles (élections, rencontres sportives), autant les services d'information sont particulièrement soumis aux aléas de l'actualité.
En période creuse, inutile de garder toute la puissance en ligne.
Pour gérer les pannes (design for failure, self-healing systems). Déjà utilisée sur les baies de disque, la notion de hotspare permet d'avoir des périphériques (des disques par exemple) prêts à prendre le relais dés qu'un composant réellement utilisé sera défaillant.
Quel genre de mécanismes peut-on envisager pour suivre la demande ?
- Ajouter /supprimer des nœuds, le classique scale-out.
- Redimensionner des nœuds (ajout à chaud de RAM / CPU), aussi connu sous le nom scale-up, cette solution n'est pas forcément triviale à adresser sans interruption de service.
- Activer / désactiver des fonctions (feature flipping) non-indispensables pour favoriser la partie névralgique du système. Dans le cas où l’augmentation de demande (et donc de trafic) ne génère pas plus de revenu (au sens large), la stratégie peut être de dégrader certains services du système.
Autour des questions d'approvisionnement de machines viennent naturellement s'ajouter des interrogations sur les modèles de facturation des infrastructures, de l'éventuelle complexité de calculs de coûts de licences pour des systèmes aussi fluctuants.
Quels genres d'indicateurs utiliser pour savoir l'état de santé d'un système ?
- Techniques (CPU, RAM, entrées/sorties disque, volume occupé...)
- Fonctionnels (nombre de clients, nombre de ventes par minutes, nombre de transactions ou de requêtes par seconde...)
- Business : nombre d'€ / $ de vente, de perte...
Quels composants sont impliqués dans une infrastructure auto-scalable ?
Résumons simplement cette question sous la forme d'une hypothèse : nous avons affaire à un modèle d'une boucle de rétroaction, type thermostat / radiateur. Notre sonde de température est la supervision et notre outil de configuration système et applicatif nous permet d'ajuster le système (qui doit être nativement élastique) pour tendre vers des valeurs de SLAs acceptables.
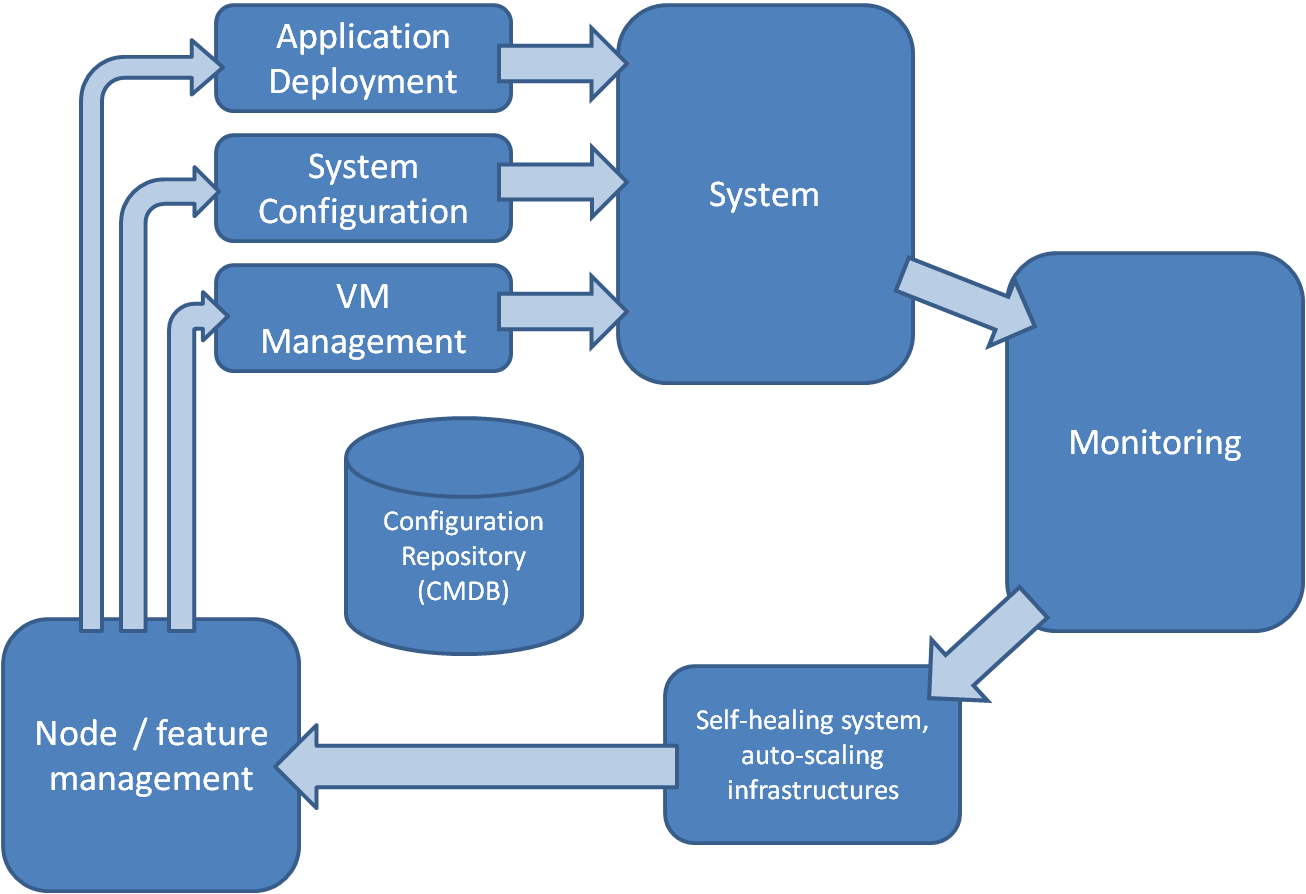
La subtilité de la démarche réside dans le besoin de mesure et piloter un système résilient et scalable. Ceci laisse à penser que les briques de gestion (le monitoring en particulier) doivent également présenter ces mêmes particularités de résilience et de scalabilité.
Quelle indépendance entre mon application et mon infrastructure ?
Mettre en œuvre une architecture auto-scalable ne doit pas se faire au détriment de l'indépendance entre l'application et l'infrastructure. Il doit être possible de changer de fournisseur d'infrastructure sans repenser tout le système. De même il est important de pouvoir définir des indicateurs métier complètement personnalisables comme critères de décision pour l'augmentation ou la réduction de la voilure de mon infrastructure. Dans les deux cas, ces adaptations doivent se faire avec le minimum d'intégration et de développements possibles, si possible uniquement par configuration.
Pour la suite
Notre travail dans les prochaines semaines sera d'apporter certains éléments de réponse venant infirmer / confirmer nos hypothèses. Nous aurons également pour mission de recenser quelques solutions du marché. Restez en ligne !